Query
The purpose of this walkthrough is to guide you through the steps to query stored data on an active databases.
This walkthrough makes reference to data ingested through pipelines created in the other walkthroughs and deployed to the insights-demo database. Therefore, before you can create the queries in this walkthrough you must ensure the insights-demo database is created, as described here.
You must also build the pipelines to ingest the data. Details on these are provided on these pages:
Create a query
Use one of the following methods to access the Query window:
- Click + on the ribbon menu
- Click + beside Query on the left-hand menu
- Click 3. Query on the Overview page.
![Open the query tab from the left-hand or ribbon menu by clicking [+], or from the Overview page.](img/query-new.png)
There is more than one method to query data from a database. Let's start with the Basic query in the Query Builder section of the scren, shown below. Click the SQL or Q tab if you want to run a query using SQL or Q.
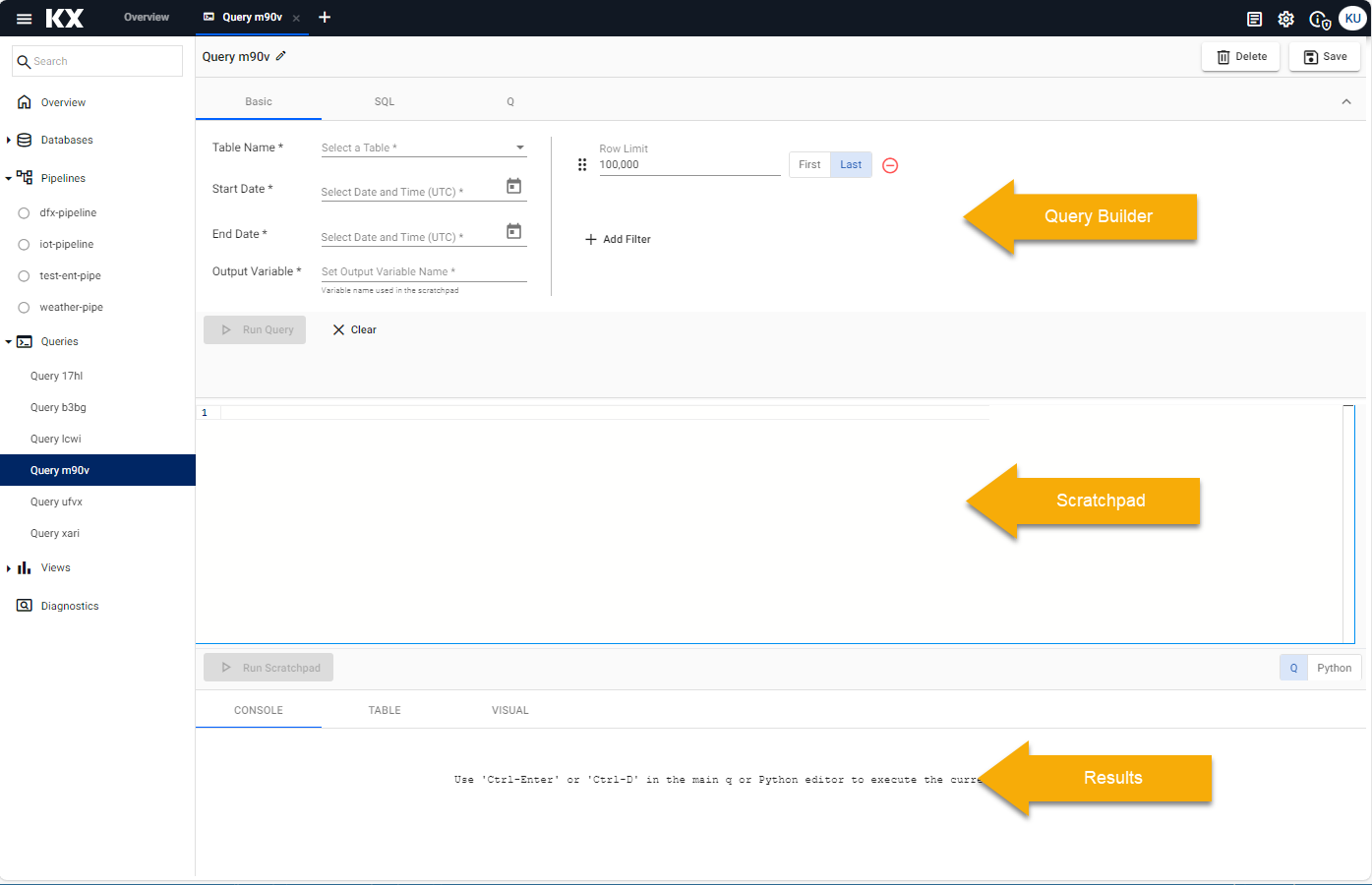
Basic is the simplest way to explore your data as it requires no coding experience.
