Manufacturing Tutorial: Apply deep neural networks to streaming IoT data using MQTT and Tensorflow
For manufacturers, machine downtime can cost millions of dollars a year in lost profits, repair costs, and lost production time for employees. By embedding predictive analytics in applications, such as kdb Insights Enterprise, manufacturing managers can monitor the condition and performance of assets and predict failures before they happen.
In this use case, compute logic is applied to live data streaming from a MQTT messaging service. Then Deep Neural Network Regression is used to determine the likelihood of breakdowns.
Benefits
| benefit | description |
|---|---|
| Predictive analysis | Use predictive analytics and data visualizations to forecast a view of asset health and reliability performance. |
| Reduce risks | Leverage data in real time for detection of issues with processes and equipment, reducing costs and maximizing efficiencies throughout the supply chain with less overhead and risk. |
| Control logic | Explore how to rapidly develop and visualize computations to extract insights from live streaming data. |
This tutorial walks you through the following:
- Build a database
- Ingest live MQTT data
- Query the data
- Define a standard compute logic
- Apply a deep neural network regression model
- Query the Model
1: Build a database
- Select Build a Database under Discover kdb Insights Enterprise of the Overview page.
-
Name the database (e.g.
manufacturing).Suggested database name
The rest of this tutorial assumes you have named the database
manufacturing. -
Open the Schema Settings tab and click Code View on the right-hand side.
-
Paste the following JSON schema into the code editor.
Manufacturing JSON schema
Paste into the code editor:
[ { "name": "sensors", "type": "partitioned", "primaryKeys": [], "prtnCol": "time", "sortColsDisk": [ "time" ], "sortColsMem": [ "time" ], "sortColsOrd": [ "time" ], "columns": [ { "type": "timestamp", "attrDisk": "parted", "attrOrd": "parted", "name": "time", "attrMem": "" }, { "name": "flowplant", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "pressplant", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempplantin", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempplantout", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "massprecryst", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempprecryst", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "masscryst1", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "masscryst2", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "masscryst3", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "masscryst4", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "masscryst5", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempcryst1", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempcryst2", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempcryst3", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempcryst4", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "tempcryst5", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "temploop1", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "temploop2", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "temploop3", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "temploop4", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "temploop5", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "setpoint", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "contvalve1", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "contvalve2", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "contvalve3", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "contvalve4", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "contvalve5", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" } ] }, { "columns": [ { "type": "timestamp", "attrDisk": "parted", "attrOrd": "parted", "name": "time", "attrMem": "" }, { "name": "model", "type": "symbol", "attrMem": "", "attrOrd": "", "attrDisk": "" }, { "name": "prediction", "type": "float", "attrMem": "", "attrOrd": "", "attrDisk": "" } ], "primaryKeys": [], "type": "partitioned", "prtnCol": "time", "name": "predictions", "sortColsDisk": [ "time" ], "sortColsMem": [ "time" ], "sortColsOrd": [ "time" ] } ] -
Applythe JSON to populate the schema table.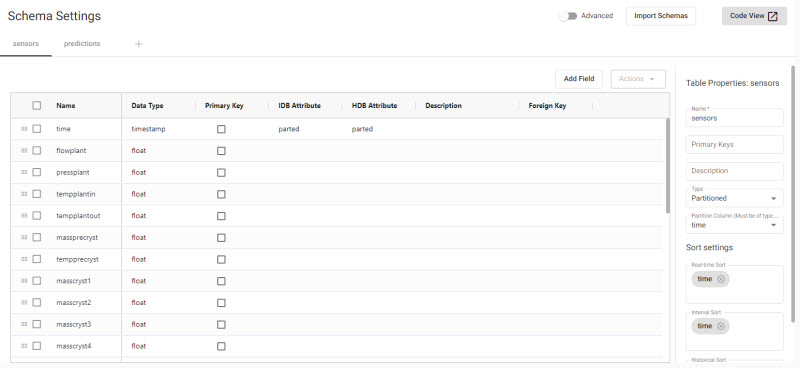
-
Click Save.
- Click Deploy.
When the database status changes to Active, it is ready to use. _An active database displays an adjacent green tick under the Databases menu.
Database warnings
Once the database is active, warnings are displayed in the Issues pane of the Database Overview page. These are expected and can be ignored.

2. Ingest live MQTT data
MQTT is a standard messaging protocol used in a wide variety of industries, such as automotive, manufacturing, telecommunications, oil and gas, etc.
It can be easily consumed by kdb Insights Enterprise.
- Select 2. Import under Discover kdb Insights Enterprise of the Overview page.
-
Select MQTT and complete the properties (
*are required):setting value Broker* ssl://mqtt.trykdb.kx.com:1883 Topic* livesensor Username* demo Use TLS* disabled -
Select the JSON Decoder option;
-
Leave the Decode Each option unchecked and click Next.
-
Transform data to a kdb+ database compatible format;
-
Leave the Data Format setting set to Any.
-
Click the
 .
. -
Select the manufacturing database and its
sensorstable created in 1. build a database. -
Click Load.
-
Click Next.
-
-
Configure the writer by applying the following settings:
setting value Database manufacturing Table sensors Write direct to HDB unchecked Deduplicate Stream checked Set Timeout Value unchecked Advanced leave blank -
Click Open Pipeline to view the pipeline.
