Object Storage (Weather)
No kdb+ knowledge required
This example assumes no prior experience with q/kdb+ and you can replace the url provided with any other Object Storage url to gain similar results.
What is Object Storage?
As the volume of business data continues to double every year, organizations need new technologies that can balance performance, control, security and compliance needs while helping to reduce the cost of managing and storing vast amounts of business data.
In short, it is storage for unstructured data that eliminates the scaling limitations of traditional file storage. Limitless scale is the reason that object storage is the storage of the cloud. All of the major public cloud services, including Amazon, Google and Microsoft, employ object storage as their primary storage.
Weather Dataset
The KX Insights Platform helps users take advantage of object storage natively, the Evangelism team has provided a demo Weather dataset stored using Object Storage. Below is the config to read from a dataset showing recorded temperatures in NYC over the past day.
Ingesting Data
Importing
Select Import from the Overview panel to start the process of loading in new data.
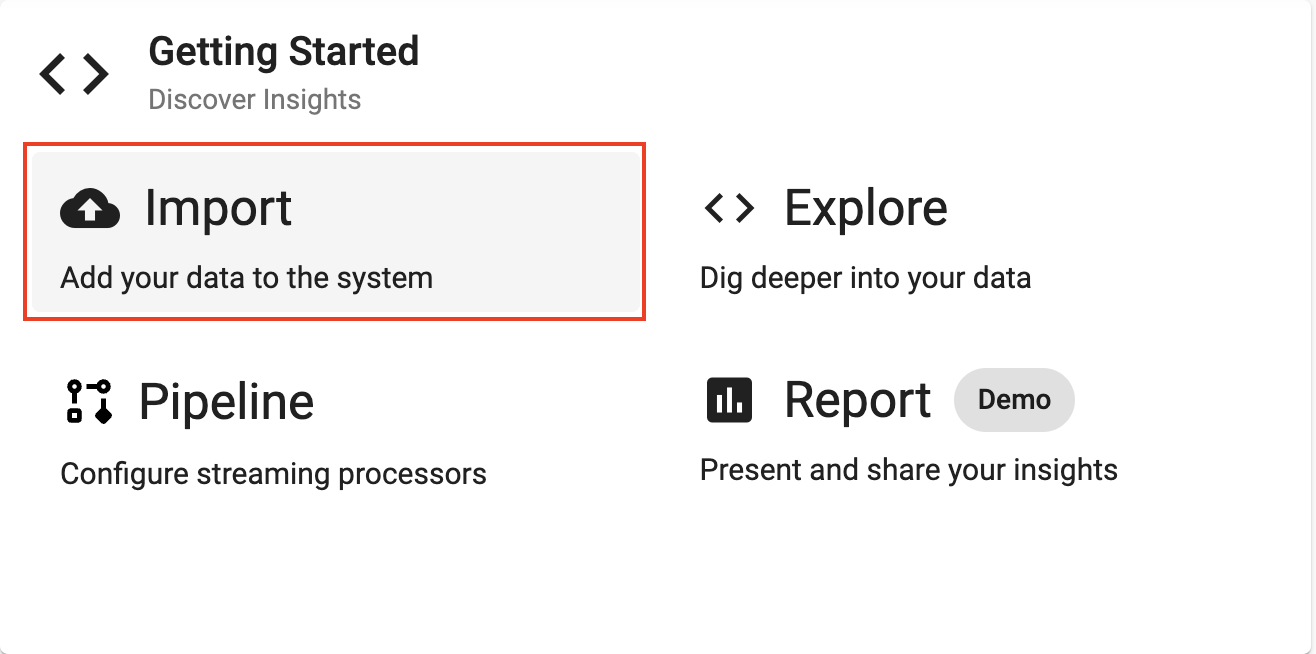
Select one of the following platforms below and enter the correspondoing details listed to connect to the datasource.
