Database
A database stores data and empowers users to run query data for insights. kdb Insights Enterprise databases allow users to store and access data from tiered data access; using faster access mechanisms for recent data, and slower, cheaper access for older, historic data. The secret to the speed of kdb Insights Enterprise database is its ability to run user driven analytics directly on the data - leveraging the timeseries, columnar performance capabilities of kdb+.
Quickstart
A database can be created by clicking [+] next to Database name in the entity tree.

Click the plus icon next to the Database name in the entity tree to create an individual database.
kdb Insights Enterprise databases are designed to scale independently for data write-down and querying. Depending on the intended workloads, compute settings can be tuned for each component. If your workload has a large amount of data being ingested, consider increasing the Writedown compute settings. If your workload has high frequency, or complex queries, consider increasing the Query Setting compute settings.
Once the database is created, it must be part of an assembly and be deployed to be activated. An active database is used to store data and is a requirement for working with data on kdb Insights Enterprise outside of testing. An active assembly will show a green circle with a tick next to its name in the left-hand entity tree listed under Assemblies.
Video Tutorial
Set up
-
Click the [+] icon from the entity tree to create a Database.
-
Select between Time-series or Custom database; it's recommended users start with a Time-series database.
-
Define database name; Submit.
-
Custom databases have tabbed options to define Mounts, Data Access and Storage properties. When creating a Custom database a
Sourcename for Storage is required; this is pre-assigned assouthfor a Time-series database. -
Submit.
-
To use the database, open up an assembly listed under Assemblies in the entity tree and add the database.
-
Save and deploy the assembly.
Quickstart - build an assembly with a database
Time-series
A quick start option for creating a database with predefined RDB, IDB and HDB mounts, and recommended for new users to kdb Insights Enterprise. Required is a Database Name, and has a predefined Storage streaming data source, but other changes are optional. There is a toggle switch to display advanced properties.
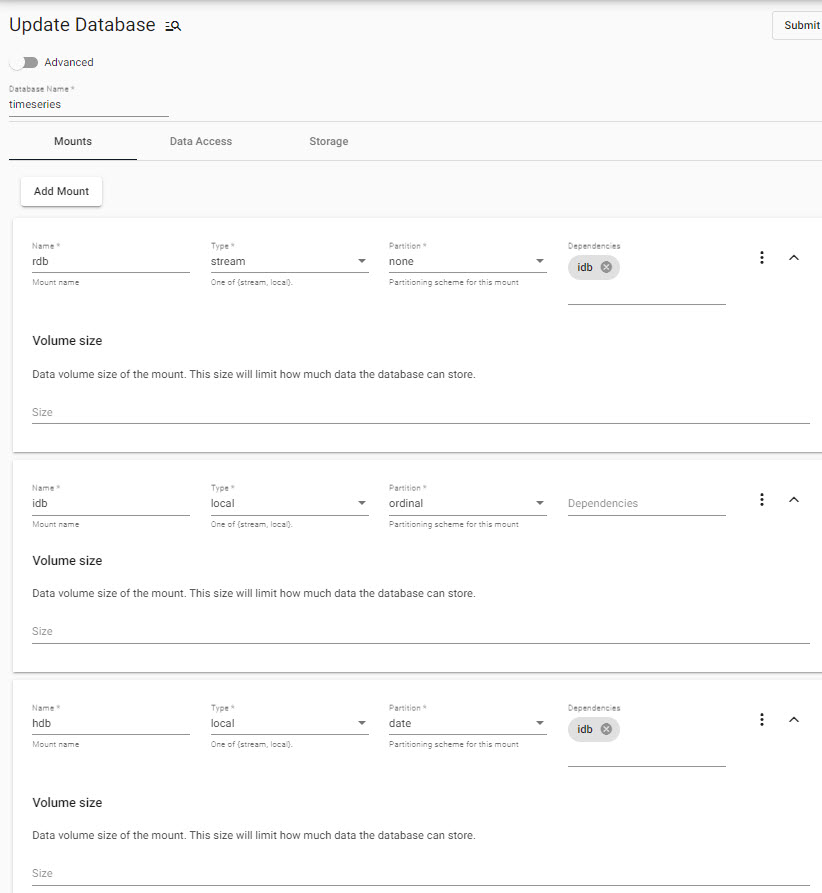
A time series database featuring customizable properties for Mounts, Data Access and Storage. A time series database can be used 'out-of-the-box' without changes to default settings.
- Database Name
- Give your database a name (required).
