Service Deployments
As of release 4.7.0, KX Delta Platform provides support for bulk operations when starting and stopping service classes. Prior to having services, applications defined their system as a set of workflows they configured and ran. Services don't fit with the workflow concept, instead a file-based approach is used.
File-based
The approach is to define the workflow-like system as a set of two JSON files, deployment and overlay. These contain groupings of service class definitions, similar to the Kubernetes deployment files. They consist of a set of service class names and associated parameters.
The deployment and overlay files are identified by appending on the .deployment.json and .overlay.json respectively. Control only scans the ${DELTA_CONFIG}/ directory for both files.
Control doesn’t load the actual deployment definition
It parses the file on-demand. This provides a future path for implementing the orchestration outside of Control.
Single definition
A single deployment file can be used to launch nodes across multiple servers. The file allows a number of replicas to be specified for each class, e.g. run two duplicate RDBs as part of the same node for query load balancing.
Separation of concerns One of the key requirements is to separate the runtime definition from the environment configuration. This was not well handled with instances/workflows where either environment variables or duplicating of instances was required.
As described above, the development team release a package with deployment files defining which services should run as part of a node. However this package will be deployed to multiple environments, likely with different server environments. Core affinities, port ranges, etc may need to be tuned for each environment.
Deployment file
The deployment file is specified as JSON which allows greater flexibility in terms of format (over csv or other tabular forms) and takes advantage of the in-built kdb+ JSON APIs.
An example solution has a simple data capture system consisting of TP, RDB, and HDB. These processes will be released as service class entities in the solution package. However in each environment the package is deployed to, there may be different requirements e.g. : * Run single RDBs and HDBs in dev but two replicas in production * Differing numbers of followers * Core affinities
An example deployment file:
$ cat fx_capture.deployment.json
[
{
"class": "__metadata__",
"version": "4.6.0",
"descr": "FX data capture deployment file"
},
{
"class": "__defaults__",
"dc_portrange": "6100-6200",
"dc_taskset": "2-3",
"dc_ispermissioned": "yes"
},
{
"class": "fx_tp",
"dc_portrange": "6300-6400",
"dc_taskset": "1",
"dc_ispermissioned": "no",
"publishChannel": "fx_tp_1"
},
{
"class": "fx_rdb",
"replicas": "2",
"subscriptionChannel": "fx_tp_1"
},
{
"class": "fx_hdb",
"replicas": "2",
"dc_secondaries": "4",
"directory": "ENV=FXDATA=/hdblog1"
}
]
- The first section describes defaults to be used across all processes unless they have a specific value set.
- The next section is the list of service class names, number of replicas and any parameter overrides
- This example produces a node of 2 RDBs, 2 HDBs and 1 TP (default number of replicas is 1 if not specified).
- For performance reasons, TP requires its own core and permissions disabled so it overrides the global defaults
- Services can define port ranges to run on. At runtime, they’ll bind to a free port in that range.
Overlay files
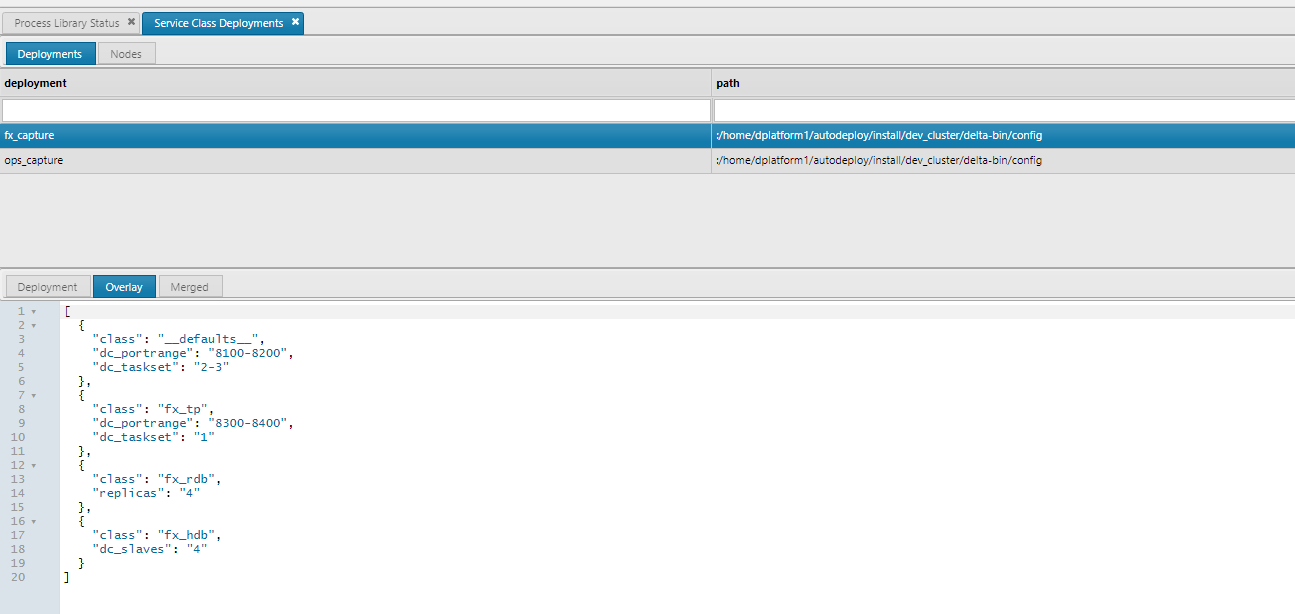
These files have the same schema and available parameters as the deployment files. When a request to get the deployment definition is made, both files are combined with a union of the parameters. This allows single RDBs and HDBs in the development environment, but multiple replicas in production environment.
