Azure Data Factory
kdb Insights Enterprise can integrate with the Azure Data Factory (ADF). You can use the ADF to ingest any data into kdb Insights Enterprise, particularly if you have data in a format for which there is no native reader in kdb Insights Enterprise today. Your ADF pipeline can transform the data into a supported format and then trigger the ingestion into kdb Insights Enterprise.
Introduction
This example shows you how to use ADF to watch a specific container within an Azure Storage Account and trigger when .csv files, containing data to be ingested, are uploaded.
When the ADF pipeline is triggered, the following sequence of events occurs:
- The ADF pipeline authenticates against a target kdb Insights Enterprise.
- If the targeted assembly is not running, the ADF pipeline starts and monitors the assembly until it is in a ready state before continuing.
- Once the assembly is running, the kdb Insights Enterprise pipeline that is defined as part of the factory definition, is triggered. This kdb Insights Enterprise pipeline does the following:
- Reads the recently uploaded .csv file from blob storage
- Attempts to ingest the data into a specified table within the targeted assembly
- The kdb Insights Enterprise pipeline status is monitored during execution.
- Upon completion of the kdb Insights Enterprise pipeline, it is torn down and you can query it using any of the querying methods available, including the UI and REST.
Schemas must match
The schema of the .csv must match the schema of the table being written to. Type conversion is not performed by the pipeline.
Limitations
-
The Azure Data Factory can start a stopped assembly, or work with an already running and ready assembly. It does not currently have the ability to distinguish when an assembly has been started but is not in a ready state. Ensure the assembly is either running and ready, or stopped completely when triggering ingestion.
-
The kdb Insights Enterprise pipeline uses HDB Direct Write. Historical data will be written directly to disk, but data will not be available to be queried until the pipeline has finished running and postprocessing is completed.
Prerequisites
The following prerequisites are required before deploying the example:
-
azcli should be configured locally. -
An Azure storage account and container from which to read .csv files must exist.
-
A resource group to deploy the ADF into should exist. The kdb Insights Enterprise resource group may be used for this, or you can create a new group.
Reducing latency when using a separate resource group
If a separate group is required, consider creating it in the same location to reduce latency.
The following command can be used to create a new group:
az group create -l $location -g $adfResourceGroupName -
The following files need to be downloaded and accessible to the
azclient:-
Azure Data Factory resource: main.bicep
-
Parameters file: main.parameters.json
-
-
Configure the parameters defined in the json file.
-
kdb Insights Enterprise must be deployed and running.
-
The target assembly must either be in a ready state or stopped. As mentioned previously, if it is not running it will be started by the factory.
-
The schema, table and database being written to must exist.
Schemas must match
The schema of the .csv must match the schema of the table being written to for the ingestion to be successful. Type conversion is not performed by the pipeline.
-
A user or service account must exist. This client is used by the factory to authenticate against kdb Insights Enterprise. It must have the following application roles in Keycloak as a minimum:
-
insights.builder.assembly.get
-
insights.builder.assembly.list
-
insights.builder.schema.get
-
insights.builder.schema.list
-
insights.pipeline.get
-
insights.pipeline.create
-
insights.pipeline.delete
-
insights.pipeline.status
-
insights.builder.assembly.deploy
-
insights.query.data
-
Parameters
The downloaded version of main.parameters.json needs to be updated with the following parameters. They are divided into two main categories:
-
Variables required to correctly interact with kdb Insights Enterprise:
-
baseUrl: Base kdb Insights Enterprise URL. Ensure this does not contain a trailing slash.
-
clientId: Keycloak client ID as configured during prerequisites
-
clientSecret: Keycloak client secret as configured during prerequisites
-
assemblyName: Target assembly containing table/database to write to
-
tableName: Table to write to
-
-
Variables required to correctly interact with Azure:
-
containerName: Name of the container to be monitored for .csv file uploads
-
storageAccountKey: Shared key used to access the storage account
-
triggerScope: the resource ID of the storage account to be monitored for uploads
This can be retrieved using:
az storage account show \ -g $storageAccountResourceGroup \ -n $storageAccountName --query id -o tsv
-
Instructions
-
Ensure the
azcli is configured to operate on the desired subscription:az account set --subscription $adfSubscriptionId -
Deploy the Azure Data Factory. Run the following command to input the parameters using stdin:
az deployment group create \ --resource-group $adfResourceGroupName \ --template-file main.bicep \ --parameters main.parameters.jsonRemember the resource group name
Keep a note of the resource group name the factory is being deployed to, as it is required in the next step.
