Writers
Choose from the list of available writers listed below.
- Click to edit node. When a node is clicked, the property panel to the right will be editable.
- Right-click to rename a node, remove (delete) or duplicate a node. A duplicated node will copy the details of the node, including any defined properties in the original node. The duplicated node will have a
-nnumeric tag in the name.
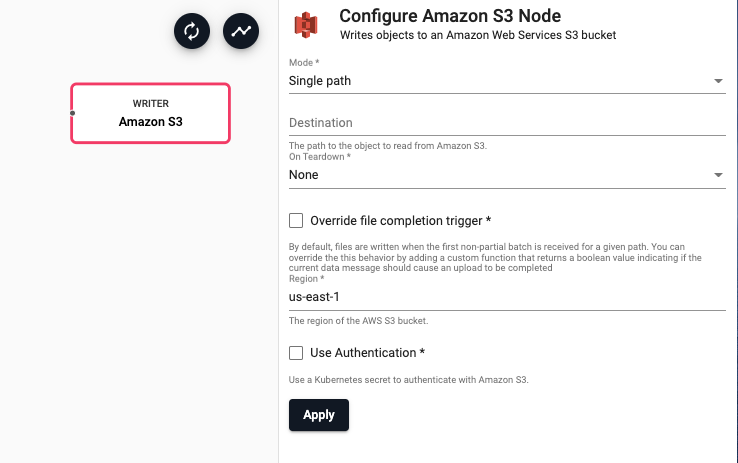
Amazon S3
Writes data to an object in an Amazon S3 bucket
See APIs for more details
q API: .qsp.write.toAmazonS3 •
Python API: kxi.sp.write.to_amazon_s3
Required Parameters:
| name | description | default |
|---|---|---|
| Mode | Indicates if this writer should write to a single file path or if it should use a function to derive a function path from the data in the stream | Single path |
| Destination | If 'Single path' is selected, the destination is the path of the object to write to in Amazon S3. If 'Dynamic path' is selected, destination is a function that accepts the current batch of data and returns a string of the object path in S3 to save data to | |
| On Teardown | Indicates the desired behavior for any pending data when the pipeline is torn down. The pipeline can perform no action ('None') and continue to buffer data until the pipeline starts again. This is recommended for most use cases. Alternatively, the pipeline can be set to 'Abort' any partial uploads. Or the pipeline can be set to 'Complete' any partial uploads. | None |
Optional Parameters:
| name | description | default |
|---|---|---|
| Override file completion trigger | When selected, an 'Is Complete' function is required to be provided. This allows the completion behavior for partial data to be customized | No |
| Is Complete | A function that accepts metadata and data and returns a boolean indicating if after processing this batch of data that all partial data should be completed. |
|
| Region | The AWS region of the bucket to authenticate against | us-east-1 |
| Use Authentication | Enable Kubernetes secret authentication. | No |
| Kubernetes Secret* | The name of a Kubernetes secret to authenticate with Azure Cloud Storage. |
* If Use Authentication is enabled.
Amazon S3 Authentication
To access private buckets or files, a Kubernetes secret needs to be created that contains valid AWS credentials. This secret needs to be created in the same namespace as the kdb Insights Enterprise install. The name of that secret is then used in the Kubernetes Secret field when configuring the reader.
To create a Kubernetes secret containing AWS credentials:
kubectl create secret generic --from-file=credentials=<path/to/.aws/credentials> <secret-name>
Where <path/to/.aws/credentials> is the path to an AWS credentials file, and <secret-name> is the name of the Kubernetes secret to create.
Note that this only needs to be done once, and each subsequent usage of the Amazon S3 reader can re-use the same Kubernetes secret.
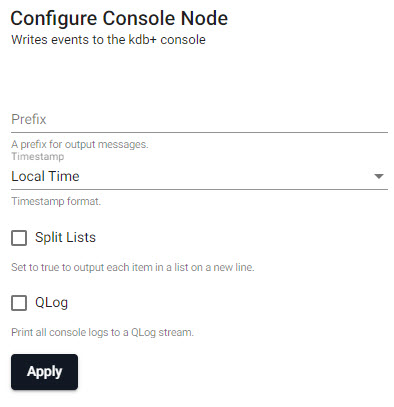
Console
Writes events to the kdb+ console. Can be used for simple streams running on a local deployment. By default, all vectors (lists of the same type) are printed on a single line. By enabling the Split Lists option, vectors will be printed on separate lines. Lists of mixed type are always printed on separate lines.
