Transform
Change the shape of data with no code transformations
Transforms enable data type and shape conversions without the need to write the transformation as code.
See APIs for more details
A q interface can be used to build pipelines programatically. See the q API for API details.
A Python interface is included along side the q interface and can be used if PyKX is enabled. See the Python API for API details.
The pipeline builder uses a drag-and-drop interface to link together operations within a pipeline. For details on how to wire together a transformation, see the building a pipeline guide.
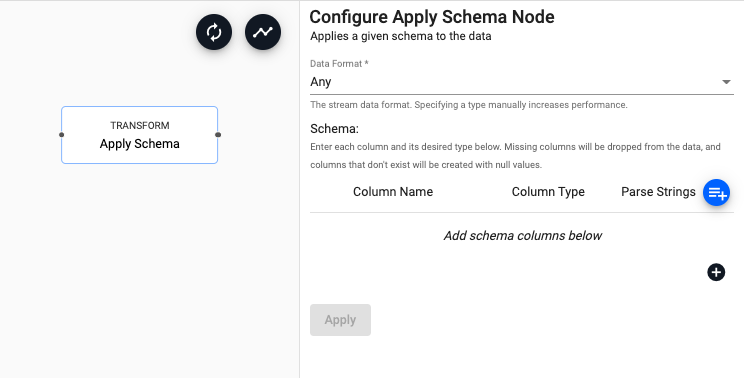
Apply Schema
Apply a table schema to data passing through the operator
See APIs for more details
q API: .qsp.transform.schema
Python API: kxi.sp.transform.schema
Required Parameters:
| name | description | default |
|---|---|---|
| Data Format | Indicates the format of the data within the stream if it is known. Selecting either Arrays or Table will allow the schema operator to optimize its data conversions. Leave this value as Any if the data format is unknown. |
Any |
| Schema | Enter a column name and column type for each column in the data. Missing columns will be dropped, and non-existent columns will be created with null values. |
Schema Parameters:
| name | description |
|---|---|
| Column Name | Give the assigned column a name. |
| Column Type | Define the kdb+ type for the assigned column. |
| Parse Strings | Indicates if parsing of data type is required. Parsing of input data should be done for all time, timestamp, and string fields unless your input is IPC or RT. Defaults to Auto, but can be configured as On or Off. |
Schemas require a timestamp partition column
Schemas require a timestamp data column. In addition, the table should be partitioned and sorted (interval, historic and/or real-time) by this timestamp column. This can be configured as part of the essential properties of a schema.
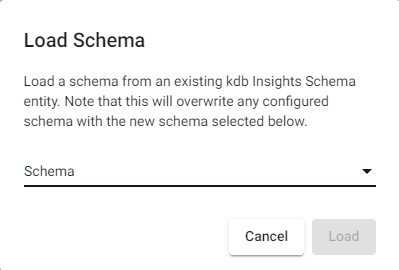
Load Schema
To load an existing schema, click the add schema button.

This open the Load Schema dialog which allows you to select a schema from a list of schemas already entered in the system. Selecting a schema will copy all of the column and type definitions into the pipeline.