Developing using q
When analyzing your data retrieved from the kdb Insights Enterprise database you have two options for the language which can be used for this analysis, q or Python. This page outlines the functionality available when using q specifically, if you are developing principally in Python see here.
The q environment provided by the scratchpads provides you with a self-contained location unique to you which allows you to assign variables and produce analyses that are visible only to you.
It is important to note that use of the q language version of the scratchpad will be indicated by the highlighting of the Q language within the scratchpad dialog.
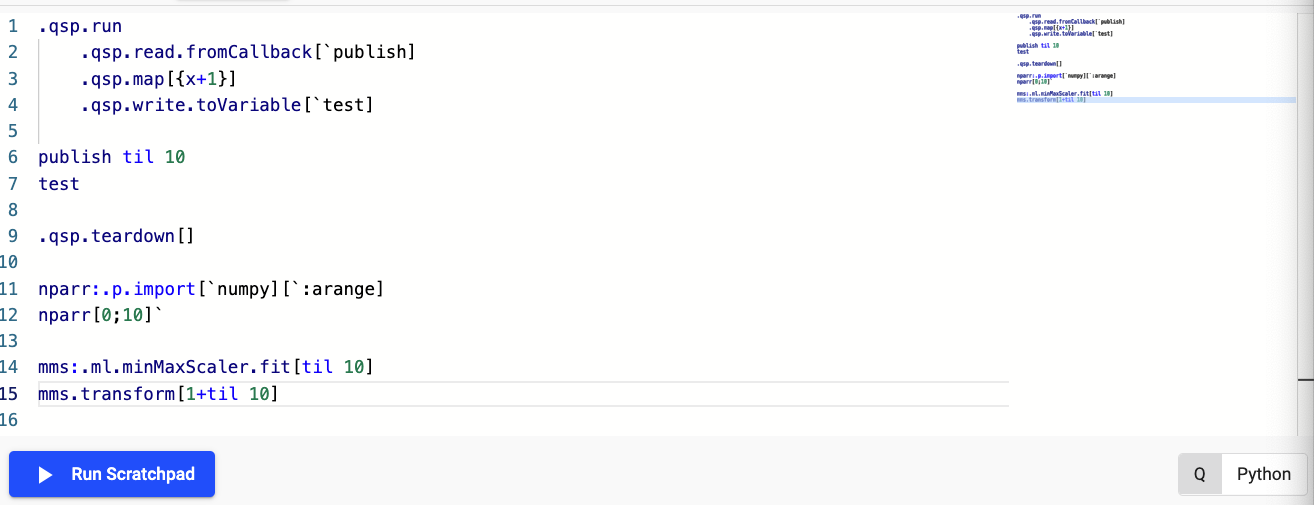
This page will guide you through the execution of code and the APIs which are provided with the scratchpad by default. These can help you accelerate the development of your enterprise workflows, these include the following.
- The Stream Processor q API
- Machine learning toolkit and it's associated functionality including the MLOps/ML Registry work
- Packaging/UDF q API
- embedPy and the PyKX q API allowing you to use Python functionality using a DSL for q.
For information relating to the visualization of data and console output within the scratchpad see here.
Executing code
When executing code within the scratchpad there are a number of important points you should be aware of:
- Use of the "Run Scratchpad" button will result in all code in the scratchpad code window being executed
- Use of
Cmd + Enterorctrl + Enterdepending on OS allows a user to execute single lines of code or multi-line highlighted code blocks
Developing prototype Stream Processor code
One useful application of the scratchpad is it's usage as a prototyping environment for Stream Processor pipelines. Access to the pipeline API gives you the ability to mock production workflows and test code logic prior to moving development work to production environments. This is facilitated through use of the Stream Processor q API.
