Schema
A schema transforms ingested data to a format compatible with kdb+ datatypes of the destination database on kdb Insights Enterprise. Schemas are used in pipelines and during data import, and are associated with Assemblies. Schemas can be created independently or as part of the data assembly wizard builder. Free Trial users already have table schemas defined for the sample data sets used by insights-demo; simply deploy the insights-demo assembly to make use of them.
A schema is made up of one or more tables. The table schema of kdb Insights Enterprise has a defined structure, but each table in a schema must have at least one data column and a timestamp column for data partitioning.
A schema consists of a table name, a list of data columns of defined kdb+ types, and a defined partitioned timestamp column
Tables can be added or removed from a schema, but schemas can only be changed when the associated Assembly is torn down (from the Overview page or right-click the assembly in the entity-tree) and associated resources generated by the deployed assembly are cleaned (this will be prompted during Teardown).
Video Tutorial
Set up
-
Click the [+] next to the Schema option in the left-hand entity tree.
-
Name the schema
-
Start by renaming the table from the default
table1, or add a new table with (+). -
To the table add data columns corresponding to ingested data; define the name and kdb type for each column of data to be converted; a column description is optional. A
Timestampdata column must be included in the table. Some of the more common kdb types for ingested data include:item column type time column Date, Datetime, Time, Timestamp category (independent data) Symbol, String numeric (dependent data) Float, Integer -
Define Table properties; i.e. the
Partitionand requiredTimestampcolumn from the data. Optional is to set the data sort. This can be done for interval, real-time and historical data; typically a sort is done using the aforementionedTimestampcolumn. -
Click

Code View
Code view allows users to define schemas using JSON. Schemas built using the code editor must conform with the requirements outlined in the set up.

A JSON schema code editor view
The code editor will do a validation check, preventing submission of invalid code. Details of error(s) will appear on a hover-over of the underlined problem in the code. In addition, when editing a property, a pop-up of supported attributes will be offered:
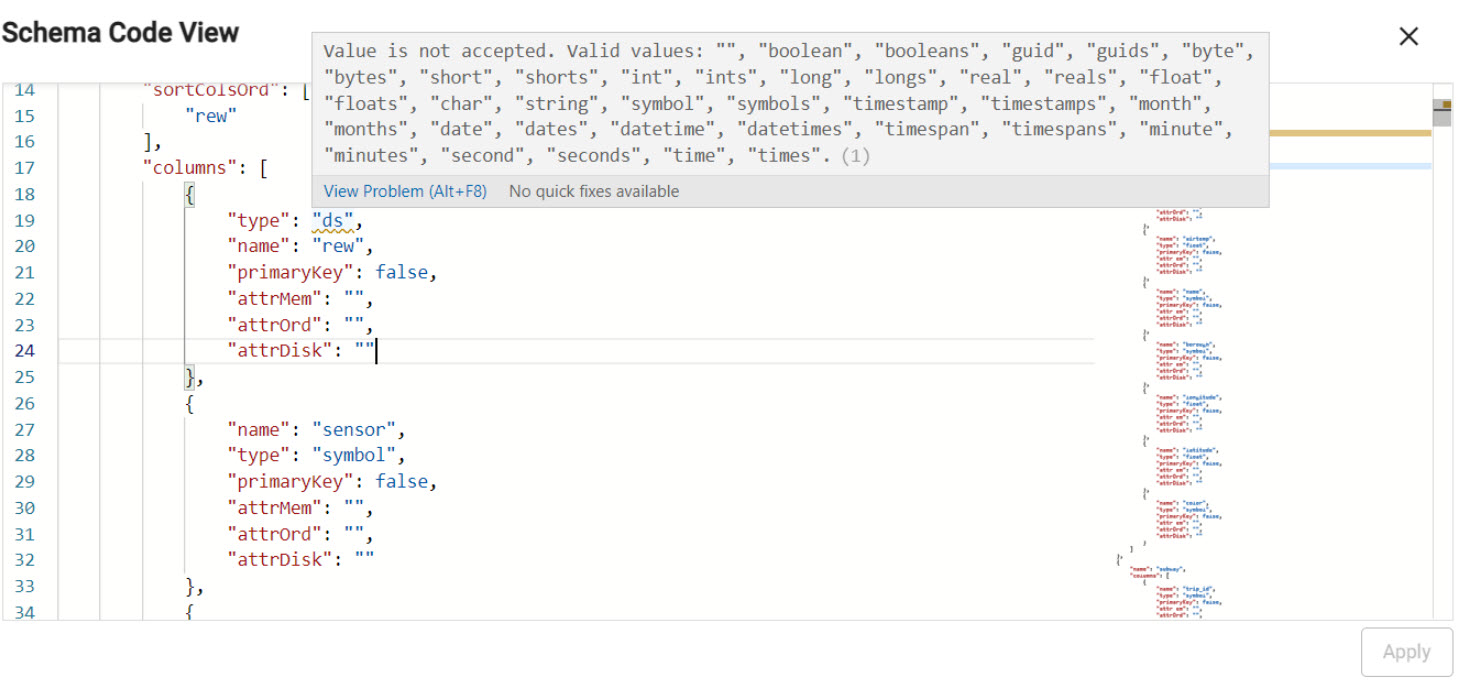
Suggested JSON attributes for selected schema property.