Alternatively, combine with the
-pflag to set individual values, or use the parameters file with@main.parameters.jsonsyntax.Upon completion, the ADF will be accessible from the Resource Group. Launching the studio will allow the pipelines to be inspected in the Author view:
-
Activate the trigger. This is required for the ADF to start listening to upload events on the storage account. The resource group needs to be the name of the group used in the previous step.
az datafactory trigger start \ --factory-name $adfFactoryName \ --resource-group $adfResourceGroupName \ --name 'csv_blob_created_trigger'
If these steps complete without error, .csv files are ready to be uploaded.
Monitoring
ADF pipeline runs can be monitored using the Monitor section in ADF:
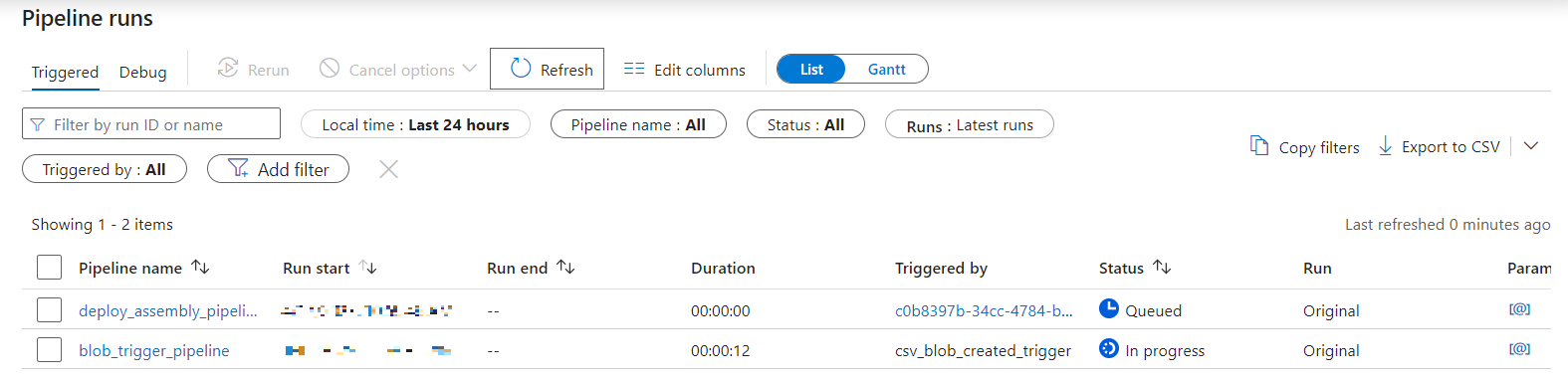
kdb Insights Enterprise pipeline creation and status can be monitored from the Overview page:

The Monitor section of ADF shows the following upon success:
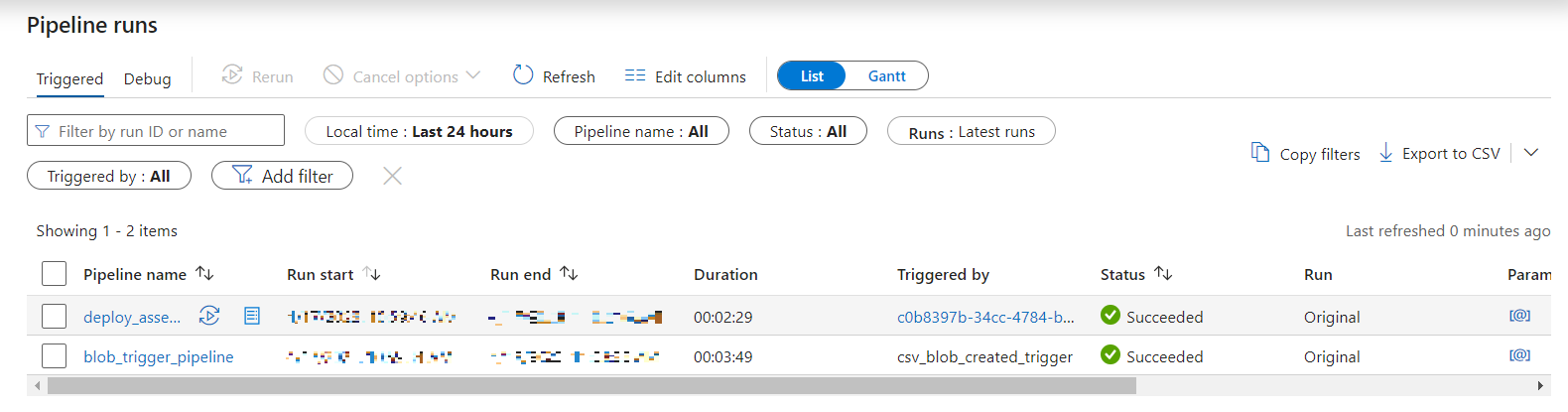
Pipelines that remain running
The kdb Insights Enterprise pipeline is torn down upon successful completion, if this does not occur, the pipeline remains running in kdb Insights Enterprise and logs should be inspected to determine the cause.