| Setting | value |
|---|---|
| Path* | gs://kxevg/weather/temp.csv |
| Project ID | kx-evangelism |
| File Mode* | Binary |
| Offset* | 0 |
| Chunking* | Auto |
| Chunk Size* | 1048576 |
 |
| Setting | value |
|---|---|
| Path* | ms://kxevg/temp.csv |
| Account | kxevg |
| File Mode* | Binary |
| Offset* | 0 |
| Chunking* | Auto |
| Chunk Size* | 1048576 |
 |
| Setting | value |
|---|---|
| Path* | s3://kxevangelism/temp.csv |
| Region* | eu-west-1 |
| File Mode* | Binary |
| Offset* | 0 |
| Chunking* | Auto |
| Chunk Size | 1048576 |
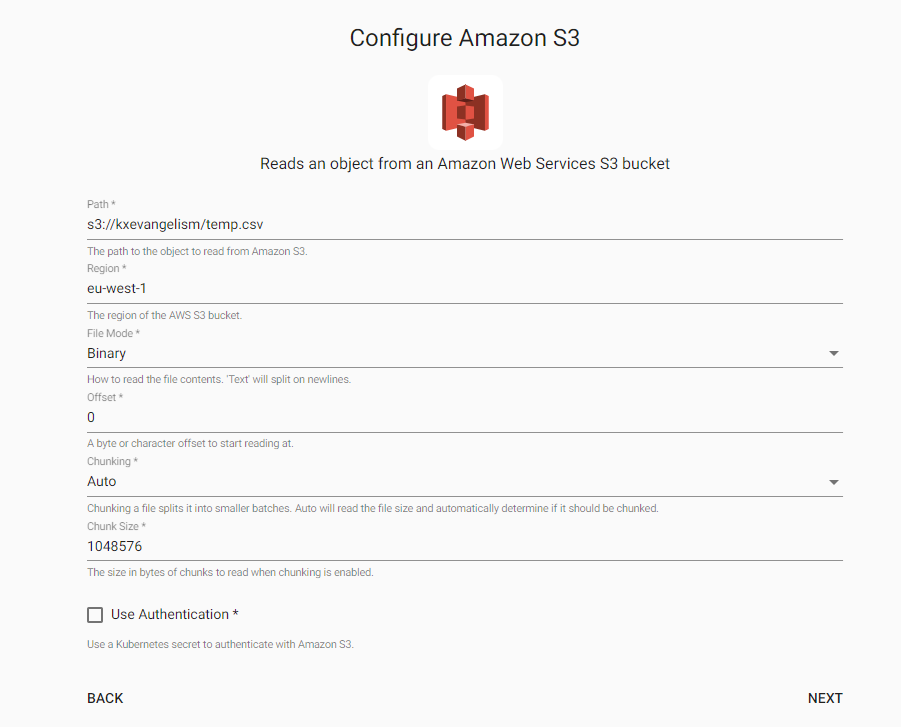 |
Decoding
Select the CSV Decoder option so you can define the schema types as outlined in the table schema.
| setting | value |
|---|---|
| Delimiter | , |
| Header | First Row |
| Schema | PSFSSFFS |
| Type | String |

Transforming
The next screen that comes up is Configure Schema. This is a useful tool that transforms the upstream data to the correct datatype of the destination database.
For this example you can untick the "Apply A Schema" option at the top right and hit 'Next' as this step is not required for this dataset. But we will see this in action in future examples.
Writing
Finally, from the dropdown select the insights-demo database and the weather table to write this data to and select 'Open Pipeline'.
