Database Service in KDB-X¶
Preview
The KDB-X DB Service is currently in Preview, and its API interfaces may change before general availability. This documentation covers the single-node version of the service. Feedback is welcome to preview@kx.com.
This page provides an overview of the Database Service (DB Service) in KDB-X, including its architecture, core capabilities, and supported interfaces.
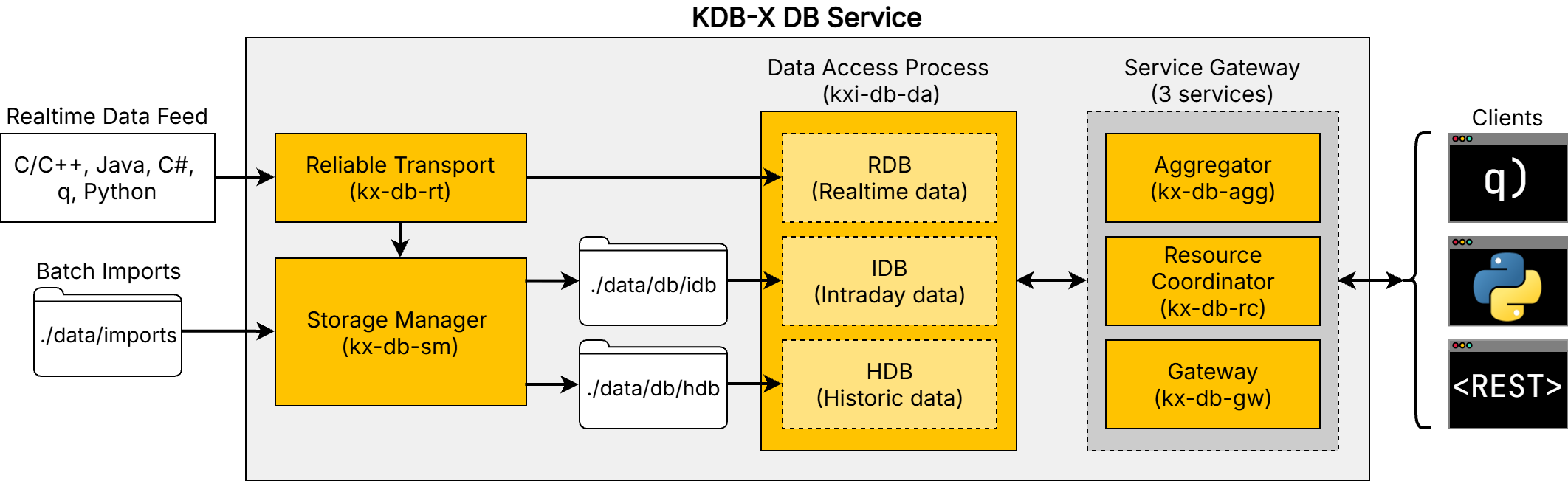
The DB Service is a self-contained variation of the KDB-X tick-based architecture, with a range of built-in features exposed through a well-documented API. It provides a simple way to deploy a fully-implemented KDB-X database for capturing and querying both streaming and batch data.
It is composed of multiple services that work together to manage data ingestion, storage, and query execution. The services are KDB-X enabled versions of a kdb Insights Database:
-
Storage manager (SM). Manages data persistence across memory and disk tiers.
-
Data access process (DAPs). Database service tiers. Provide read access to real-time (RDB), intraday (IDB), and historical data (HDB).
-
Service gateway. Provides request queuing, query routing, and response aggregation.
-
Reliable transport (RT). High performance message stream for real-time data ingest.
These components enable separation of ingest, storage, and query workloads, allowing the system to scale independently across each layer.
Single-node architecture overview¶
The single-node version is deployed using Docker Compose and comes with a standard configuration. As a result, it is less flexible than a custom-built KDB-X tick architecture. However, it is quick to set up and easy to run, making it a good fit for new users or for applications that don’t require deep customization.
You can deploy the single-node architecture in minutes by following the quickstart guide.
The service can also be run as a high-availability cluster, with optional data sharding.
Data ingest¶
The DB Service supports multiple data import methods.
-
Streaming ingest (real-time). Designed for continuous, high-throughput data feeds, with publisher APIs available for C/C++, Java, q, C#, and Python.
-
Batch ingest (file-based). Supports loading data from files such as CSV and Parquet, with automatic table creation from incoming data.
-
API ingest. Allows inserting JSON or q data structures via REST or client libraries, and is suitable for small payloads, testing, or bootstrapping tables.
The system includes slow subscriber protection, ensuring that downstream components do not block high-frequency ingest.
Data storage and tiering¶
The DB Service separates data across multiple storage tiers, including RDB (in-memory) for recent data, HDB (historical) for persisted data on disk, and IDB (intraday write-down) for intermediate persistence.
Data is automatically written down from memory to disk while remaining available for query. The system maintains full availability across end-of-day (EOD) and end-of-interval (EOI) transitions, with independent write-down processing managed by the storage manager.
This version of the single-node DB Service supports basic table management: you can create and drop tables, as well as list and describe them.
Query¶
The DB Service provides a few different ways to query data:
- A structured query API, where queries are defined through API parameters such as table, start/end times, filters, aggregations, and more.
