Build and backtest scalable trading strategies using real time and historical tick data
kdb Insights Enterprise can be used to stream live along with historical tick data to develop interactive analytics; powering faster, and better in-the-moment decision-making. This provides the following benefits.
- Streaming live tick data alongside historical data provides the big picture view of the market which enables you to maximise opportunities.
- Real-time data enables you to react to market events as they happen to increase market share through efficient execution.
- Aggregating multiple liquidity sources provides for a better understanding of market depth and trading opportunities.
Financial dataset
With kdb Insights Enterprise you can work with both live and historical data. The example in this page provides a real-time price feed alongside historical trade data. The real-time price feed calculates two moving averages. A cross between these two moving averages establishes a position (or trade exit) in the market.
Build a database
- Select Build a Database on the Overview page.
- Enter a Name for the database, such as equities.
-
Define the database schema in the Schema Settings tab. There are two options for setting up the schema:
- Column Input - this is best for small data sets.
- Code View - this is useful for large schema tables, allowing you enter the schema in JSON. For this example it is quicker if you use the Code View method.
You can try out each of these options by selecting the relevant tab below.
-
Define schemas for three data tables named as: trade, close, and analytics. Column descriptions are optional and not required here.
column data type timestamp timestamp price float volume integer column data type Date date Time timestamp Open float High float Low float Close float AdjClose float Volume long AssetCode symbol column data type timestamp timestamp vwap float twap float open float high float low float close float -
Select the Advanced toggle, located above and to the right of the field grid.
-
Update the columns below for the timestamp fields in each table:
setting value RDB Attribute none IDB Attribute sorted HDB Attribute sorted -
In the right-hand Table Properties panel, update the following settings:
setting value Type partitioned Partition Column timestamp Real-time Column Sort none Intraday Column Sort timestamp Historical Column Sort timestamp setting value Type splayed Real-time Column Sort Time Intraday Column Sort Time Historical Column Sort Time setting value Type partitioned Partition Column timestamp Real-time Column Sort timestamp Intraday Column Sort timestamp Historical Column Sort timestamp
- Click Code View.
-
Replace the JSON in the code editor with the following code.
equities schema
Paste the JSON code into the code editor:
[ { "columns": [ { "attrDisk": "sorted", "attrOrd": "sorted", "description": "KXI Assembly Schema Column", "name": "timestamp", "type": "timestamp", "compound": false, "attrMem": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "price", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "volume", "type": "int", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" } ], "description": "KXI Assembly Schema", "name": "trade", "primaryKeys": [], "prtnCol": "timestamp", "sortColsDisk": [ "timestamp" ], "sortColsMem": [], "sortColsOrd": [ "timestamp" ], "type": "partitioned" }, { "columns": [ { "description": "KXI Assembly Schema Column", "name": "Date", "type": "date", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "attrDisk": "sorted", "attrOrd": "sorted", "description": "KXI Assembly Schema Column", "name": "Time", "type": "timestamp", "compound": false, "attrMem": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "Open", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "High", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "Low", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "Close", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "AdjClose", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "Volume", "type": "long", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "AssetCode", "type": "symbol", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" } ], "description": "KXI Assembly Schema", "name": "close", "primaryKeys": [], "prtnCol": "Time", "sortColsDisk": [ "Time" ], "sortColsMem": [], "sortColsOrd": [ "Time" ], "type": "splayed" }, { "columns": [ { "attrDisk": "sorted", "attrOrd": "sorted", "description": "KXI Assembly Schema Column", "name": "timestamp", "type": "timestamp", "compound": false, "attrMem": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "vwap", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "twap", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "open", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "high", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "low", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" }, { "description": "KXI Assembly Schema Column", "name": "close", "type": "float", "compound": false, "attrMem": "", "attrOrd": "", "attrDisk": "", "foreign": "" } ], "description": "KXI Assembly Schema", "name": "analytics", "primaryKeys": [], "prtnCol": "timestamp", "sortColsDisk": [ "timestamp" ], "sortColsMem": [], "sortColsOrd": [ "timestamp" ], "type": "partitioned" } ] -
Click Apply to apply the JSON to setup the database schema.
-
Click Save to save the new database and its schema.
-
Click Deploy. The resources summary screen is displayed. Click Deploy if you are satisfied with the resources allocated to the database. The database runs through the deployment process.
-
Hover over the icon beside the database name in the left-hand menu or over the Getting Ready status for the database in the Databases screen to see the progress of each of the processes. This can take several minutes depending on the resources that are available in your deployment. When successful, the database listed in the left-hand menu shows a green tick and is active for use.
Database warnings
Once the database is active some warnings are displayed in the Issues pane of the Database Overview page, these are expected and can be ignored.
Ingest live data
The live data feed uses Apache Kafka. Apache Kafka is an event streaming platform whose data is easily consumed and published by kdb Insights Enterprise.
- Select Import on the Overview page.
-
Select the Kafka from the set of readers and complete the connection details as follows:
Setting Value Broker* kafka.trykdb.kx.com:443 Topic* spx Keep the defaul values for the following settings.
Setting Value Offset* End Use TLS Unchecked Use Schema Registry Unchecked -
Expand the Advanced parameters section and tick Advanced Broker Options.
-
Click +, under Add an Advanced Configuration, to add the following key value-pairs:
key value sasl.username demo sasl.password demo sasl.mechanism SCRAM-SHA-512 security.protocol SASL_SSL -
Click Next.
-
Event data on Kafka is of type JSON. Select th JSON Decoder.
- In the Configure JSON screen click Next, leaving Decode each unchecked.
-
Incoming data is converted to a type compatible with a kdb Insights Enterprise database using a schema. The schema is already defined as part of database creation.
-
Leave the value of Data Format set to Any.
-
Click the Load Schema icon
 and select the following values
and select the following values -
Database = Equities
-
Table = Trade
-
Click Next.
-
-
The Writer step defines which database and table the data is written to. Use the database and table defined earlier.
Setting Value Database Name as defined earlier, equities Table trade Keep the defaul values for the following settings.
Setting Value Write Direct to HDB Unchecked Deduplicate Stream Checked Set Timeout Value Unchecked -
Click Open Pipeline to open a view of the pipeline in the pipeline template.
Modify pipeline
At this stage the pipeline is setup to convert data from an incoming JSON format on the Kafka feed, to a kdb+ friendly dictionary. Another node is required to convert the data from a kdb+ dictionary to a kdb+ table before deployment. This is done using enlist in a Map node.
- In the pipeline template, click and drag the Map Function node into the pipeline template workspace.
- Disconnect the Decoder and Transform nodse by right-clicking on the join and clicking Remove Edge.
-
Insert the Map function between the Decoder and Transform nodes by dragging-and-connecting the edge points of the Decoder node to the Map node, and from the Map node to the Transform node, as shown below.

-
Click on the Map function node and replace the code in the code editor with the following. You have the choice of using either Q, Python code or UDF.
