Historical database¶
A historical database (HDB) holds data before today, and its tables would be stored on disk, being much too large to fit in memory. Each new day’s records would be added to the HDB at the end of day.
Typically, large tables in the HDB (such as daily tick data) are stored splayed, i.e. each column is stored in its own file.
Knowledge Base: Splayed tables
Q for Mortals: §11.3 Splayed Tables
Typically also, large tables are stored partitioned by date. Very large databases may be further partitioned into segments, using par.txt.
These storage strategies give best efficiency for searching and retrieval. For example, the database can be written over several drives. Also, partitions can be allocated to secondary threads so that queries over a range of dates can be run in parallel. The exact set-up would be customized for each installation.
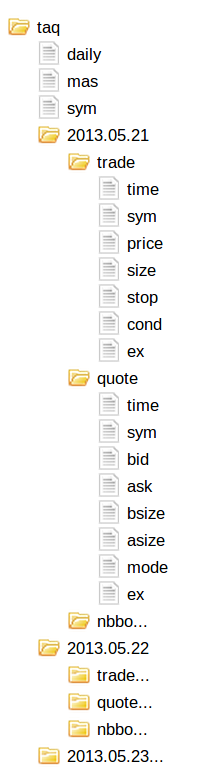
For example, a simple partitioning scheme on a single disk might be as shown right. Here, the daily and master tables are small enough to be written to single files, while the trade and quote tables are splayed and partitioned by date.
Sample partitioned database¶
The script KxSystems/cookbook/start/buildhdb.q builds a sample HDB.
It builds a month’s random data in directory start/db.
Load q, then:
q)\l buildhdb.qTo load the database, enter:
q)\l start/dbIn q (actual values may vary):
q)count trade
369149
q)count quote
1846241
q)t:select from trade where date=last date, sym=`IBM
q)count t
1017
q)5#t
date time sym price size stop cond ex
---------------------------------------------------
2013.05.31 09:30:00.004 IBM 47.38 48 0 G N
2013.05.31 09:30:01.048 IBM 47.4 56 0 9 N
2013.05.31 09:30:01.950 IBM 47.38 89 0 G N
2013.05.31 09:30:02.547 IBM 47.36 70 0 9 N
2013.05.31 09:30:03.448 IBM 47.4 72 0 N N
q)select count i by date from trade
date | x
----------| -----
2013.05.01| 15271
2013.05.02| 15025
2013.05.03| 14774
2013.05.06| 14182
...
q)select cnt:count i,sum size,last price, wprice:size wavg price by 5 xbar time.minute from t
minute| cnt size price wprice
------| -----------------------
09:30 | 44 2456 47.83 47.60555
09:35 | 27 1469 47.74 47.77138
09:40 | 17 975 47.84 47.87198
09:45 | 19 1099 47.84 47.78618
...Join trades with the most recent quote at time of trade (as-of join):
q)t:select time,price from trade where date=last date,sym=`IBM
q)q:select time,bid,ask from quote where date=last date,sym=`IBM
q)aj[`time;t;q]
time price bid ask
------------------------------
09:30:00.004 47.38 47.12 48.01
09:30:01.048 47.4 46.91 47.88
09:30:01.950 47.38 46.72 47.99
09:30:02.547 47.36 47.33 47.46
...Sample segmented database¶
The buildhdb.q script can be customized to build a segmented database.
In practice, database segments should be on separate drives, but for illustration, the segments are here written to a single drive.
Both the database root, and the location of the database segments need to be specified.
For example, edit the first few lines of the script KxSystems/cookbook/start/buildhdb.q as below.
dst:`:start/dbs / new database root
dsp:`:/dbss / database segments directory
dsx:5 / number of segments
bgn:2010.01.01 / set 4 years data
end:2013.12.31
...Ensure that the directory given in dsp is the full pathname, and that it is created, writeable and empty. For Windows, dsp might be: dsp:`:c:/dbss.
This example writes approximately 7GB of created data to disk.
Load the modified script, which should now take a minute or so. This should write the partitioned data to subdirectories of the directory specified by dsp
par.txt can be found within the dsp directory, which lists the disks/directories containing the data of the segmented database.
/dbss/d0
/dbss/d1
/dbss/d2
/dbss/d3
/dbss/d4Restart q, and load the segmented database:
q)\l start/dbs
q)(count quote), count trade
61752871 12356516
q)select cnt:count i,sum size,size wavg price from trade where date in 2012.09.17+til 5, sym=`IBM
cnt size price
--------------------
4033 217537 37.35015