-
Select one of the available tables; weather, crime, subway, health, taxi for the Table Name field.
-
Define the Start Date and End Date filters. The following table gives these dates for each of the walkthrough examples. Typically, the pipeline deployment date is the Start Date and End Date; for example, if you deployed a sample pipeline today, then the start and end date would be from midnight to 23:59 of today's date. The exceptions are the crime and weather data sets.
data table name output variable start date end date weather weather weather 2022-07-28T00:00:00.000000000 2022-07-28T23:59:00.000000000 crime crime crime 2022-03-31T00:00:00.000000000 2022-03-31T23:59:00.000000000 subway subway subway deployment date T00:00:00.000000000 deployment date T23:59:00.000000000 health health health deployment date T00:00:00.000000000 deployment date T23:59:00.000000000 taxi trips trips 2021-12-31T00:00:00.000000000 2021-12-31T23:59:00.000000000 -
Define an Output Variable.
-
Click Run Query to return data.
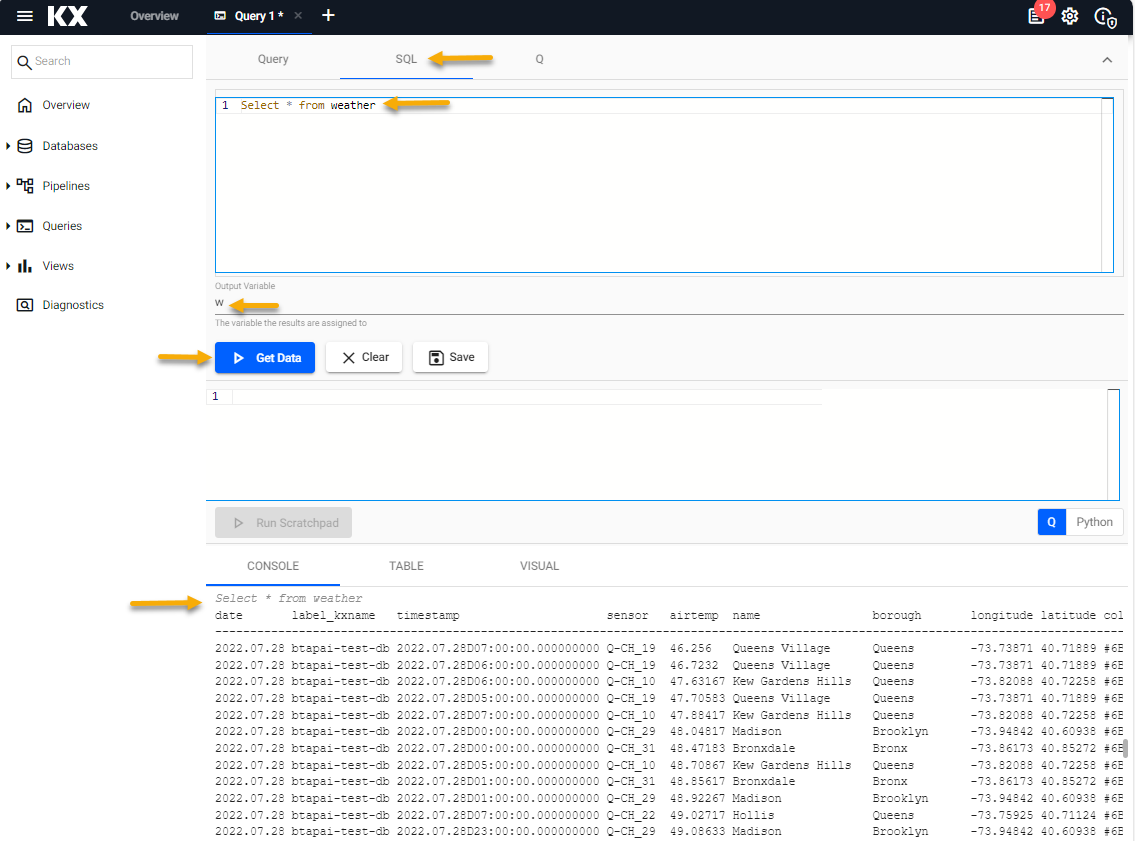
To query the insight-demo database with SQL:
-
Enter one of the sql queries from the following table, in the SQL tab.