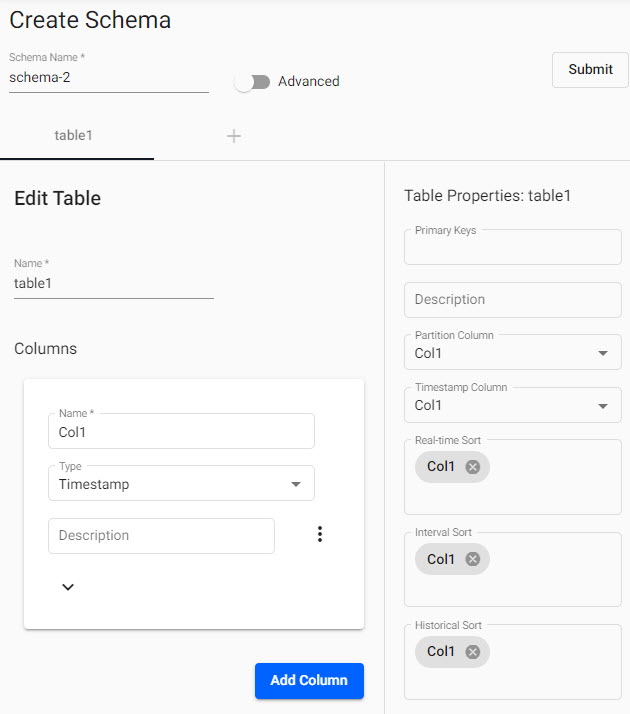
Create Schema
Give the schema a name before adding data columns.
| item | description |
|---|---|
| Schema Name | Name the schema to be created |
| Advanced | Toggle additional properties for the schema if required. Note, all schemas are of type Partitioned under Advanced settings. |
| Code View | Opens a JSON editor for an alternative method to build table schemas. |
| Submit | Submit a completed schema |
Edit Table
Give the table a name, this will appear in the tab menu; avoid using reserved keywords for SQL or q ; e.g. table as this will return an error when queried. To add a new table, click [+].
Details of the first column can be edited inside the table, additional columns can be added with the  button.
button.
Schemas are a collection of separate tables; add a table by clicking the plus sign, then give it a name
To remove a column, click on the  and select delete. From the latter menu it's also possible to duplicate a column.
and select delete. From the latter menu it's also possible to duplicate a column.
Columns can be repositioned on click-and-drag.
Select the expander for additional properties: Primary Key, On-Disk Attributes and Foreign. Expanded properties are marked by a * in the table item list below:
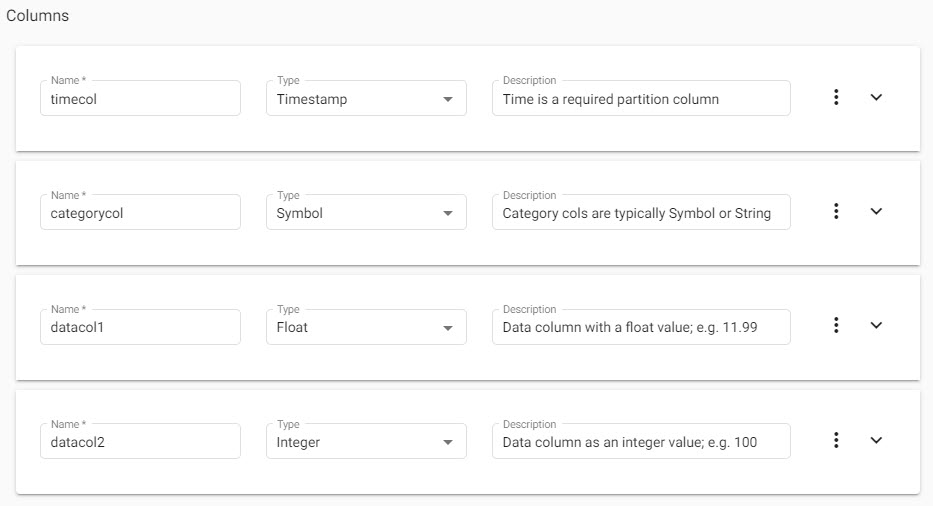
Sample columns to add to a schema table and suggested Types for each of the common data types.
