Tickerplant
The tickerplant (TP) template is an important component in the data warehouse architecture. It handles messages into the application, persisting them to disk and distributing to other processes. It usually receives all updates from feedhandlers (FHs). The logging takes the form of an append-only file on-disk and is critical for process recovery after a failure or restart.
Parameters
The below table details the TP template parameters.
| name | type | description |
|---|---|---|
| messagingServer | Config | Messaging server config |
| publishChannel | Symbol | Publish channel |
| subscriptionChannel | Symbol | Subscription channel |
| subscriptionTableList | Symbol[] | Subscription tables |
| logDirectory | Symbol | Location of logs |
| dsLsInstance | Instance | Name of log streamer |
| timeOffset | Integer | Hour offset from local time |
| pubFreq | Integer | Batching interval (ms) |
| eodTime | Time | Time when EOD signal triggered |
| initialStateFunct | Analytic | Analytic to run on startup |
| logRecoveryFunct | Analytic | Analytic to recover corrupt logs |
| includeColumns | Boolean | Include column names in logs |
| intradayFreq | Integer | Intraday roll frequency |
| intradayTables | Symbol[] | Intraday table names |
| logUpdError | Boolean | Log message to console if error processing |
| timeType | Symbol | Timestamping updates with gmt or local |
| consumerAlertSize | Integer | Limit on buffered messages before alert in bytes |
| consumerDisconnectSize | Integer | Limit on buffered messages before disconnect in bytes |
| multiPublish | Boolean | Publish single message with multiple tables |
| retryInterval | Integer | Retry interval (ms) for failures writing to log file |
| bufferEnabled | Boolean | Enable message buffering |
| bufferFunct | Analytic | Function to handle updates during buffering |
| bufferLimit | Integer | Buffer file size limit (MB) |
| EOIOffset | Integer | An integer number of minutes to offset the EOI times. May also be negative |
Intraday logging
By default the TP only writes one single log per day containing all data for all tables. In large volume environments, this can cause application and hardware issues. To address these, it's possible to split high-volume tables into lower frequency interval files. These files contain data for sub-intervals of the day; the frequency is determined by the intradayFreq parameter. If set to a value greater than zero, this mode is enabled. The intradayTables parameter specifies which tables should be written to these logs.
In a multi node set up, interval file rolling can be staggered using the EOIOffset parameter. Setting the value to a positive or negative value will offset the interval roll time for that instance. It will not affect the interval size.
Resilience and retries
The role of the TP is important for persistence and recovery. However this counts on the disk being reliable. Functionality is provided to try mitigate temporary disk failures by retrying when these occur. This can be enabled by setting the retryInterval parameter. If set, the TP will attempt I/O operations when they fail by sleeping and retrying.
Buffering
This feature provides support for applications to buffer messages in the TP. The target use-case is for rebalancing data across sharded data nodes. During the rebalance event, the application may not want to process certain data until the rebalance has completed. In this case, the TP will provide a hook for the application to buffer this to a separate file until a later point.
An example would be handling late data. Assume the application starts as a single node system with intraday write-downs. The current hour is stored in the RDB, IDB stores previous hours and HDB stores previous dates. Now if the load increases, the application decides to shard the instruments into two sets; A-M and N-Z. The system now consists of two sets of databases. The RDB data is easily migrated and feeds sharded to send to different locations. The on-disk data will likely take longer. Below is the situation at this point, assuming the current time is between 11:00 and 12:00.
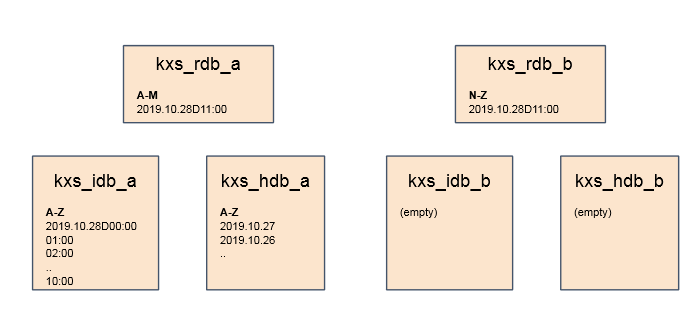
If data older than 11:00 hits the system, it can’t be merged with the on-disk data yet as that hasn't been migrated. In this case, the application wants the TP to buffer this data to a separate logfile until the rebalance completes. In the diagram below, the application code recognises a record as late and buffers it for later consumption.