-
The JSON decoder creates a kdb+ friendly dictionary that needs to be converted to a kdb+ table, using a Function Map node, before the schema is applied to the data. In the pipeline view, add a Function Map node to the pipeline as follows:
- Right-click the existing link between the
DecoderandTransformnode; click Remove Edge to remove. - Position the
Function Mapnode between theDecoderandTransformnode. -
Connect the
Function Mapnode to theDecoderandTransformnodes with a click-and-drag connect of the dot edge of the node.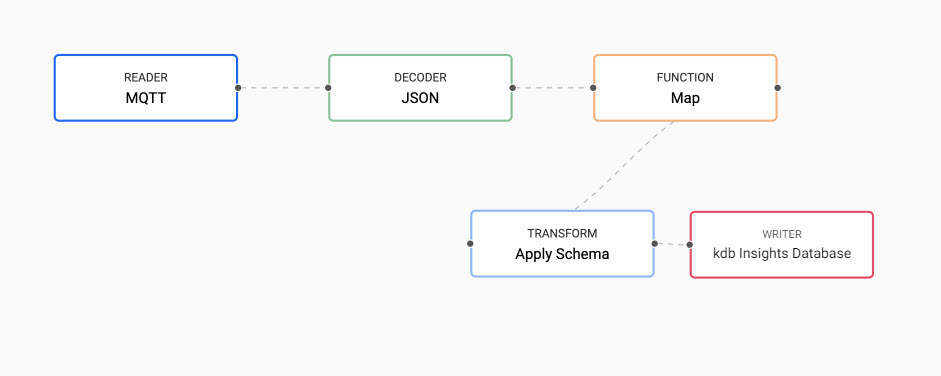
-
Select the
Functionnode and replace theqcode with the following; this transforms the kdb+ dictionary to a table:{[data] enlist data } -
Leave Allow Partials checked.
- Save the pipeline.
-
Deploy the pipeline by completing the authentication for the
MQTTfeed:setting value password demo Deploying a pipeline requires an active database to receive the data. Ensure the
manufacturingdatabase is deployed and active before deploying theMQTTpipeline.Check your pipeline is running in the Running Pipelines section on the Overview page. Your pipeline should display as
Status=Running.Trouble deploying a pipeline?
When running Deploy, choose the Test option to debug each node.
- Right-click the existing link between the
3. Query the data
Data queries are run in the query tab, which is accessible from the [+] of the ribbon menu, or Query under Discover kdb Insights Enterprise of the Overview page.
-
Open the SQL tab.
Allow 15-20 minutes of data generation before querying the data. Certain queries may return visuals with less data if run too soon.
-
Copy and paste the following code into the top window pane:
SELECT time,tempcryst1,tempcryst2,tempcryst3,tempcryst4,tempcryst5 FROM sensors -
Define the
Output variableass1.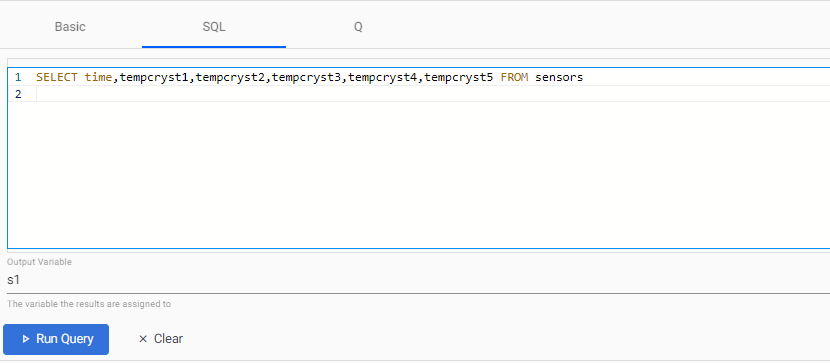
-
Click Run Query to generate the results.
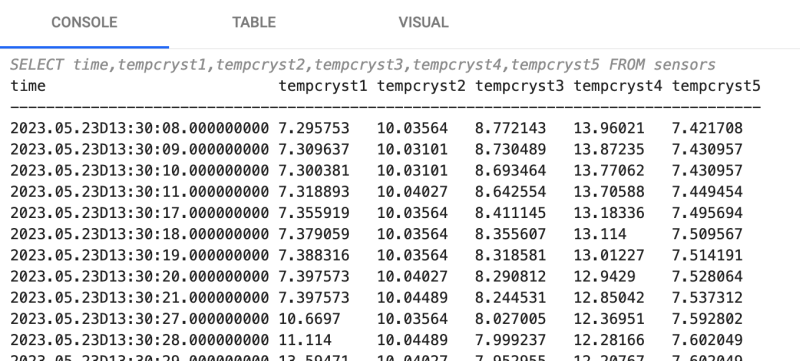
-
Create a visual to focus on temperature by switching the output tab to Visual and run Run Query again.
In the visual, there is a cyclical pattern of temperature in the crystallizers, fluctuating between 7-20 degrees Celsius.