Time series databases come with predefined RDB, IDB and HDB mounts. Additional mounts can be added but are not required. Advanced options are marked with an * in the table item list.
| item | description |
|---|---|
| Name | Name of mount, e.g. rdb. |
| Type | Select from stream or local; defaults to stream for rdb, and local for idb and hdb. |
| Partition | Partition scheme for the mount, e.g. none, ordinal, date, month, year; defaults to none for an rdb, ordinal for idb and date for hdb. |
| Dependencies | List of mounts required to be mounted as a dependency of this mount; defaults to idb for rdb and hdb mounts, but is undefined for an idb. |
| BaseURI* | Uniform Resource Identifier (URI) representing where data can be mounted by other services; set to none for an rdb, and file:///data/db for the respective idb and hdb. |
| Description* | A text description of the purpose of the mount. |
| Volume Size | Define the disk size limit for how much data the database can store; defaults to no value set. |
Define how data will be accessed from the database. Check Enable Query Environment to allow data querying for the database from the Query tabs in the User Interface. Advanced options are marked with an * in the tables.
| item | description |
|---|---|
| Replicas | The number of query environment replicas; default to 1 |
For time series database, RDB, IDB and HDB instances are created by default, but additional instances can be added if required. Each instance offers:
| item | description |
|---|---|
| Mount Name | Name of data access mount, e.g. rdb. |
| Stream Logs volume | Set requested PV disk size, e.g. 20Gi, but no value is set by default. |
| Replicas* | Size of the Data Access deployment; defaults to 1 |
| Source | Sequence Bus to subscribe to; defaults to south |
Options to define CPU and Memory Size required to handle data access during querying.
CPU of the tier
| item | description |
|---|---|
| Minimum CPU | Minimum CPU required - 1 is for one core, 0.5 is half time for one core - must be greater than 0.1; defaults to 0.1. |
| Maximum CPU | Maximum CPU available and must be less than 12. Process is throttled when maximum CPU usage is reached; defaults to 1. |
Memory Size
| item | description |
|---|---|
| Minimum Memory | Minimum memory to allocate to the database writer and always available, must be greater than 1MB; defaults to 128 MB |
| Maximum Memory | Maximum memory to allocate to the database writer; once reached, an out-of-memory error will return, must be less than 20,480MB; defaults to 512 MB. |
Environment Variables
Advanced only and adding of environment variables is optionable.
| item | description |
|---|---|
| variable | value |
Required is a definition of the source for database storage. The source is either an URI directed at a static data source, or is the name of an entity for streaming data. For a time series database, the source is preconfigured for streaming data and is named south. Advanced options are marked with an * in the tables.
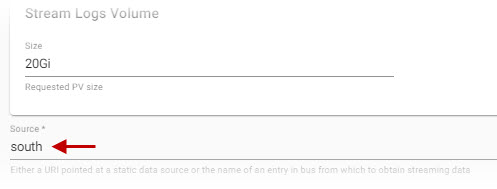
The storage source is required for a time series database defaults to south.
| item | description |
|---|---|
| Enforce Schema* | Check (enable) to enforce table schema when persisting - used for debugging, may incur performance penalty; default is off. |
| EOD Peach Level* | Level at which EOD peaches to parallelize HDB table processing; select between part or table. No default set. |
| Replicas (Beta)* | Number of storage replica deployments; defaults to 1. |
| Sort Limit GB* | Memory limit when sorting splayed tables or partitions on disk in GB. No default set. |
| Source (required) | Either a URI pointed at a static data source of the name of an entry in bus from which to obtain streaming data. Defaults to south. |
Tiers
Data is stored by tiers; when certain storage conditions are met, data rolls into another tier. For a time series database there are preconfigured tiers for RDB, IDB and HDB, but users can add HDB tiers if required.
| item | description |
|---|---|
| Mount | The name of the corresponding mount at which data in this tier can be accessed, e.g. rdb. |
| Name | Reference to a particular tier; defaults to streaming for rdb, interval for idb and historical for hdb |
Compression (Advanced only)
Define how stored data is compressed.
| item | description |
|---|---|
| Algorithm | Define how the data is to be compressed; set to default. |
| Block | Define block size for compression; numeric value. |
| Level | Set compression level; numeric value. |
Retain and Schedule
Toggle the dropdown for additional Tier options. Retain determines how much data to store in the current tier before rolling into the next tier, and schedule determines when the rollover should occur.