You can take the following script as an example, here you will create a pipeline for ingesting both trade and quote data and join it using a left-join
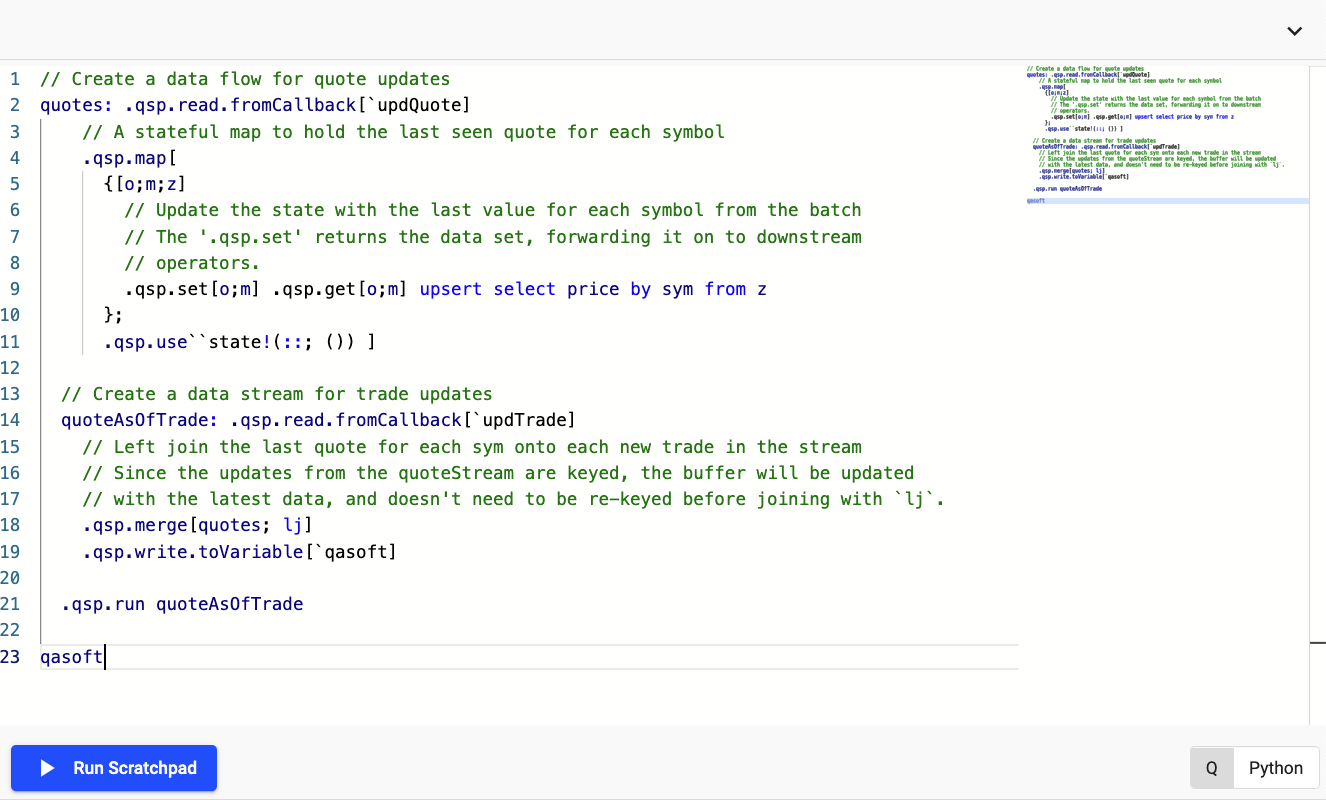
Code snippet for the above pipeline
The following provides the equivalent code snippet the screenshot above allowing you to replicate it's behavior yourself:
// Create a data flow for quote updates
quotes: .qsp.read.fromCallback[`updQuote]
// A stateful map to hold the last seen quote for each symbol
.qsp.map[
{[o;m;z]
// Update the state with the last value for each symbol from the batch
// The '.qsp.set' returns the data set, forwarding it on to downstream
// operators.
.qsp.set[o;m] .qsp.get[o;m] upsert select price by sym from z
};
.qsp.use``state!(::; ()) ]
// Create a data stream for trade updates
quoteAsOfTrade: .qsp.read.fromCallback[`updTrade]
// Left join the last quote for each sym onto each new trade in the stream
// Since the updates from the quoteStream are keyed, the buffer will be updated
// with the latest data, and doesn't need to be re-keyed before joining with `lj`.
