Overview
The Query Router (QR) framework in KX Control is used to manage client requests and database availability. The goal is to dispatch and load-balance queries efficiently to make the most of available resources.
In large, heavy-usage environments, there is often contention of resources with multiple clients trying to access the same processes. This can lead to long wait times against some processes, while others are idle. The framework aims to minimize such issues by acting as a layer between the clients and databases, managing the load and making more efficient routing decisions.
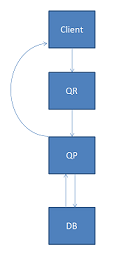
The image above shows the lifecycle of a request.
The framework consists of two main components: the Query Router (QR) and the Query Processor (QP). The QR is the entry point for client requests and performs the routing decisions. It keeps track of database availability for every process registered with it, only ever routing to available ones.
Once a query is ready to be dispatched, it gets assigned to a QP process. The selected QP will send the request to the database and collect the results. Once complete it will send the result back to the client directly. This asymmetric return path means the QR is isolated from the overhead of handling results. All communications in the framework are asynchronous to avoid blocking if a single process gets locked. This includes all communications with end-clients.
By default, the framework is deployed as a single cluster, where this is one set of QR and QP processes. The QRs run in a hot-warm cluster where only the leader handles requests and the rest are available to take over should the leader fail. The QPs are relatively state-less so operate hot-hot. They are assigned requests in a load-balanced manner. The framework can be split into shards to handle increasing loads.
The QRs and QPs are deployed as standard process templates and instances. In their definitions, they provide analytic hooks which allow developers to customize selected behaviors. For the QR, this includes;
- How it dispatches requests: could prioritize certain users or types of requests, but by default, dispatches first in, first out
- Choose what QP to assign to: by default assigns to the least busy
- Decide what routings to apply: used for for routed requests
- How to parse the incoming request: for deciding if routed or not
Request targets
For standard requests, a client is required to know the name of the target they want to execute against. There are a couple of types of targets;
- instances
- connections
- connection groups
- service classes
Instances and connections each correspond to a single process running on a single server. While this is useful for some cases, it lacks in load-balancing and failover, as it requires the client to know of each underlying database. If one fails, the client would need to switch to another.
Connection groups and service classes are groups of multiple processes. The client specifies the name of one of these and the QR assigns the request to an available process in that group according to the configured mode for it.
There are four supported database types and the logic for each is described in the table below.
| Type | Logic |
|---|---|
| Default | Default mode, the Query Router (QR) behaves as a first-available connection selector. It iterates through the list of connections defined in a cluster and attempts to use them in order. For each request, QR tries the first connection in the list. If that connection is available and responsive, it is used to execute the query. If it fails (e.g. connection error or timeout), QR automatically moves to the next connection in the list and retries. This process continues until a working connection is found or all options are exhausted. There is no load balancing or rotation in this mode, each request always starts from the top of the list. The additional connections act purely as failover (backup) rather than being actively used. Summary: Default mode provides simple failover by always selecting the first working connection, without distributing load or combining results. |
| Round Robin | Round Robin mode, the Query Router distributes queries evenly across all available connections in a group. QR maintains an internal counter (index) per database group. For each incoming query, it increments this counter and selects the corresponding connection in the list. Once it reaches the end of the list, it wraps around to the beginning. This ensures that: - Each database is selected in turn - Load is spread evenly across all nodes - No single database is consistently overused Unlike Default mode, Round Robin does not prioritise any specific connection — all are treated equally. If a connection is unavailable, it is skipped, and the rotation continues with the next available node. Summary: Round Robin mode balances load by cycling through all connections sequentially, ensuring even distribution of queries across databases. |
| Leader Cluster | Leader Cluster mode introduces a priority-based approach to connection selection. In this mode, the first connection in the group is treated as the leader (primary node). The Query Router will always attempt to use this leader for query execution. If the leader is unavailable or fails, QR falls back to the next connection in the list, which acts as a replica or secondary node. This fallback process continues in order until a working connection is found. The connections assumes that the ordering of connections defines priority, with the first entry always considered the leader. Summary: Leader Cluster mode prioritises a primary node for all queries and only uses secondary nodes when the leader is unavailable. |
| Combined | Combined connection is fundamentally different from the other connections, as it allows the Query Router to use multiple connections simultaneously. Instead of selecting a single database, QR connects to all relevant databases in the group and executes the query across each of them in parallel. For queries: - Each database returns its own result - QR then aggregates or merges these results into a single final response For subscriptions: - QR establishes multiple underlying (child) subscriptions, one per database - Each child subscription has its own ID - QR creates a parent (combined) subscription ID - Incoming data from all child subscriptions is merged and presented as a single unified stream This mode is essential when: - Data is partitioned across multiple nodes - A complete result requires querying all data sources Summary: Combined connections executes queries across multiple databases in parallel and merges the results, supporting both aggregated queries and unified subscriptions. |
Routed requests
By default, a single request operates on a single underlying database. Routed requests provide the ability to hit multiple databases from a single client request. The QR splits this type of request into one or more sub-requests and processes each of them separately. When all sub-requests complete, the results are aggregated and sent to the client.
