Decoders
Decode an external data format into the Stream Processor
Decoding allows data to be converted into a format that can be processed directly within the Stream Processor. Decoders need to be used when ingesting data from an external data format before performing other transformations.
See APIs for more details
A q interface can be used to build pipelines programmatically. See the q API for API details.
A Python interface is included alongside the q interface and can be used if PyKX is enabled. See the Python API for API details.
The pipeline builder uses a drag-and-drop interface to link together operations within a pipeline. For details on how to wire together a transformation, see the building a pipeline guide.
Arrow
(Beta Feature) Decodes Arrow encoded data
Beta Features
Beta feature are included for early feedback and for specific use cases. They are intended to work but have not been marked ready for production use. To learn more and enable beta features, see enabling beta features.
![]()
See APIs for more details
q API: .qsp.decode.arrow •
Python API: kxi.sp.decode.arrow
Required Parameters:
| name | description | default |
|---|---|---|
| As List | If checked, the decoded result is a list of arrays, corresponding only to the Arrow stream data. Otherwise, by default the decoded result is a table corresponding to both the schema and data in the Arrow stream. | No |
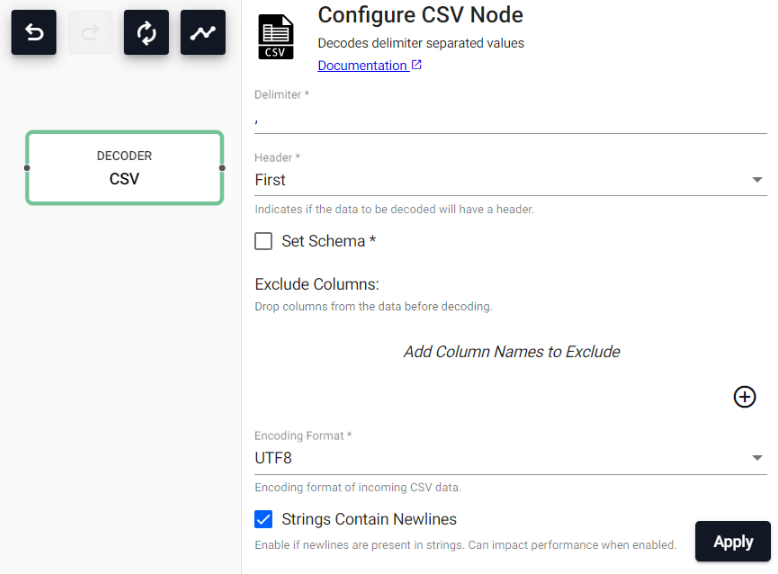
CSV
Parse CSV data to a table
See APIs for more details
q API: .qsp.decode.csv •
Python API: kxi.sp.decode.csv
Required Parameters:
| name | description | default |
|---|---|---|
| Delimiter | Field separator for the records in the encoded data | , |
Optional Parameters:
| name | description | default |
|---|---|---|
| Header | Defines whether source CSV file has a header row, either Always, First and Never. When set to Always, the first record of every batch of data is treated as being a header. This is useful when decoding a stream (ex. Kafka) and each message has a header. First indicates that only the first batch of data will have a CSV header. This should be used when processing files that have a header row. Lastly, None indicates that there is no header row in the data. |
First |
| Schema | A table with the desired output schema. | |
| Columns to Exclude | A list of columns to exclude from the output. | |
| Encoding Format | How the data is expected to be encoded when being consumed. Currently supports UTF8 and ASCII. |
UTF8 |
| Newlines | Indicates whether newlines may be embedded in strings. Can impact performance when enabled. | 0b |
Expected type formats
The parse option allows for string representations to be converted to typed values. For numeric values to
be parsed correctly, they must be provided in the expected format. String values in unexpected formats may
be processed incorrectly.
- Strings representing bytes are expected as exactly two base 16 digits, e.g.
"ff" - Strings representing integers are expected to be decimal, e.g.
"255" - Strings representing boolean values have a number of supported options, e.g.
"t","1"- More information on the available formats.
GZIP
(Beta Feature) Inflates (decompresses) gzipped data
Beta Features
Beta feature are included for early feedback and for specific use cases. They are intended to work but have not been marked ready for production use. To learn more and enable beta features, see enabling beta features.
