Developing in the Scratchpad using Python
This section guides you through the execution of Python code and APIs using the Scratchpad.
The Python environment in the Scratchpad offers a unique, self-contained location where you can assign variables and create analyses that are visible only to you.
The following sections describe how to:
- Execute code using Python in the Scratchpad
- Interact with custom code using Packages
- Develop machine learning workflows using the Machine Learning Core APIs
- Include q in your Python code using PyKX
- Develop Stream Processor pipelines using the Stream Processor Python API.
- Debug UI Pipelines
For information on data visualization and console output in the Scratchpad see here.
If you primarily develop in q see here.
Execute Python code
When executing code in the Scratchpad, keep these key points in mind:
- The Python language is highlighted within the Scratchpad to indicate the use of Python code.
- Use Ctrl + Enter or Cmd + Enter, depending on OS, to execute the current line or selection. You can execute the current line without selecting it.
- Click Run Scratchpad to execute everything in the editor.
Available Python Libraries
The Scratchpad supports the libraries currently installed within the Scratchpad image. The following is a selection of the most important data-science libraries included:
- Machine learning libraries: keras, scikit-learn, tensorflow-cpu, xgboost
- Data science libraries: numpy, pandas, scipy, statsmodels, h5py (numerical data storage), pytz (for working with timezones)
- Natural language processing: spacy (parsing, tokenizing, named entity recognition), beautifulsoup4 (HTML and XML parsing)
- Insights and kdb+ integration: kxi (the stream processor and assorted Insights-specific functionality), pykx (allows running q and Python code in the same process)