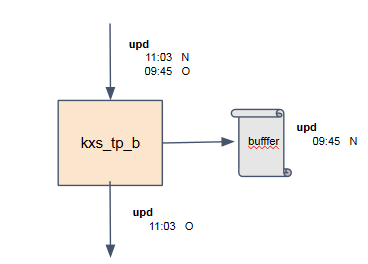
Important notes
- The buffering logic is implemented using the
bufferFunctparameter - The hook is injected into the TP
updhandler - Buffering hook isn't injected by default to protect performance
- Buffering events are controlled by the application starting and stopping them
Implementation
The mechanics of a buffering event are described. The application initiates a buffer event with a call to .ds.tp.buff.start. This creates a buffer log and opens a handler to it. It updates the TP update handler to inject the bufferFunct. Each event is identified by an ID provided by the application and this is part of the buffer filename; kx_tp_a.10.buffer. The start event also publishes a mark to subscribers and TP logs so the rest of the application can track the event.
The bufferFunct takes the incoming table name and data, and decides whether to process the update normally or buffer to the logfile. It should return the data it doesn't want to buffer and call .ds.tp.buff.log for the rest.
When complete, the application can end the event using .ds.tp.buff.end. This closes the buffer log and renames to indicate it's complete; kx_tp_a.10.buffer.complete. The bufferFunct is removed from the TP update handler. Another mark is published to subscribers and logs to indicate the event has finished.
If the TP restarts during a buffer event, it will attempt to recover its state by interrogating any open buffer logs. If an active log is found, the TP will re-initiate the event as active.
API
.ds.tp.buff.start
Called to initiate a buffering event. Along with the event ID, the function takes a dictionary argument, which can be used to describe the event for subscribers.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| id | long | Event ID |
| args | dict | Dictionary of event details |
Example:
.ds.tp.buff.start[10j; `source`cutoff!(`kx_dbw_a; .z.p)]
.dm.buff.start
This is the mark published at the start of a buffering event. It contains the ID, buffer log path and event meta dictionary.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| id | long | Event ID |
| logname | symbol | Buffer log path |
| args | dict | Event meta dictionary |
Example:
(`.dm.buff.start; 10; `:/path/to/kx_tp_a.10.buffer; `source`cutoff!(`kx_dbw_a; .z.p))
.ds.tp.buff.log
Logs a table record to the buffer log.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| tablename | symbol | Name of table |
| data | table | Data to be logged |
Example:
.ds.tp.buff.log[`kxData; ([] time:.z.p; sym:2?`2; reading:2?10.)]
.ds.tp.buff.end
Called to end a buffer event. Also takes a dictionary argument for providing additional information.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| id | long | Event ID |
| args | dict | Additional information |
Example:
.ds.tp.buff.end[10; `time`status!(.z.p; `complete)];
.dm.buff.end
This is the mark published at the end of a buffering event. It contains the ID, buffer log path and event meta dictionary.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| id | long | Event ID |
| logname | symbol | Buffer log path |
| args | dict | Event meta dictionary |
Example:
(`.dm.buff.end; 10; `:/path/to/kx_tp_a.10.buffer.complete; `time`status!(.z.p; `complete)
Subscribers
Subscriber processes can specify handlers for the buffer mark events. This allows them to take actions when buffer events start or end. The handlers are defined using instance parameters; .dm.buff.i.start and .dm.buff.i.end.
If not defined, the hooks will default to stubbed functions that take no action.
Interval Triggering
This function is added to TP to manually trigger interval roll. It takes one optional parameter - the name (symbol) of the calling process. This then updates the next interval trigger time to the end of the current second. Interval will trigger and then reset to the previous scheduled times, i.e. if rolling every hour and triggered manually at 11:30, will be re-scheduled for 12:00 after the manual trigger.
APIs
.ds.tp.triggerInterval
Called to manually trigger an interval roll. Takes an optional parameter - the name(symbol) of the calling process.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| inst | symbol | Process name |
Example:
.ds.tp.triggerInterval[`];
<->2020.02.04D12:10:29.653 ### normal ### (24501): Manual interval trigger. Scheduled for: 2020.02.04T12:10:30.000 ### ()!()
.ds.tp.triggerIntervalDetails
Similar to .ds.tp.triggerInterval but takes additional dictionary parameter of details you wish to print to logs.
Parameter(s):
| Name | Type | Description |
|---|---|---|
| inst | symbol | Process name |
| details | dict | Interval details |
Example:
.ds.tp.triggerIntervalDetails[`; `a`b`c!til 3];
<->2020.02.04D12:15:39.046 ### normal ### (24501): Manual interval trigger. Scheduled for: 2020.02.04T12:15:40.000 ### `a`b`c!0 1 2