Streaming analytics
Streaming Analytics is a highly configurable subscription-based framework for streaming data to clients in real time. This allows users to visualize and efficiently make decisions on fast data.
Workflow
The main component of the framework is the streaming analytic itself. The client initiates a subscription by invoking this analytic with parameters. This is routed to a target process where it sets up some subscription state. Once this is complete, the client receives an ACK and doesn't need to take any further action other than to process updates. The process then uses that state to publish updates on a timer or event-driven basis. Streaming analytics can be setup with a corresponding snapshot analytic. This generates an initial dataset for the subscription when it is initialized.
The diagram below shows the life-cycle of a streaming analytic. The interface for streaming analytics is from KX Dashboards or KX Connect through the App Server and Query Manager (QM). This is conflated to the QM in the diagram.
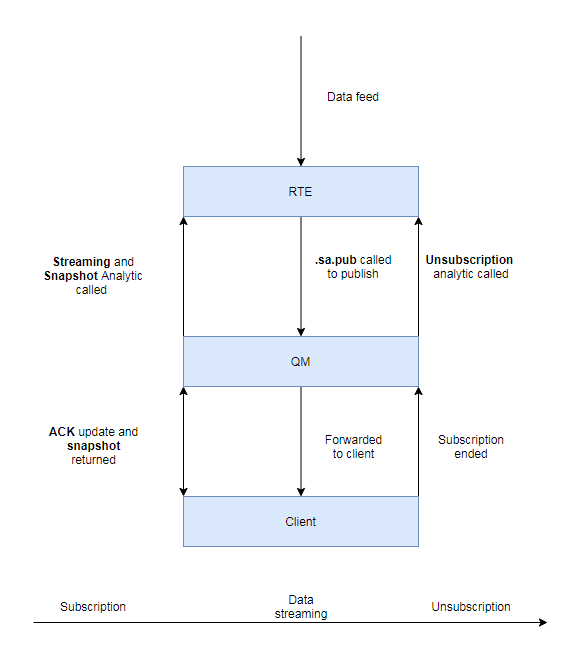
- Client subscribes to a streaming analytic while providing parameters for the subscription
- QM forwards this to the target RTE process where the streaming analytic is invoked, generating subscription state
- The snapshot analytic is run after this and returns the initial dataset
- RTE process then publishes updates for the streaming analytic on a timer or event-driven basis
- When no longer required, the subscription can be ended, which calls the unsubscription analytic on the database
Shared subscriptions
If the same subscription is invoked by multiple clients, the QM will share one subscription across all. Uniqueness is defined by the following components of the subscriptions;
- Analytic name
- Parameters
- Target process
- End-user
When a client is added to an existing subscription, the workflow above is almost identical. The main difference is that the streaming analytic doesn't get called on setup, only the snapshot. Running the snapshot ensures the user can catch up the current state of the subscription.
API
| Function | Parameters | Called By | Description |
|---|---|---|---|
| (Streaming Analytic) | (defined by analytic signature) | QM | Actual name will match analytic name. Must return a user-generated long ID. |
| (Unsubscription Analytic) | uID (long) | QM | Called to remove a subscription |
| (Snapshot Analytic) | uID (long) | QM | Called when subscription initialized to provide an initial dataset |
| .sa.registerfuncs | Streaming Analytic/Subscribe Function (symbol) Unsubscription Analytic (symbol) Snapshot Analytic (symbol) |
User code | Used to register unsubscription and snapshot functions for a given streaming analytic. |
.sa.pub |
uID (long) data (table) |
User code | Called to publish stream data. uID matches ID returned from streaming analytic |
Example
This section details an example implementation of a streaming analytic. The use-case is an RTE consuming monitoring stats with a streaming analytic configured to subscribe to updates by server name (sym column).
Streaming analytic
The streaming analytic code is given below;
// Define the streaming analytic returning user-generated long ID
.monPublic.sub:{[param]
syms:(), param`syms;
.mon.streamingID+:1j;
`.mon.streamingSubs upsert `id`syms!(.mon.streamingID; syms);
.mon.streamingID }
- It takes a dictionary with a single parameter; a list of symbols
- This corresponds to server names
- A unique ID is generated for the subscription
- Subscription added to internal table
- ID returned to framework
Streaming data
Once the subscription state is setup, it's up to the underlying process to decide when to stream the data. This might be event-based, i.e. through a upd function, where incoming data triggers updates published to streaming subscriptions. It could also be triggered on a timer to throttle or aggregate by time. The .sa.pub API is used to publish data to a stream.
