Persistence
KX Control stores the state of the system in-memory and persisted to disk. This data is stored to ${DELTADATA_HOME}/DeltaControlData/tdir directory. The persistence and recovery strategy of a single Control process is described in this section.
Persistence
Writing the complete state of a table to disk on every update is not feasible so Control uses a more efficient (and familiar) approach. In-memory tables are periodically written to disk in their entirety by a checkpoint job. However changes occurring between these events also need to be persisted. This is done by using an append-only transaction log. The example below explains in a bit more detail.
- Assuming a checkpoint occurs at 12:00, at that point the on-disk tables contain the complete list of Control data.
- Subsequently over the next two hours, updates to some state occur. These are appended to the transaction log
- At 14:00, an issue occurs that causes the Control process to shutdown unexpectedly
In the above example, changes up to 12:00 are stored in the on-disk tables. Between 12:00 and 14:00, the transaction log contains all of the updates. On restart of the process, it will first load the tables and then replay the log to get back up to speed.
Note: the checkpoint logic clears the transaction log as all changes in it should be captured on-disk at this point.
The checkpoint scheduling is controlled by the dc_housekeeping_tdir_checkpoint.1 task. It can be scheduled to run at an interval or can be run on-demand from the Control UI.
Archiving
In addition to the checkpoint logic, Control will also create backups of the tdir state periodically. This creates a zipped copy of the current state and archives it to the ${DELTADATA_HOME}/DeltaControlData/tdirarchive directory. The scheduling of the job is controlled by the dc_housekeeping_tdir_archive.1 task and can be also be run on-demand.
On a normal shutdown of Control, both the checkpoint and archive tasks will run.
Fault recovery
On start-up, Control loads the tdir state to recover its previous state. However, in some cases this data can become corrupted. If a fault is detected in this on-disk state, by default the process will abort start-up and log the errors detected. This is to ensure the system doesn't start-up in a corrupt state and cause further issues down the line.
In some cases, there is appetite to do a partial recovery and proceed as normal. This behavior can be enabled by adding the below setting to the delta.profile;
DELTACONTROL_FAULTRECOVERY=ON
When Control starts in this mode, it will attempt to load the last "good" state from disk. The recovery is split into two parts; the on-disk tables and the transaction log replay. The following sections describe the workflow when recovering from a fault.
Table recovery
Control will proceed with the fault recovery algorithm if the tdir status is corrupt. There are two main ways this can occur;
- One or more of the on-disk tables are corrupt and can't be loaded into memory.
- Not all of the tables were written to disk.
In order to protect against the latter case, Control creates an on-disk table to track the status of the checkpoint. It writes a tdirStatus table to the tdir with a row for each table and a Boolean for the write status. When beginning the checkpoint it sets the status to false for each table and updates each to true as they are written. On start-up, it will check that all table statuses are set to true and if not, it will initiate the fault recovery.
With the former case where one or more tables are corrupt, it attempts to load each one and switches to fault recovery mode if any of them fail.
If one of the above conditions is met, the fault recovery logic tries to recover from one of the tdirarchive backups. The workflow is described in the image below.
Note: When recovering from a backup, the current, corrupt state will be backed-up to a temporary location where it can be investigated. The location will be indicated in the process logging.
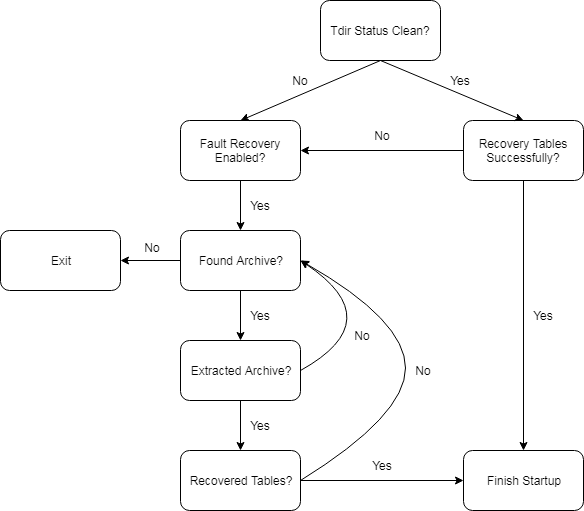
After loading the on-disk table state, either cleanly or from the archive, the transaction log will be replayed. If recovering from a backup, the replayed log will be the one from the backup.
Transaction log replay
The screenshot below details the steps taken if a corrupt transaction log is encountered.
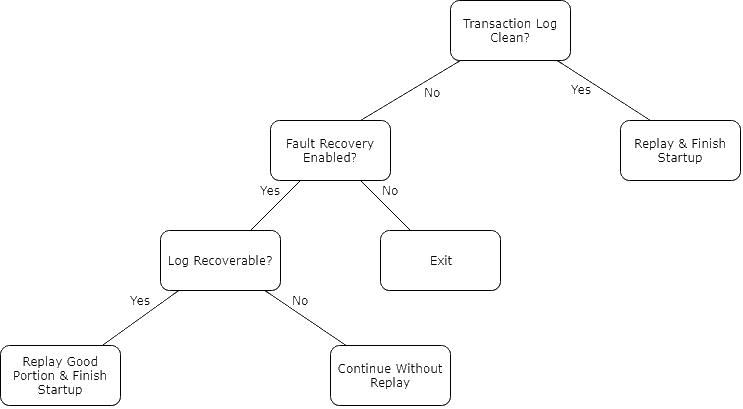
The log can be corrupted in two ways;
- The entire file is corrupt and unreadable
- Some portion of the file can be replayed
As before, by default, the fault recovery will only take affect with DELTACONTROL_FAULTRECOVERY enabled. In the former case, the transaction log will be replaced with an empty log. Any data living in the log will be lost. In the latter case, a portion of the file is recoverable. This "good" portion will be replayed and the rest of the file will be lost.
In both cases, the corrupt transaction log will be backed-up to a temporary location for further investigation.