data SQLqueryweather select * from weather crime select * from crime subway select * from subway health select * from health taxi select * from trips For example, to see the number of events generated in the subway pipeline:
select count(*) from subway -
Define an Output Variable.
-
Click Run Query to generate results.
To query the insight-demo database with Q:
-
Enter a query such as the following:
select from weather ```
-
Select insights-demo from the list of Assemblies and select an instance.
-
Define an Output Variable.
-
Click Run Query to generate results.
You always need to define an Output Variable as this is used for querying in the scratchpad and is valid for the current session.
Reserved keywords for Output Variable names
Avoid naming pipelines with reserved keywords for SQL or q; e.g. table, as this results in an error on the query.
Ad-hoc queries using Scratchpad
You have the option to run additional data investigations in the Scratchpad with q or python. Scratchpad queries must reference the Output Variable defined in the previous section. For this walkthrough it is also the table name. For example, to focus on crimes committed in the Bronx, use the kdb+/q query:
select from crime where borough like "BRONX"
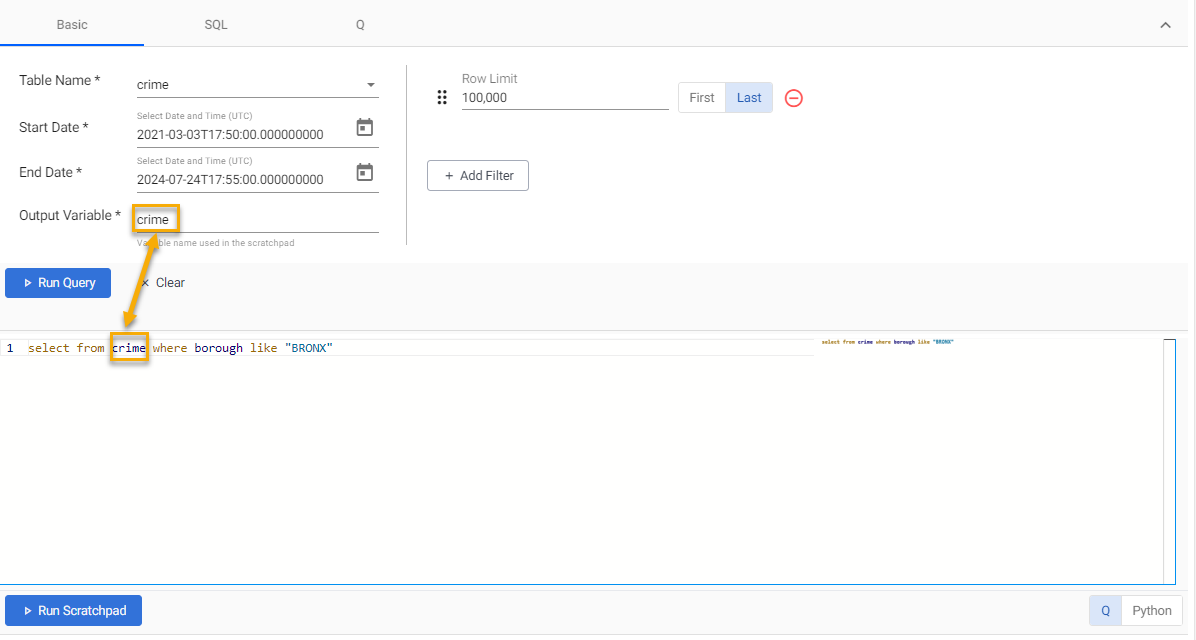
Click Run Scratchpad to return data.
