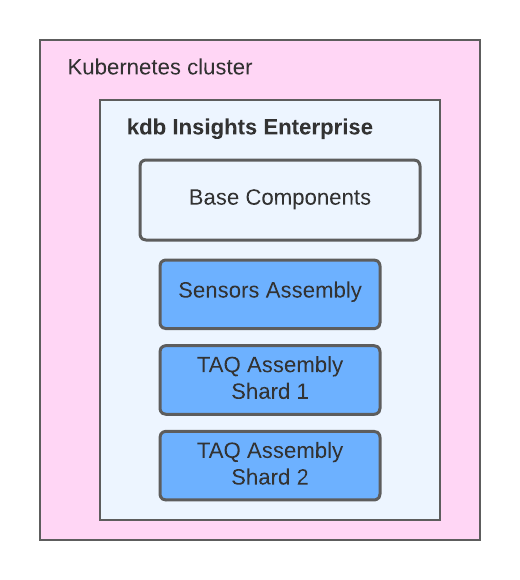
kdb Insights Enterprise architecture
kdb Insights Enterprise provides the following core components that are used to create data-capture and analytics workflows:
- Databases (Storage Manager and Data Access)
- Streams (Reliable Transport)
- Pipelines (Stream Processor)
These are grouped into an assembly (similar to a database shard). A single kdb Insights Enterprise installation can deploy any number of these assemblies, for either related or disjointed data-sets.
Dynamic workload creation
The life cycle of each assembly deployed into kdb Insights Enterprise is managed by an internal Kubernetes operator. The operator takes care of creation and placement of all required configuration files, deployments, and services, to bring an end-to-end data workflow online. The configuration of these workloads can be changed dynamically, and kdb Insights Enterprise automatically updates the underlying workflow components.
Data capture
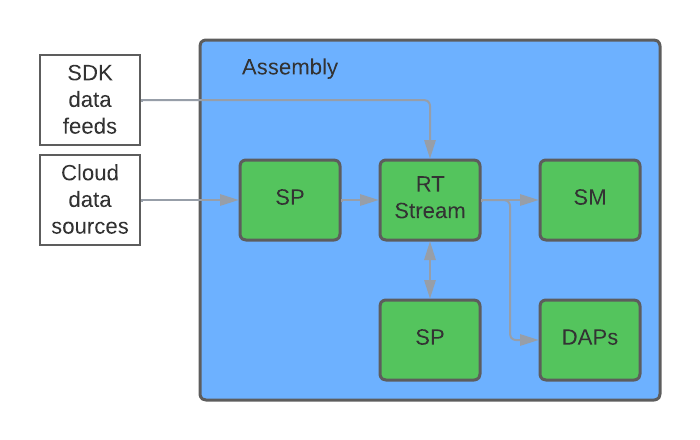
The Stream Processor is used for getting data in, streaming data out, and creating streaming analytics such as derived data and alerts. Multiple input and output sources are built-in. For anything not built-in, data can be written directly to a Stream (Reliable Transport) via the C or Java RT SDK. The Stream Processor can then read the data from that stream if required, or it can be written directly into a database.
Data exploration
Each assembly is associated with a label set (a key/value set) of metadata which associates it with other assemblies that have an overlapping subset of labels. This allows queries to target a single assembly, or aggregate across multiple assemblies by specifying the common label set between assemblies.

Scalability
kdb Insights Enterprise is built on top of Kubernetes, allowing scaling and orchestration to be handled by the underlying cloud platform. kdb Insights Enterprise leverages this capability by allowing scaling for a number of purposes.
Scaling for query load
Each assembly database takes the form of a single-writer, many-reader paradigm, with each of these being kdb+ processes.
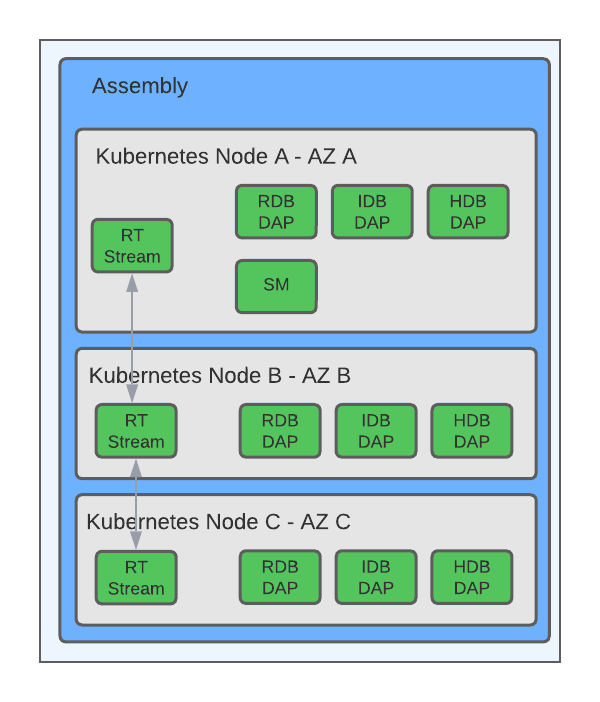
Data is split into temporal tiers and automatically migrated between tiers (the most immediate data is held in memory, daily data is held on disk partitioned by arrival bucket, and historical data is held on disk and in object storage partitioned by arrival date). Each of these ranges is surfaced for queries by a separate class of data access process (RDB, IDB, and HDB respectively). Each of these allows multiple dynamic replicas to be set, and this number can change as required.
Data is written to fast shared storage, allowing query processes to span multiple nodes.
Scaling for increased ingestion
As data sizes grow for a given dataset, or if new datasets are added to an existing deployment, kdb Insights Enterprise can scale horizontally to accommodate the additional data.
Since each assembly database is a single writer, kdb Insights Enterprise scales for additional ingestion by creating more assemblies.
Fault tolerance
kdb Insights Enterprise is designed with process level redundancy and node assignment in mind; this allows for individual process, node, and availability zone failure without impacting primary data functionality.
All assembly components allow multiple redundant replicas:
- Multiple Stream (Reliable Transport) replicas making use of RAFT for coordination
- Optional multiple DAP database read replicas
- Optional multiple Stream Processor replicas with output deduplication handled by the receiving stream
The exception is the database writer (Storage Manager), which is a single replica within each assembly. However, since the writer is not visible to queries, a failure or rescheduling of the writer does not impact ingestion and query workloads. This is because Kubernetes and the kdb Insights Operator bring the writer back online on a working node. During this time, additional data is held in memory in the real-time (RDB) data tier. When the writer comes back online, it continues to write data from the point where it left off.