For the complete list, with versions, run the following in a scratchpad
import pkg_resources
"\n".join(sorted([package.key + "==" + package.version for package in pkg_resources.working_set]))
The Scratchpad does not currently support the integration of your own Python library.
Interact with custom code
By using Packages you can add custom code to kdb Insights Enterprise for use in:
- The Stream Processor when adding custom streaming analytics
- The Database for adding custom queries.
The Scratchpad also has access to these APIs allowing you to load custom code and access user-defined functions when prototyping workflows for the Stream Processor or developing analytics for custom query APIs.
The example below demonstrates a Scratchpad workflow that utilizes both the packages and UDF APIs available within the Scratchpad.
This example shows a package named "ml", containing two functions that increment every value in the input by one. They are each passed a q table of two columns, each with five random numbers between 0 and 1. The functions return the incremented values.
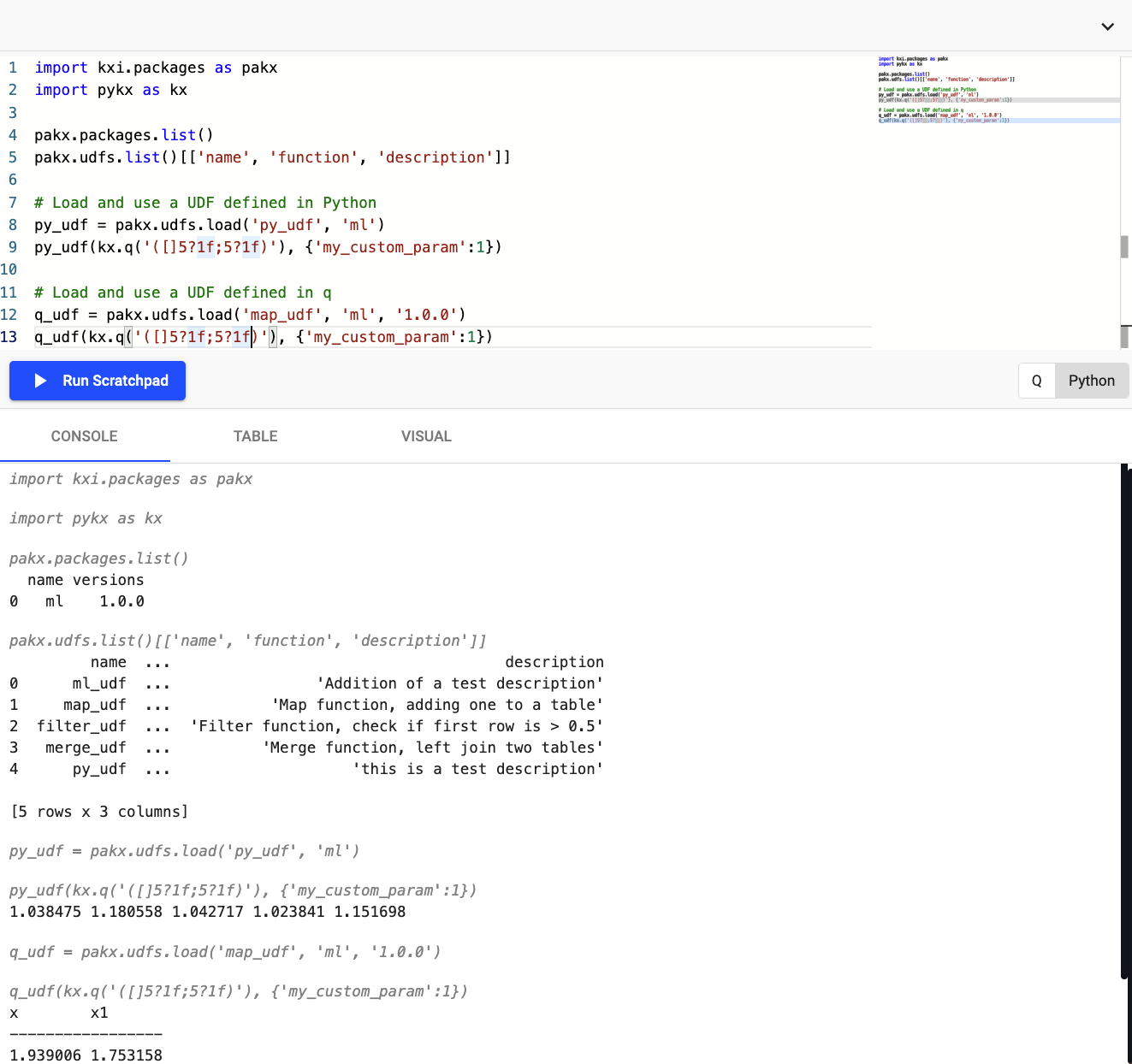
Develop machine learning workflows
The Scratchpad has access to a variety of machine learning libraries developed by the Python community and by KX. Specifically, you can use the KX ML Python library to access its Model Registry functionality as well as some of the most used machine learning and NLP Python libraries:
| library | version |
|---|---|
| beautifulsoup4 | 4.11.2 |
| keras | 2.11.0 |
| numpy | 1.22.4 |
| pandas | 1.4.4 |
| scikit-learn | 1.5.1 |
| scipy | 1.7.3 |
| spacy | 3.6.1 |
| statsmodels | 0.13.1 |
| tensorflow-cpu | 2.11.1 |
| xgboost | 1.6.2 |