If you are using python, only the first line of code is processed.
Note
There is no requirement to use the Scratchpad to view data. The Scratchpad is for ad hoc analysis of the data and is done after Get Data is run.
View results
Once you have run queries either by clicking Get Data or Run Scratchpad the results are returned to lower portion of the screen in three tabs. Right-click inside the console window to clear results. For more information on each of these tabs see:
Note
The console shows results of the most recent query irrespective of the selected tab. When switching between tabs, re-run Get Data or Run Scratchpad to repopulate results for the selected tab.
Query subway data
The following sections provide instructions and code examples to help you query the Kafka subway data.
Event count
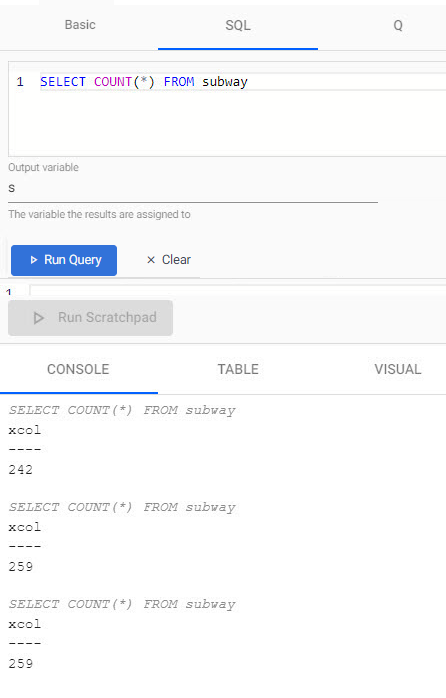
To count the number of subway journeys in the table:
-
Enter the following query in the SQL tab.
SELECT COUNT(*) FROM subway -
Define the Output Variable as s.
-
Click Run Query to execute the query. Rerun the query to get an updated value.
Filtering and visualizing
To get a subset of the data and perform further analysis using the Scratchpad:
- In the Q tab, select the database you created earlier and the RDB instance.
-
Enter the following query.
select from subway where arrival_time.date in .z.dSet today's date in
qUse
.z.das a convenient way to return today's date. -
Define the Output Variable as s.
-
Click Run Query.
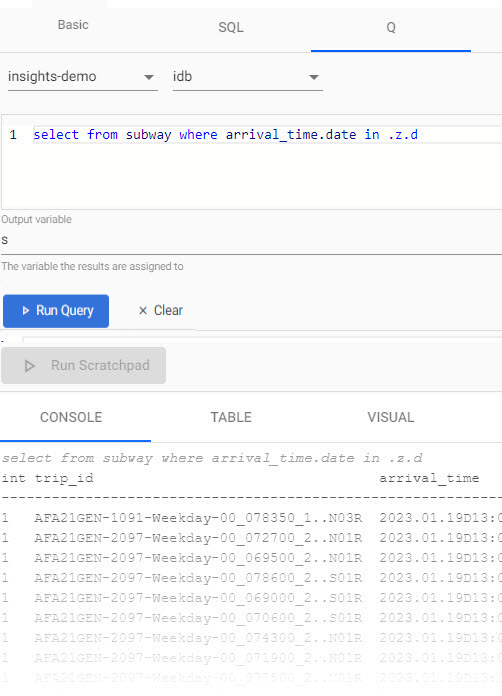
Additional analysis, of today’s train data, can be performed against the s variable using the scratchpad. Querying in the scratchpad is more efficient than direct querying of the database and supports both q and python.