Synchronous support
As mentioned before, all communication in the framework is asynchronous in order to prevent blocking and increase concurrency. However not all clients can support asynchronous requests or use a supported client interface so the ability to execute sync requests is provided.
Polling requests
Most requests are single-shot, meaning they're executed once only. For clients that require polling requests, support is provided.
Clients
To execute requests through the framework, a client must use one of the supported interfaces (kdb+, Java and C#). The kdb+ client is available in all kdb+ processes launched from KX Control and full details of the APIs are in the Template API Guide. The Java and C# documentation is bundled with their respective packages.
Upon registering with the framework, the client will automatically register with all QR and QP processes. This process is asynchronous so a callback is provided to execute when complete. The interface supports one-shot or polling queries.
The registration API also allows the client to specify a heartbeat frequency. This will send heartbeats to the leader QR process on a timer to check the process is still responsive, guarding against server or network failures. If a heartbeat timeout occurs, it will disconnect and retry registration with the cluster again.
Enabling clients & databases
A process can interact as a client,database or both with a QR. Any process using the following process templates:(CONTROL_SANDBOX; DC_ARCHIVE; DC_HOUSEKEEPING; DS_ALERT; DS_BRIDGE; DS_DMSERVER; DS_EMAIL;DS_EOD; DS_EXEC_ANALYTIC; DS_FILEWATCHER; DS_LAUNCH; DS_LS;DS_QM; DS_QP; DS_QR; DS_REPLAY;DS_STARTER; DS_TERMINATE_PRCL) don't register as a database with the QR.
To enable a process to register as a database on startup. This mode, .qr.db.enabled should be set to true in the INSTANCE_CONFIG config parameter override/DEFAULT set for the process. Similarly to enable a process to register as a client on startup, .qr.client.enable should be set to true.
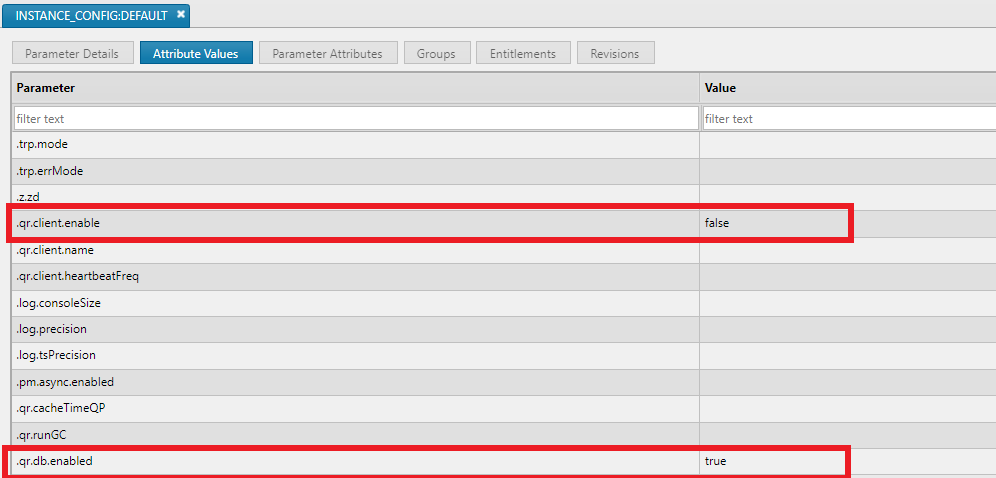
The example below shows how a running process can register as client or database with the QR.
// Check if registered as a database with a QR
.qr.db.enabled
/=> 0b
// Register as a database
.qr.db.enable[];
.qr.db.enabled
/=> 1b
// Check if registered as a client with a QR
.qr.client.isRegistered[];
/=> 0b
// Register as a client
.qr.client.register[`Client1; 10i];
.qr.client.isRegistered[]
/=> 1b
Customizations
The QRs and QPs are deployed as standard process templates and instances. In their definitions, they provide analytic hooks which allow developers to customize selected behaviors. For the QR, this includes;
- How it dispatches requests: could prioritize certain users or types of requests, but by default, dispatches first in, first out
- Choose what QP to assign to: by default assigns to the least busy
- Decide what routings to apply: used for for routed requests
- How to parse the incoming request: for deciding if routed or not
Failover and timeouts
The QR processes run in a hot-warm cluster where multiple run at the same time but only one is designated as leader to handle requests. The rest are available to take over should the leader fail. The QPs are relatively state-less, so operate hot-hot, where every running QP is assigned queries in a load-balanced manner.