Deployment
{
"dc_portrange": "6300-6400",
"publishChannel": "fx_tp_1"
}
Overlay
{
"dc_portrange": "7400-7500",
"dc_taskset": "1-2"
}
Result
{
"dc_portrange": "7400-7500",
"publishChannel": "fx_tp_1",
"dc_taskset": "1-2"
}
Service Class Deployment Editor
The Service Class Deployment Editor interface in KX Control allows the user to view , stop & start services. The deployment tab allows the user to view the meta data from the deployment and overlay files. Along with viewing the merged result. To open the window Pick Service Class Deployments from the Tools > Open Viewer menu.
-
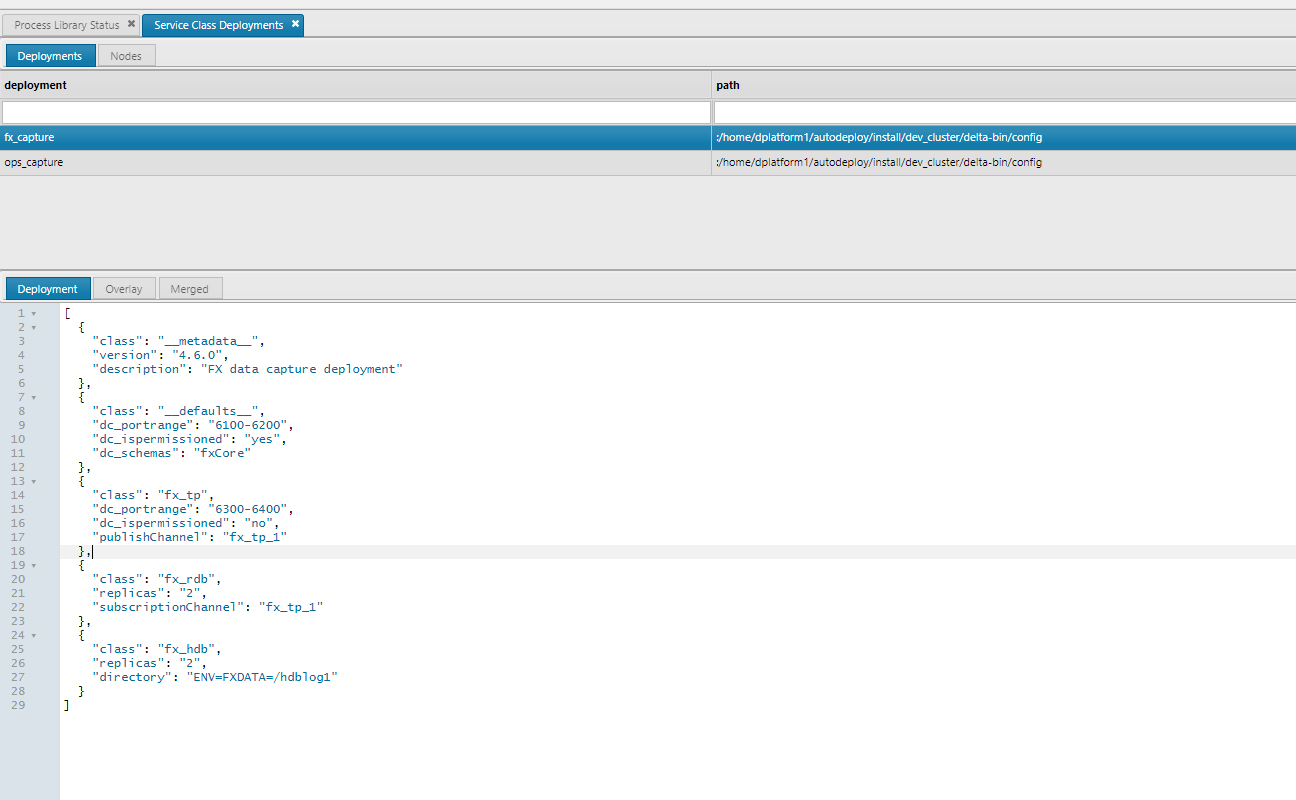
Select a deployment name to view deployment description
-
View the JSON data and ensure it is correct for both deployment and overlay files
-
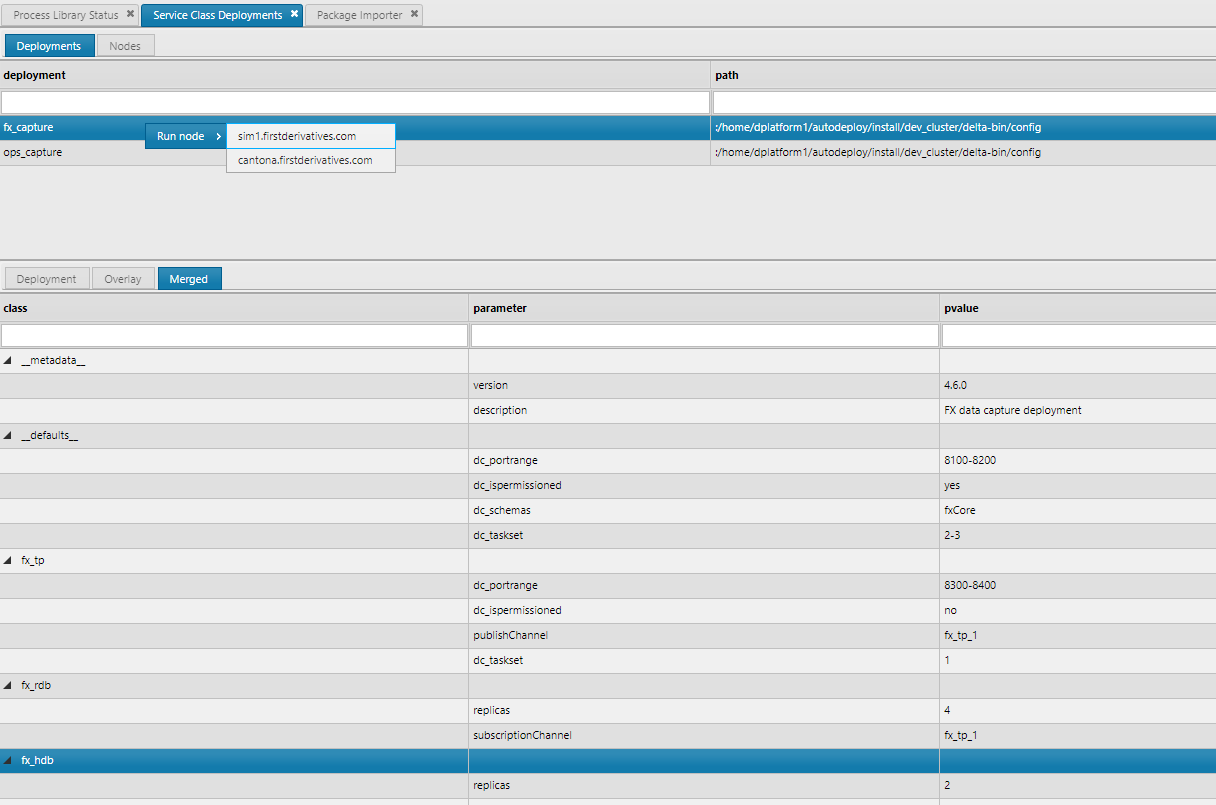
Expand the tabular view for the merged table results. Right click on a deployment name to select the list of possible hosts to startup the services on.
