Package User-Defined functions
User-Defined functions (UDFs) are functions written in Python or q which are defined as named functions for use in a Stream Processor pipeline or the Scratchpad.
Motivation of UDFs
The addition of UDFs is motivated by the need to define analytics in a streaming context while abstracting the underlying implementation logic and language used to define the UDF. This can be particularly useful in organizations with limited numbers of either q or Python developers who wish to make the most of their development resources by allowing experts in these languages to define functionality that can be used by anyone in the organization.
Within kdb Insights Enterprise, UDFs are supported for use in the following:
-
A Stream Processor pipeline - as the input to any of the Function nodes that support code, allowing you to specify persisted custom logic to be associated with a pipeline via:
-
In the Scratchpad section of the Query Window you can:
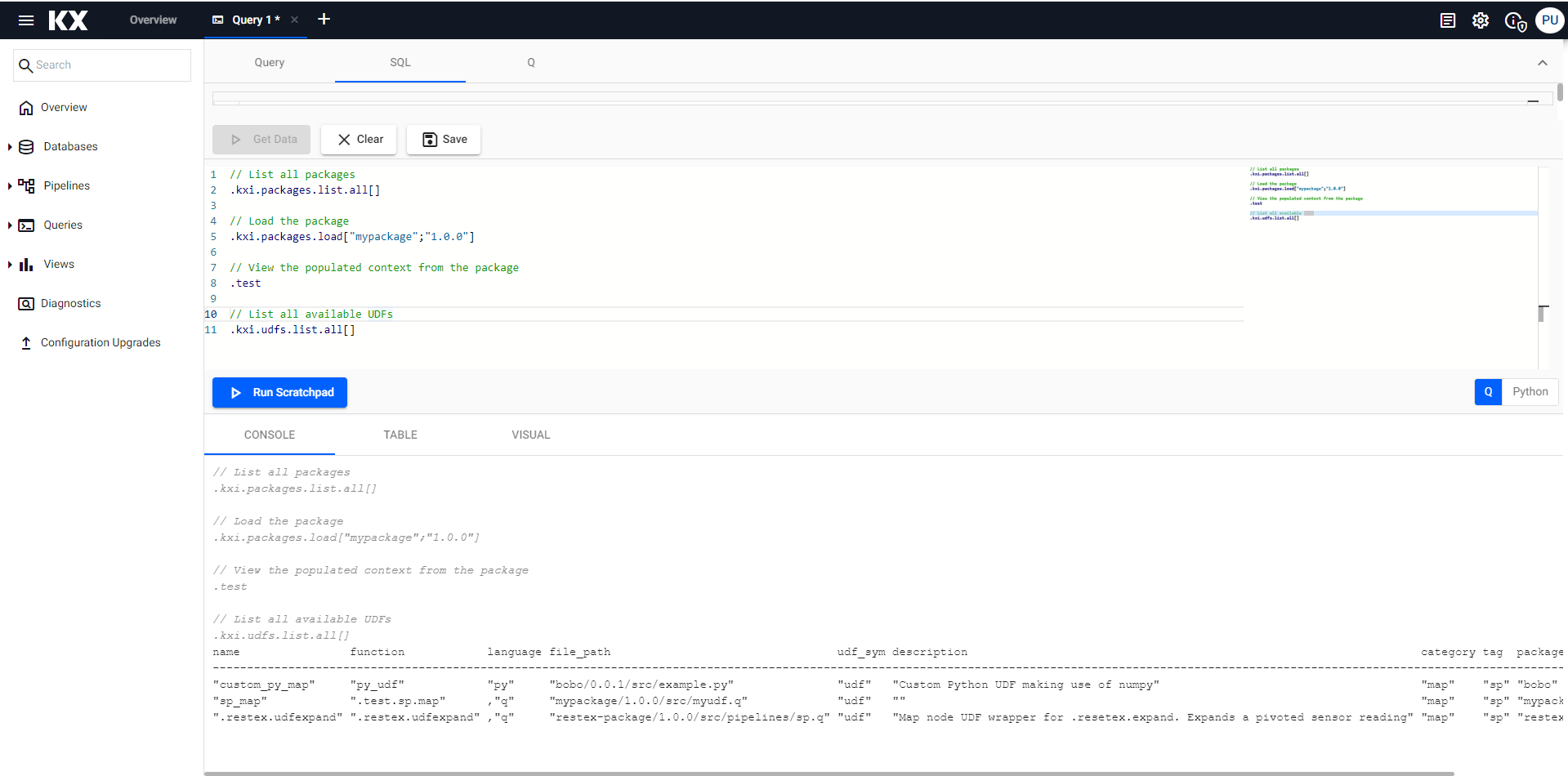
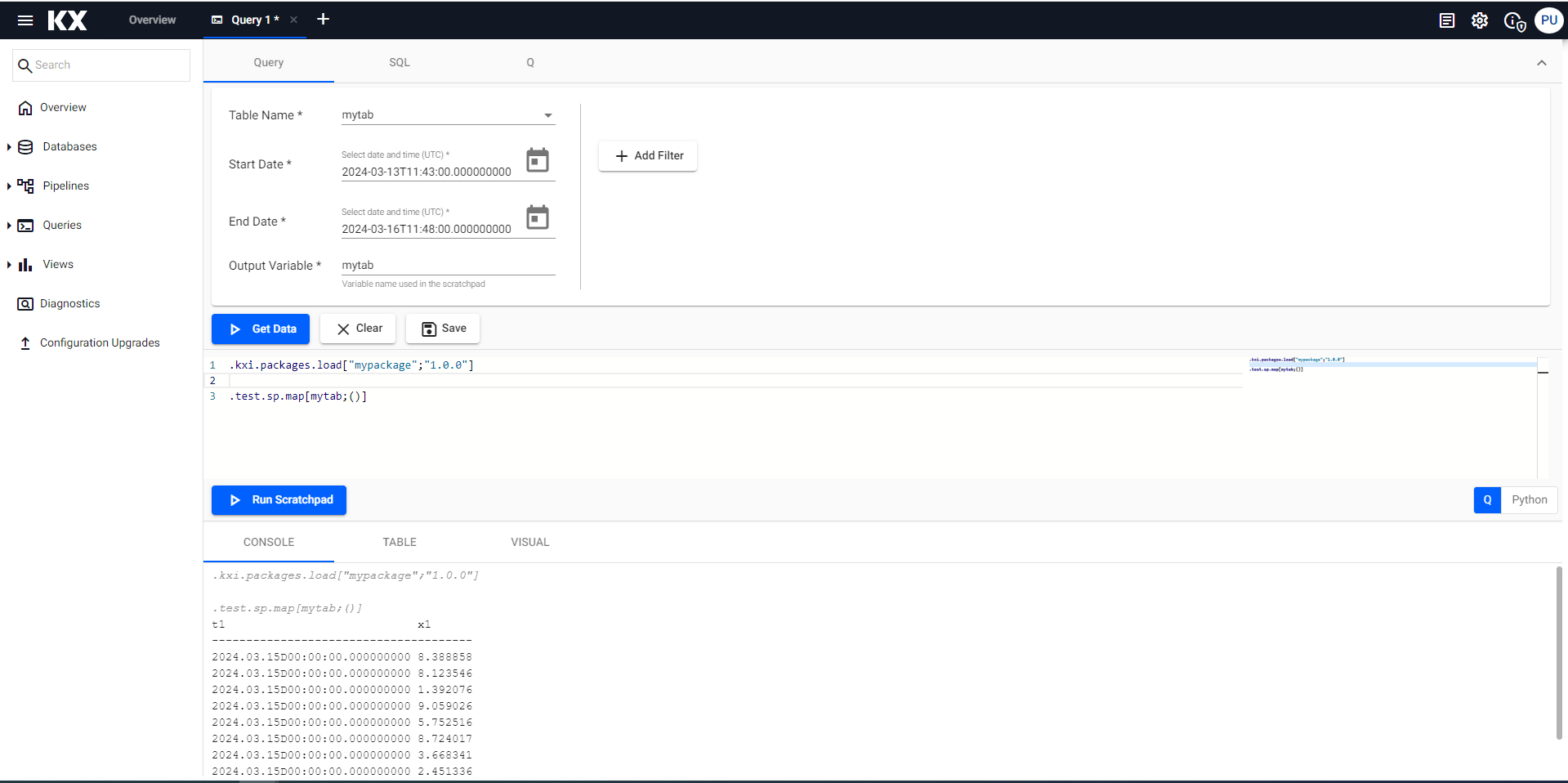
For examples of their usage see the kdb Insights Enterprise quickstart guide here.
Defining a UDF
You can define UDFs within packages using comments in q and decorators in Python. These constructs provide an association between the configuration of a UDF and the function linked with the UDF.