| item | description |
|---|---|
| Rows* | Rollover occurs for data beyond the number of rows set by this variable. |
| Size* | Threshold of tier size before rollover occurs. Number in byte size followed by unit, e.g. 2 TB. |
| Size Pct* | Threshold of tier size before rollover occurs, expressed as a percentage of total storage for the corresponding mount; value between 1 and 100. |
| Time | A timespan consisting of a number followed by a time unit (Seconds, Minutes, Hours, Days, Weeks, Months or Years); e.g. 2 Years. Rollover occurs for data whch has been stored for this length of time; defaults to no value. |
| Frequency | How often ahould the tier roll data into the next tier; defaults to no value for an rdb, 0D00:10:00 for an idb, 1D00:00:00 for an hdb. Set using a 24h clock. In order to rollover data from a hdb, it's necessary to create an hdb sub-tier; click  |
| Snap | At what whole multiples of time should rollovers be scheduled; defaults to 00:00:00. |
CPU
Allocated CPU resources for the database writer.
| item | description |
|---|---|
| Minimum CPU | Minimum CPU required - 1 is for one core, 0.5 is half time for one core - must be greater than 0.1; defaults to 0.1. |
| Maximum CPU | Maximum CPU available and must be less than 12. Process is throttled when maximum CPU usage is reached; defaults to 1. |
Memory Size
Allocated memory resouces for the database writer.
| item | description |
|---|---|
| Minimum Memory | Minimum memory to allocate to the database writer and always available, must be greater than 1MB; defaults to 128 MB |
| Maximum Memory | Maximum memory to allocate to the database writer; once reached, an out-of-memory error will return, must be less than 20,480MB; defaults to 512 MB. |
Stream Logs Volume
Define the disk size for requested logs. Defaults to 20Gi.
Environment Variables (Advanced only)
Adding of environment variables is optionable.
| item | description |
|---|---|
| variable | value |
Custom
A standard database with a single RDB mount, additional mounts can be added as required. In addition to giving the database a name there is a requirement to define a Storage Source to create the database. There is a toggle switch to display advanced properties.
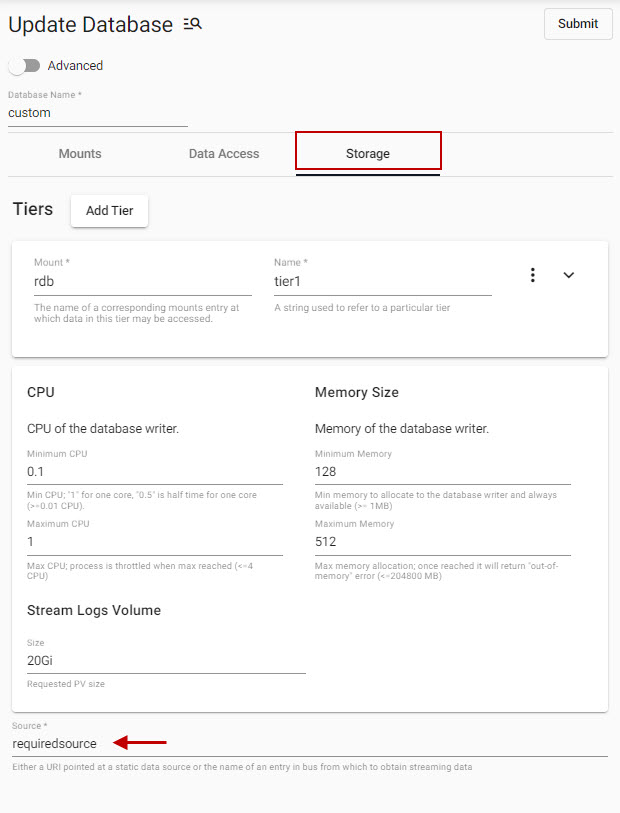
Define the 'Source' for the storage of a custom database is required.
- Database Name
- Give your database a name (required).
A custom database comes with just an RDB mount, but additional IDB and HDB mounts can be added if required. Advanced options are marked with an * in the table item list.
| item | description |
|---|---|
| Name | Name of mount, e.g. rdb. |
| Type | Select from stream or local; defaults to stream for thr rdb. |
| Partition | Partition scheme for the mount, e.g. none, ordinal, date, month, year; defaults to none for an rdb. |
| Dependencies | List of mounts required to be mounted as a dependency of this mount; defaults to idb for rdb. |
| BaseURI* | Uniform Resource Identifier (URI) representing where data can be mounted by other services; set to none for an rdb. |
| Description* | A text description of the purpose of the mount. |
| Volume Size | Define the disk size limit for how much data the database can store; defaults to no value set. |
Define how data will be accessed from the database. Check Enable Query Environment to allow data querying for the database, enabled by default. Advanced options are marked with an * in the tables.
