Import
Import is a guided process for importing data from a number of different sources, including cloud and relational data services.

Available data sources to import data from.
Get started
-
Select Import under Getting Started of the Overview page.
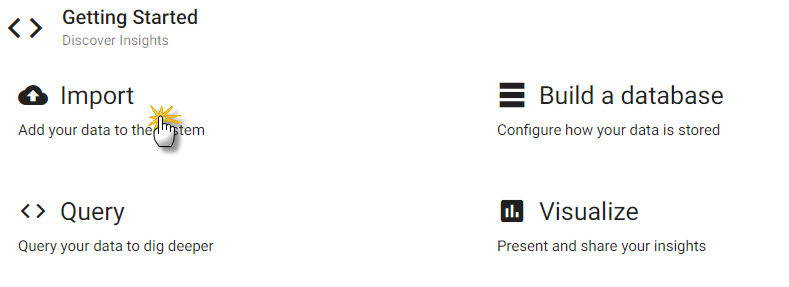
From the home page under "Getting Started", select Import. -
Select a data service; working examples are available for:
-
Complete the workflow for the selected import of step 2 before proceeding. Click
 to view the completed pipeline in the template.
to view the completed pipeline in the template.
Pipeline view of the SQL database in the template. -
Changes can be made in the pipeline template; for example, for Kafka import it is necessary to include a Map function.
-
Name and save the pipeline.

Save pipeline and give it a name. -
Optionally, associate a pipeline with an assembly; use the assembly wizard to create a database if one does not already exist. Save the assembly once the pipeline has been associated with it.
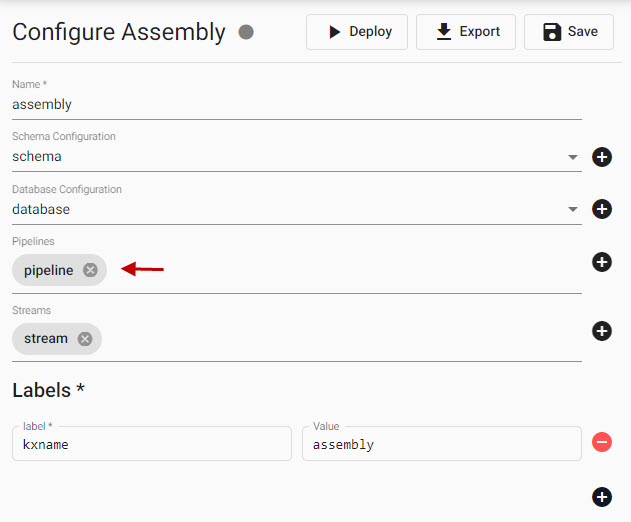
Associating a pipeline with an assembly; this is not required as a pipeline can be deployed independently as long as there is an active database available to ingest the data. -
Deploy the pipeline to an active assembly, or deploy the data assembly if associated with generated import pipeline(s).
A deployed data assembly with data is ready to query when active. An active assembly is indicated by a green circle with a tick inside it appears next to the assembly name in the left-hand menu.
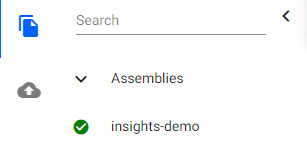
A running assembly listed under Assemblies of Overview..An active pipeline is listed under Pipelines in Overview and shows
Status=Runningwith a green tick next to it.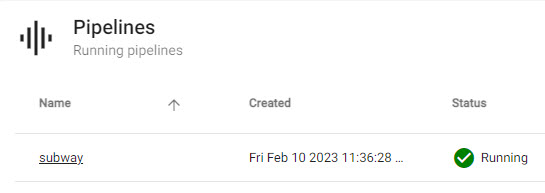
A runningsubwaypipeline listed under Pipelines of Overview.An active database is a requirement to receive data from a pipeline. If deploying a database and pipeline separately, deploy your assembly (with the database) first, then the pipeline.
Guided Walkthrough
If using a guided walkthrough example, deploy the
insights-demoassembly before deploying the pipeline. -
Open a Query tab to query the data. Opening the SQL tab is the quickest way to get data:
SELECT * FROM tablenameDefine an
output variable, this can usetablename.Click

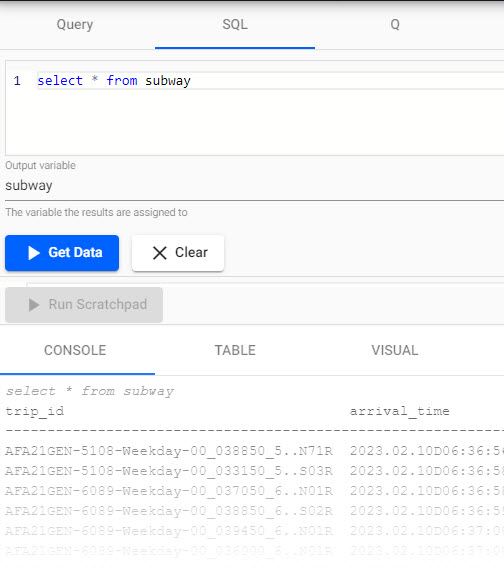
Results of a SQLsubwayquery in the query tab.
