Introduction
The following sections will explain how to build a basic data warehouse. It will walkthrough how to configure each of the components. The example use-case will be capturing system monitoring statistics at a server level which can be used to build out dashboards, alerts, ML models etc. A dummy feed will be configured to provide the feed data.
Why adopt the intraday model?
While server RAM is getting larger and cheaper, in practice there are still limitations for most systems. As daily data volumes increase, so do the challenges capturing and efficiently accessing this data. The length of time to perform EOD (writing the data to disk from memory) also increases. This takes the RDB offline for performing other operations.
The intraday writedown model addresses this by splitting the daily data across on-disk and in-memory, and introducing another process to handle the writedowns. The LR handles the disk writing, freeing the databases up. It also creates an on-disk database for the current day's data. Data for the current day is split across on-disk and in-memory.
How it works
- The TP receives streams of data and logs to disk for recovery purposes.
- The LR periodically checks for inactive intraday log files. If found, it replays the log to create the intraday database, tells the IHDB to reload and delete equivalent data from the RDB.
- In this transaction, data is partitioned by
symcolumn and sorted by time. It allows data in the IHDB to be queried more efficiently, and saves time to write to the HDB and add parted attribute at end of day (EOD). - When data is transient during writedown, the gateway (GW) and query router (QR) are taken offline so data can’t be queried.
- At EOD, the LR finishes replaying the remaining logs and moves all data to the HDB. It refreshes all databases, resetting the realtime and intraday databases and reloads the newest data to the HDB. By having the LR do the writedown, the RDB is free to accept client requests and perform other operations.
Logging
The TP writes "interval" files for high volume tables and a "main" file for the rest. "Interval" files are replayed to the intraday DB and others remain in-memory in the RDB. The TP maintains active interval and main files.
Building a data warehouse
This document will provide instruction on building a basic data warehouse using intraday writedowns and service classes. It includes:
- A package for the system to maintain modular organization (
KxWarehouse). - A schema group (
monCore) and four schemas to organize and define the datasources to be captured, stored and used throughout the system. - A tickerplant to capture, log and distribute data to other processes in the system (
kxw_tp). - A realtime database to store the most recent data in memory (
kxw_rdb). - An intraday historical database to store "today's data" excluding what is stored in the RDB (
kxw_ihdb). - A historical database to store and manage access to data prior to today (
kxw_hdb). - A log replay process that does the writedown to intraday HDB and to the HDB at end of day (
kxw_lr). - A realtime engine (
mon_feed) and analytics to populate the realtime database (In a real system, data would be streaming into the system via one or more feedhandlers coded with C, JAVA, or Python). - Another realtime engine (
mon_agg) and _analytics_to perform data manipulations, in this case, aggregating the average of monitoring data on intervals.
Conventions
As with any software, it's best practice to follow a consistent style. This document uses a combination of kxw and mon prefixes for the entities created. When creating your own entities and packages, it is advised to follow a similar convention.
Some other notes;
- Use a consistent naming convention, e.g. camelCase, under_score
- Use a shared prefix to group entities
- Use group entities for better organisation
- Add comments and descriptions
For general notes on coding style for kdb+, there is a comprehensive document linked.
Build a package
Packages are used to organize a system and make it more portable. When building systems to be shared across multiple environments, place all entities in a package. These packages can then be exported from KX Control and deployed to other systems as we do at the end of this example.
- Click on the Package radio button to switch to Package view in the tree.
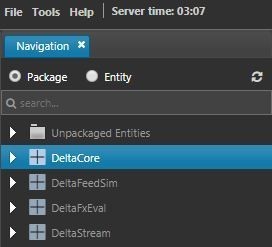
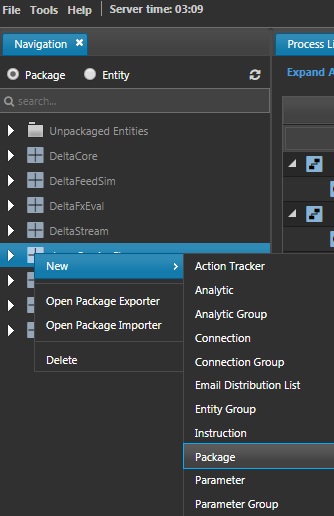
- In the tree, right-click on any entity and select New > Package from the context menu.
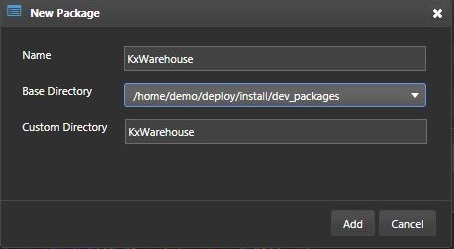
- A dialog will appear. Enter
KxWarehouseas the name of the package. Click Add.
- The package will appear in the tree.