| item | description |
|---|---|
| Replicas | The number of query environment replicas; default to 1 |
A single RDB instance is provided, additional IDB and HDB instances can be added to the database if required. Each instance offers:
| item | description |
|---|---|
| Mount Name | Name of data access mount, e.g. rdb. |
| Stream Logs volume | Set requested PV disk size, e.g. 20Gi, but no value is assigned by default. |
| Replicas* | Size of the Data Access deployment; defaults to 1 |
| Source | Sequence Bus to subscribe to. Not set by default and not a requirement for the database, but can share the name of the corresponding mount Source used by Storage. |
Options to define CPU and Memory Size required to handle data access during querying.
CPU of the tier
| item | description |
|---|---|
| Minimum CPU | Minimum CPU required - 1 is for one core, 0.5 is half time for one core - must be greater than 0.1; defaults to 0.1. |
| Maximum CPU | Maximum CPU available and must be less than 12. Process is throttled when maximum CPU usage is reached; defaults to 1. |
Memory Size
| item | description |
|---|---|
| Minimum Memory | Minimum memory to allocate to the database writer and always available, must be greater than 1MB; defaults to 128 MB |
| Maximum Memory | Maximum memory to allocate to the database writer; once reached, an out-of-memory error will return, must be less than 20,480MB; defaults to 512 MB. |
Environment Variables
Advanced only and adding of environment variables is optionable.
| item | description |
|---|---|
| variable | value |
Required is a definition of the source for database storage. The source is either an URI directed at a static data source, or is the name of an entity for streaming data. Advanced options are marked with an * in the tables.
The storage source is required for a time series database defaults to south.
| item | description |
|---|---|
| Enforce Schema* | Check (enable) to enforce table schema when persisting - used for debugging, may incur performance penalty; default is off. |
| EOD Peach Level* | Level at which EOD peaches to parallelize HDB table processing; select between part or table. No default set. |
| Replicas (Beta)* | Number of storage replica deployments; defaults to 1. |
| Sort Limit GB* | Memory limit when sorting splayed tables or partitions on disk in GB. No default set. |
| Source (required) | Either a URI pointed at a static data source of the name of an entry in bus from which to obtain streaming data. No default is set |
Tiers
Data is stored by tiers; when certain storage conditions are met, data rolls into another tier. A custom database comes with a single RBD tier, but addition IDB and/or HDB tiers can be added if required.
| item | description |
|---|---|
| Mount | The name of the corresponding mount at which data in this tier can be accessed, e.g. rdb. |
| Name | Reference to a particular tier; defaults to tier1 for the provided rdb mount. |
Retain and Schedule
Toggle the dropdown for additional Tier options. Retain determines how much data to store in the current tier before rolling into the next tier, and schedule determines when the rollover should occur.
| item | description |
|---|---|
| Retain | A timespan consisting of a number followed by a time unit (Seconds, Minutes, Hours, Days, Weeks, Months or Years); e.g. 2 Years. Rollover occurs for data whch has been stored for this length of time; defaults to no value. |
| Frequency | How often ahould the tier roll data into the next tier; defaults to no value for an rdb, 0D00:10:00 for an idb, 1D00:00:00 for an hdb. Set using a 24h clock. In order to rollover data from a hdb, it's necessary to create an hdb sub-tier; click |
| Snap | At what whole multiples of time should rollovers be scheduled; defaults to 00:00:00. |
CPU
Allocated CPU resources for the database writer.
| item | description |
|---|---|
| Minimum CPU | Minimum CPU required - 1 is for one core, 0.5 is half time for one core - must be greater than 0.1; defaults to 0.1. |
| Maximum CPU | Maximum CPU available and must be less than 12. Process is throttled when maximum CPU usage is reached; defaults to 1. |
Memory Size
Allocated memory resouces for the database writer.
| item | description |
|---|---|
| Minimum Memory | Minimum memory to allocate to the database writer and always available, must be greater than 1MB; defaults to 128 MB |
| Maximum Memory | Maximum memory to allocate to the database writer; once reached, an out-of-memory error will return, must be less than 20,480MB; defaults to 512 MB. |
Stream Logs Volume
Define the disk size for requested logs. Defaults to 20Gi
Environment Variables (Advanced only)
Adding of environment variables is optionable.
| item | description |
|---|---|
| variable | value |