Overview
What does this guide include?
This guide provides a walkthrough of creating a Data Warehouse in KX Stream. It introduces each of the basic components used in the system and some of the core frameworks they're built on. The guide builds a data warehouse from scratch for a sample use-case but steps will be provided for the user to extend for their own applications.
What is a data warehouse?
A data warehouse is system of components for capturing and storing large amounts of data across varying different sources and serving this data to end-clients. Tools are provided to;
- store realtime and historical data
- perform complex enrichment of data streams
- serve the data to end-clients in a consolidated view
A variety of clients can be serviced by a data warehouse through a set of access frameworks; including web and downstream applications, analyst users, reporting tools.
Warehouse architecture
In KX Stream data is typically split by age into distinct time buckets (usually calendar days). Historical data is partitioned by date and stored on-disk. The data for the current bucket uses a hybrid approach of in-memory and on-disk. The most recent data is stored in-memory for fast access with the rest saved on-disk.
This is the described as the intraday writedown approach. The main reason for this is to protect against data volumes outgrowing the available memory, especially when servicing queries and performing end of day (EOD). This approach also uses another process, the log replay, to perform the on-disk writes, which frees up the database components for servicing queries or performing other tasks. The diagram below details the basic architecture.
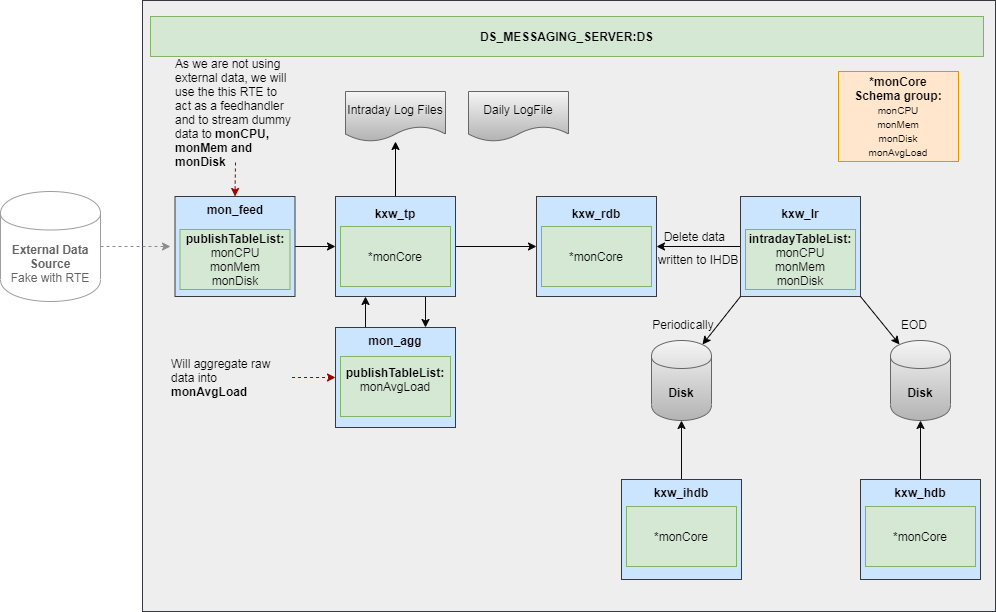
Process templates
KX Stream provides out of the box templates each performing each of the different roles. These templates have hooks that allow the user to customize the behavior as required. The main templates used in this document are;
- Tickerplant (TP): acts as an entry point for streaming data. Logs data streams for failover and distributes to other processes
- Realtime database (RDB): stores realtime data in-memory for fast access
- Intraday database (IHDB): stores intraday data on-disk
- Historical database (HDB): data store for historical data from previous windows
- Log replay (LR): uses the logs generated by the
TPto build the intraday and historical databases - Realtime engine (RTE): cleanses and enriches data streams
Messaging
Since the system will be composed of a set of disparate processes, a framework is required to allow these processes to discover and stream data to each other. The Messaging framework caters for this.
The framework consists of servers and clients. When the clients launch, they register with the server and publish the metadata of what topics they're interested subscribing and/or publishing to.
The server stores this metadata and matches publishers to consumers when an overlap of topics occurs. It initiates a handshake between the processes and sets up a subscription between them.
Note: after the handshake occurs, the clients communicate directly.
Services
In KX Control processes are pre-configured before they are run. The guide defines all processes as service class entities. These provide the ability to run many processes from a single definition. This allows the components of the data warehouse to be scaled elastically in response to system load. The service class documentation goes into detail on the benefits of using this model but in short, it provides much greater scalability and flexibility.