{[data] enlist data }import pandas as pd import pykx as kx def func(data): dataDict = data.pd() vals,keys = list(dataDict.values()), list(dataDict.keys()) newDf = pd.DataFrame(vals,index=keys) return kx.K(newDf.transpose()) -
Click Apply to save the details to the node.
-
Enter a unique Name in the top left of the workspace, such as trade.
-
Click Save & Deploy.
Ingest historical data
Where Kafka is used to feed live data to kdb Insights Enterprise, historic data is kept on object storage. Object storage is ideal storage for unstructured data, eliminating the scaling limitations of traditional file storage. Limitless scale makes it the default storage of the cloud with Amazon, Google and Microsoft all employing object storage as their primary storage.
Historical data, in the trade table is maintained on Microsoft Azure Blob Storage.
- Select Import on the Overview page.
-
Select the Microsoft Azure Storage reader and complete the properties.
Setting Value MS URI ms://kxevg/close_spx.csv Account kxevg Keep the defaul values for the following settings.
Setting Value Tenant Not applicable File Mode* Binary Offset* 0 Chunking* Auto Chunk Size* 1MB Use Watching Unchecked Use Authentication Unchecked -
Click Next.
- The historic data is stored as a csv file in the cloud. Select CSV decoder and keep the default settings.
- In the Configure CSV screen keep all the default values and click Next.
- In the Configure Schema screen, transform the data into a format compatible with a kdb Insights Enterprise database with a schema.
- Leave Data Format unchanged as Any.
- Click the Load Schema icon , select the equities database created earlier, see here. Select the close table schema.
- Click Load to apply the schema.
- Click Next.
-
In the Configure Writer screen define the following settings:
Setting Value Database Name as defined in the section Build a database Table close Keep the defaul values for the following settings.
Setting Value Write Direct to HDB Unchecked Deduplicate Stream Checked Set Timeout Value Unchecked -
Click Open Pipeline to open a view of the pipeline.
-
Enter a unique Name for the pipeline in the top left of the workspace. For example, close.
-
Click Save & Deploy..
Deploying the pipelines reads the data from its source, transform it to a kdb+ compatible format, and write it to the database.
Check the progress of the pipelines, that have been deployed, under the Running Pipelines panel of the Overview tab, which may take several minutes.
The data is loaded when the trade pipeline reaches a Status of Running and the close pipeline reaches a Status of Finished.
Query the data
Data queries are run in the Query tab, accessible from the [+] of the ribbon menu, or Query on the Overview page.
-
Click the SQL tab and enter the following command to retrieve a count of streaming events in the
tradetable:3. Define the Output Variable as t.SELECT COUNT(*) FROM trade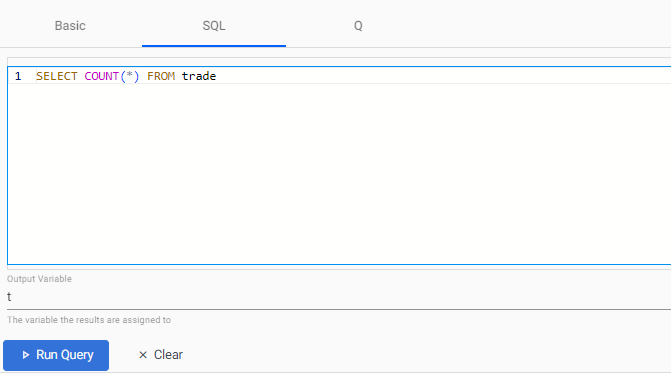
-
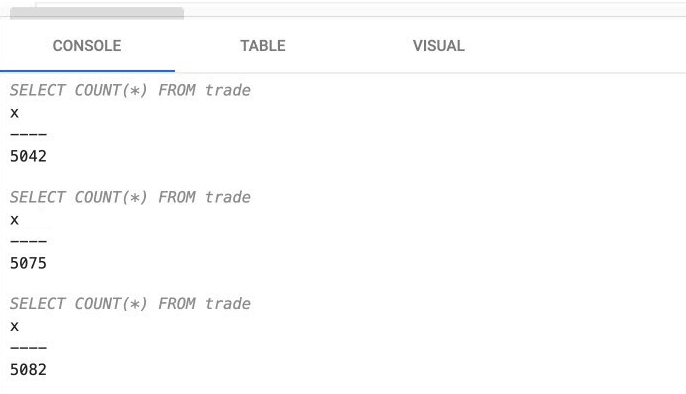
Click Run Query to execute the query. Re-run the query to get an updated value. The results are displayed in the lower part of the Query screen, as shown below.
-
Right-click in the Console and click Clear to clear the results.
-
In the SQL tab, replace the existing code with:
SELECT * FROM close -
Define the Output Variable as
t. -
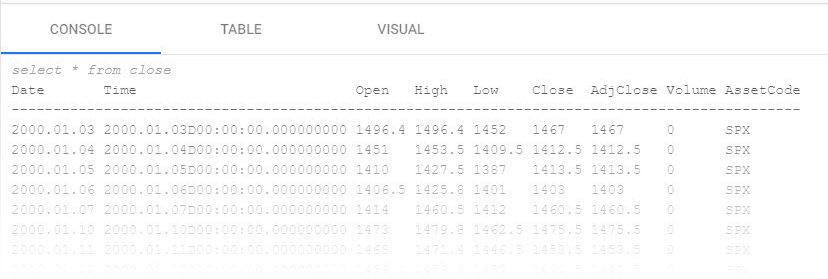
Click Run Query to execute the query. The results are displayed in the Console as illustrated in the example below which shows end-of-day S&P historic prices.
Create powerful analytics
Using the data, a trade signal is created to generate a position in the market (S&P).
-
Replace the text in the code editor with the following query:
SELECT * FROM trade -
Set the Output Variable to t.
-
Click Get Data to execute the query to get the trade data into a variable t for use in the rest of this section.
-
In the output section, toggle between Console, Table or Visual for different views of the data. For example, a chart of prices over time.