Advanced Settings
Each pipeline created by the Import wizard has an option for Advanced pipeline settings. Advanced settings include Global Code which is executed before a pipeline is started; this code may be necessary for Stream Processor hooks, globals and named functions.
Schema Column Parsing
Parsing is done automatically as part of the import process. If defining a manual parse, ensure parsing is enabled for all time, timestamp, and string fields unless your input is IPC or RT.
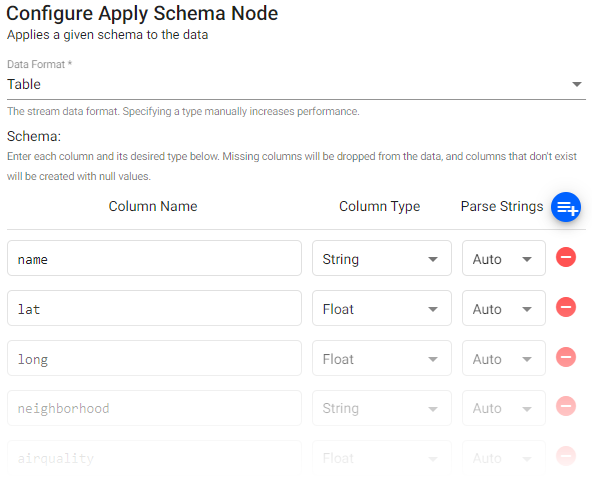
Parsing is done automatically, but it should be done for all time, timestamp and string fields if not automatic.
Data service
In the following examples, broker or server fields should include the appropriate Kubernetes namespace substring as required. The guided walkthrough offers a number of sample data sets as part of the insights-demo assembly. Follow the guided walkthrough examples to get started.
Kafka
Connect to an Apache Kafka distributed event streaming platform. For a working example, build the guided-walkthrough monitoring efficiency on the NY subway.
-
Define the Reader node with the Kafka broker details, port information and topic name; for example:
setting value Broker kafka:9092 Topic trades Offset Start Use TLS Disabled -
Event data on Kafka is of JSON type. Select the JSON decoder to tansform the data to a kdb+ friendly format. Data will be converted to a kdb+ dictionary. There is no need to change the default setting for this.
setting value Decode Each False -
Apply a Schema; this ensures that data is of the correct datatype in the destination database.
Data Formatdefines the stream data format; this can be aTableor anArray, and performance improves if you select one or the other, but leaving defaultAnyis fine in all cases.Parse Stringscan be left asAuto; but ensure any time, timestamp and string data columns is set toOnorAuto. During the import process, you can select a schema from an assembly by clicking .The schema must be defined in advance of the import.
.The schema must be defined in advance of the import.setting value Data Format Any Ensure your schema table has a
timestampcolumn; for example:column name column type parse strings datetime Timestamp Auto ticker Symbol Auto price Float Auto size Integer Auto I want to learn more about schemas.
Create an assembly to add a schema using the guided wizard. -
The next step writes data to a database table. Select a database from the dropdown to assign the data, or create a database by clicking
 before returning to the pipeline to add this newly created database. Next, select a table from the selected database to write the data too; this is typically the schema table from the previous step. If not already completed, create a table with a schema matching that of the previous step and assign it here. During the database wizard creation process, there is a step in the wizard for creating a table (and schema); tables can be added to its schema.
before returning to the pipeline to add this newly created database. Next, select a table from the selected database to write the data too; this is typically the schema table from the previous step. If not already completed, create a table with a schema matching that of the previous step and assign it here. During the database wizard creation process, there is a step in the wizard for creating a table (and schema); tables can be added to its schema. setting value Database In general, select database used during schema step Table Select table used in schema step Write Direct to HDB Disabled (default) Deduplicate Stream Enabled (default) I want to learn more about databases.