-
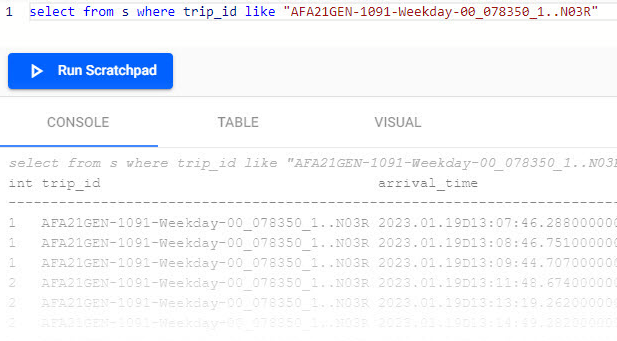
Enter the following query, in the Scratchpad and click Run Scratchpad.
This pulls data for a selected trip_id. Change the value of the trip_id to another if this example returns no results.select from s where trip_id like "AFA21GEN-5108-Weekday-00_091350_5..N71R" -
Results are displayed in the tabs; Console, Table or Visual tabs.
-
In the Visual tab, set the y-axis to use stop_sequence and x-axis to arrival_time to return a plot of journey times between each of the stops.
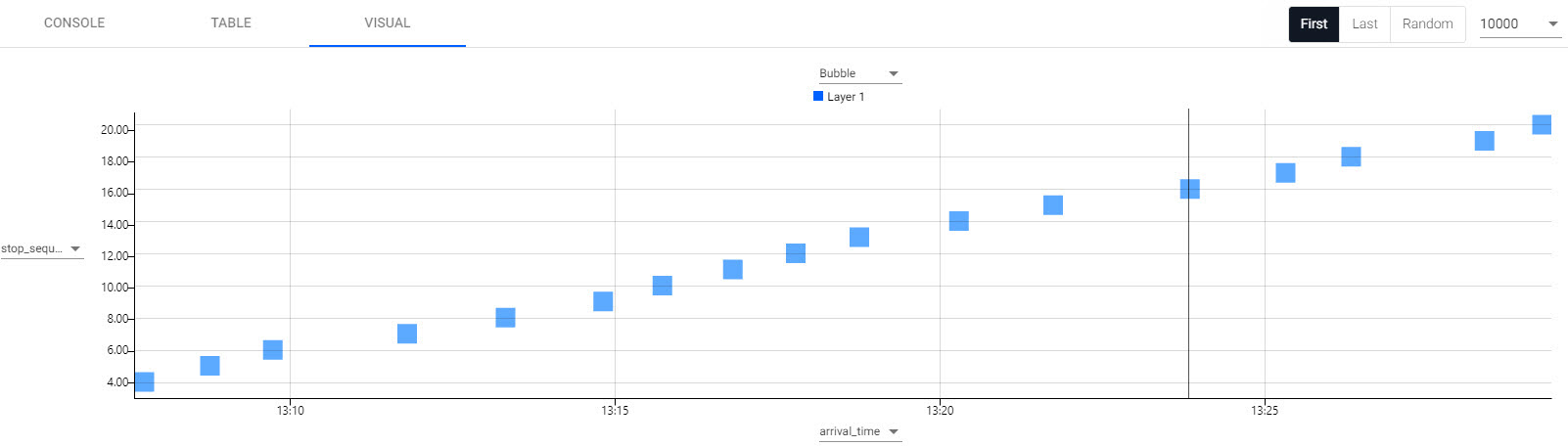
Each time you change the results tab you must rerun the query
Calculate average time between stops
You can calculate the average time between stops, as a baseline to determine percentage lateness.