.qsp.merge[quotes; lj]
.qsp.write.toVariable[`qasoft]
.qsp.run quoteAsOfTrade
qasoft
Interacting with custom code
Through the use of Packages it is possible for you to add custom code to kdb Insights Enterprise for use within the Stream Processor when adding custom streaming analytics or the Database for adding custom queries. The scratchpad also has access to these APIs allowing you to load custom code and access user defined functions when developing Stream Processor pipelines or analytics for custom query APIs.
The following shows an example of a scratchpad workflow which utilizes both the packages and a UDF APIs available within the scratchpad.

Developing machine learning workflows
The scratchpad has access to a variety of machine learning libraries created by KX over the last 5 years. In particular the Machine Learning Core APIs are included by default with all running scratchpads. These APIs provide users with access to data preprocessing functionality and ML models/analytics designed specifically for streaming and time-series use-cases alongside access to our ML Model Registry which provides a cloud storage location for ML models generated in q/Python.
The following example shows how you can use some of this functionality to preprocess data, fit a machine learning model and store this ephemerally within your scratchpad session (Note that the storage of models in this way will result in the models being lost at restart of the scratchpad pod)
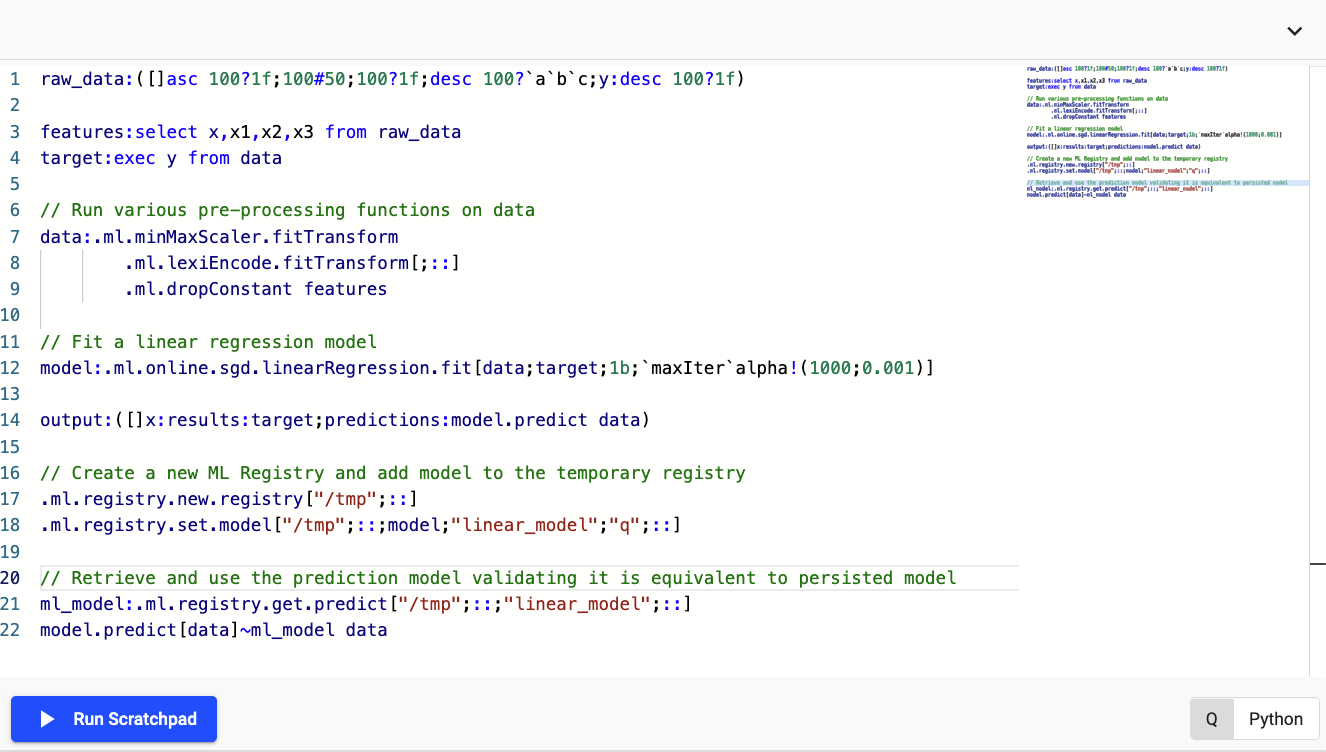
Code snippet for ML scratchpad example
The following provides the equivalent code snippet the screenshot above allowing you to replicate it's behavior yourself:
raw_data:([]asc 100?1f;100#50;100?1f;desc 100?`a`b`c;y:desc 100?1f)
features:select x,x1,x2,x3 from raw_data