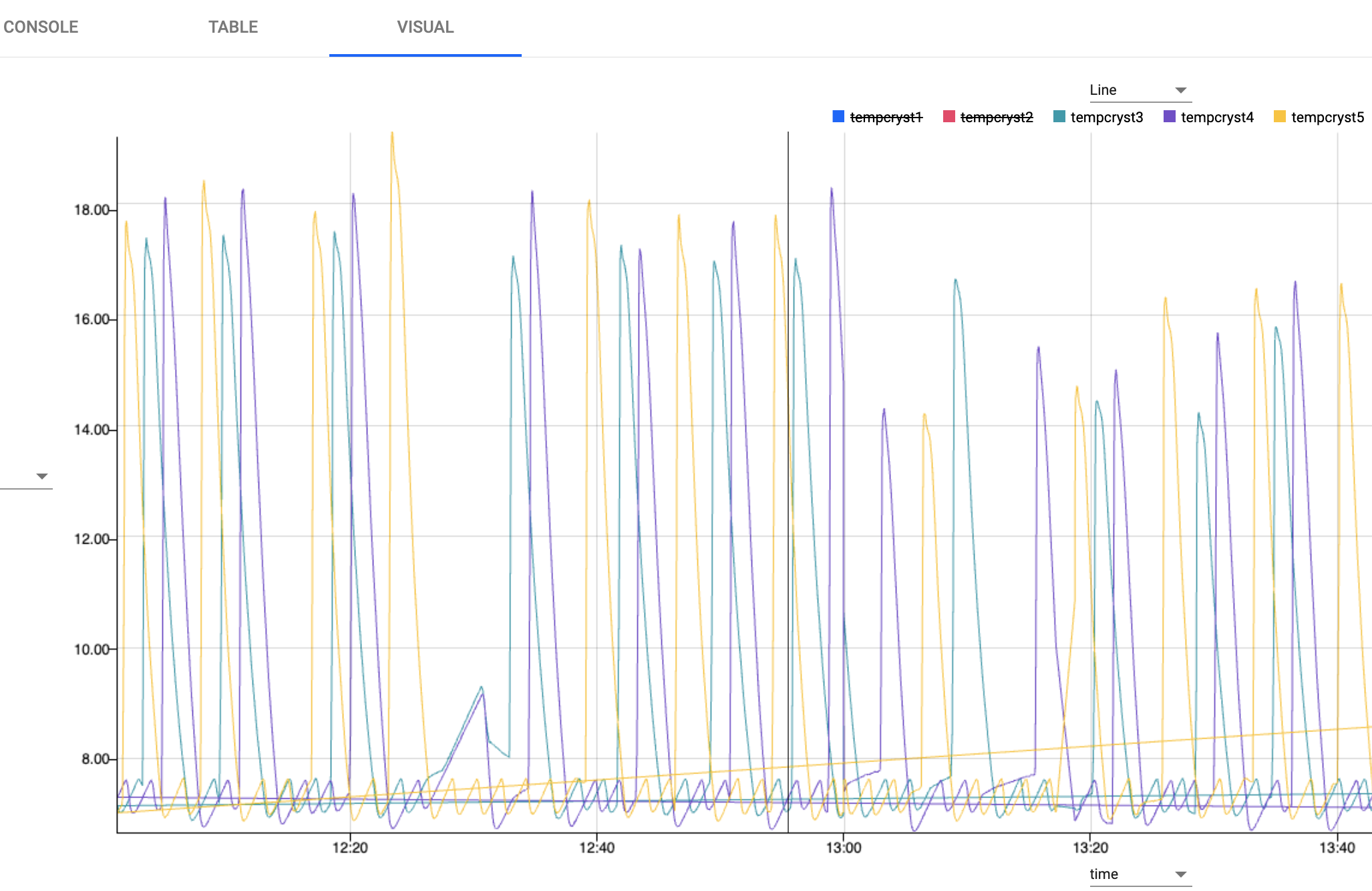
-
You can also query data for the mass fields using
SQL. Similar fluctuations to those for the temperature values, occur for mass levels in the crystallizers, moving between 0-20000kg on a cycle.- Copy and paste the following code into the top window pane:
SELECT time,masscryst1,masscryst2,masscryst3,masscryst4,masscryst5 FROM sensors-
Change the
Output variabletos2. -
Click Run Query.
4: Define a standard compute logic
Use the scratchpad to set Control Chart Limits to identify predictable Upper Control (UCL) and Lower Control Limits (LCL).
-
Calculate a 3 sigma UCL and LCL to account for 99.7% of expected temperature fluctuations. A recorded temperature outside of this range requires investigation.
-
Copy and paste the code below into the scratchpad q input box:
// Calculating 5 new values, most notably ucl and lcl where // ucl - upper control limit // lcl - lower control limit select lastTime:last time, lastVal: (1.0*last tempcryst3), countVal: count tempcryst3, ucl: avg tempcryst3 + (3*dev tempcryst3), lcl: avg tempcryst3 - (3*dev tempcryst3) by xbar[10;time.minute] from s1 -
Click Run Scratchpad.
-
Visualize the threshold by selecting the Line graph. The change in control limits is more obvious in the visual similar to the graph below after ~15-20 minutes of loading data.
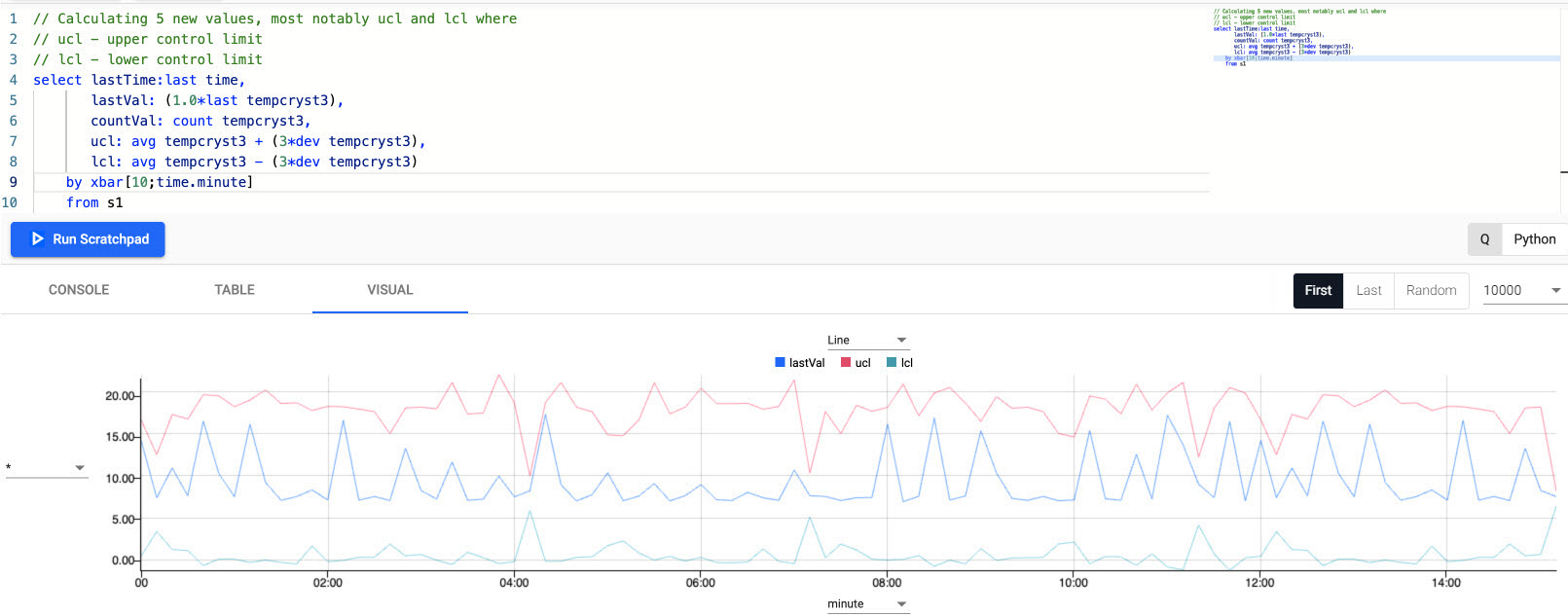
Plot of a 3 sigma upper and lower control temperature bound to account for 99.7% of expected temperature fluctuation in manufacturing process. Outliers outside of this band require investigation. -
-
Next, aggregate temperature thresholds over two rolling time windows; a 1 minute aggregate and a second, smoother, 60 minute aggregate of sensor readings.