-
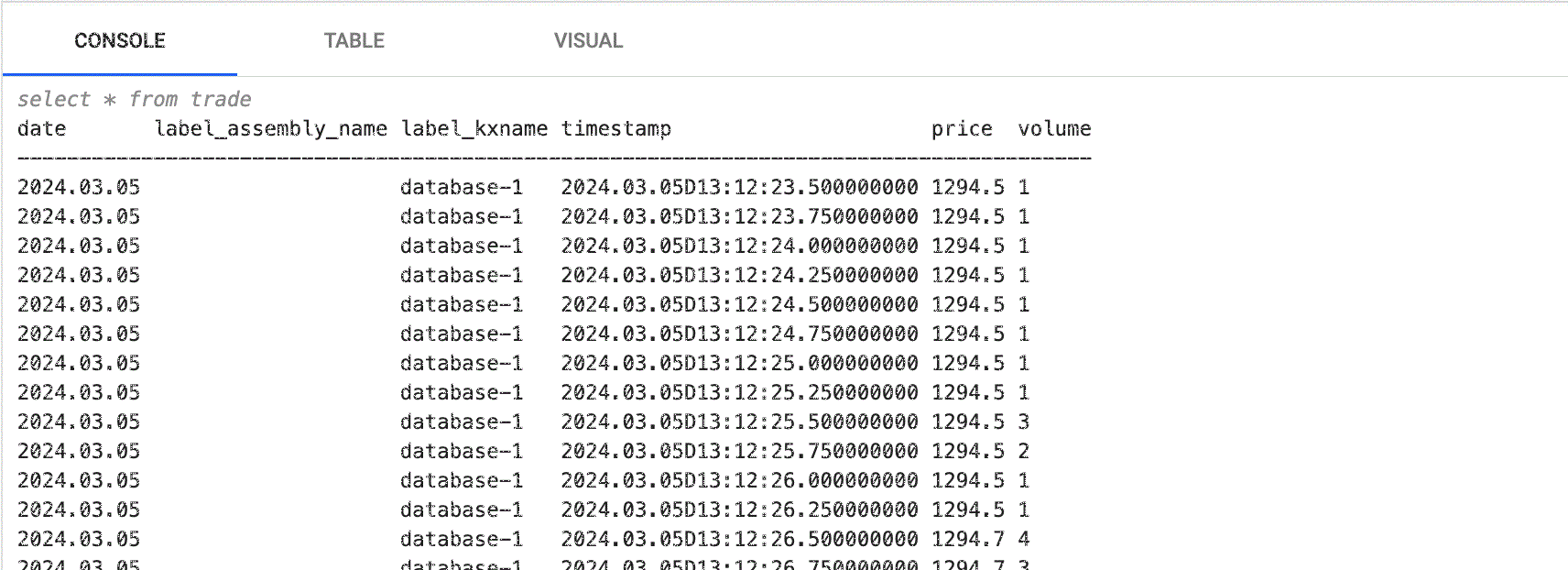
Click Get Data again after changing tabs. The following screenshot shows an SQL query against streaming trade data, viewed in the console.
Long and short position simple moving averages
This strategy calculates two simple moving averages, a fast short time moving average, and a slow long time period moving average.
When the fast line crosses above the slow line, we get a 'buy' trade signal, with a 'sell' signal on the reverse cross.
This strategy is also an always-in-the-market signal, so when a signal occurs, it not only exits the previous trade, but opens a new trade in the other direction; going long (buy low - sell high) or short (sell high - buy back low) when the fast line crosses above or below the slow line.
-
Enter the following code to create a variable analytics in the scratchpad to calculate the fast and slow moving average.
// taking the close price we calculate two moving averages: // 1) shortMavg on a window of 10 sec and // 2) longMavg on a window of 60 analytics : select timestamp, price, shortMavg:mavg[10;price], longMavg:mavg[60;price] from t -
Click Run Scratchpad.
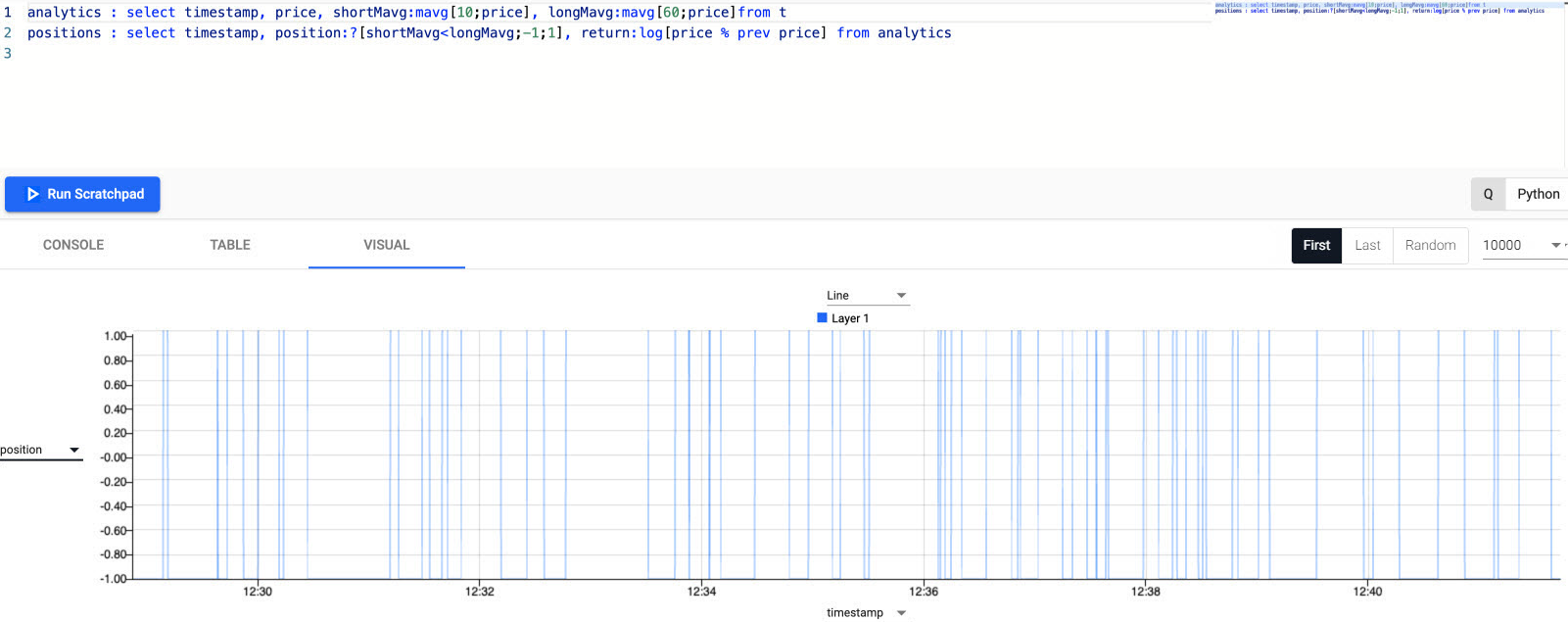
This strategy uses a 10-period moving average for the fast signal, and a 60-period moving average for the slow signal. Streamed updates for the moving average calculations are added to the chart, as illustrated below.