Requests will be timed out if they don’t complete within a configured interval. This protects the framework from continuing to target unavailable resources, which can be triggered by events such as server, network or application failures. If the query breaches the timeout threshold, the request will be marked as expired and the client notified.
There are two main reasons a timeout can occur;
- Database too busy to service the request or it takes too long to execute. More often than not this is the cause
- Server or network failure between the components
After a timeout occurs, databases that haven't re-registered as available will be disconnected. This protects further requests from targeting them and forces them to re-register when they're healthy again.
QP heartbeats
QPs can also be the cause of a timeout due to either of the reasons above. To monitor their health, these processes heartbeat to the QR. If the QR doesn't receive heartbeats within a configured period, it will disconnect the QP and remove it from the rotation. This protects further requests from being dispatched to an unavailable QP and causing further timeouts.
The QR heartbeats are enabled by default with a frequency of 30s and a timeout of 45. These values can be changed using the .qr.qpHeartbeatFreq and .qr.qpHeartbeatTimeout instance parameters.
Connection timeouts
QR cluster connection timeouts
For connections between QR processes in a cluster, the hopen timeout and repeat interval can be configured using INSTANCE_CONFIG settings
Enhanced Instance Configuration
| parameter | type | default | description |
|---|---|---|---|
.rpl.reconnFreq |
integer | 10000 | Interval between reconnect attempts (milliseconds) between QR processes in a cluster |
.rpl.openTimeout |
integer | 200 (windows)/1000 (linux) | hopen connection timeout (milliseconds) between QR processes in a cluster |
QP to QR and client to QR/QP connection timeouts
For connections from QPs to QR and from client processes to QR/QPs, the hopen timeout and repeat interval can be configured using INSTANCE_CONFIG settings
Enhanced Instance Configuration
| parameter | type | default | description |
|---|---|---|---|
.qr.reconnFreq |
integer | 1000 | Interval between reconnect attempts (milliseconds) from client to QR/QP and QP to QR when opening connection and when connection dropped |
.qr.openTimeout |
integer | hopen connection timeout (milliseconds) from client to QR/QP and QP to QR when opening connection and when connection dropped |
For QP to QR connections, the default value of .qr.openTimeout is 100ms (windows)/500ms (linux). For client to QR/QP connections, the default value of .qr.openTimeout is 100ms (windows)/1000ms (linux).
Deferred requests
When running a request on a database, the result is expected to be returned to the QP immediately. In some cases, the user might want to defer the result to complete some other tasks, i.e. if not all data is available for the result. In this case, the user would delay returning until the it received the missing data.
A sample workflow might look like this:
- Client sends request to QR
- Request is passed through and executed on the database
- Request code notifies that the result will be deferred until later and awaits for a condition to be met
- When the result is ready, it is passed back to the framework with a correlator ID
- The result is then sent back to the QP and to the original client
The API calls are detailed in the QueryRouter.Deferred module in the Template API guide.
QR leader selection
The QR cluster will decide the leader during the handshaking of the processes with the leader chosen by earliest startup time. The leader will only change if the previous leader becomes unavailable. By default all processes will start as leader and may change status later as handshaking with other processes occurs. This may not always be desirable so the QR can be configured to start as a follower. In this mode the process will wait until it connects to the rest of the cluster or reaches a configured timeout before doing leader selection. This can be set using the .qr.rpl.startupTimeout instance parameter and is defined as an integer number of seconds to wait before performing a selection.
Applications can manually influence the selection process by providing an ordered preference list to direct which one should be elected as leader. This preference list will be shared across the cluster and a failover will be triggered if the preferred process is not currently the leader. Some examples where this is useful:
- Primary database cluster changes and the QR leader needs to be close to the data
- Where the current QR leader is unreliable due to environmental issues
To provide a preference order into the cluster, the .qr.client.setPreferredQRs is provided. The cluster will persist this message for the duration of the session (until all processes are restarted).
procs:`kx_qr_a`kx_qr_b`kx_qr_c`kx_qr_d;
.qr.client.setPreferredQRs[procs; `];
Warning
In previous versions, the QR preference list was published using the .px.rpl APIs but this is now deprecated
Housekeeping
By default the QR will run housekeeping every 60 minutes. This housekeeping removes completed requests by trimming the request and query tables. By default garbage collection isn't performed but this can enabled using the .qr.runGC instance parameter.