See APIs for more details
q API: .qsp.decode.gzip •
Python API: kxi.sp.decode.gzip
Fault Tolerance
GZIP decoding is currently not fault tolerant which is why it is marked as a beta feature. In the event of failure, the incoming data must be entirely reprocessed from the beginnging. The GZIP decoder is only fault tolerant when you are streaming data with independently encoded messages.
GZIP requires no additional configuration. On each batch of data, this operator decodes as much data as it can passing it down the pipeline and buffering any data that cannot be decoded until the next batch arrives.
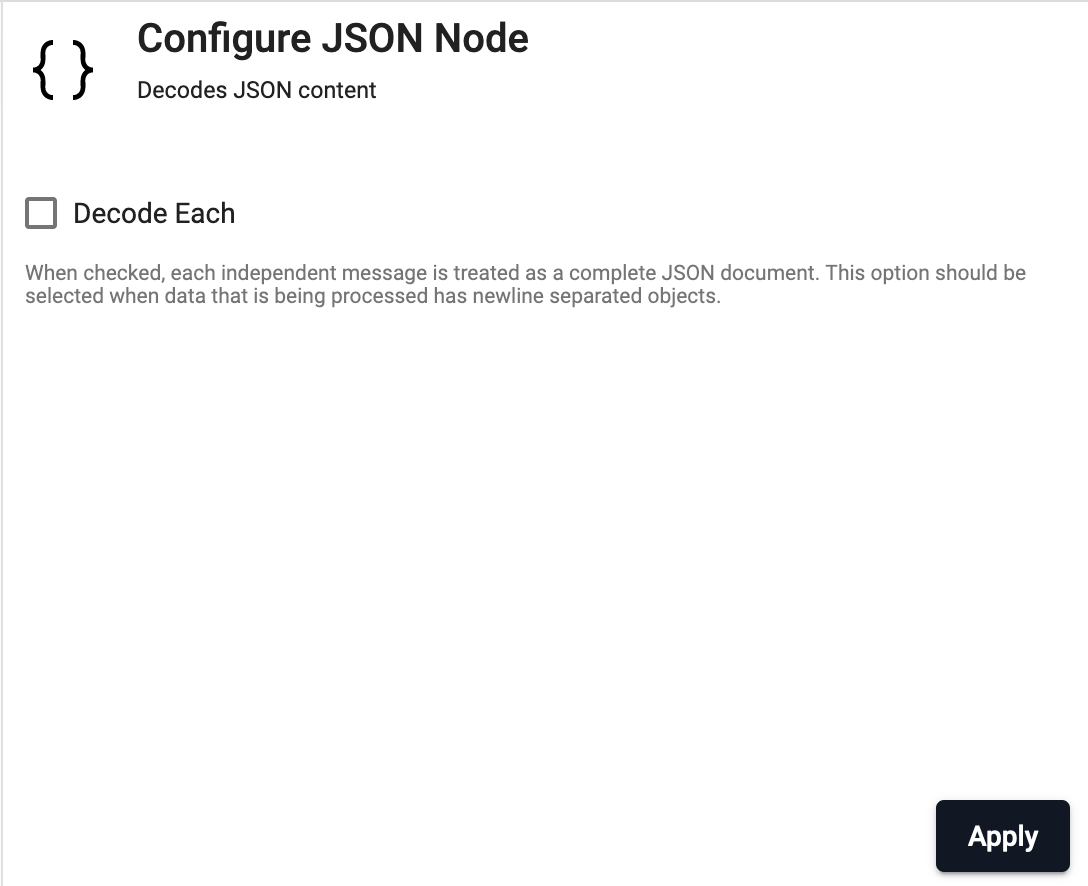
JSON
Parse JSON data
See APIs for more details
q API: .qsp.decode.json •
Python API: kxi.sp.decode.json
Required Parameters:
| name | description | default |
|---|---|---|
| Decode Each | By default messages passed to the decoder are treated as a single JSON object. Setting decodeEach to true indicates that parsing should be done on each value of a message. This is useful when decoding data that has objects separated by newlines. This allows the pipeline to process partial sets of the JSON file without requiring the entire block to be in memory. |