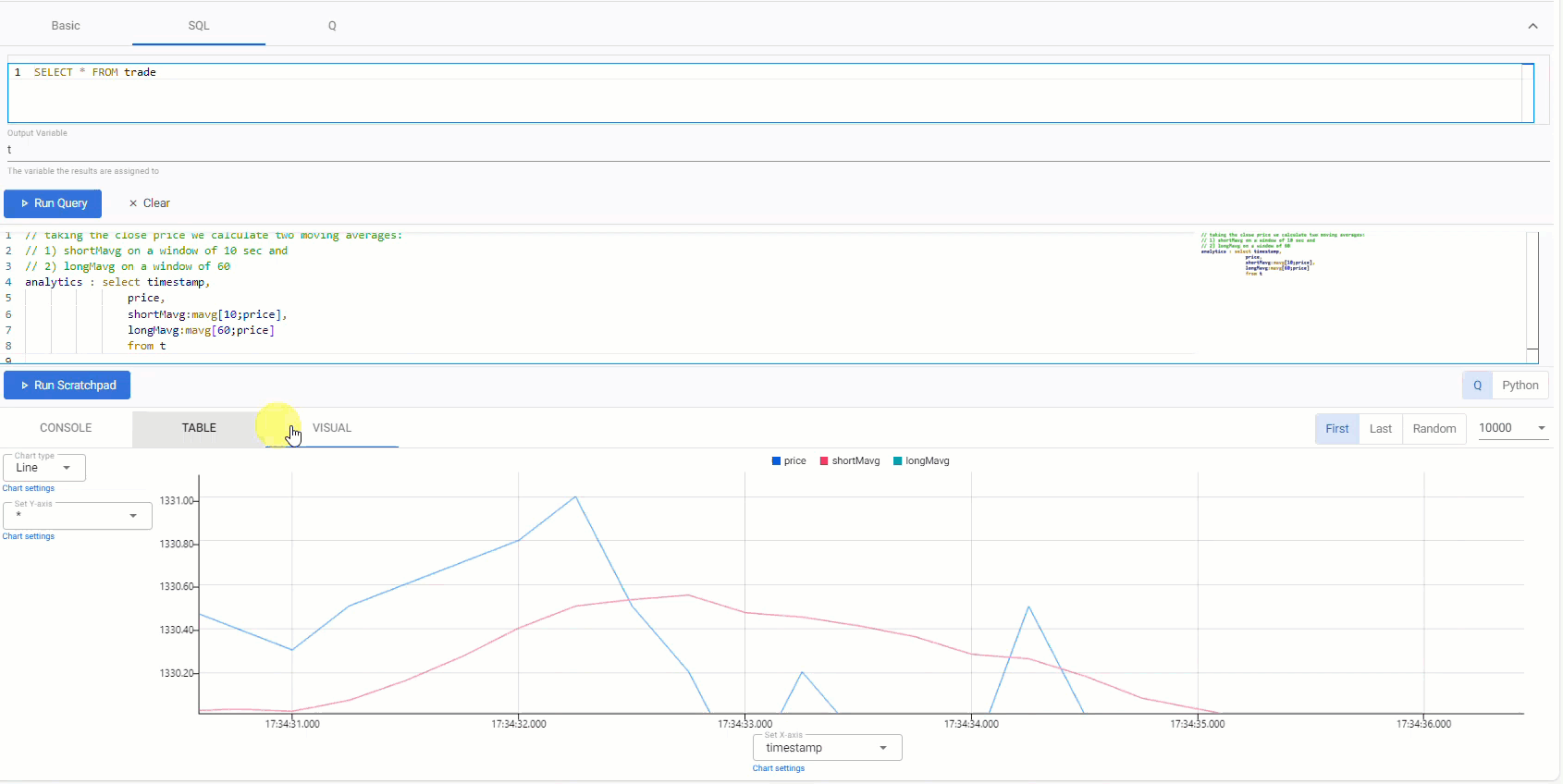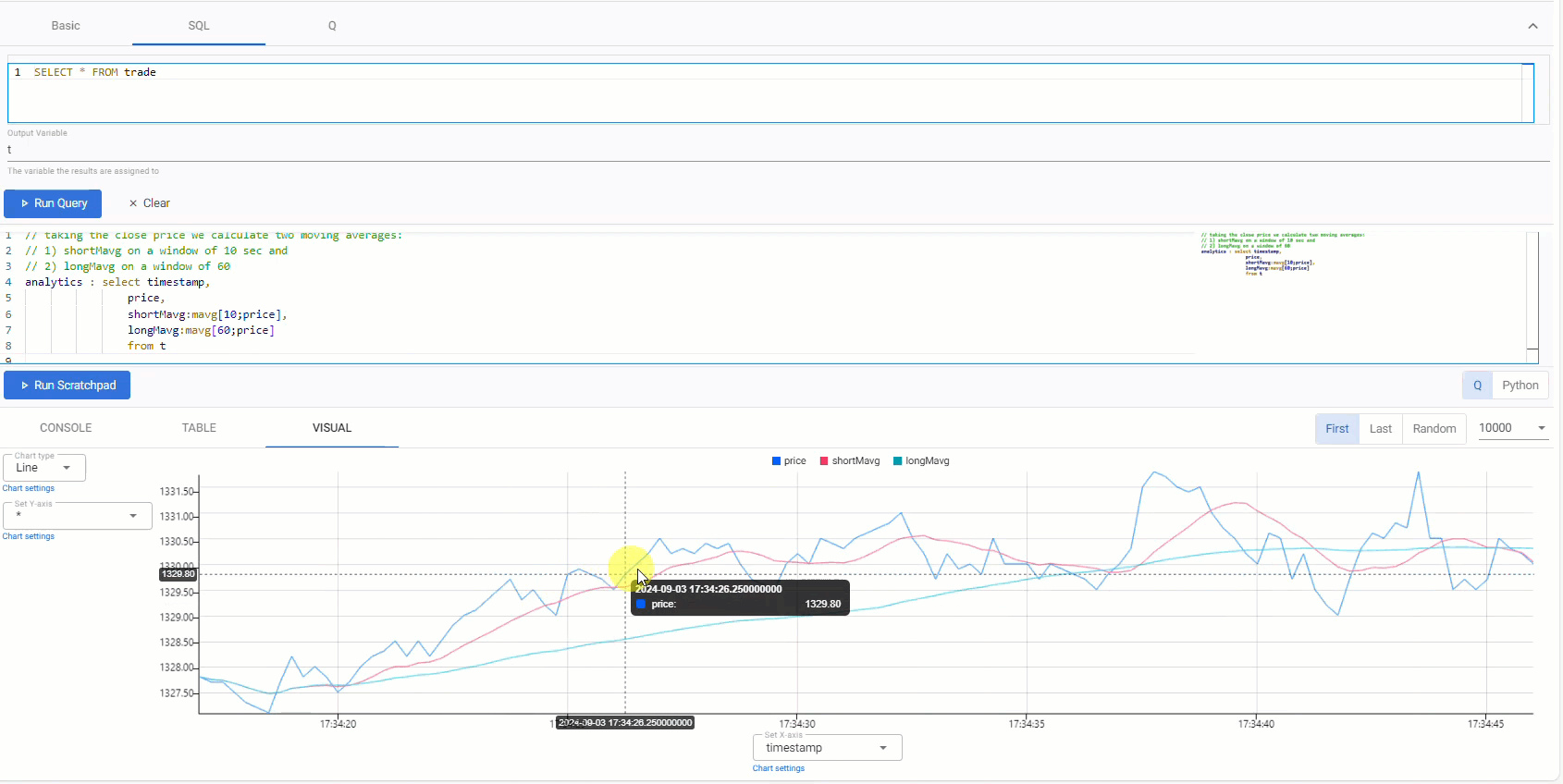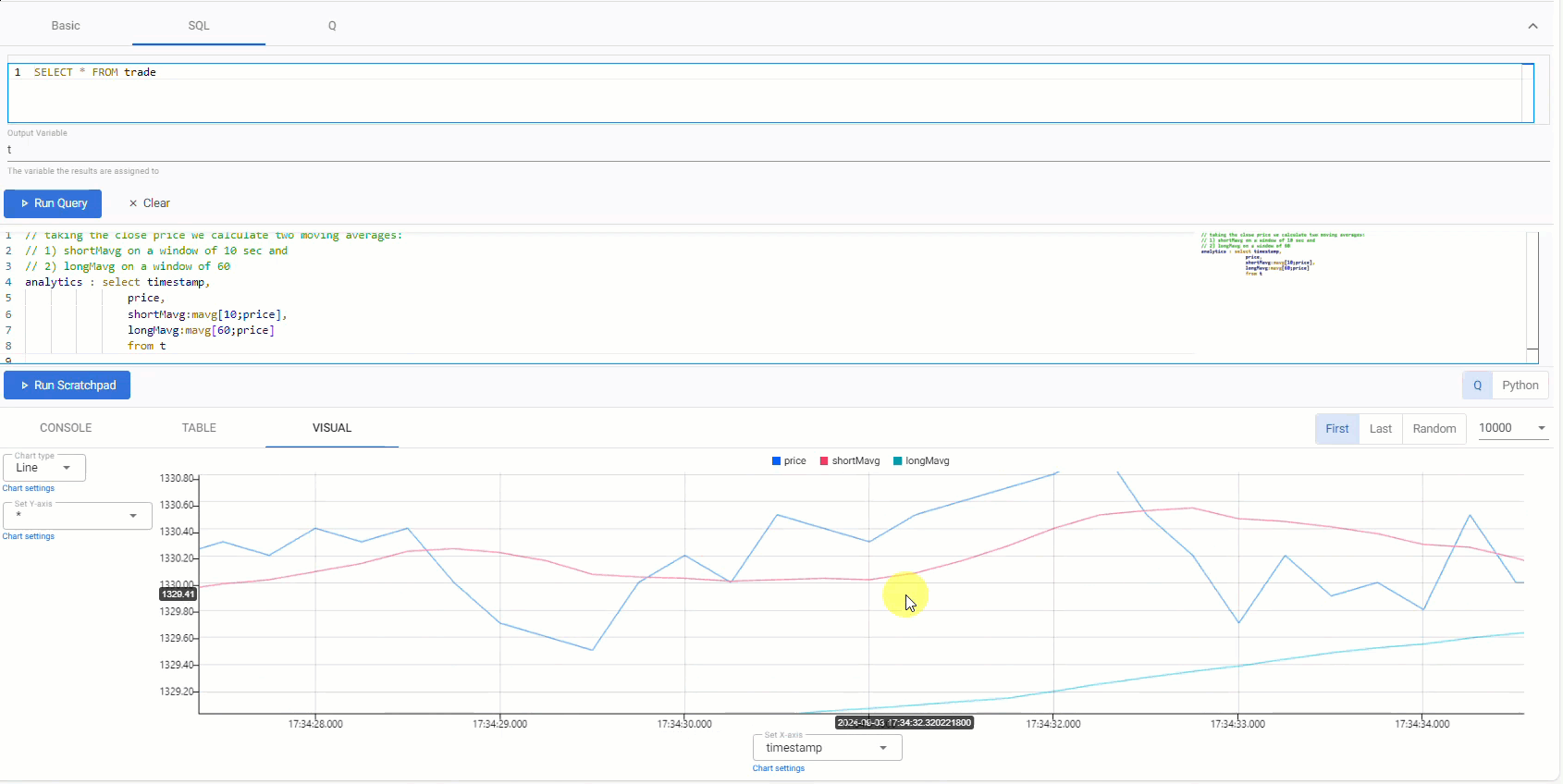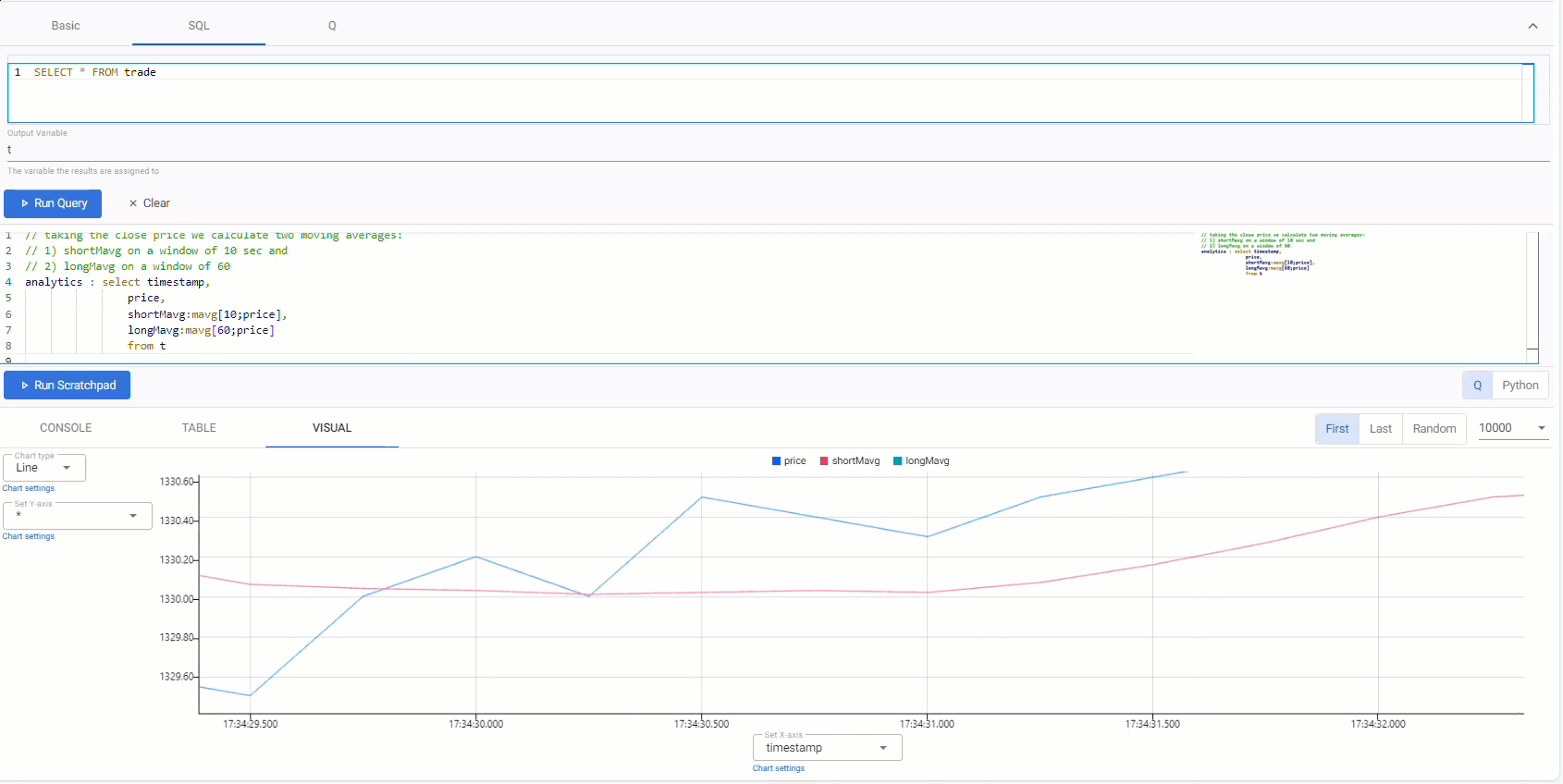
Trade position
The crossover of the two fast and slow moving averages creates trades. These can be tracked with a new variable called positions.