Create an assembly database using the guided wizard. -
Click
to view the pipeline template. -
Include a Map function to convert the data from a kdb+ dictionary to a kdb+ table. In the pipeline template, open the list of Functions from the left-hand-menu and click-and-drag a
Mapnode into the pipeline workspace.Insert the
Mapnode between the Decoder and the Transform node; right-click a connection to remove, then connect the dots of the nodes to link them.
A completed Kafka pipeline. -
Select the
Mapnode, and cut-and-paste into the code editor of "Configure Map Node" in the right-hand-panel:{[data] enlist data } -
Save the pipeline; give it a name.
-
Before deploying the pipeline, ensure the database used for the database write step (step 4) is active. Deploying the assembly with the database from the list of Assemblies listed in Overview, activates the database.
-
Deploy the pipeline. This starts the activation process. An active pipeline shows
Status=Runningunder Pipelines of Overview. -
Query the data. Open the
SQLtab. The query is run against the table defined in the write-to-database step (step 4); for example, if we had a schema table calledtrades, which was also the name of the table to write data too in step 4, then ourSQLquery is:SELECT * FROM trades -
Define an
output variable. This table reference is used when working in scratchpad; it can use the same name as the table name (e.g. can also be namedtrades). -
Click
to run the query.
The Broker field can be the Kafka broker pod name when the Kafka broker is installed in the same Kubernetes namespace as kdb Insights Enterprise. If the Kafka cluster has been installed into a different Kubernetes namespace, then the field expects the full service name of the Kafka broker, kafka.default.svc.cluster.local:9092, where default is the namespace that the Kafka cluster is in. The full-service name is set in the KX_KAFKA_BROKERS environment variable property in the Kafka Producer Kubernetes installation instructions.
See the guided walkthrough Kafka import example.
kdb expression
Import data from a kdb+ expression. This is the simplest import to do.
-
First define the kdb+ query; in the code editor, add:
n:2000; ([] date:n?(reverse .z.d-1+til 10); instance:n?`inst1`inst2`inst3`inst4; sym:n?`USD`EUR`GBP`JPY; cnt:n?10) -
Next, define the schema corresponding to the kdb+ generated data.
Data Formatdefines the data format and can be set toTableor left asAny.setting value Data Format Any In the majority of cases, a schema is loaded from a database. However, a schema can be defined at this step by manually adding columns. Ensure your schema table has a `` column.
column name column type parse strings date Timestamp Auto instance Symbol Auto symbol Symbol Auto cnt Integer Auto Click
 to load a schema from a database. Note, a pre-defined table - same as "Manual Schema definition", and database, is required for this option to be available.
to load a schema from a database. Note, a pre-defined table - same as "Manual Schema definition", and database, is required for this option to be available. 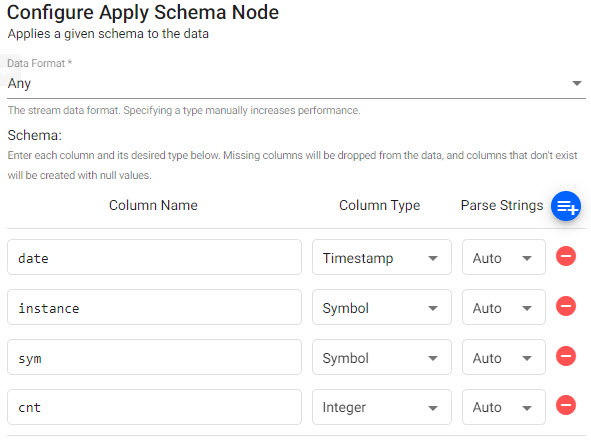
An expression pipeline schema.Guided Walkthrough
Guided walkthrough has a
crimeschema in theinsights-demodatabase to use for this purpose. -
Configure the Writer. The Writer assigns data to a table in a database. If no database is available, create one by clicking
before returning to the pipeline to add the newly created database and matching table. With guided walkthrough, the insights-demodatabase can be used and the details of the table added.Select a table from the selected database to write the data to; this is typically the schema table from the previous step. If not already completed, create a table with a schema matching that of the previous step and assign it here. During the database wizard creation process there is a step for creating a table (and schema).
setting value Database In general, select database used during schema step Table Select table used in schema step Write Direct to HDB Disabled (default) Deduplicate Stream Enabled (default) I want to learn more about databases.
Create an assembly database using the guided wizard. -
Click
to view the pipeline template. No further changes are required here. -
Click
 and give the pipeline a name.
and give the pipeline a name.
Saving an expression pipeline. -
You can optionally add the pipeline to an assembly. The advantage is only a single deployment of the assembly is required to deploy both pipeline and the database receiving the data. If the pipelne and assembly (with database) are separate, deploy the assembly first, then deploy the pipeline.
