Reliable Transport (RT) Overview
RT is a microarchitecture used within kdb Insights Enterprise for ensuring the reliable streaming of messages. It is designed to satisfy both high availability and high performance requirements.
RT uses a sequencer and replication strategy to ensure that messages are moved as quickly as possible between publishers and subscribers. Its basic operation consists of the following steps:
-
Publishers use one of the available kdb Insights SDKs to write events to a session file on local disk (think of writing a tickerplant log).
-
The session file is replicated between publisher and subscribers.
-
If multiple publishers are writing to the same stream, they are merged into a single unified and ordered stream file by the sequencer.
-
Subscribers within kdb Insights Enterprise such as the Stream Processor and Storage Manager consume the transaction stream file once it has been replicated and merged.
Note
Multiple subscribers can consume the stream file and there is no requirement for them to do so within a certain time frame (i.e. they don't have to "keep up" with the publisher).
This results in full decoupling of publishers and subscribers (i.e. publishers don't have to deal with slow subscribers).
RT vs tick
RT is similar to tick, but it also provides the following benefits:
-
Configurable High Availability (however there is always a HA/throughput tradeoff).
-
Slow subscribers cannot affect the publisher.
Definitions
-
stream - this is synonymous with an instance of RT, whether it is a 1,3,5,7... node RT implementation. All the messages sent to the stream are replicated, merged and sequenced before being passed to the consumers.
-
stream id - identifies a stream in a kdb Insights Enterprise deployment. Since there can be multiple Streams in a kdb Insights Enterprise , the stream id (currently known in the UI as a Sub Topic) is used by external publishers to identify the stream to send data to.
-
session is the identifier used for the set of messages sent to the Stream by a single publisher, or set of publishers on different hosts if you wish to deduplicate the messages. Each session is physically representated as an
indirectory. The messages from these sessions are then merged to a single output stream (outdirectory) which is read by all subscribers. -
publisher: the publisher pushes messages to one or more streams.
Publishers must use unique session names
Each publisher on a given host MUST use a different session name to provide a unique directory name for the stream files before they are merged.
-
subscriber: The consumer of messages.
Components
We will now look at the various components that make up the RT micro architecture:
- Replicators: continuously, rapidly, and securely transport a stream file directory from one machine to another.
- Sequencers: read from multiple stream file directories and produce a single merged directory that can itself be consumed.
- Archiver: drives the garbage collection of all merged logs.
This diagram shows RT being used in a 3-node RAFT configuration as using in kdb Insights Enterprise.
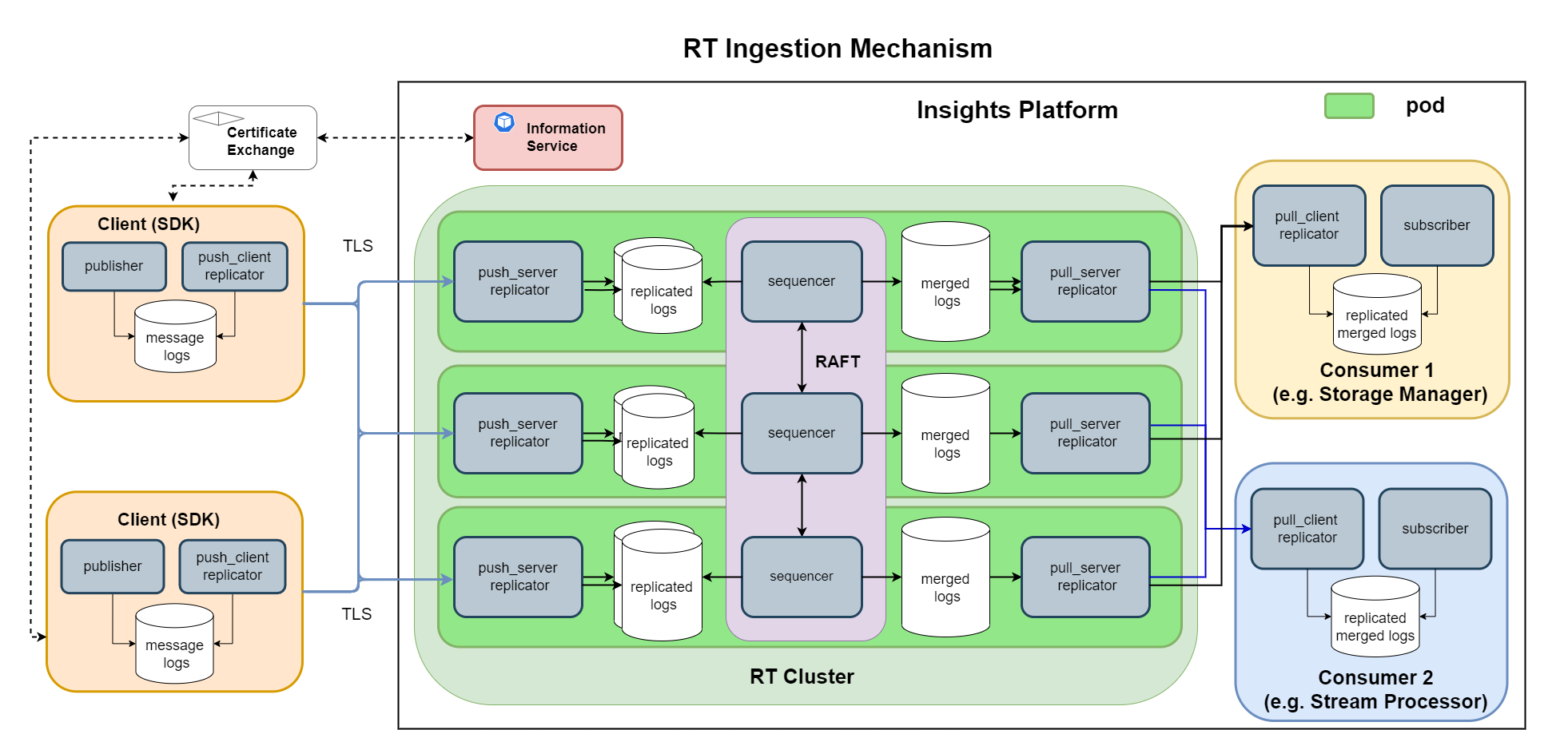
Replicators
The replicator's job is to transport messages from one machine to another and each replicator is made up of a client and a server.