-
In the scratchpad enter the following code, replacing the trip-id with the value you used in the previous section.
The following screenshot shows this query in the scratchpad and the results in the Console.`arrival_time`time_between_stops xcols update time_between_stops:0^`second$arrival_time[i]-arrival_time[i-1] from select from s where trip_id like "AFA21GEN-1091-Weekday-00_138900_1..N03R"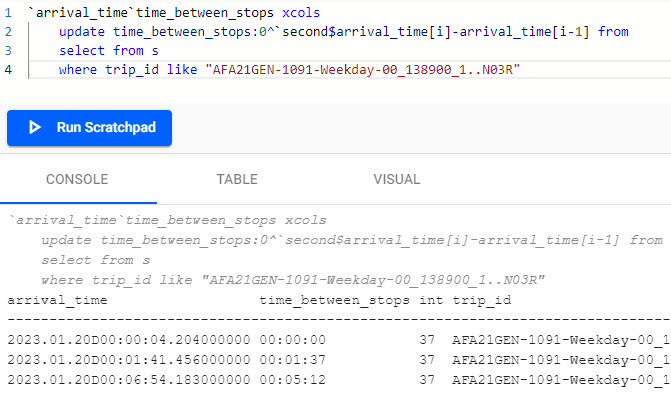
Understanding the
qqueryIn the above query, the following
qelements are used:Element Description xcols To reorder table columns ^ To replace nulls with zeros $ To cast back to second datatype x[i]-x[i-1] To subtract each column from the previous one If you run into an error on execution, check to ensure the correct code indentation is applied for
s3.What was the longest and shortest stop for this trip?
Use the Table tab to filter the results. For example, doing a column sort by clicking on the column header for the newly created variable time_between_stops toggles the longest and shortest stop for the selected trip.
Each time you change the results tab you must rerun the query
Calculating percentage lateness for all trains
You can discover which trains were most frequently on time.
-
In the scratchpad, replace any existing code with the following and click Run Scratchpad.
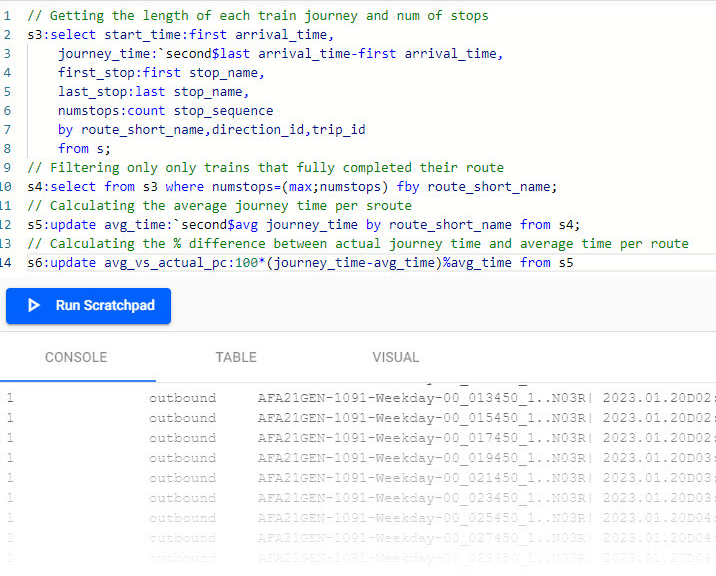
// Getting the length of each train journey and num of stops s3:select start_time:first arrival_time, journey_time:`second$last arrival_time-first arrival_time, first_stop:first stop_name, last_stop:last stop_name, numstops:count stop_sequence by route_short_name,direction_id,trip_id from s; // Filtering only trains that fully completed their route s4:select from s3 where numstops=(max;numstops) fby route_short_name; // Calculating the average journey time per sroute s5:update avg_time:`second$avg journey_time by route_short_name from s4; // Calculating the % difference between actual journey time and average time per route s6:update avg_vs_actual_pc:100*(journey_time-avg_time)%avg_time from s5Understanding the
qquery?In the above query, the following
qelements are used:Element Description first, last To get first or last record - To subtract one column from another count To return the number of records by To group the results of table by column/s - similar to excel pivot fby To filter results by a newly calculated field without needing to add it to table x=(max;x) To filter any records that equal the maximum value for that column $ To cast back to second datatype * To perform multiplication % To perform division. If you run into an error on execution, check to ensure the correct code indentation is applied.
