Get Data - Protocol Buffers
The purpose of this walkthrough is to guide you through the steps to create a pipeline to ingest Protocol buffers data into kdb Insights Enterprise.
Protocol buffers are Google's language-neutral, platform-neutral, extensible mechanism for serializing structured data. We have provided a crime data set, for use in this walkthrough, which is a record of events from March 31st 2022 in NYC, organized by precinct, including location coordinates of the call, dispatch times and a description of the crime.
No kdb+ knowledge required
No prior experience with q/kdb+ is required to build this pipeline.
Before you build your pipeline you must ensure the insights-demo database is created, as described here.
Create a pipeline
Open the Pipeline editor from the ribbon menu [+], or from the left-hand Pipeline menu, as shown below.
Add an Expression node
-
Click-and-drag an Expression node, from the Readers, into the workspace.
-
Click on the Expression and add the following
qcode to the Configure Expression Node panel. This code pulls in the crime data set.URL:"https://code.kx.com/kxiwalkthrough/data/crime.msg"; resp:.kurl.sync[(URL;`GET;(::))]; if[200 <> first resp; ' last resp]; "\n" vs last resp -
Click Apply to apply these changes to the node.
Add a Decoder node
The output from the Expression node resembles a binary format. The next step is to add a Decoder node which reads in this data in a format compatible with kdb+.
-
Click-and-drag the Protocol Buffers decoder node, from the list of Decoders into the central workspace, and connect it to the Expression node.
-
Select the Decoder node.
-
Add the following settings to the right-hand property panel:
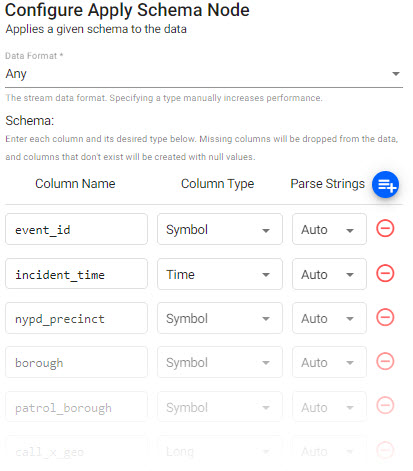
setting value Message Name crime Message Definition copy the JSON code block below As List disabled syntax = "proto3"; message crime { uint64 event_id = 1; string incident_time = 2; uint64 nypd_precinct = 3; string borough = 4; string patrol_borough = 5; uint64 call_x_geo = 6; uint64 call_y_geo = 7; string radio_code = 8; string description = 9; string crime_in_progress = 10; string call_timestamp = 11; string dispatch_timestamp = 12; string arrival_timestamp = 13; string closing_timestamp = 14; double latitude = 15; double longitude = 16; } -
Click Apply to apply these values to the node.
Add a Transform Node
The next step adds a Transformer node which transforms the crime data fields to kdb+ types compatible with the insights-demo kdb database.
-
Click-and-drag the Apply Schema node from the list of Transform nodes and connect it to the Decoder node.
insights-demohas a predefined schema forcrimedata which transforms the data to a kdb+/q format. -
Select the Apply Schema node.
-
In the Configure Apply Schema Node section leave the Data Format setting set to
Any. -
Click the Load Schema icon
 , select the
, select the insights-demodatabase and thecrimetable from the dropdowns as shown below.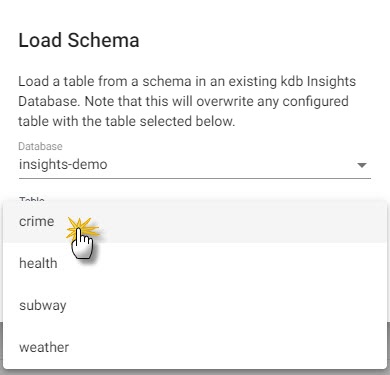
-
Click Load.
-
Click Apply to apply changes to the node.
Add a Writer Node
The next step is to add a Writer node which writes the transformed crime data to the kdb Insights Enterprise database.
-
Click-and-drag the kdb Insights Database node from the list of Writer nodes into the workspace and connect it to the Transform node.
-
Select the Writer node and add the following settings to the right-hand Configure kdb Insights Database property panel:
setting value Database insights-demo Table crime Write Direct to HDB No Deduplicate Stream Yes Set Timeout Value No -
Click Apply to apply these settings to the node.
Review the Pipeline
The final pipeline looks like this:

Save the Pipeline
You now need to save and deploy your Pipeline.
-
Enter a unique Name for the pipeline, in the top left of the workspace. For example, crime-1.
-
Click Save.
Deploy the Pipeline
You can now deploy the pipeline which reads the data from its source, transforms it to a kdb+ compatible format, and writes it to a kdb Insights Enterprise database.
- Click Save & Deploy in the top panel.
Note
It may take Kubernetes several minutes to spin up the necessary resources to deploy the pipeline.
-
You can check the progress of the pipeline under the Running Pipelines panel of the Overview tab. The data is ready to query when Status = Running.
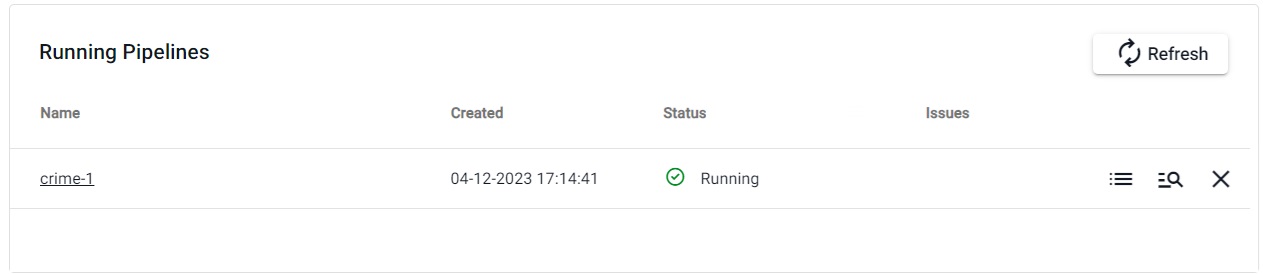
Pipeline warnings
Once the pipeline is running some warnings may be displayed in the Running Pipelines panel of the Overview tab, these are expected and can be ignored.
Next Steps
Now that your Pipeline is up and running you can:
- Query the data.
- Build a visualization from the data.
Further Reading
Use the following links to learn more about: - View (Dashboard) components