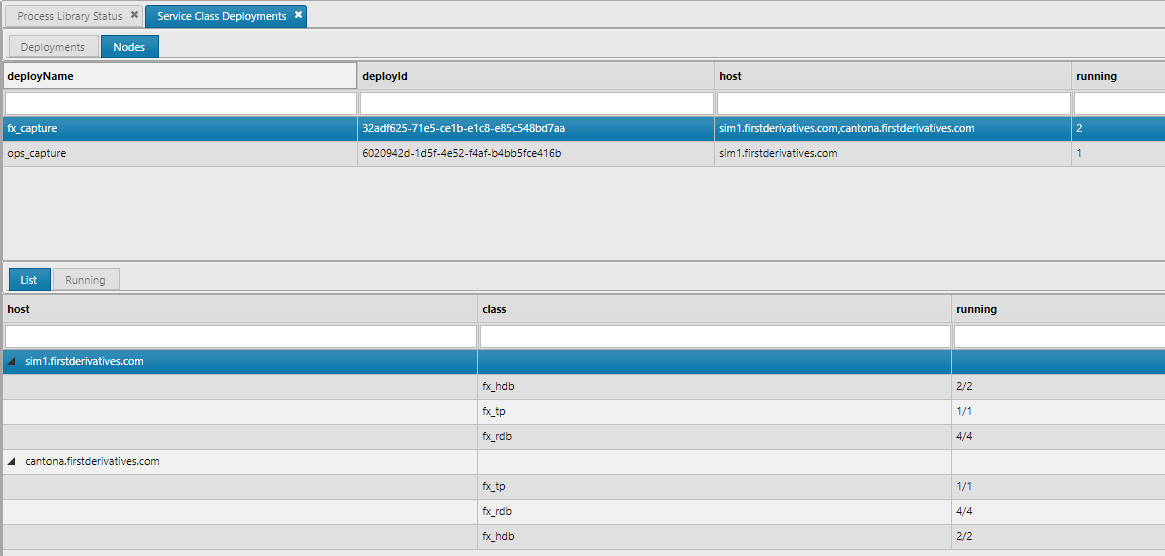
Running Nodes
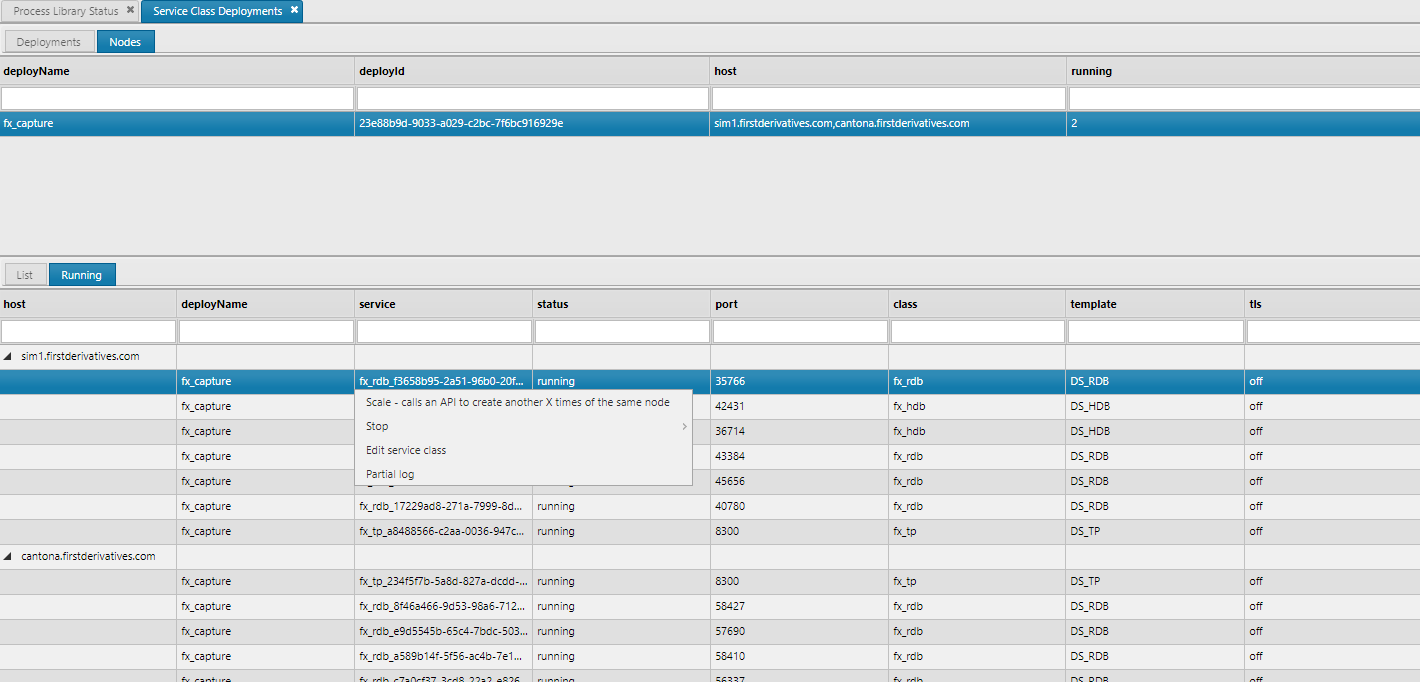
The Node tab view shows list of nodes for which each deployment is running on. Also in the List view it gives a simple breakdown of the selected deployment and the number of running services for each class.
Scaling
The Running view gives a more detailed breakdown of each service running per node. These details are similar to the Process Library Status viewer. Right click on a running service and the option to _scale, stop , start _ appear. The ability to scale a node means scaling the number of services in the node to deal with a changing load. The service being scaled will use the exact same parameters provided in the merged deployment files.