The example below shows how you can use this functionality to preprocess data, fit a machine learning model, and store this ephemerally within your Scratchpad session. (Note that storing models in this manner results in them being lost upon restarting the Scratchpad pod.)
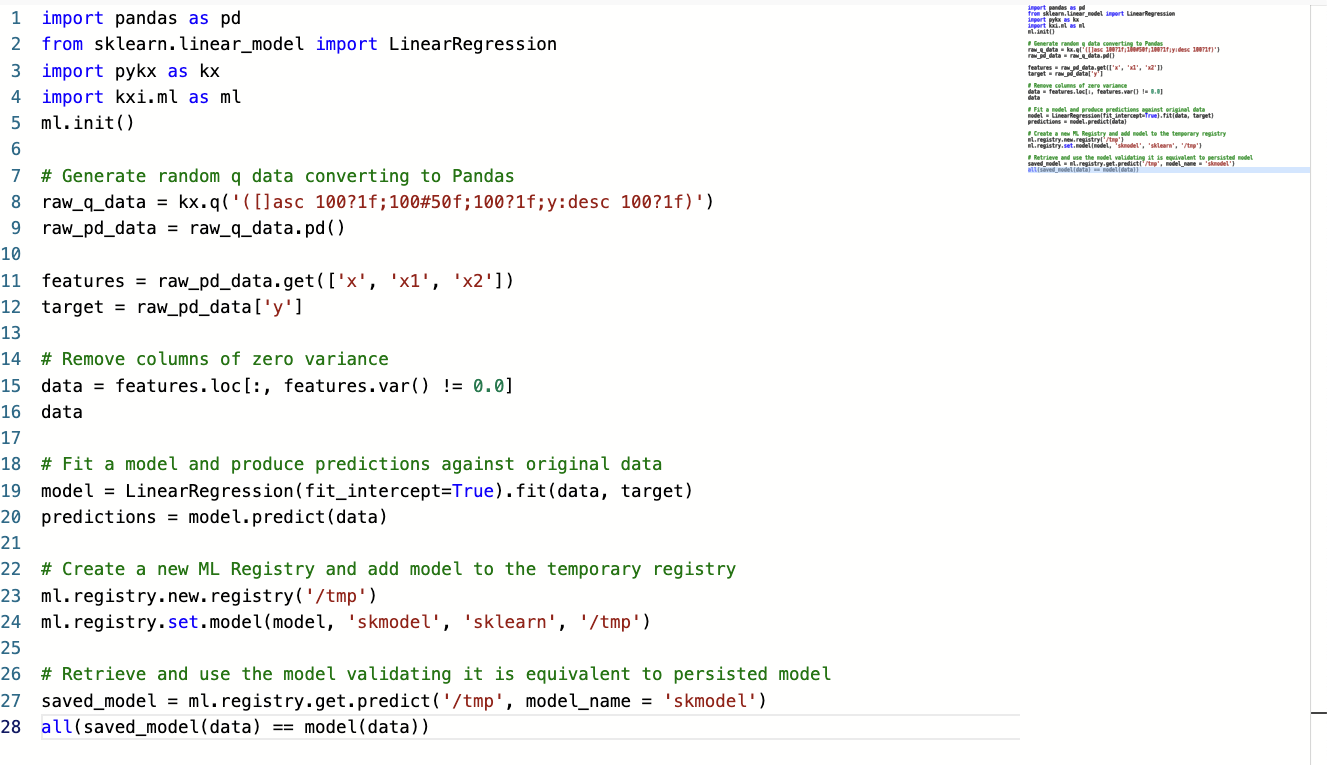
Code snippet for ML Scratchpad example
Use the following code to replicate the behavior illustrated in the screenshot above:
import pandas as pd
from sklearn.linear_model import LinearRegression
import pykx as kx
import kxi.ml as ml
ml.init()
# Generate random q data converting to Pandas
raw_q_data = kx.q('([]asc 100?1f;100#50f;100?1f;y:desc 100?1f)')
raw_pd_data = raw_q_data.pd()
features = raw_pd_data.get(['x', 'x1', 'x2'])
target = raw_pd_data['y']
# Remove columns of zero variance
data = features.loc[:, features.var() != 0.0]
data
# Fit a model and produce predictions against original data
model = LinearRegression(fit_intercept=True).fit(data, target)
predictions = model.predict(data)
# Create a new ML Registry and add model to the temporary registry
ml.registry.new.registry('/tmp')
ml.registry.set.model(model, 'skmodel', 'sklearn', '/tmp')
# Retrieve and use the model validating it is equivalent to persisted model
saved_model = ml.registry.get.predict('/tmp', model_name = 'skmodel')
all(saved_model(data) == model.predict(data))
Include q code in Python development
Should your workflow require it, you can tightly integrate q code and analytics within your Python code using PyKX. This library, included in the Scratchpad, allows you to develop analytics in q to operate on your Python or q data.
By default, database queries following the querying databases guide return data as a PyKX object rather than a Pandas DataFrame. Therefore, it may be more efficient to perform data transformations and analysis using q in PyKX before converting to Pandas/Numpy for further development.
The following basic example shows usage of the PyKX interface to interrogate data prior to conversion to Pandas:
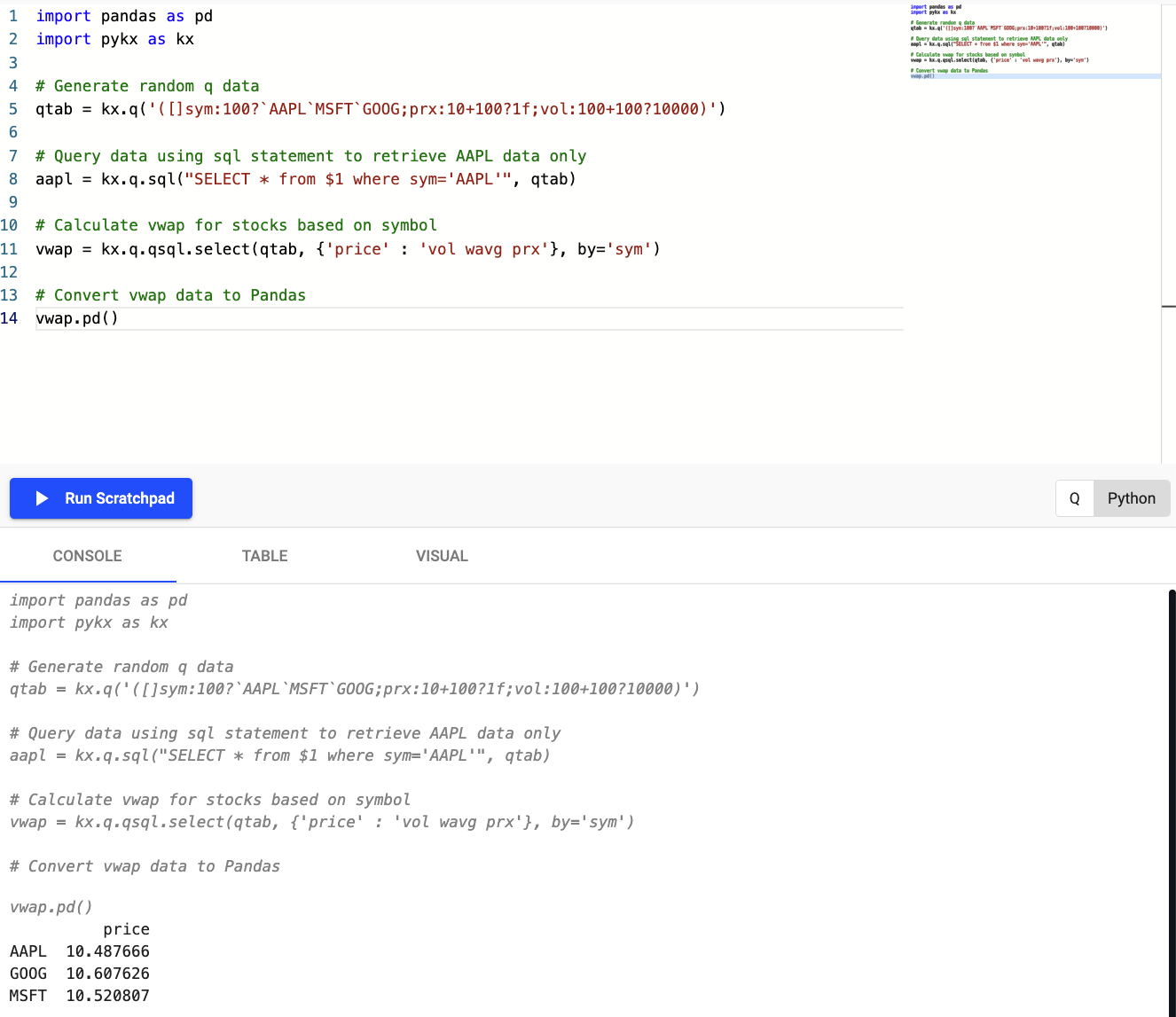
Code snippet for PyKX usage within Python Scratchpad
Use the following code to replicate the behavior illustrated in the screenshot above:
import pandas as pd
import pykx as kx
# Generate random q data
qtab = kx.q('([]sym:100?`AAPL`MSFT`GOOG;prx:10+100?1f;vol:100+100?10000)')
# Query data using sql statement to retrieve AAPL data only
aapl = kx.q.sql("SELECT * from $1 where sym='AAPL'", qtab)
# Calculate vwap for stocks based on symbol
vwap = kx.q.qsql.select(qtab, {'price' : 'vol wavg prx'}, by='sym')
# Convert vwap data to Pandas
vwap.pd()
Develop Stream Processor pipelines
The Scratchpad can be used as a prototyping environment for Stream Processor pipelines, allowing you to easily publish batches to a pipeline, capture intermediate result, and step through your functions. Access to the pipeline API gives you the ability to simulate production workflows and test code logic prior to moving development work to production environments. This is facilitated through use of the Stream Processor Python API.
Pipeline(s) run in the scratchpad are not listed under Pipelines on the Overview page, and must be managed from within the scratchpad. They are run in the scratchpad process, the same as when deployed using Quick Test.
The following example creates a pipeline for enriching weather data. It contains an error that can easily be debugged in the scratchpad.
-
Copy the following code to your Scratchpad to create the pipeline.
