kdb Insights Enterprise Scaling
The kdb Insights Enterprise aims to provide the capability to appropriately scale a deployment as resource limits (e.g. CPU, memory or IO) are reached. This will allow users to take advantage of the potentially unlimited resources available on the cloud.
The manner in which kdb Insights Enterprise scales is a large and expansive topic, and depends on the use case and client requirements.
kdb Insights Enterprise Core Services
The kdb Insights Enterprise base installation is deployed using a base helm chart which installs the core components and services. Each of these services aims to scale horizontally as dictated by the system load. These core services utilize Kubernetes auto scale features where each service can be configured with auto scaling parameters to allow them to scale up and down appropriately.
Data Assembly pipelines
Data Assembly pipelines handle the path for clients to publish data into kdb Insights Enterprise. Typically that data is transformed and persisted to disk. The main scalability concerns of these services typically include
- The number of clients publishing into the system and...
- The amount of data being published
Note
This leads to RPO (Recovery Point Objective) and RTO (Recovery Time Objective) requirements which should be considered in the definition and design of these pipelines .
As such when designing a system to support increasing data loads; an appropriate data sharding design is required to avoid too much data going down a single channel and ultimately cause IO limitations. Through data shards we can dynamically launch new Data Assembly pipelines dealing with additional data sources with different data topics, different ingestion adaptors such as Kafka brokers, multiple Reliable Transport (RT) clients or even object store data source for batch ingest end points.
For example within kdb Insights Enterprise we could deploy multiple concurrent assembly pipelines, and thus spread the data ingestion load across the potentially unlimited CPU of the cloud.
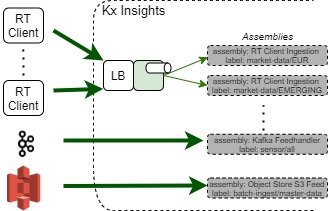
With a well architected system and an appropriately resourced Kubernetes cluster we can continue this pattern to scale out the data ingestion as more data sources and clients come on board.