-
Replace all code in the scratchpad with the code below:
// Using asof join to join 2 tables // with differing aggregation windows aj[`minute; // table 1 aggregates every 1 minute select lastTime : last time, lastVal : last tempcryst3, countVal : count tempcryst3 by xbar[1;time.minute] from s1; // table 2 aggregates every 60 minute select ucl : avg[tempcryst3] + (3*dev tempcryst3), lcl : avg[tempcryst3] - (3*dev tempcryst3) by xbar[60;time.minute] from s1]q/kdb+ functions explained
For more information on the code elements used in the above query:
aj is a powerful timeseries join, also known as an asof join, where a time column in the first argument specifies corresponding intervals in a time column of the second argument.
This is one of two bitemporal joins available in kdb+/q.
To get an introductory lesson on bitemporal joins, view the free Academy Course on Table Joins.
-
Click Run Scratchpad.
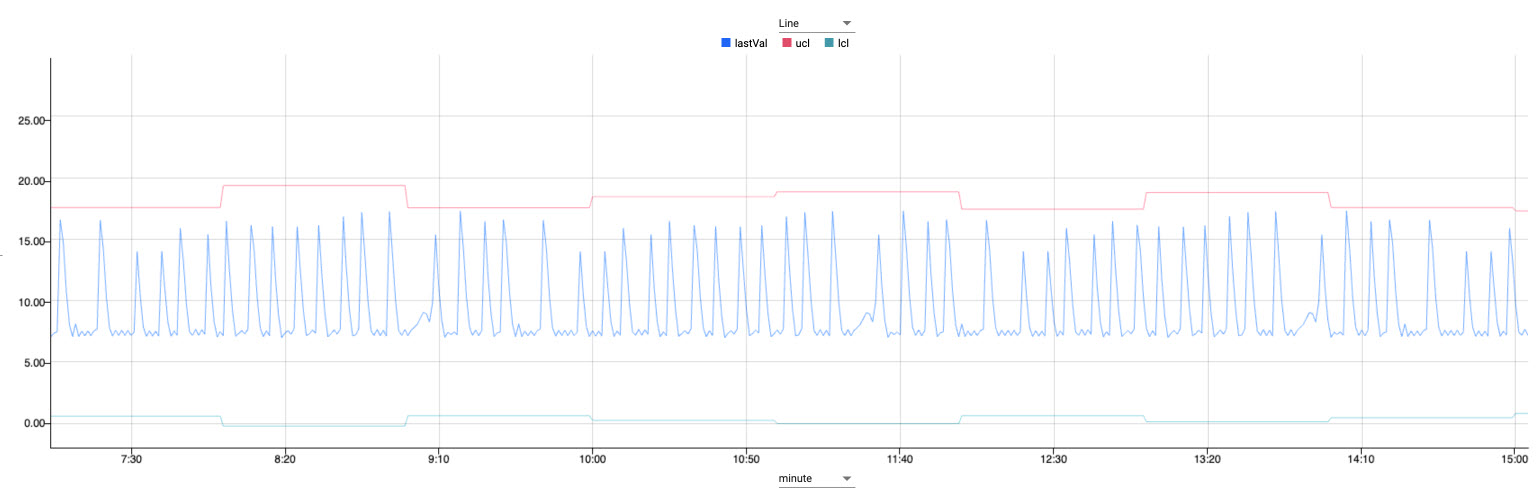
Plot of aggregate temperature thresholds for 1 minute and 60 minutes. -
-
Next, define a function to simplify querying and run the query with a rolling 1 minute window:
-
Append the code below to the code already in the scratchpad:
// table = input data table to query over // sd = standard deviations required // w1 = window one for sensor readings to be aggregated by // w2 = window two for limits to be aggregated by controlLimit:{[table;sd;w1;w2] aj[`minute; // table 1 select lastTime : last time, lastVal : last tempcryst3, countVal : count tempcryst3 by xbar[w1;time.minute] from table; // table 2 select ucl : avg[tempcryst3] + (sd*dev tempcryst3), lcl : avg[tempcryst3] - (sd*dev tempcryst3) by xbar[w2;time.minute] from table] } controlLimit[s1;3;1;60]q/kdb+ functions explained
For more information on the code elements used in the above query:
{} known as lambda notation allows us to define functions.
It is a pair of braces (curly brackets) enclosing an optional signature (a list of up to 8 argument names) followed by a zero or more expressions separated by semicolons.
To get an introductory lesson, view the free Academy Course on Functions.
-
Click Run Scratchpad.