target:exec y from data
// Run various pre-processing functions on data
data:.ml.minMaxScaler.fitTransform
.ml.lexiEncode.fitTransform[;::]
.ml.dropConstant features
// Fit a linear regression model
model:.ml.online.sgd.linearRegression.fit[data;target;1b;`maxIter`alpha!(1000;0.001)]
output:([]x:results:target;predictions:model.predict data)
// Create a new ML Registry and add model to the temporary registry
.ml.registry.new.registry["/tmp";::]
.ml.registry.set.model["/tmp";::;model;"linear_model";"q";::]
// Retrieve and use the prediction model validating it is equivalent to persisted model
ml_model:.ml.registry.get.predict["/tmp";::;"linear_model";::]
model.predict[data]~ml_model data
Including Python in your q code
You can include Python functionality within your q code using embedPy or PyKX. Depending on your use-case or familiarity with these APIs you are free to use and interchange both APIs, however it is strongly suggested that usage of the embedPy functionality should be reserved for historical code integration while any new code development should target the PyKX equivalent API.
The following basic example shows usage of both the embedPy and PyKX q APIs to generate and use callable Python objects.
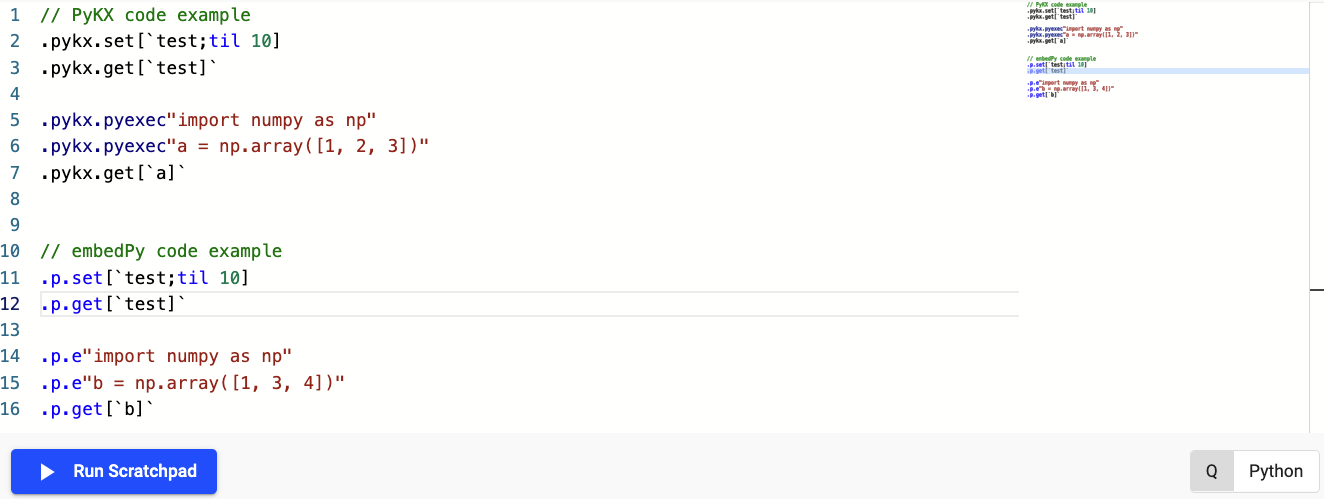
Code snippet for Python DSL use in scratchpad
The following provides the equivalent code snippet the screenshot above allowing you to replicate it's behavior yourself:
// PyKX code example
.pykx.set[`test;til 10]
.pykx.get[`test]`
.pykx.pyexec"import numpy as np"
.pykx.pyexec"a = np.array([1, 2, 3])"
.pykx.get[`a]`
// embedPy code example
.p.set[`test;til 10]
.p.get[`test]`
.p.e"import numpy as np"
.p.e"b = np.array([1, 3, 4])"
.p.get[`b]`
For more comprehensive Python development you should follow the Python development page here.