Guided Walkthrough
Add the pipeline to the
insights-demoassembly. Save the assembly with the pipeline. -
Deploy the Data assembly with the associated expression pipeline.
-
Query the data. Open the
SQLtab. The query is run against the table named defined in the write-to-database (step 3). Anoutput variableis also required; it can be the same name as the table. Theoutput variableis used when working with the scratchpad.SELECT * FROM tablename -
Click
to run the query.
SQL databases
Applicable to all supported SQL databases, including PostgreSQL and Microsoft SQL Server.
-
Select PostgreSQL reader and configure its properties; for a working example, see guided walkthrough.
setting value Server postgresql (see below) Port 5432 Database testdb Username testdbuser Query select * from datatablename Where Server is
postgresql.default.svc, thedefaultis the namespace, e.g. ifdbis your namespace, then it will bepostgresql.db.svccase sensitive
Node properties and queries are case sensitive and should be lower case.
-
Click
to add a schema from a database assembly. Note, this must be defined in advance of the import. Ensure your schema table has a timestampcolumn.Parse Stringscan be left asAutofor all columns; but ensure any time, timestamp and string data columns are set toOnorAuto.setting value Data Format Any A sample Postgres schema
column name column type parse string Year Date Auto Name Symbol Auto Miles_per_Gallon Float Auto Cylinders Float Auto Displacement Float Auto Horsepower Float Auto Acceleration Float Auto Origin Symbol Auto Laptime Timestamp Auto 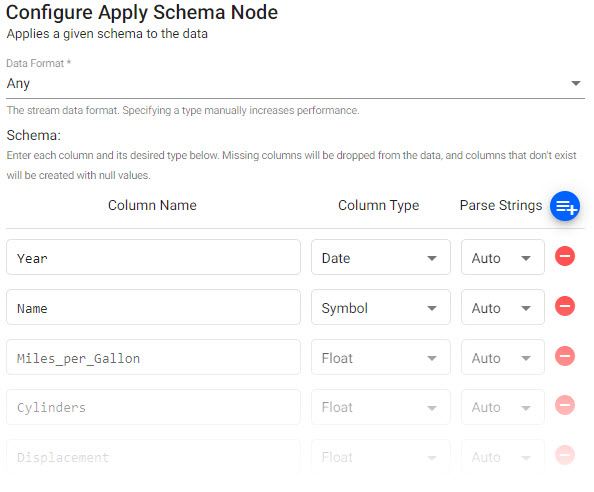
A sample schema.I want to learn more about schemas. I want to build an assembly with database and schema.
-
Define the write-to-database. If no database is available, create one by clicking
. Select a database table to write the data to; this is typically the schema table. setting value Database In general, select database used during schema step Table Select table used in schema step Write Direct to HDB Disabled (default) Deduplicate Stream Enabled (default) I want to learn more about databases.
Create an assembly database using the guided wizard. -
Click
to view the pipeline template. No further changes are required here. -
Click
and give the pipeline a name. -
Deploy the pipeline to an active assembly. At this point, you will be prompted for the database password.
-
Query the data. Open the
SQLtab. The query is run against the table named defined in the write-to-database (step 3). Anoutput variableis also required; it can be the same name as the table.SELECT * FROM datatablename -
Click
to run the query.
See the guided walkthrough SQL database import example.
Cloud storage services
Organizations require data services which balance performance, control, security and compliance - while reducing the cost of storing and managing such vast amounts of data. Limitless scale is the reason object storage is the primary storage of cloud service providers, Amazon, Google and Microsoft. kdb Insights Enterprise allows you to take advantage of object storage natively and a working example is available in the guided walkthrough.
-
Define the Reader with S3 path details. An option is also available for Kubernetes secret authentication available too. You can use default values for all but
PathandRegion.setting value Path (click [+] to access) s3://bucket/pricedata.csv Region us-east-1 File Mode Binary Offset 0 Chunking Auto Chunk Size 1MB Use Authentication Disabled -
Select the decoder to use, e.g. CSV. Imported data requires a timestamp column to parse the data, but the CSV decoder automatically assigns kdb+ data types to columns.
setting value Delimiter , Header First Row -
Click
to add a schema from a database assembly. Note, this must be defined in advance of the import. Parse Stringscan be left asAutofor all columns; but ensure any time, timestamp and string data columns are set toOnorAuto.setting value Data Format Any Ensure your schema table has a
timestampcolumn.A sample schema for a time column, category column and two value columns:
column name column type parse strings time Timestamp Auto sym Symbol Auto price Float Auto volume Integer Auto I want to learn more about schemas. I want to build an assembly with database and schema.