-
-
Finally, change the
w1parameter value to see the change in signal when you use different window sizes:-
Append the code below to the code already in the scratchpad, to set the parameter to 10 minutes:
controlLimit[s1;3;10;60] -
Append the code below to the code already in the scratchpad, to set the parameter to 20 minutes:
controlLimit[s1;3;20;60]
By varying the parameter for one of the windows, you can see the change in signal between rolling windows of 1, 10 and 20 minutes. This means you can tailor the output to make it more or less smooth as per your requirements.
-
5: Apply a deep neural network regression model
Apply a trained neutral network model to incoming data.
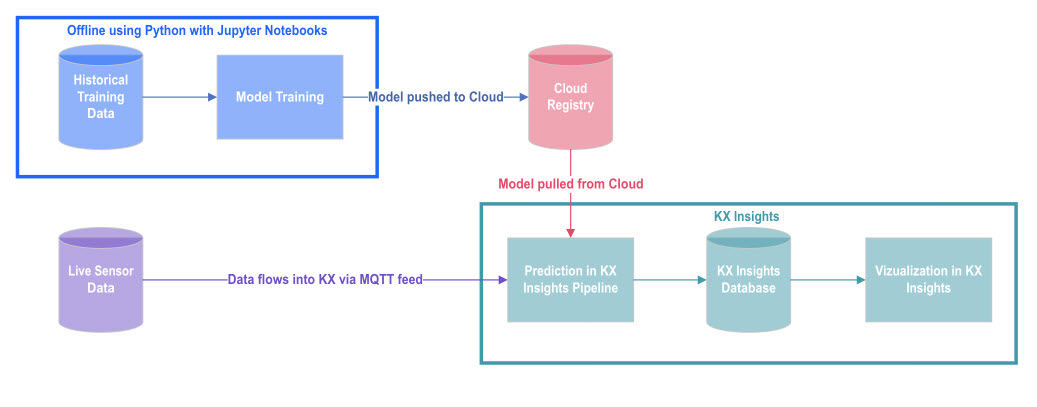
Architecture of neural network reguression model as it relates to kdb Insights Enterprise.
For the purpose of this use case, our model is pre-trained using tensorflow neural networks and xgboost. Each model prediction is then aggregated for added benefit.
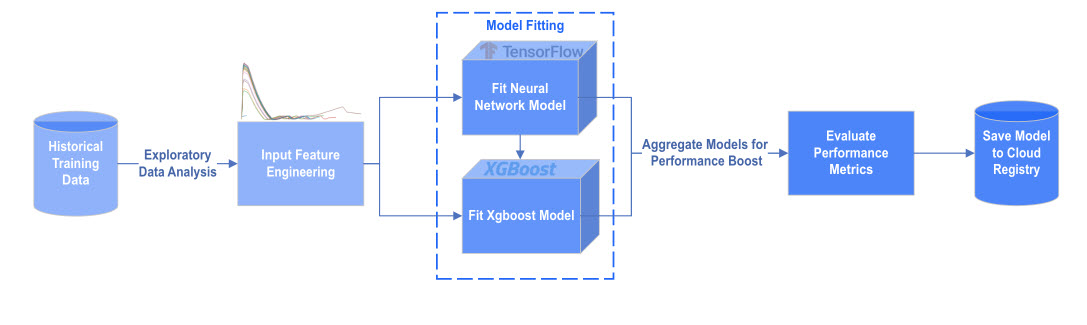
Aggregated model pre-trained using tensorflow neural networks and xgboost.
kdb Insights Enterprise offers a range of machine learning nodes in the pipeline template to assist in model development.
-
Duplicate the pipeline created in MQTT import; and assign a name:
Duplicate the MQTT import pipeline from the pipeline template menu. -
Paste into the Global Code editor:
import numpy as np import pykx as kx ewmaLag100 = np.nan ewmaLead100 = np.nan ewmaLag300 = np.nan ewmaLead300 = np.nan timeSince = np.nan started = False back = np.nanewmaLag100:0n; ewmaLead100:0n; ewmaLag300:0n; ewmaLead300:0n; timeSince:0n; started:0b; back:0n;Update the Global Code with
qorpythoncode. -
Add a Function Split node to the pipeline.
This split maintains the original database write as one path, and you add the machine learning workflow to the second path.
- Right-click the existing link between the
Apply Schemaandkdb Insights Databasenode; click on Remove Edge to remove. - Position the
Function Splitnode between theApply Schemaandkdb Insights Databasenode. - Connect the
Function Splitnode to theApply Schemaandkdb Insights Databasenode with a click-and-drag connect of the dot edge of the node.

Add a Function Split node to the pipeline. - Right-click the existing link between the
-
Add a Function Map node:
This adds a new variable,
timePast, that calculates the time interval between spikes. A spike occurs when product mass breaks above the spike threshold of 1,000 kg.-
Connect it to the Split node.
-
Click on the Map node and copy and paste the following to the code editor using either
pythonorqcode, leave Allow Partials checked:def func(data): global timeSince, back if (data["masscryst3"][0].py()>1000)&(not np.isnan(back))&(back < 1000): timeSince = 0.0 else: timeSince = timeSince + 1.0 back = data["masscryst3"][0].py() d = data.pd() d['timePast'] = timeSince return d[['time','timePast','tempcryst4','tempcryst5']]{[data] data:-1#data; $[(first[data[`masscryst3]]>1000)&(not null back)&(back<1000); [timeSince::0; back::first[data[`masscryst3]]; tmp:update timePast:timeSince from data]; [timeSince::timeSince+1; back::first[data[`masscryst3]]; tmp:update timePast:timeSince from data] ]; select time,timePast,tempcryst4,tempcryst5 from tmp } -
Click Apply.
-
Rename the node to "Spike Threshold".
Rename nodes on right-click
Right-click on a node to rename
Rename a node on right-click.