The code below shows how a process would use the event-based approach to trigger streaming analytic updates from incoming data. It assumes the upd or realTimeMsgFunct does something like;
upd:{[tab; data]
// ..
if[tab=`monCPU; .mon.pubStreaming[data]]; }
- The subscriptions are stored in a table with the unique ID as the key and the list of syms the user is interested in.
- On receipt of CPU updates from the feed, the
updfunction will call.mon.pubStreaming - Each subscription is processed and the CPU update is filtered on the
symcolumn according to the subscription .sa.pubcalled any resulting data, streaming it to the client via the QM
// Set up subscription ID and state table (with dummy row to ensure correct type)
.mon.streamingSubs:([id:`u#enlist -1j] syms:enlist "s"$())
.mon.streamingID:0j
// Check for streaming subscriptions and filter incoming data for each active one
.mon.pubStreaming:{[data]
toRun:1_ 0!.mon.streamingSubs;
if[not count toRun; :()];
.mon.filter[data] each toRun; };
// Function to select subscribed syms
.mon.filter:{[data; x]
s:x`syms;
w:();
if[count s; w:enlist(in; `sym; enlist s)];
t:?[data; w; 0b; ()];
if[count t; .sa.pub[x`id; t] ]; }
Snapshot
The snapshot concept is powerful where a stream is keyed. In the example so far, CPU data is the subject of the streams. In this case, the data will be keyed by the server name or sym column (ignoring most servers are multi-core). If the client is only interested in the current state, then only the latest by sym is relevant. One approach to this is to send the current state for all servers with every update, however this sends larger datasets with every update, resulting in more processing, rendering etc.
Initial update
| sym | cpu |
|---|---|
| server1 | 10.1 |
| server2 | 12.2 |
| server3 | 9.9 |
.. |
.. |
Server2 updates
The unsubscribe is triggered when a client shuts down the subscription. This removes the subscription state from the target process.
The snapshot concept is powerful where a stream is keyed. In the example so far, CPU data is the subject of the streams. In this case, the data will be keyed by the server name or sym column (ignoring that most servers are multi-core). If the client is only interested in the current state, then only the latest by sym is relevant. One approach to this is to send the current state for all servers with every update, however this sends larger datasets with every update, resulting in more processing, rendering etc.
Initial update:
sym cpu
-------------
server1 10.1
server2 12.2
server3 9.9
..
Server2 updates:
sym cpu
-------------
server1 10.1
server2 14.2
server3 9.9
..
The other approach is to send only what has changed. This is what the example has done to this point. When an update arrives, the data published is only the syms contained in the incoming data. The client should merge this to the existing state for the remaining syms. This is a much more efficient approach as it saves on bandwidth, processing etc.
Current state:
sym cpu
-------------
server1 10.1
server2 12.2
server3 9.9
..
However consider the case where a subscription is initiated after the system is already running. The client will only see the full universe once each sym has updated. To solve this, a snapshot analytic runs to provide the current view of the universe. In this case the snapshot returns the current state table from above.
Snapshots are also used when multiple clients share the same subscription. The framework combines these to a single database subscription. However the late joiners will need to run a snapshot to get up to speed.
// run snapshot for a subscription
.mon.snapshot:{[x]
if[not count s:exec from .mon.streamingSubs where id=x; :() ];
data:0!select from monCPU;
.mon.filter[data; s];
};
Unsubscription
The unsubscription function is triggered when a client shuts down the subscription. This removes the subscription state from the target process.
// remove the subscription for a particular ID
.mon.unsub:{[x]
delete from `.mon.streamingSubs where id=x
};
Initial state function
The snapshot and unsubscription functions need to be associated with the streaming analytic. This should be done on startup of the process in the initialStateFunct
.sa.registerfuncs[`.monPublic.sub; `.mon.unsub; `.mon.snapshot];
Standalone mode
The streaming analytics interface is available in all process instances by default. However it is possible to use it outside KX Control. Processes that want to use it should manually load the streamingapi.q file located in ${DELTACONTROL\_HOME}/shared/q folder.
The existing API are still used to publish data and register subscription handlers. There are two additional points to note.
Disconnection handler
The interface overwrites the kdb+ .z.pc handler in order to manage disconnects from the QM.
- If an existing handler it exists, it will overload it so the existing logic gets run and then
.sa.disconnect. - Otherwise,
.z.pcwill be set to.sa.disconnect
The overwrite behavior can be disabled by setting a global variable called .sa.zpc before loading streamingapi.q.
If disabling the overwrite, call .sa.disconnect directly to clean up handles.
Debug logging
Debug logging can be enabled or disabled.
.sa.log.setDebug[1b] // enable
.sa.log.setDebug[0b] // disable