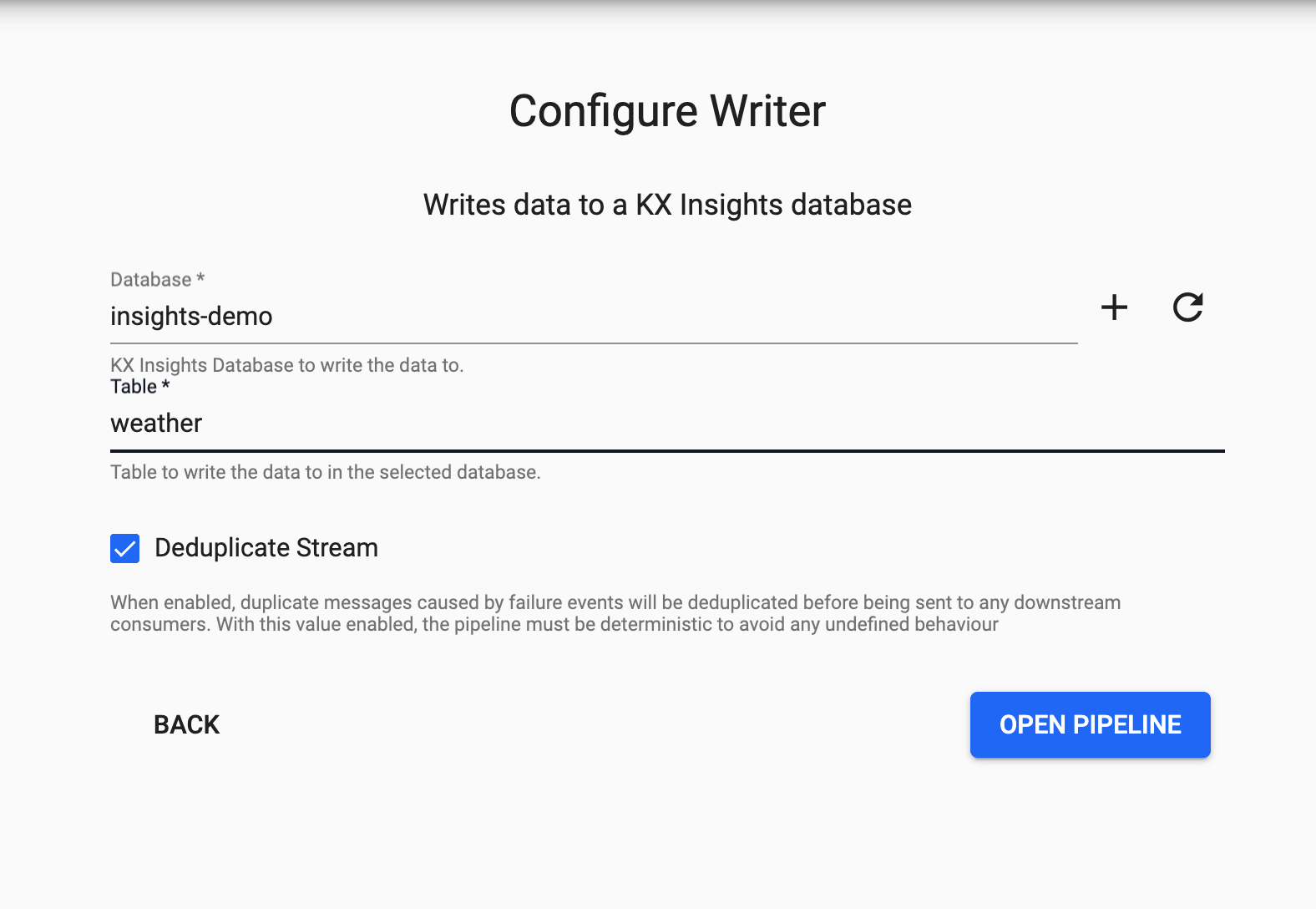
Deploying
The next step is to deploy your pipeline that has been created in the above Importing stage.