For ingestion each of the client SDKs include a push_client replicator, which sends the messages to the push_server replicator, which receives the messages.
Replicators have the following characteristics:
-
Keep track of the restart position on the consumer side, not the publisher side, for zero data loss/gaps. The consumer initiates recovery i.e. it knows the "position" to restart from, but the producer opens the (TCP) connections.
-
Use inotify() to detect data with low latency.
-
Use mutually authenticated TLS to encrypt traffic across network boundaries.
-
Support topologies where either the producer or consumer can have a fixed address.
-
The replicator is expected to run indefinitely.
Sequencers
Combining more than one stream file into a single output is the responsibility of a sequencer. The sequencer is entirely deterministic: it chooses a sequence of events from any number of input stream directories and combines them into a plausible order in another directory.
The sequencer uses RAFT, which is suitable for ⅗/7-node topologies, and has the advantage that as long as the majority of nodes are up (a quorum) the output stream file can be constructed and delivered to the consumers. This means that RT can continue to run even if up to half the RAFT nodes stop running.
The RAFT sequencer nodes work together as follows:
- Using the RAFT algorithm, the sequencers form a cluster and elect a leader.
- The cluster nodes communicate with the leader about how much of each published stream file they have replicated (locally to themselves).
- Using the above information, the leader determines what new information can be appended to the merged file. It publishes this back to the follower nodes as a merge instruction.
- Using the publisher files (which the nodes have gotten externally to the RAFT process) and merging those files into a single file using the instructions supplied by the RAFT leader.
- Since all sequencers have the same files and merge them using the same instruction set, then all of the merged files output by the various sequencers will be identical.
- Using the rules set out by RAFT, if a leader fails, a new leader will be elected. In this way up to half the nodes can fail before the cluster as a whole stops functioning.
Once a merged file has been appended to, a pull replicator replicates the merged file for a subscriber to consume.
Archiver
The RT Archiver runs as part of the sequencer and drives the garbage collection of all merged logs - those in RT and other subscribers - based on a configurable policy. This policy can specify:
- Retention period for merged RT log files in minutes. Rolled merged log files which contain messages older than this (based on the message timestamp) are garbage collected.
- Maximum size of all log files in RT. Rolled merged log files which push the total size beyond this limit are garbage collected, oldest first.
- Maximum percentage of the available disk space that will be used by RT. When this percentage is exceeded rolled merged log files are garbage collected, oldest first. If not configured the default value of 90% is used.
When a log file on the sequencer is marked for garbage collection, this information is propagated to the subscribers such that the log files are also garbage collected there.
When pruning, the following additional constraints exist:
- The newest stream file is never pruned.
- Stream files roll every 1GB (or every session, whichever comes first).
- The time considered is only the first timestamp in a stream file, so some time beyond the expiration can actually pass before the stream file is pruned. I.e. it must roll first.
Minimum disk size
The size of the disk associated with each RT and consumer pod MUST be larger than the limit defined.
Note
These archival options can be defined as part of the kdb Insights Configuration.
Stream files
Each publisher and subscriber writes and reads from a set of RT stream log files in a directory.
Publishers and subscribers specify a 64 bit position in the stream when writing or reading from it. That position first identifies the log file which contains that message, with RT log files being named as log.x.y where:
- x is the top 20 bits of the position
- y is the next 14 bits of the position
The remaining 30 bits then locate the start of the message in the correct log file. Therefore, each log file has a maximum size of 1GB before automatically rolling to the next log file.