Realtime aggregation
So far there are three data streams of monitoring statistics. Let's say a consumer (user dashboard, reporting application etc) needed a realtime, consolidated view of server health. One option is to query the databases periodically and join the three tables on the fly. This will work initially but will get increasingly expensive as data volume grows. In contrast, a streaming, realtime aggregation approach is much more computationally efficient and simplifies things for the consumer.
Instead of aggregating data across the three database types, an RTE subscriber will be created to consume the raw streams and build the aggregated state in realtime. In this example, the aggregated view is computed as the average load per one minute time window. At the end of the minute window, the aggregated stream is published downstream. This is just one approach; the time window could be narrowed or the data could be simply joined and published with no aggregation window.
Code
Create an instruction
- Create an instruction to define the subscriber logic.
- Right-click Analytics Library and select New Instruction.
- Name the instruction
.mon.aggLogic. - In the Instruction Details subtab, give it a description. For example, Logic to aggregate and publish data.
- In the Content subtab, copy and paste the code from the appendix. Again, it will be easier to write code if a connection is made to a running process.
Briefly, it does the following;
-
Contains an initialization function
.mon.initAggTablesto create three internal aggregation tables. These tables will be used to track the usage within a time window. -
Define callback functions for each of the three data streams. Each callback is associated with the corresponding table;
.mon.updAvgCPU,.mon.updAvgMem, and.mon.updAvgDisk. Here, we take the sum and count of the incoming data by sym, and append the values to the aggregated tables defined above. -
Add callback functions by using the
.dm.addCallbackfunction. Pass two parameters: table name and the function to call back. For every update the table receives, the function set in the second parameter is called. -
Define a function
.mon.updAvgto aggregate, join and publish data to the monAvgLoad table. -
Set a timer using
.d.prcl.addFunctToTimerto call the.mon.updAvgfunction every minute.
Table callbacks
The ability to specify function callbacks against a table is available in subscribers. Each table can have one or more functions to be executed whenever an update is received.
The standard model would be to;
- setup the table to function(s) callbacks on process startup.
- apply the callbacks whenever a new message is received to the
updorrealTimeMsgFunct.
This allows multiple instances to share one generic upd function but specify different callbacks per process.
A general example of the API calls is provided below.
callback:{[t;x] 0N!(t;x) };
monMem:([] time:.z.p; sym:`A`B; usage:10 20)
// add a callback
.dm.addCallback[`monMem; `callback];
// execute callbacks
.dm.applyCallbacks[`monMem; monMem];
/=> (`monMem;+`time`sym`usage!(2018.08.06D05:42:44.188299000 2018.08.06D05:42:44.188299000;`A`B;10 20f))
-
Create a callback analytic
.kxw.updCallbacks -
Set the parameters.

- Set the contents as below:
{[tab;data]
.dm.applyCallbacks[tab; data];
}
Create an init function
Now that there is the code to publish aggregated data, create an analytic to load the code. We will later set this to the parameter of the RTE so it will be called once at start up.
- Create an analytic
.mon.initAgg. - Use the code below in the Content tab.
// load instruction
.al.loadinstruction[`.mon.aggLogic];
// initialize aggregated tables
.mon.initAggTables[];
The actual analytics of aggregating and publishing data resides in the .mon.aggLogic instruction.
Create a RTE
- Create a RTE process. Name it
mon_aggand set the template toDS_RTE. - Add a description.
- Configure the Service Parameters.
| parameter | value |
|---|---|
| messagingServer | DS_MESSAGING_SERVER:DS |
| subscriptionChannel | kxw_tp |
| subscriptionTableList | monCPU, monMem, monDisk |
| publishChannel | |
| publishTableList | monAvgLoad |
| initialStateFunct | .mon.initAgg |
| realTimeMsgFunct | .kxw.updCallbacks |
- In the Schemas subtab, associate the
monCoregroup. - Save the service class.
Realtime aggregation
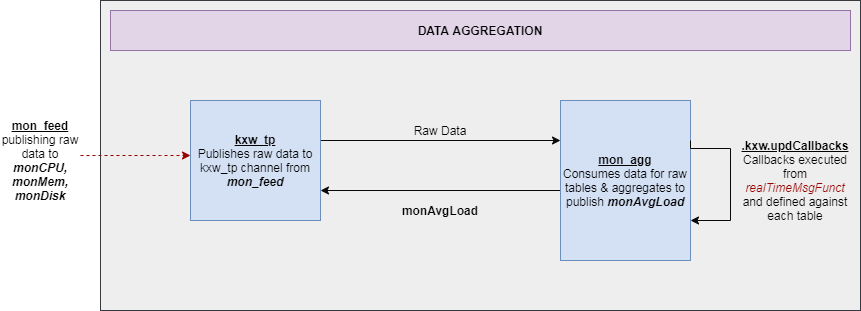
The diagram below shows the flow of data from the realtime feed(mon_feed), to the Tickerplant(kxw_tp) then to the Aggregation Engine(mon_agg).
Testing the analytics
-
Next, run this process to ensure that data it's working correctly.
-
To test this, make sure that the following processes are running:
ds_ms_a,kxw_tp,kxw_rdb,mon_feed,mon_agg. -
Now, open an IDE on the
mon_aggandkxw_rdbservice classes. Right-click on themon_aggin the Process Library Status and select Connect. Do the same forkxw_rdb. It will open an KX Analyst session. -
Next, see if the aggregated tables have data.
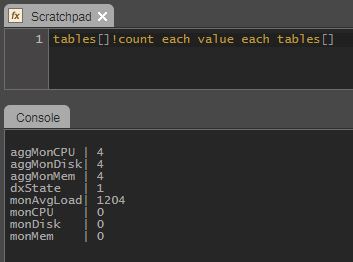
-
If everything is working properly, the
.dm.pubfunction inside the.mon.aggLogicinstruction should publish the aggregated data to themonAvgLoadtable. The RDB should be receiving this data stream and storing. -
In the
kxw_rdbAnalyst session, see if data is in the aggregation table. TypemonAvgLoadinto a scratchpad and display the results in the Console.
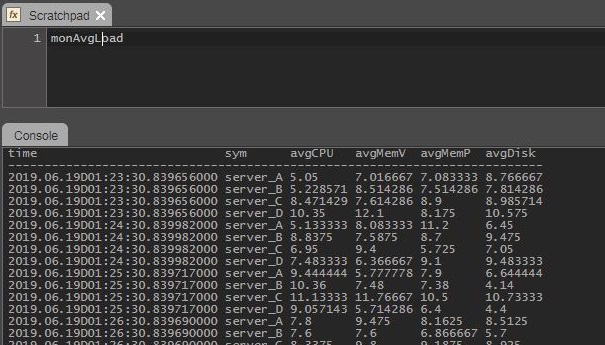
You now should have an RTE that aggregates realtime data and publishes a stream of aggregated data.