-
Create a file that contains the UDF definition
from kxi.packages.decorators import udf @udf.*The code below provides an example of UDF that multiples a column value by a random number between 0 and 1:
from kxi.packages.decorators import udf @udf.name('custom_py_map') @udf.description('Custom Python UDF making use of numpy') @udf.tag('sp') @udf.category('map') def py_udf(table, params): mod_column = table[params['column']] # Multiply the content of the column to be modified by random values between 0 and 1 table[params['column']] = mod_column * np.random.random_sample(len(mod_column),) return(table)// @udf.*The code below provides an example of UDF that multiples a column value by a random number between 0 and 1:
// @udf.name("custom_map") // @udf.description("Custom map function providing filtering against incoming data for a specified column and maximum threshold.") // @udf.tag("sp") // @udf.category("map") .test.my_custom_udf:{[table;params] select from table where params[`column]>params`threshold }The definition of the
@udf.*decorators are as follows:value description required default nameThe name by which the underlying UDF will be known when referenced by kdb Insights Enterprise yesN/AdescriptionA user supplied description allowing you to discern the motivation for the UDF no""tagUser specified tag to provide a domain context that this UDF was designed for. For example fx, crypto, iot. It is purely descriptive, in order to help group UDFs. no""categoryA user specified category/list of categories which can be used to define where the UDF is to be deployed. For example @udf.category(["map", "filter"])to define usage within amapandfilternode of a Pipeline.no"" -
Update the package to reference the UDF using either of the following two methods:
-
Run the
package-refreshcommand as follows:kxi package refresh mypackage -
Pack a package.
There is currently no manual way to update a package to reference a UDF.
This command searches all files for
@udfdefinitions and writes them to audfsfile. -
The following provides examples of fully defined UDFs within each language:
Fully Specified
import kxi.packages as pakx
from pakx.decorators import udf
import numpy as np
@udf.name('custom_py_map')
@udf.description('Custom Python UDF making use of numpy')
@udf.tag('sp')
@udf.category('map')
def py_udf(table, params):
mod_column = table[params['column']]
# Multiply the content of the column to be modified by random values between 0 and 1
table[params['column']] = mod_column * np.random.random_sample(len(mod_column),)
return(table)
Minimal-Information
import kxi.packages as pakx
from pakx.decorators import udf
import numpy as np
@udf.name('custom_py_map')
def py_udf(table, params):
mod_column = table[params['column']]
# Multiply the content of the column to be modified by random values between 0 and 1
table[params['column']] = mod_column * np.random.random_sample(len(mod_column),)
return(table)
Fully Specified
// @udf.name("custom_map")
// @udf.description("Custom map function providing filtering against incoming data for a specified column and maximum threshold.")
// @udf.tag("sp")
// @udf.category("map")
.test.my_custom_udf:{[table;params]
select from table where params[`column]>params`threshold
}
Minimal-Information
// @udf.name("custom_map")
.test.my_custom_udf:{[table;params]
select from table where params[`column]>params`threshold
}
UDF Constraints
The definition of your UDFs comes with the following constraints:
- When loaded, UDFs only load the file within which they are defined. This means that when you are defining UDFs, it is important to ensure that all logic required to execute the UDF is defined within the file.
- A UDF must take two or more parameters with a maximum of eight parameters supported.
- If defined in q, the function which is to be defined as a UDF must be presented beneath the relevant comment block to which it is associated with its full namespace definition, namely:
- All keywords used to define UDFs within a package must be added to the
udfssection in the packages manifest file. This is important for deployment as any UDFs defined using keywords that are not listed in the manifest file are not retrievable.
\d .test
pi:3.14
square:{x wsum x}
// @udf.name("test")
// @udf.description("This is correct as UDF will be resolved in correct namespace")
.test.user_defined_function:{[data;params]pi*square data}
\d .test
pi:3.14
square:{x wsum x}
// @udf.name("test")
// @udf.description("This is incorrect as UDF will not resolve .test namespace")
user_defined_func:{[data;params]pi*square data}
Loading files within packages
The process of adding code into your packages requires the ability to load code contained within other files within the package. Loading one file from another should not be completed using relative or absolute paths. Instead, the loading of files internal to your packages should be completed through use of the kxi.packages.packages.load_file and .kxi.packages.file.load functions for Python and q respectively. These functions load files relative to the root of the package being loaded or the package within which a UDF is being loaded. The use of the relative path from root can then be used to pin all loading from.
Examples of their usage within package files are as follows:
from kxi.packages import packages
# Load the file src/example.py
packages.load_file("src/example.py")
// Load the file src/example.q
.kxi.packages.file.load["src/example.q"]
Locked files
To facilitate the use of locked files, by default the loading functionality attempts to load the locked version of all files first, followed by the loading of unlocked files.