-
In the scratchpad, append the following:
// when shortMavg and long Mavg cross each other we create the position // 1) +1 to indicate the signal to buy the asset or // 2) -1 to indicate the signal to sell the asset positions : select timestamp, position:?[shortMavg<longMavg;-1;1], return:log[price % prev price] from analytics -
Click Run Scratchpad. A position analytic to track crossovers between the fast and slow moving averages is displayed in the query visual chart, as shown in the following screenshot.
q/kdb+ functions explained
If any of the above code is new to you don't worry, we have detailed the q functions used above:
| Function | Description |
|---|---|
| ?[x;y;z] | When x is true return y, otherwise return z |
| x<y | Returns true when x is less than y, otherwise return false |
| log | To return the natual logarithm |
| x%y | Divides x by y |
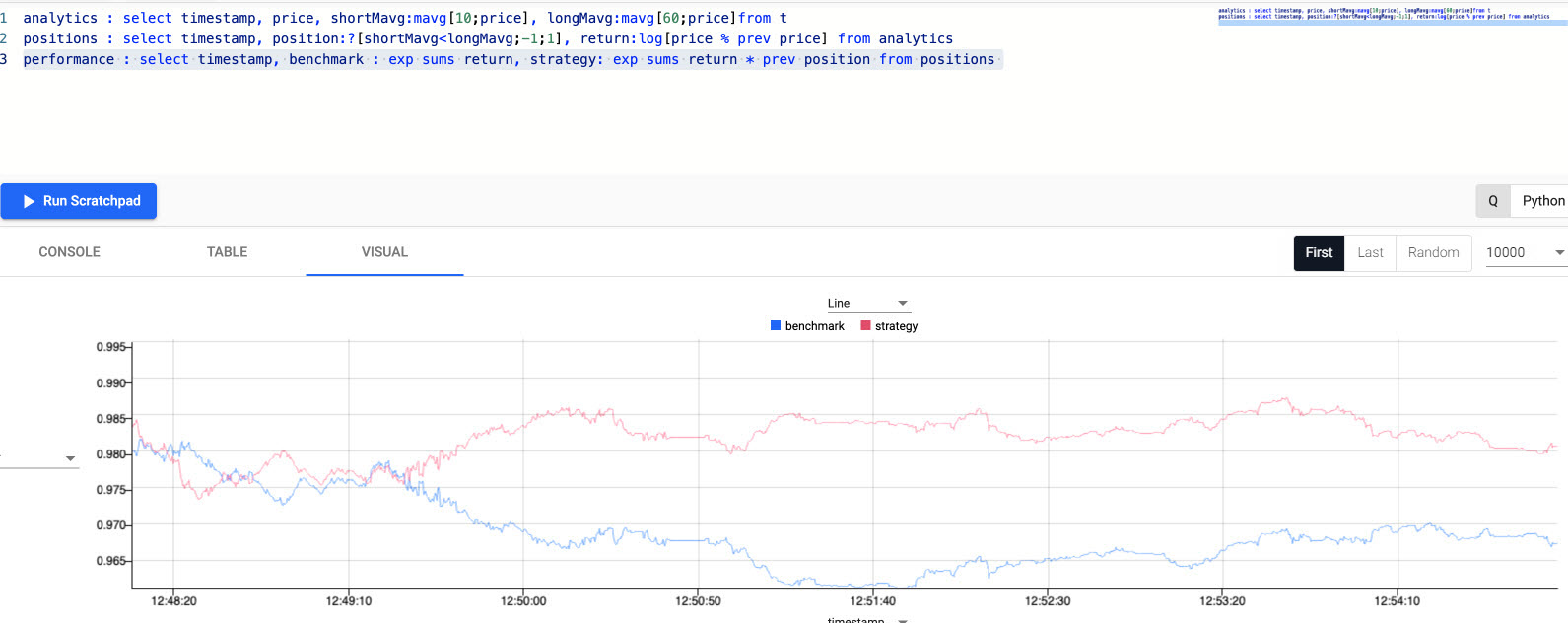
Active versus passive strategy
The current, active strategy is compared to a passive strategy; that is a strategy tracking a major index, like the S&P 500 or a basket of stocks, such as an ETF. We want to know if our strategy performs better.
-
In the Scratchpad, append the following code, to create a new variable called performance which generates a benchmark to compare strategy performance to.
performance : select timestamp, benchmark: exp sums return, strategy: exp sums return * prev position from positions -
Click Run Scratchpad.
q/kdb+ functions explained
If any of the above code is new to you don't worry, we have detailed the q functions used above:
| Function | Description |
|---|---|
| exp | Raise e to a power where e is the base of natual logarithms |
| sums | Calculates the cumulative sum |
| * | To multiply |
| prev | Returns the previous item in a list |
The results are plotted on a chart, as shown below, which shows that the active strategy outperforms the passive benchmark.
Create a View
Up to now, ad hoc comparative analysis was conducted in the Scratchpad with the results displayed in the Results tabs. We can perform more complex analysis and visualizations by creating a View.
Saving analytics to a database
Before creating a View, we must save the analytics to a database. The quickest way to do this is to modify the data pipeline used by the analytic.
-
Open the trade pipeline template; select it from the left-hand pipeline menu on the Overview page.
-
If the pipeline is still running, click Teardown and select Clean up resources after teardown.
-
From the pipeline template view, add a Split node from the list of Function nodes. Position it between the Map node and the Apply Schema node. Right-click existing links to clear, before reconnecting the point-edges with a drag-and-connect. This leaves one available point-edge in the Split node, as illustrated below.