Most punctual train
To calculate which train was most punctual:
-
In the Scratchpad, replace any existing code with the following and click Run Scratchpad
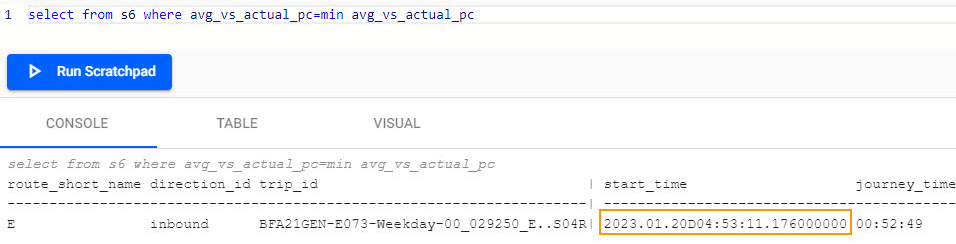
select from s6 where avg_vs_actual_pc=min avg_vs_actual_pcUsing min, the 04:53 route E train was the most punctual (your result will differ).
Visualize journey time
In the Visual tab, you can create a visualization for a single route.
-
In the Scratchpad, replace any existing code with the following and click Run Scratchpad
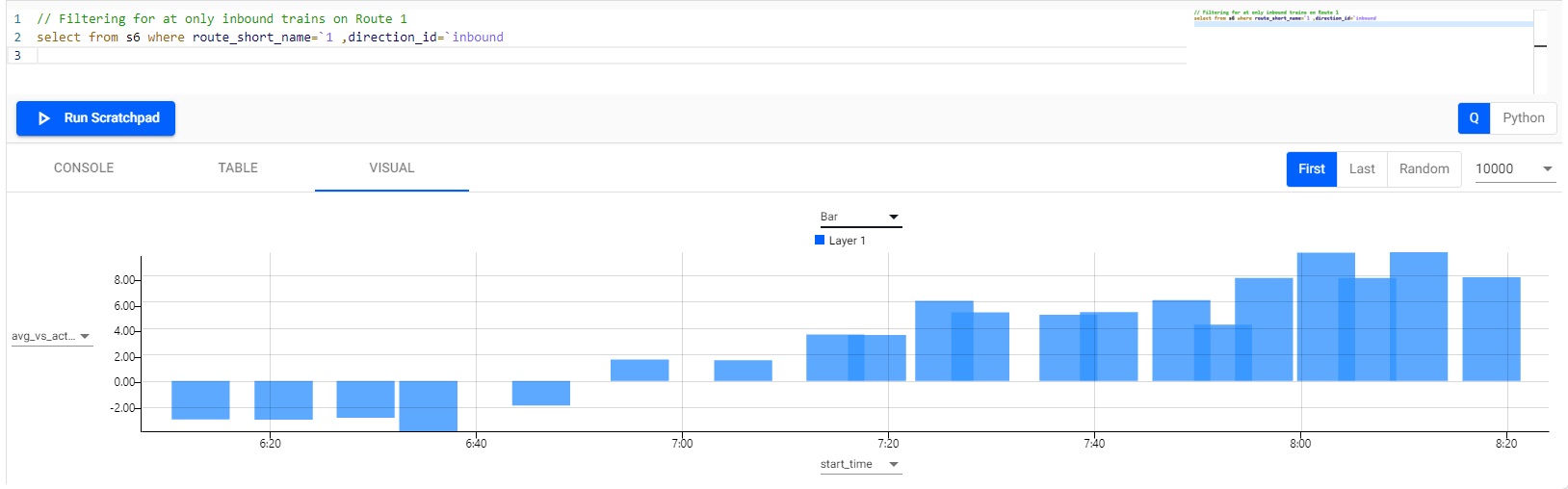
// Filtering for at only inbound trains on Route 1 select from s6 where route_short_name=`1 ,direction_id=`inbound -
Switch to a bar chart. Set the y-axis to avg_vs_actual_pc and the x-axis to start_time to view results as shown below.