-
Define the write to database. If no database is available, create one by clicking
. Select a table from the selected database to write the data to, this is typically the schema table. setting value Database In general, select database used during schema step Table Select table used in schema step Write Direct to HDB Disabled (default) Deduplicate Stream Enabled (default) I want to learn more about databases.
Create an assembly database using the guided wizard. -
Click
to view the pipeline template. No further changes are required here. -
Click
and give the pipeline a name. -
First deploy the assembly with the database to receive the data, then deploy the Amazon S3 pipeline.
-
Query the data. Open the
SQLtab. Set theoutput variable. Use the same name as the table. Query withSQL:SELECT * FROM pricedata -
Click
to run the query.
Note that a Kubernetes secret is required if authenticating with Amazon S3. See the section on Amazon S3 Authentication for more details.
- Define the Reader with GCS details. You can use default values for all but
PathandProject ID.Project IDmay not always have a customizable name, so its name is contingent on what is assigned when creating your GCS account.
| setting | value |
|---|---|
| Path (click [+] to access) | gs://mybucket/pricedata.csv |
| Project ID | ascendant-epoch-999999 |
| File Mode | Binary |
| Offset | 0 |
| Chunking | Auto |
| Chunk Size | 1MB |
| Use Authentication | Disabled |
-
Select the decoder to use, e.g. csv. Imported data requires a timestamp column to parse the data, but the CSV decoder automatically assigns kdb+ data types to columns.
setting value Delimiter , Header First Row -
Click
to add a schema from a database assembly. Note, this must be defined in advance of the import. Parse Stringscan be left asAutofor all columns; but ensure any time, timestamp and string data columns are set toOnorAuto.setting value Data Format Any Ensure your schema table has a
timestampcolumn.A sample schema for a time column, category column and two value columns:
column name column type parse strings time Timestamp Auto sym Symbol Auto price Float Auto volume Integer Auto I want to learn more about schemas. I want to build an assembly with database and schema.
-
Define the write to database. If no database is available, create one by clicking
. Select a table from the selected database to write the data too; this is typically the schema table. setting value Database In general, select database used during schema step Table Select table used in schema step Write Direct to HDB Disabled (default) Deduplicate Stream Enabled (default) I want to learn more about databases.
Create an assembly database using the guided wizard. -
Click
to view the pipeline template. No further changes are required here. -
Click
and give the pipeline a name. -
First deploy the assembly with the database to receive the data, then deploy the Amazon S3 pipeline.
-
Query the data. Open the
SQLtab. Set theoutput variable, this can use the same name as the table. Query withSQL:SELECT * FROM pricedata -
Click
to run the query.
I want to learn more about Google Cloud Storage Authentication
- Define the ACP Reader with ACS details. You can use default values for all but
PathandProject ID. A customizable account name is supported for ACS.
| setting | value |
|---|---|
| Path (click [+] to access) | ms://mybucket/pricedata.csv |
| Account | myaccountname |
| File Mode | Binary |
| Offset | 0 |
| Chunking | Auto |
| Chunk Size | 1MB |
| Use Authentication | Disabled |
-
Select the decoder to use, e.g. csv. Imported data requires a timestamp column to parse the data, but the CSV decoder automatically assigns kdb+ data types to columns.
setting value Delimiter , Header First Row -
Click
to add a schema from a database assembly. Note, this must be defined in advance of the import. Parse Stringscan be left asAutofor all columns; but ensure any time, timestamp and string data columns are set toOnorAuto.setting value Data Format Any Ensure your schema table has a
timestampcolumn.A sample schema for a time column, category column and two value columns:
column name column type parse strings time Timestamp Auto sym Symbol Auto price Float Auto volume Integer Auto I want to learn more about schemas. I want to build an assembly with database and schema.
-
Define the write to database. If no database is available, create one by clicking
. Select a table from the selected database to write the data to, this is typically the schema table. setting value Database In general, select database used during schema step Table Select table used in schema step Write Direct to HDB Disabled (default) Deduplicate Stream Enabled (default) I want to learn more about databases.
Create an assembly database using the guided wizard. -
Click
to view the pipeline template. No further changes are required here. -
Click
and give the pipeline a name. -
First deploy the assembly with the database to receive the data, then deploy the Amazon S3 pipeline.
-
Query the data. Open the
SQLtab. Set theoutput variable, this can use the same name as the table. Query withSQL:SELECT * FROM pricedata -
Click
to run the query.