-
-
Add a second Function Map node:
This calculates moving averages for temperature.
-
Connect it to the Spike Threshold node.
-
Copy and paste the following to the code editor in
pythonorq. Leave Allow Partials checked:def func(data): global started,ewmaLag100,ewmaLead100,ewmaLag300,ewmaLead300 a100=1/101.0 a300=1/301.0 if not started: started = True ewmaLag100 = data["tempcryst5"][0].py() ewmaLead100 = data["tempcryst4"][0].py() ewmaLag300 = data["tempcryst5"][0].py() ewmaLead300 = data["tempcryst4"][0].py() else: ewmaLag100 = a100*data["tempcryst5"][0].py() + (1-a100)*ewmaLag100 ewmaLead100 = a100*data["tempcryst4"][0].py() + (1-a100)*ewmaLead100 ewmaLag300 = a300*data["tempcryst5"][0].py() + (1-a300)*ewmaLag300 ewmaLead300 = a300*data["tempcryst4"][0].py() + (1-a300)*ewmaLead300 d = data.pd() d['ewmlead300'] = ewmaLead300 d['ewmlag300'] = ewmaLag300 d['ewmlead100'] = ewmaLead100 d['ewmlag100'] = ewmaLag100 d['model'] = kx.SymbolAtom("ANN") d = d[~(np.isnan(d.timePast))] return d{[data] a100:1%101.0; a300:1%301.0; $[not started; [ewmaLag100::first data`tempcryst5; ewmaLead100::first data`tempcryst4; ewmaLag300::first data`tempcryst5; ewmaLead300::first data`tempcryst4; started::1b]; [ewmaLag100::(a100*first[data[`tempcryst5]])+(1-a100)*ewmaLag100; ewmaLead100::(a100*first[data[`tempcryst4]])+(1-a100)*ewmaLead100; ewmaLag300::(a300*first[data[`tempcryst5]])+(1-a300)*ewmaLag300; ewmaLead300::(a300*first[data[`tempcryst4]])+(1-a300)*ewmaLead300 ]]; t:update ewmlead300:ewmaLead300,ewmlag300:ewmaLag300,ewmlead100:ewmaLead100,ewmlag100:ewmaLag100 from data; select from t where not null timePast } -
Click Apply.
-
Rename the node to "Temperature".
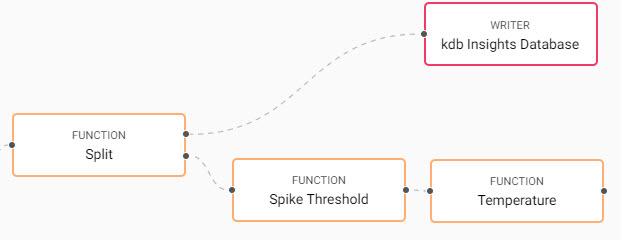
A second Function node calculates moving averages for temperature and is connected to the spike threshold node. Each function node is renamed to identify its role in the pipeline. -
-
Add a Machine Learning node:
-
Add the Predict Using Registry Model.
Use the Search feature at the top of the Nodes list to quickly find the Predict Using Registry Model node
-
Connect it to the Temperature node.
-
Click on the ML node and click
 to add a Feature Column Name; this is done for the variables defined in the previous function node:
to add a Feature Column Name; this is done for the variables defined in the previous function node:setting value Feature Column Name ewmlead300 Feature Column Name ewmlag300 Feature Column Name ewmlead100 Feature Column Name ewmlag100 Feature Column Name tempcryst4 Feature Column Name tempcryst5 Feature Column Name timePast 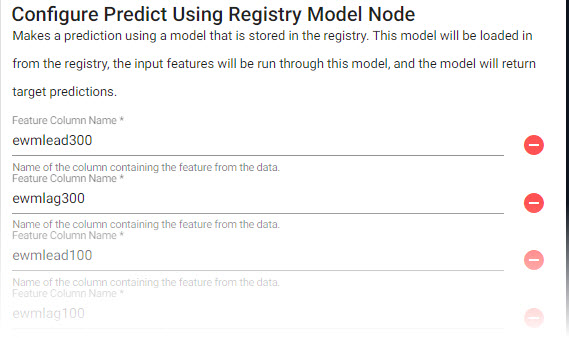
In the Predict Using Registry Model node, add a Feature Column Name for the variables defined in the previous function node. -
Set the remaining properties of the Predict Using Registry Model node:
setting value Prediction Column Name yhat Registry Type AWS S3 Registry Path s3://qrisk -
Click Apply.
-
-
Add another Function Map node:
This node adds some metadata.
-
Connect it to the Machine Learning node.
-
Copy and paste the following into the
pythonorqcode editor. Leave Allow Partials checked:def func(data): d = data.pd() d['prediction'] = d['yhat'].astype(float) return d[['time','model','prediction']]{[data] select time, model:`ANN, prediction:"f"$yhat from data } -
Click Apply.
-
Rename the node to "Metadata".

A third Function Map node is connected to the Machine Learning node to add some metadata. -
-
Add a second kdb Insights Database node:
This completes the workflow and writes the preditions to the
predictionstable.-
Connect the Writer kdb Insights Database to the Metadata node.
-
Apply the following settings:
setting value Database manufacturing Table predictions Write direct to HDB unchecked Deduplicate Stream checked -
Click Apply.