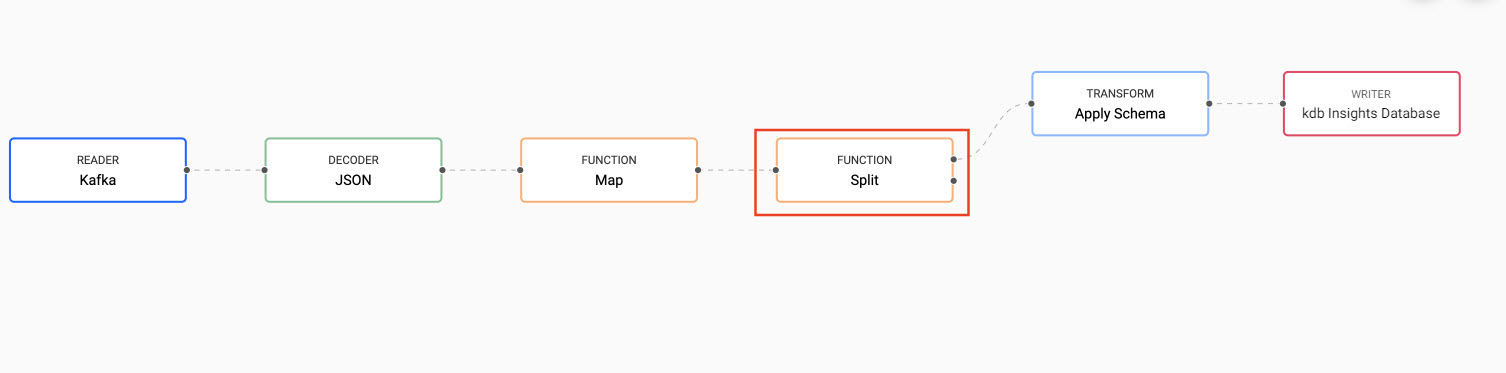
Read more about the Function Split node here.
-
Add a Timer Window node to the pipeline workspace. Connect it to the second point-edge of the Split node, as illustrated in the following screenshot. The Timer Window aggregates incoming data by time.
-
Click on the Timer Window and value of Period to 0D00:00:05. This ensures the timer runs every 5 seconds.
Keep the remainder of the settings as default.
Setting Value Skip Empty Windows Unchecked Use Count Trigger Unchecked Accept Dictionaries Checked 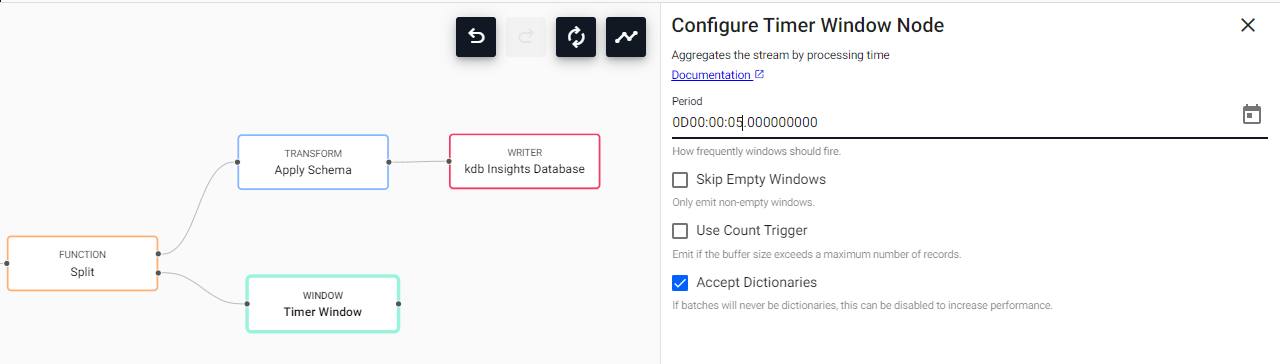
Read more about the Window Timer Windows here.
-
Click Apply.
-
Next we define the business logic for the analytic in a Map node. Add a Map node from the Functions, and connect it to the Timer Window node. Click on the Map node and replace the code displayed with the following code, as shown below.
// the following code is calculating the fields: // 1) vwap = weighted average price, adjusted by volume, over a given time // 2) twap = weighted average price over a given time // 3) open = price at which a security first trades when an exchange opens for the day // 4) high = highest price security is traded at // 5) low = lowest price security is traded at // 6) close = price at which a security last trades when an exchange closes for the day // 7) volume = volume of trades places {[data] select last timestamp, vwap:|[1;volume] wavg price, twap:last[price]^(next[timestamp]-timestamp) wavg price, open:first price, high:max price, low:min price, close: last price from update "P"$timestamp, volume:|[1;volume] from data }kdb+/q functions explained
If any of the above code is new to you don't worry, we have detailed the q functions used above:
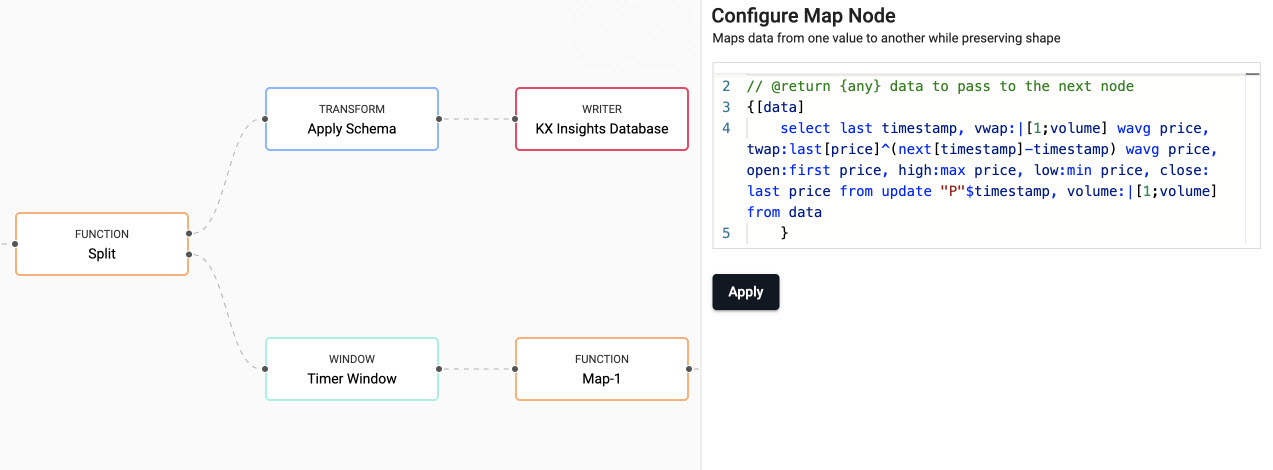
-
Click Apply to apply these settings to the node.
-
The data generated by the analytic must be transformed and written to the database. In the same way you did it for the trade table, connect an Apply Node node and a kdb Insights Database node to the Map node, as shown below. Use the equities database that you created earlier, and the analytics table for the schema and writing to database.
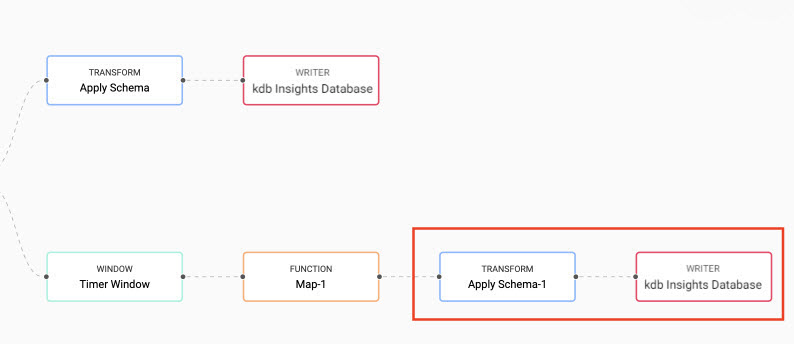
-
Click Save & Deploy to deploy the modified pipeline. A successful deployment shows Status of Running under Running Pipelines on the Overview page.