- SQL queries, with read-only
SELECTsupport for KDB-X SQL. - q queries, allowing free-form q to run on each data tier, with an optional aggregation function.
The query gateway queues and balances requests, automatically routing queries across data tiers and query replicas. Queries are unified across real-time and historical tiers, and are automatically aggregated after execution.
The system supports some horizontal scaling through replicated query nodes (DAP replicas).
Interfaces¶
You can interact with the DB Service using:
- The REST API, using direct HTTP requests.
- A q client, which wraps the REST API for use in q.
- A Python client, which wraps the REST API for use in Python.
These interfaces provide consistent access to ingestion, querying, and schema management operations.
Clustered architecture overview¶
The underlying services can be deployed in a clustered setup to Kubernetes.
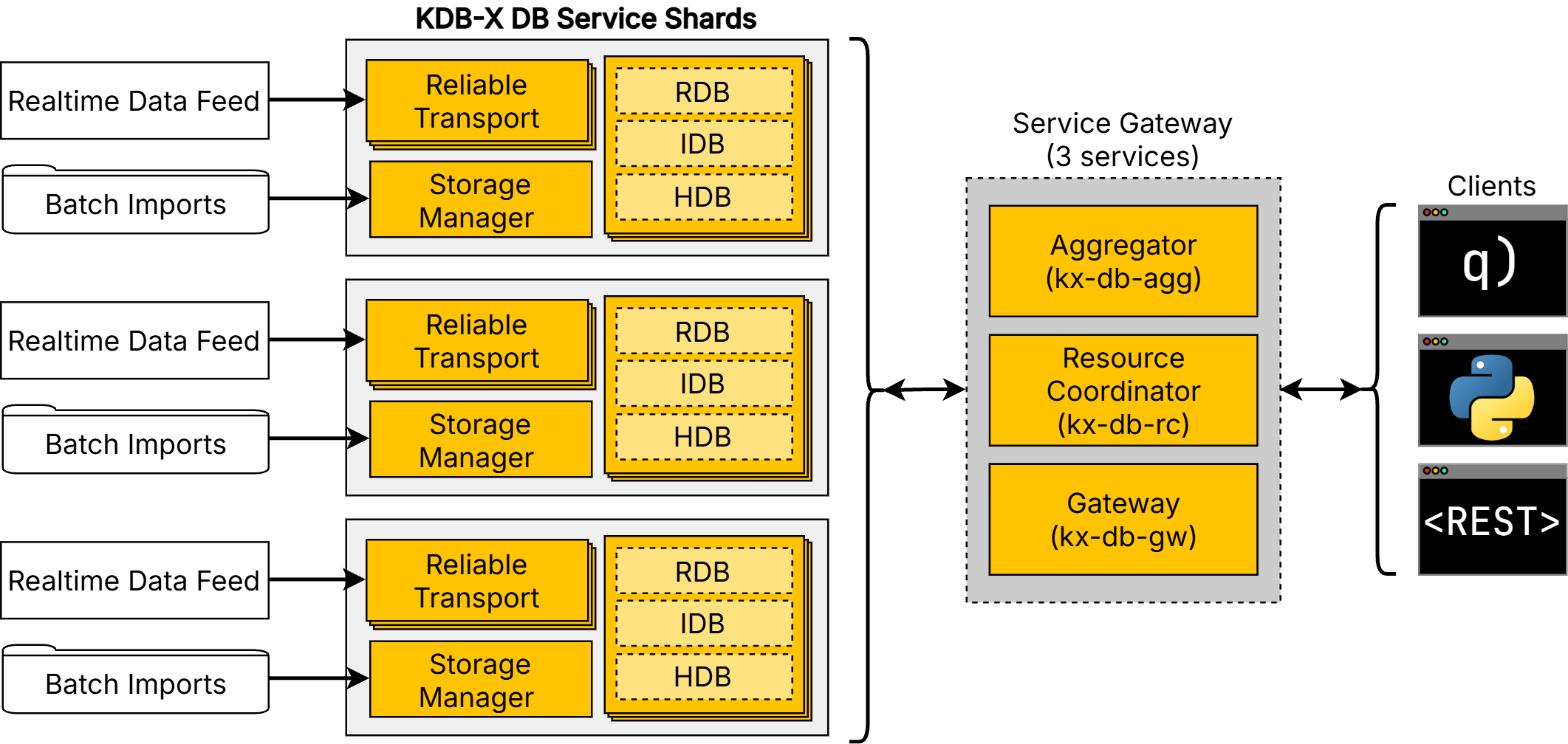
Running as a cluster offers:
- Automatic orchestration and failover by Kubernetes during node maintenance or problems.
- Triple replication of databases, offering high availability over 3 availability zones. Realtime data logs are synchronized via Reliable Transport – eliminating data drift between the replicas.
- Horizontal scalability, for a multi-database and multi-sharded application, with a common gateway to query across everything.
Official reference architectures for the clustered DB Service will be available soon. The underlying services can, however, already be deployed using the existing Insights SDK reference architectures.
Next steps¶
- Get started with the DB Service in KDB-X
- Check the DB Service release notes for version history and fixes