-
-
Click on the Settings tab in pipeline:
-
Scroll down to the Environment Variables. These variables provide the credentials that are required to access the machine learning model on AWS cloud storage.
variable value AWS_ACCESS_KEY_ID AKIAZPGZITYXCEC35GF2 AWS_SECRET_ACCESS_KEY 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 AWS_REGION eu-west-1
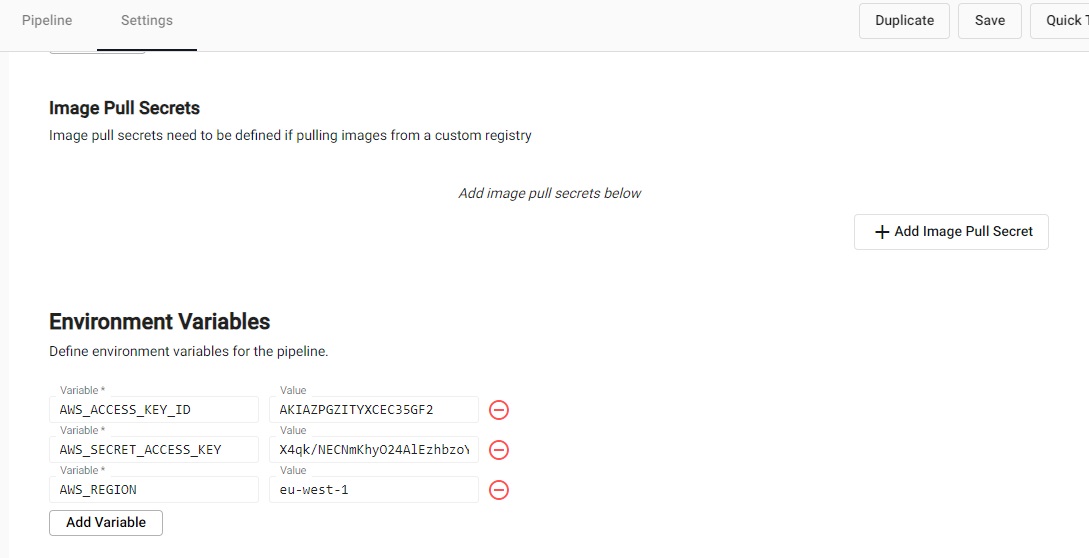
Define the Environment Variables to access the machine learning model stored on AWS. -
-
Click Save.
-
If still running, go to the Overview page to teardown the existing manufacturing pipeline and select Clean up resources after teardown.
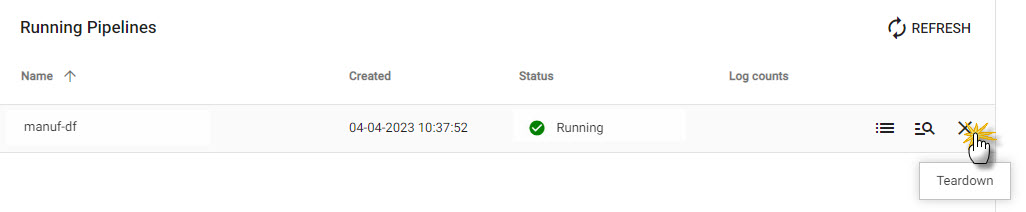
Teardown any running manufacturing pipeline before deploying the machine learning version. Check the box to _Clean up resources after teardown in the pop-up dialog._ -
Deploy the modified pipeline with the machine learning workflow. Complete the authentication to access the
MQTTfeed:setting value Password demo Check Running Pipelines in Overview; when
Status=Runningthe prediction model has begun.When will my data be ready to Query?
It takes at least 20 minutes to calculate the
timePastvariable as two spikes are required. For more spikes in the data, shorten the frequency of spike conditions.
6. Query the Model
After sufficient time has passed to generate values for timePast, open the query tab. This is accessible from the [+] of the ribbon menu, or Query under Discover kdb Insights Enterprise of the Overview page.