Load and review the ready-made view
To create a View: 1. Click + on the ribbon menu and click View, or click Visualize on the Overview page. 1. Upload the ready-made View: 1. Click here to display a JSON representation of the ready-made Equities View in a new browser window. 1. Select all the text in the new browser window and copy it into an empty text file using the editor of your choice. 1. Save the file on your machine. The file must be saved with a .json extension. 1. Drag the file over the View, going to the top left-hand corner. When the workspace is highlighted in blue and Drop Dashboards to Import is displayed in the center of the workspace you can drop the file. The ready-made View is displayed in a new tab.
Note that the dashboard has two screens.
-
The Chart view uses both live and historic data for the big picture in the market.
The top chart in the dashboard plots the price data and VWAP analytic generated by the trade pipeline.
The lower chart plots historic index data ingested by the Azure object storage pipeline.
The following screenshot shows the new View. The top chart is a live feed of price and the calculated VWAP analytic. The lower chart is a time series chart of historic index data.
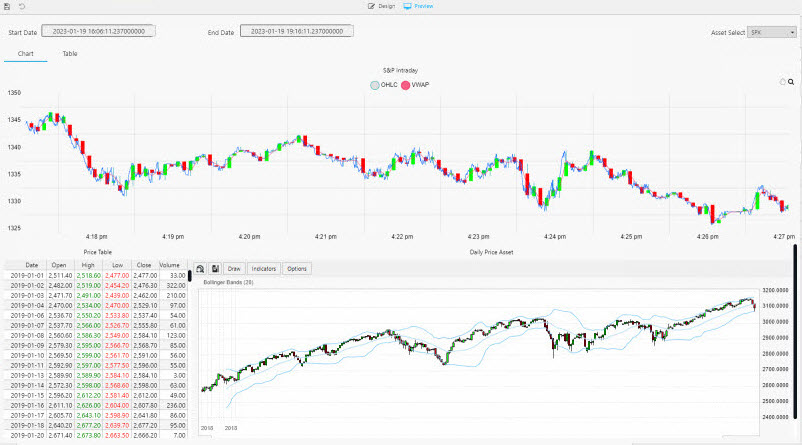
-
The Table dashboard view tracks positions in the market.
In the top chart, a green highlight is used if a Long (a buyer) trade, or red if Short (a seller).
A similar highlight is used in the table on the left and in the volume bars of the lower chart.
The following screenshot illustrates the Chart view showing the strategy position in the market. Long trades are marked in green and short trades in red.
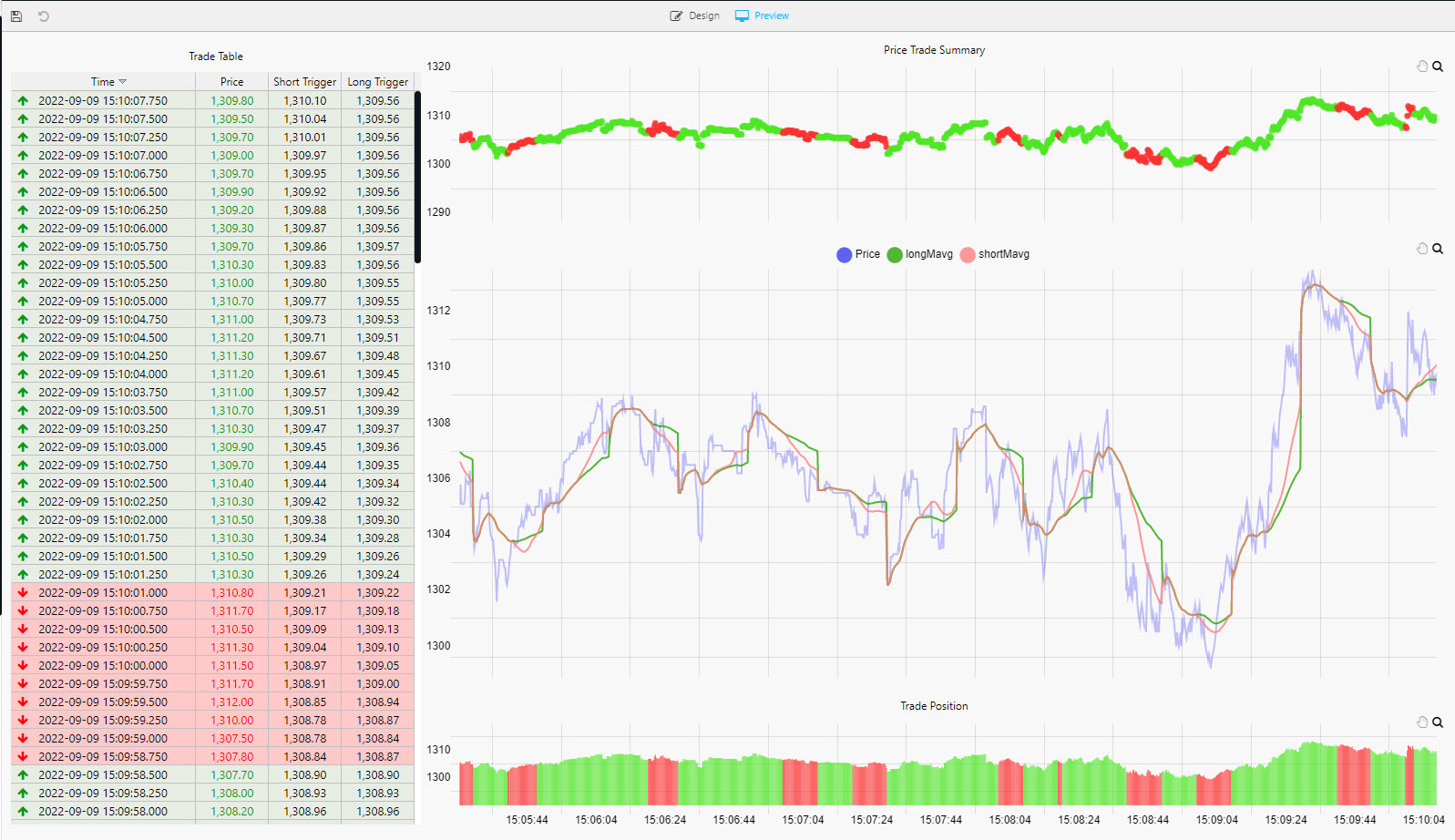
Next Steps
- Learn how to build and run a machine learning model to create stock predictions in real-time on this financial dataset in the next tutorial.