| item | description |
|---|---|
| Name | Assign a name to the column in the table. |
| Type | Select the kdb+ datatype conversion for the data column; any, boolean, booleans, byte, bytes, char, date, dates, datetime, datetimes, float, floats, guid, guids, integer, integers, long, longs, minute, minutes, real, reals, second, seconds, short, shorts, string, symbol, symbolds, time, times, timespan, timespans, timestamp, or timestamps. For more on selecting the correct kdb+ types for your data refer to this key . |
| Description | Optional description of the column purpose. |
| Primary Key* | Check if a Primary Key column. |
| On-Disk Attribute (Ordinal Partitioning)* | Column attribute when stored on disk. Select from None, Sorted, Grouped, Parted and Unique. |
| On-Disk Attribute (Temporal Partitioning)* | Column attribute when stored on disk with an ordinal partition scheme. Select from None, Sorted, Grouped, Parted and Unique. |
| Foreign* | A foreign key into another table of the assembly, of the form tablename.columnname. |
All Tables Require a Timestamp Partition Column
Each table of a schema have a time data column. In addition, the table is typically partitioned and sorted (interval, historic and/or real-time) by this time column. See table properties
Table naming
Avoid using reserved keywords for SQL or q when naming tables as this can return an error.
Table Properties
Every table in a schema has a set of properties. Every table of a schema must have a column defined for the Timestamp Column and the Partition Column. Advanced schema properties are marked by an * in the table item list.
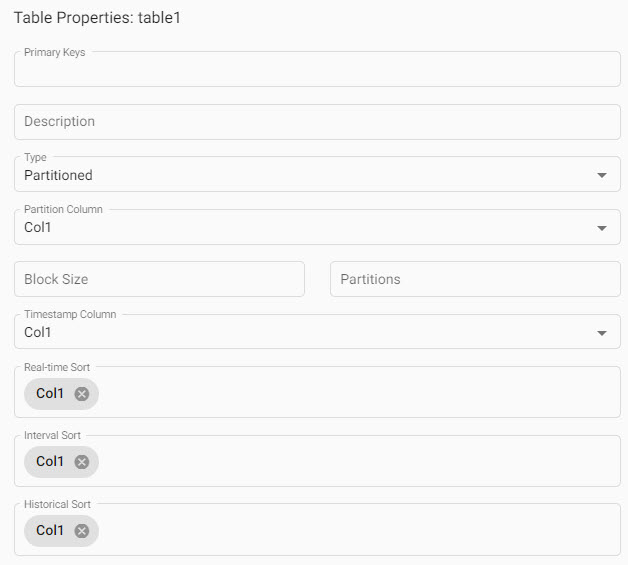
Table properties which includes a partition column that must be a timestamp, a defined timestamp column, and optional sort columns for each RDB, IDB and HDB tier.
| item | description |
|---|---|
| Primary Keys | A list of primary key column names. |
| Description | Description of the table purpose. |
| Type* | Select between splayed or partitioned; defaults to partitioned. |
| Partition Column | Select from dropdown options; defaults to Col1, although Col1 or the selected column must be of type Timestamp |
| Partitions* | Set number of partitions; an integer |
| Block Size* | Define number of records to keep in memory before writing to disk; an integer |
| Timestamp Column (required) | Select from dropdown options; defaults to Col1. |
| Real-time Sort | Real-time (rdb) data sort column; defaults to Col1. |
| Interval Sort | Interval (idb) data sort column; defaults to Col1. |
| Historical Sort | Historical (hdb) data sort column; defaults to Col1. |