-
Select the Query tab.
-
Define the filters:
setting value Table name predictions Output variable p1 Start date Midnight of deployment date End date 23:59 of deployment date -
Select the Visual tab.
-
Click Run Query.
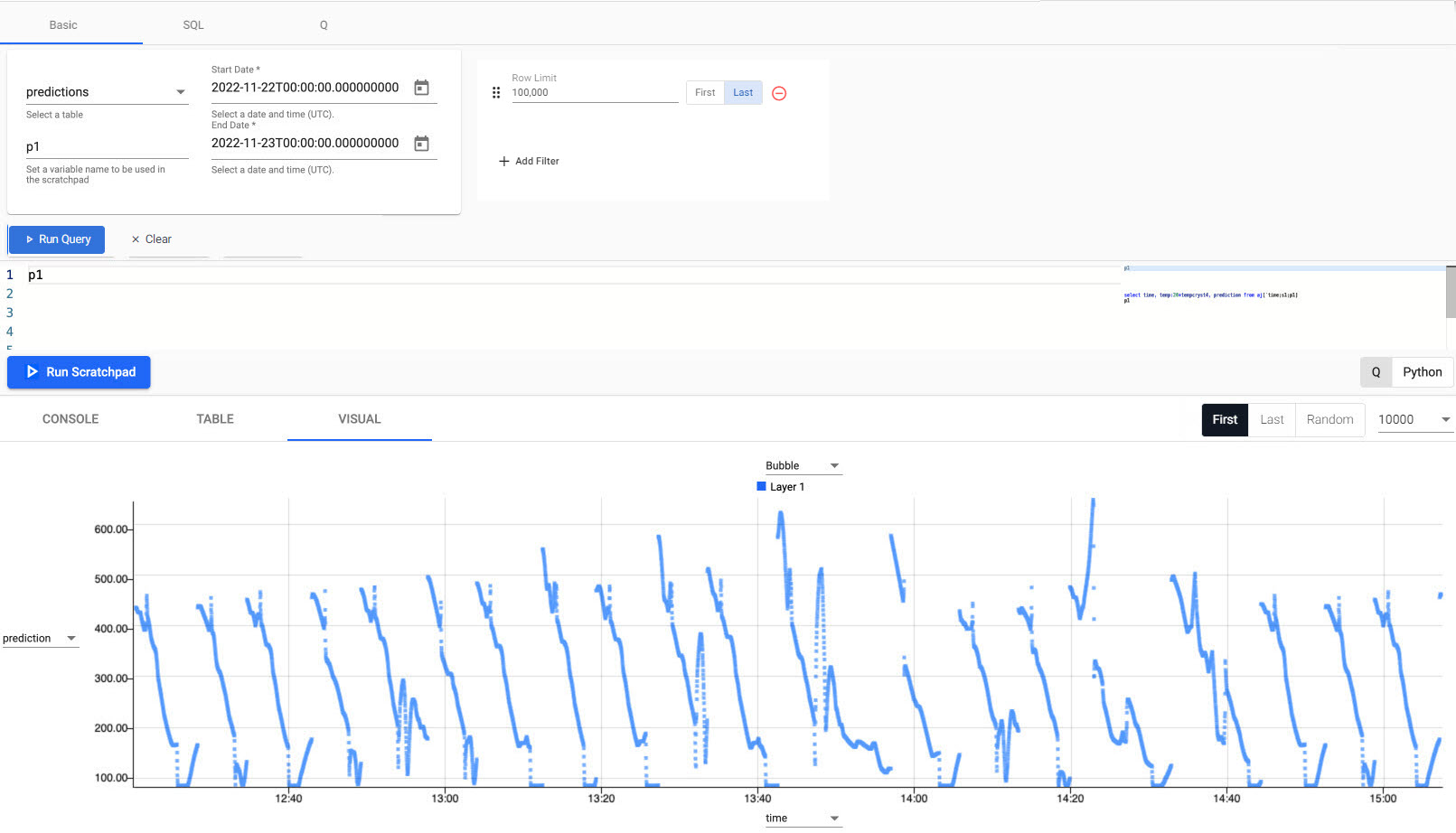
-
Compare the prediction to "real-world" data;
-
In the scratchpad paste the following:
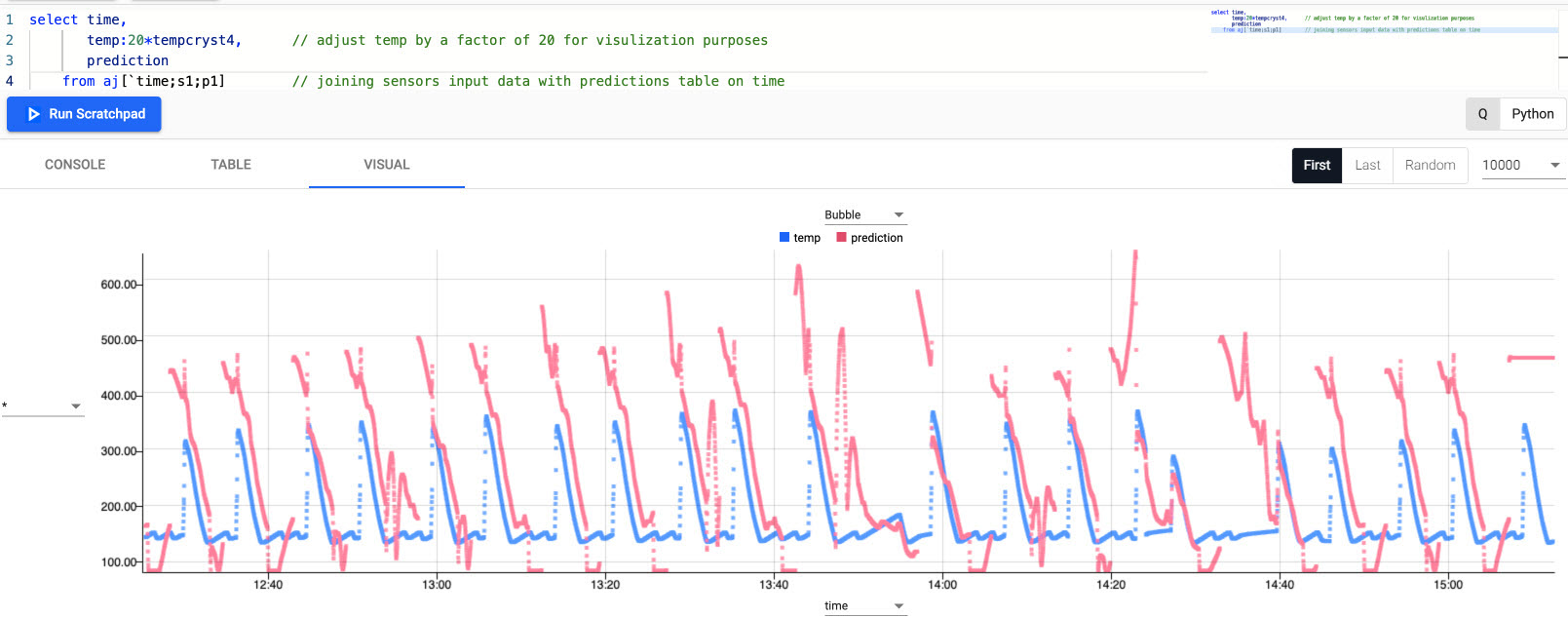
select time, temp:20*tempcryst4, // adjust temp by a factor of 20 for visualization purposes prediction from aj[`time;s1;p1] // joining sensors input data with predictions table on time -
Click
 .
.
-
Summary
While not exact, the red predictive data matches relatively well to real-world data in blue. Model performance would improve with more data.
The prediction model gives the manufacturer advance notice to when a cycle begins and expected temperatures during the cycle. Such forecasting informs the manufacturer of filtration requirements.
In a typical food processing plant, levels can be adjusted relative to actual temperatures and pressures. By predicting parameters prior to filtration, the manufacturer can alter rates in advance, thus maximising yields.
This and other prediction models can save millions of dollars in lost profits, repair costs, and lost production time for employees. By embedding predictive analytics in applications, manufacturing managers can monitor the condition and performance of assets and predict failures before they happen.