Distribution of journey times between stations
To assess the distribution of journey times between stations.
-
In the Scratchpad, replace any existing code with the following and click Run Scratchpad.
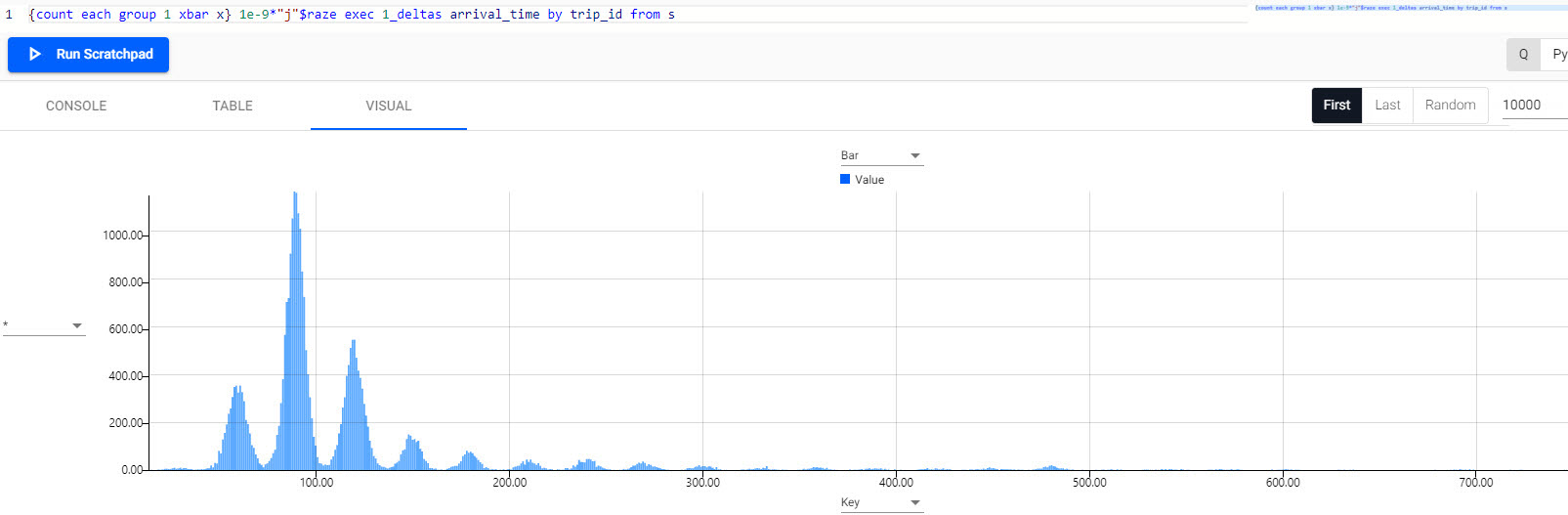
{count each group 1 xbar x} 1e-9*"j"$raze exec 1_deltas arrival_time by trip_id from s -
From the histogram, you can see that the most common journey time between stations is 90 seconds.
Next Steps
- Go to View for details on how to visualize data.
Further Reading
Use the following links to learn more about specific topics mentioned in this page: