Test deploys
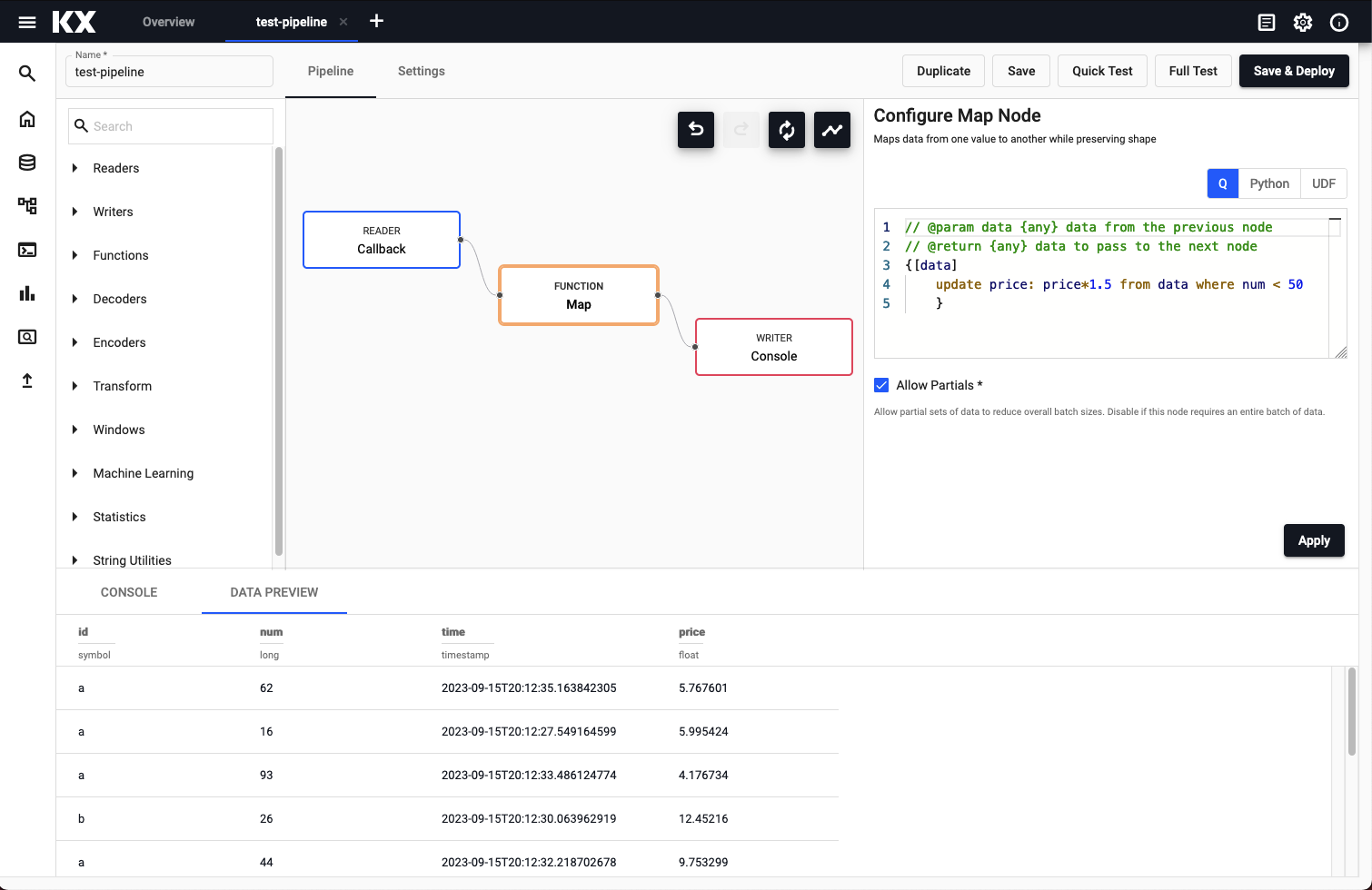
Pipelines can be tested before deployment by running a test deploy. A test deploy runs a pipeline with data tracing enabled, and then tears it down automatically. Any nodes with an error will be highlighted, and the data being outputted by each node can be seen by selecting a given node. It is recommended that before deploying a new pipeline, a test deploy is run to ensure correctness or for debugging.
Stubbed writers
In test deploys the writer nodes of the pipeline are "stubbed". This means they will not actually write data anywhere, instead they will simply validate the data passing through the node and log it for tracing.
Errors in nodes
The preview for a node shows the output of that node. However, when a node errors the input data is displayed instead.
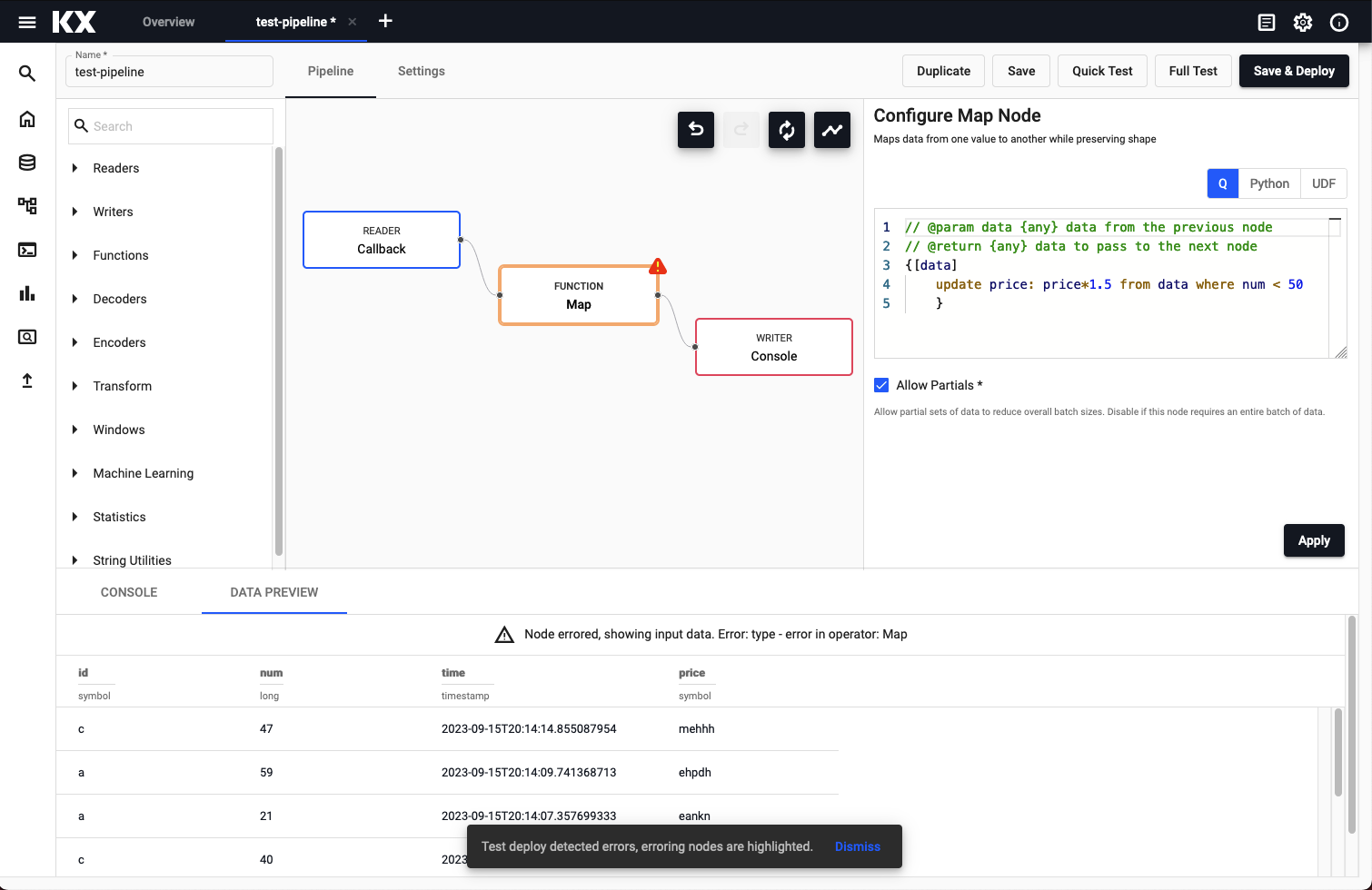
The result of running a full test deploy, with erroring nodes highlighted.
Full test deploy
A full test will deploy the pipeline into kubernetes with data tracing enabled, and then tear it down automatically. The pipeline will be torn down if it errors, or when all writers receive their first batch of data, or after 30 seconds of waiting for data; whichever comes first. In comparison to a quick test a full test is more comprehensive. The pipeline is deployed fully into kubernetes which allows kubernetes specific settings and infrastructure to be tested - like mounting kubernetes secrets for credentials for example. As a result however, this test is much slower than a quick test.
This test works with all nodes.
Quick test deploy
Beta feature
Quick test deploys are currently in beta, as not all workflows are currently supported.
A quick test will run the pipeline in the user's scratchpad with data tracing enabled, and then clean it up automatically. The test will finish when the pipeline errors, or when all writers receive their first batch of data, or after 10 seconds of waiting for data; whichever comes first. In comparison to a full test, a quick test is an order of magnitude faster. Due to this method running in user's scratchpad process, large amounts of data can cause the scratchpad to out-of-memory. Kubernetes specific settings are also ignored and not tested.
Some nodes rely on specific kubernetes infrastructure and are currently not supported by quick test deploys. These include:
- kdb Insights Database reader
- kdb Insights Stream reader
- Upload reader
- Any node configured to mount kubernetes secrets
Attempting to run a quick test on a pipeline that includes any of these nodes will throw an error. Pipelines that include these nodes should be tested using a full test instead.
Debugging variables
Quick test deploys run in the user's scratchpad, so it's possible to debug problematic code by using global variables in any node that executes a user defined function. The user can then inspect those same global variables from the Query page to better understand why the code is erroring. For example, a user can store the data being passed into a 'Map' node by doing .test.data: data;, and then after running a quick test they can inspect and manipulate that same data from the Query tab.
Running a test deploy
To run a test deploy, click the desired test button.
The test pipeline will enter a running mode and sample a set of data from the pipeline. You can view test data for a node by clicking it and viewing the data in the lower section under the Data Preview tab.