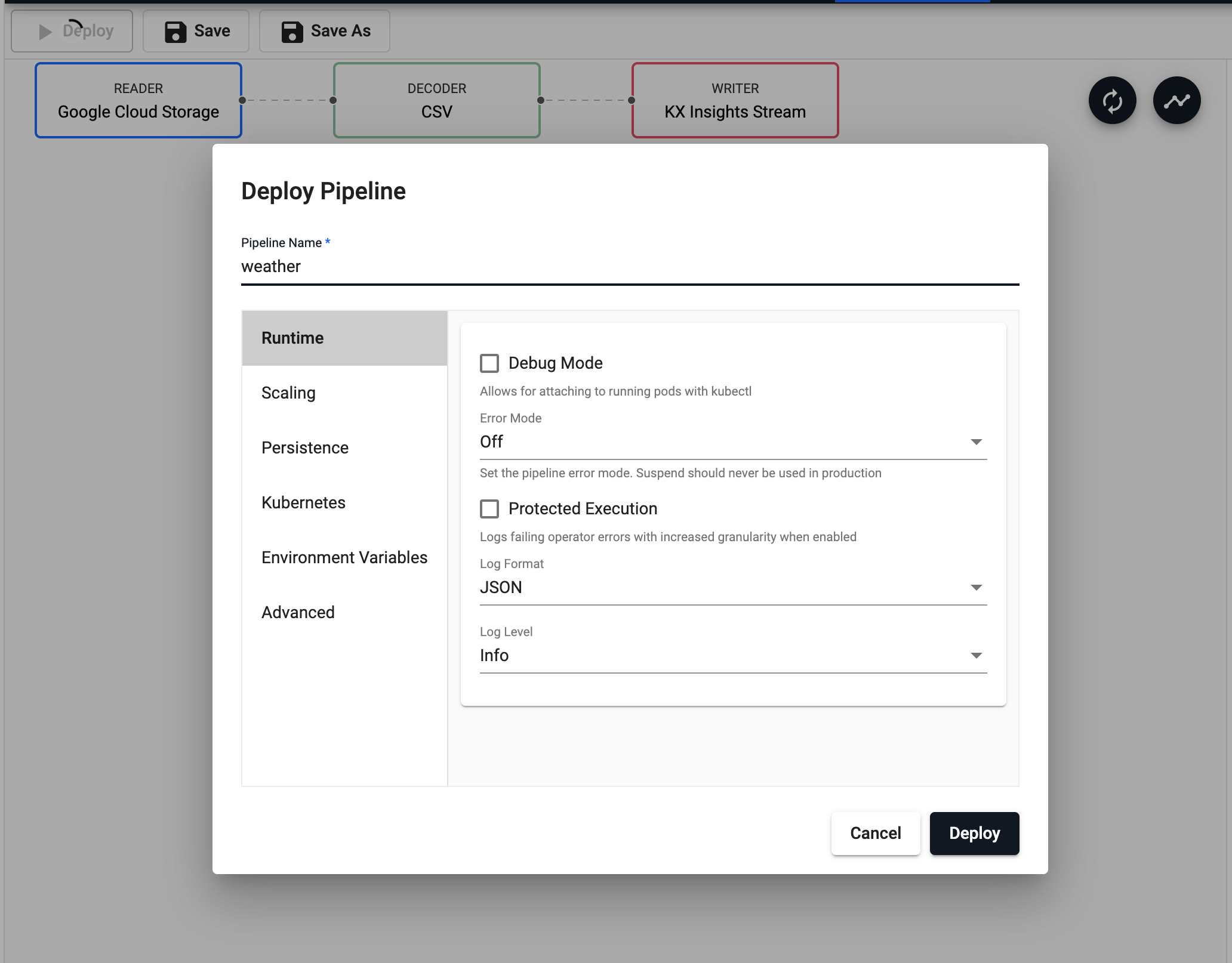
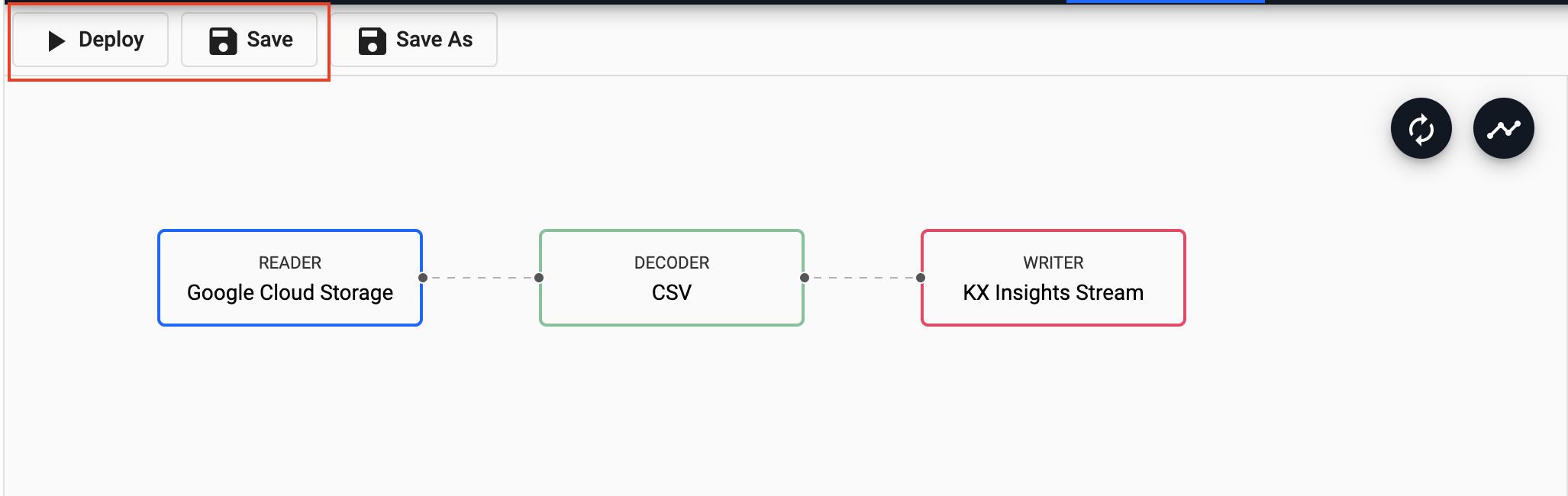 You can first Save your pipeline giving it a name that is indicative of what you are trying to do. Then you can select Deploy.
You can first Save your pipeline giving it a name that is indicative of what you are trying to do. Then you can select Deploy.
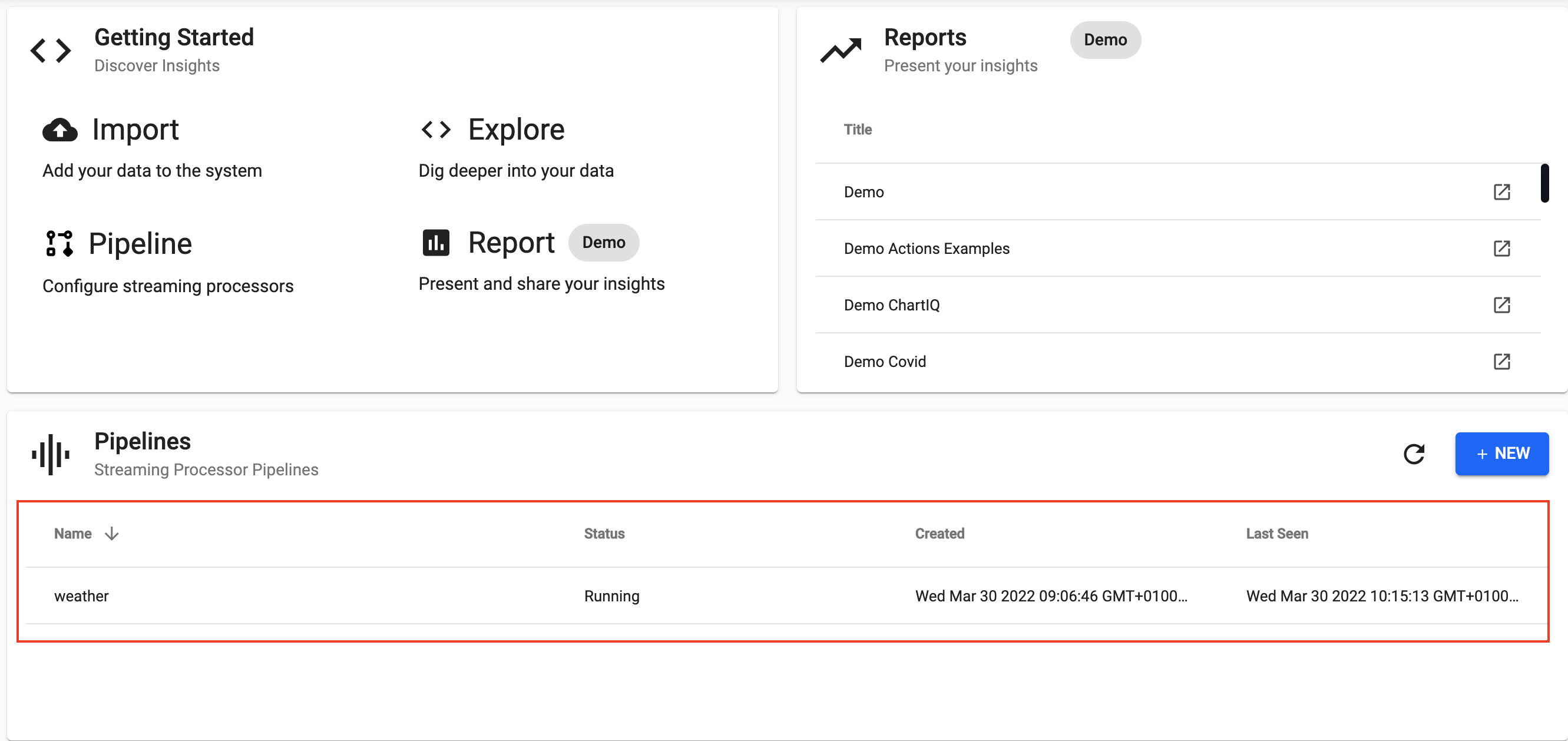
 Once deployed you can check on the progress of your pipeline back in the Overview pane where you started. When it reaches
Once deployed you can check on the progress of your pipeline back in the Overview pane where you started. When it reaches Status=Running then it is done and your data is loaded.
Exploring
Select Explore from the Overview panel to start the process of exploring your loaded data.
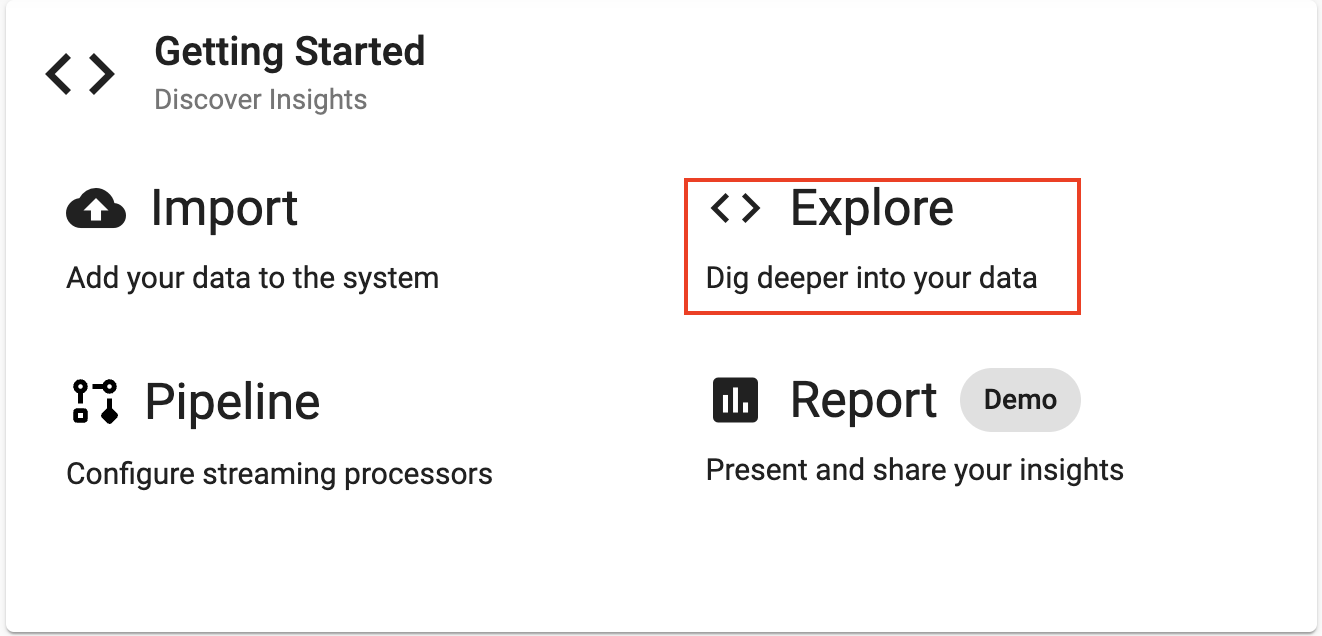
First select insights-demo from the assembly dropdown on the top left hand side.
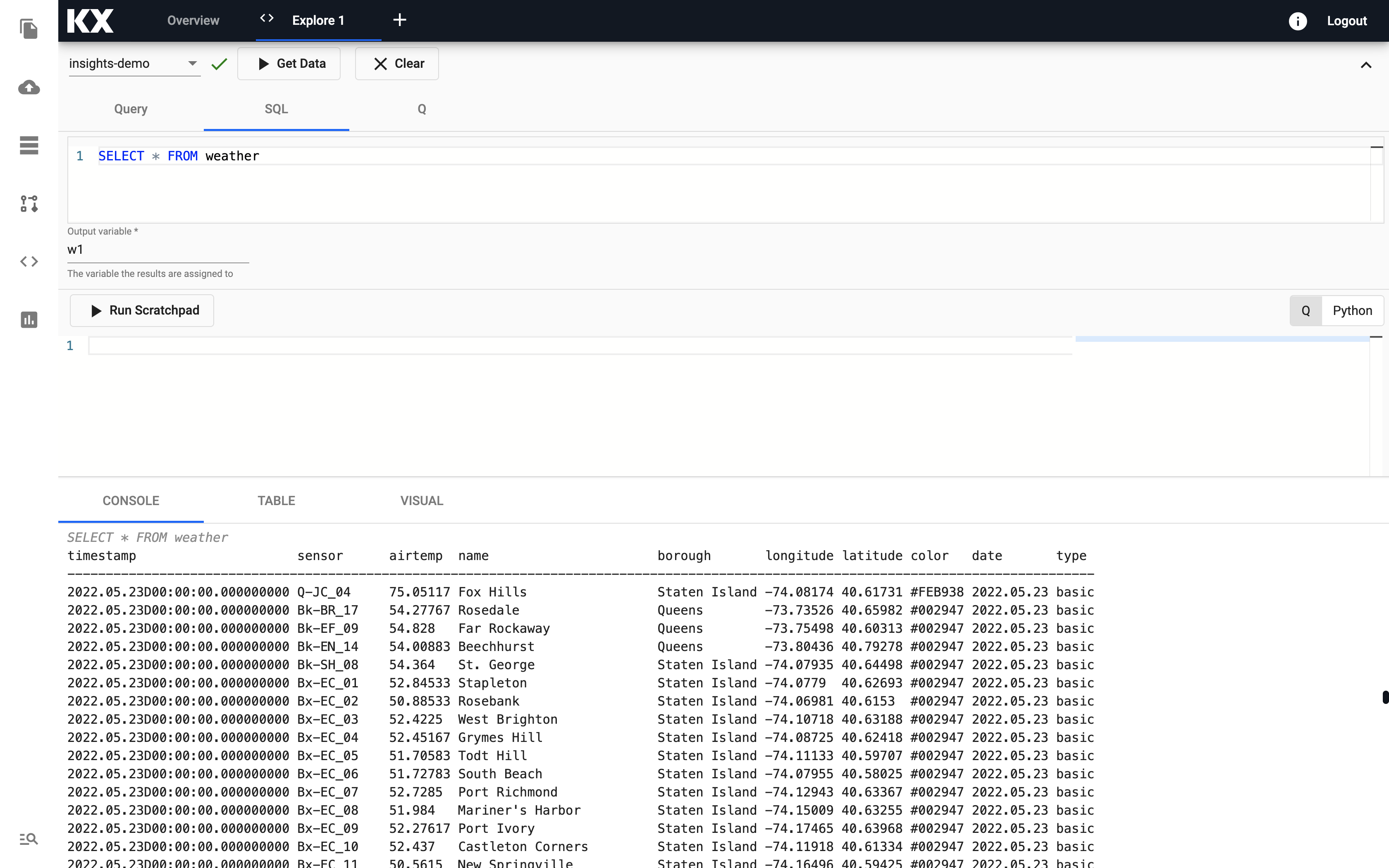
In the Explore tab there are a few different options available to you, Query, SQL and q. Let's look at SQL. You can run the following SQL to retrieve all records from the weather table.
SELECT * FROM weatherNote that you will need to define an Output Variable and then select Get Data to execute the query.
Refresh Browser
If the database or tables are not appearing in the Explore tab as expected - it is a good idea to refresh your browser and retry.
Troubleshooting
If the database or tables are still not outputting after refreshing your browser, try our Troubleshooting page.
Let's ingest some more data! Try next with the live Kafka Subway Data.