# PyKX and sp are required for all pipelines import pykx as kx from kxi import sp # This pipeline will be enriching a stream of temperature and humidity records # with the dew point and apparent temperature. # The input to this function is a q table, which can be read and modified from Python. def enrich_weather(data): data['dewpoint'] = data['temp'] - .2 * (100 - data['humidity']) data['heatIndex'] = .5 * (data('temp') + 61 + (1.2 * (data['temp'] - 68)) + data['humidity'] * .094) return data # Only one pipeline can be run at once, so the `teardown` is called before running a new pipeline # Because the scratchpad process hosting the pipeline is already running, there is no deployment step needed, just a call to sp.run sp.teardown(); sp.run( # While developing a pipeline, the fromCallback reader lets you send batches one at a time # This creates a q function `publish` to accept incoming batches. sp.read.from_callback("publish") # Pipeline nodes are strung together using the | operator # To decode a CSV, strings coming from Python must be cast to q strings | sp.map(lambda x: kx.CharVector(x)) # This parses a CSV file from a string to a q table. # The argument maps each column to a q data type | sp.decode.csv({ 'time': 'timestamp', 'temp': 'float', 'humidity': 'float' }) | sp.map(enrich_weather) # The result is written to a variable called `out` in the q namespace | sp.write.to_variable('out')) # Send a batch of data to the pipeline. # As this is an example of how to debug a pipeline, running this will throw an error. # Note: kx.q is used to evaluate q from Python. In this case, getting a reference to the function `publish`, and passing it an argument. kx.q('publish', ( "time,temp,humidity\n" "2024.07.01T12:00,81,74\n" "2024.07.01T13:00,\"82\",70\n" "2024.07.01T14:00,83,70" )) -
Publishing to the pipeline throws the error shown below.
Error: Executing code using (Python) raised - QError('TypeError("\'Table\' object is not callable") - error in operator: map_1')The last part,
error in operator: map_1, indicates the error is in the map node. To debug the function, cache the incoming batch to a global, then redefine the function, rerun the pipeline, and resend the batch.def enrich_weather(data): global cache cache = data data['dewpoint'] = data['temp'] - .2 * (100 - data['humidity']) data['heatIndex'] = .5 * (data('temp') + 61 + (1.2 * (data['temp'] - 68)) + data['humidity'] * .094) return data -
After resending the batch, evaluating
cachedisplays the batch to the console. It looks correct so far.time temp humidity dewpoint ---------------------------------------------------- 2024.07.01D12:00:00.000000000 81 74 75.8 2024.07.01D13:00:00.000000000 82 70 76 2024.07.01D14:00:00.000000000 83 70 77 -
After assigning
data = cache, it's possible to step through the code. The error occurs when evaluating the last line, and selecting and evaluating sections of that line. The error comes fromdata('temp'). Updating this todata['temp']resolves the error.data = cache data['dewpoint'] = data['temp'] - .2 * (100 - data['humidity']) data['heatIndex'] = .5 * (data('temp') + 61 + (1.2 * (data['temp'] - 68)) + data['humidity'] * .094) -
You can now redefine the corrected function, rerun the pipeline, pass it multiple batches, and inspect the output.
kx.q('publish', ( "time,temp,humidity\n" "2024.07.01T12:00,81,74\n" "2024.07.01T13:00,\"82\",70\n" "2024.07.01T14:00,83,70" )) kx.q('publish', ( "time,temp,humidity\n" "2024.07.02T12:00,87,73\n" "2024.07.02T13:00,90,74\n" )) # The output is a q variable in the global namespace, # so it must be referenced via kx.q kx.q('out')time temp humidity dewpoint heatIndex -------------------------------------------------------------- 2024.07.01D12:00:00.000000000 81 74 75.8 82.278 2024.07.01D13:00:00.000000000 82 70 76 83.19 2024.07.01D14:00:00.000000000 83 70 77 84.29 2024.07.02D12:00:00.000000000 87 73 81.6 88.831 2024.07.02D13:00:00.000000000 90 74 84.8 92.178
Debugging UI Pipelines
Pipelines written in the UI and run via Quick Test are evaluated in the Scratchpad process. Therefore, any global variables cached in a UI pipeline are available in the Scratchpad, and any global variables defined in a Scratchpad are available in a pipeline process.
You can step through UI pipeline functions in-place, as the hotkeys for evaluating code work in the pipeline editors.
Known Issues
- STDOUT and STDERR (including the effects of
printstatements) are not shown in the console. - Statements that open a prompt, like
help()orimport pdb; pdb.set_trace(), make the Scratchpad unresponsive.