| item | description |
|---|---|
| Prefix | A string for output messages. |
| Timestamp | Choose between Local Time, UTC, No Timestamp or empty for no timestamp. |
| Split Lists | When enabled, each item in a list appears on a new line. |
| QLog | When enabled, prints all console logs to a QLog stream. |
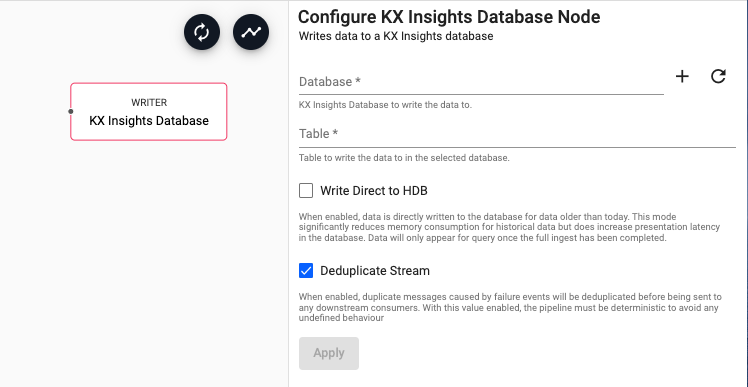
KX Insights Database
Write data to a KX Insights Database
See APIs for more details
q API: .qsp.write.toDatabase •
Python API: kxi.sp.write.to_database
Required Parameters:
| name | description | default |
|---|---|---|
| Database | The name of the database to write data to | |
| Table | The name of the table to insert data into |
Optional Parameters:
| name | description | default |
|---|---|---|
| Write Direct to HDB | When enabled, data is directly written to the database for data older than the purview of the HDB. For large historical ingests, this option will have significant memory savings. Note that when this is selected, data will not be available for query until the entire pipeline completes. | No |
| Deduplicate Stream | For deterministic streams, this option ensures that data that is duplicated during a failure event only arrives in the database once. Only uncheck this if your model can tolerate data that is duplicated but may not be exactly equivalent. | Yes |
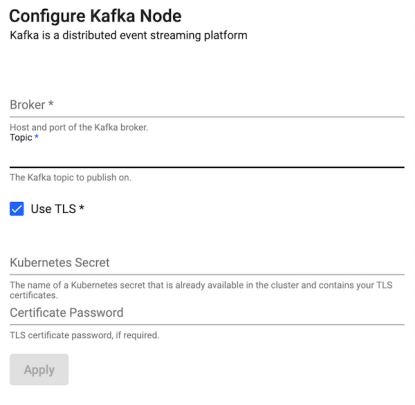
Kafka
Publish data on a Kafka topic. Kafka is a distributed event streaming platform. A Kafka producer will publish data to a Kafka broker which can then be consumed by any downstream listeners. All data published to Kafka must be encoded as either strings or serialized as bytes. If data reaches the Kafka publish point that is not encoded, it is converted to q IPC serialization representation.
| item | description |
|---|---|
| Broker | Define Kafka connection details as host:port information - for example: localhost:9092. |
| Topic | The name of the Kafka data service to publish on. |
| Use TLS | Enable TLS. |
| Kubernetes Secret* | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. |
| Certificate Password* | TLS certificate password, if required. |
* If TLS enabled.
Process
Writes events to another kdb+ process, publishes data to a table or invokes a function with that data.
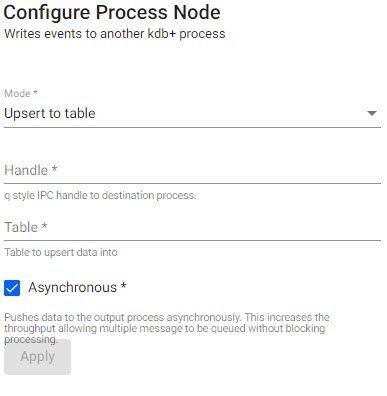
| item | description |
|---|---|
| Mode | Select between Upsert to table or Call function. |
| Handle | q style IPC Handle to destination process, includes port details to write to. |
| Table | The name of table to upsert data to for further exploration. |
| Asynchronous | When enabled, push to the output process asynchronously. This increases the throughput allowing multiple messages to be queued without blocking processing. |
KX Insights Stream
Writes events to a KX Insights Stream.
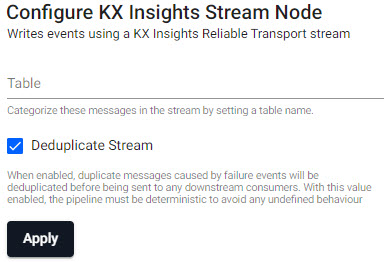
| item | description |
|---|---|
| Table | Categorize stream messages by table name |
| Deduplicate Stream | When enabled, duplicated message caused by failure events will be de-duplicated before sent downstream. When enabled, the pipeline must be deterministic to avoid any undefined behavior. |