No |
Pcap
Decode Pcap Data
See APIs for more details
q API: .qsp.decode.pcap •
Python API: kxi.sp.decode.pcap
Required Parameters:
| name | description | default |
|---|---|---|
| Columns to Include | The columns to include. If none of the options are selected, the output will include every available column. |
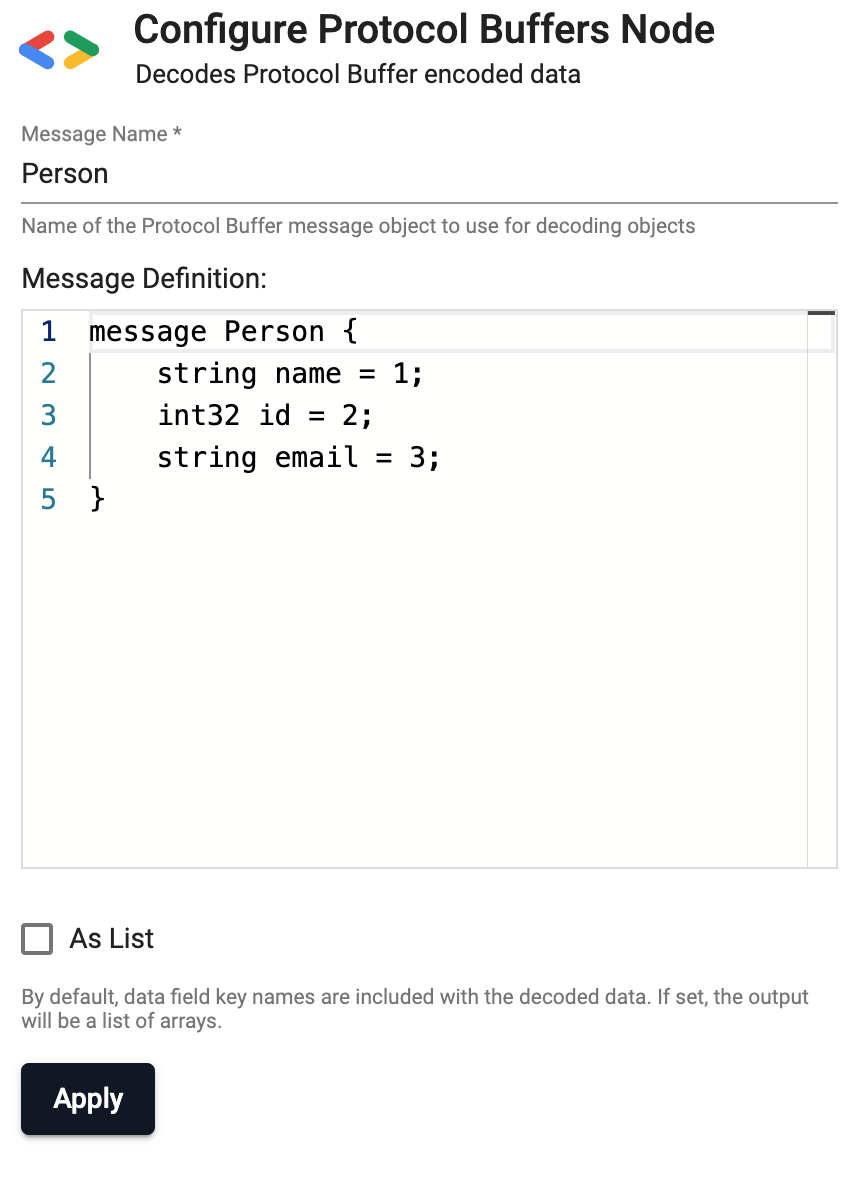
Protocol Buffers
Decodes Protocol Buffer encoded data.
See APIs for more details
q API: .qsp.decode.protobuf •
Python API: kxi.sp.decode.protobuf
Required Parameters:
| name | description | default |
|---|---|---|
| Message Name | The name of the Protocol Buffer message type to decode | |
| Message Definition | A .proto definition containing the expected schema of the data to decode. This definition must include a definition of the Message Name referenced above. |
Optional Parameters:
| name | description | default |
|---|---|---|
| As List | If checked, the decoded result is a list of arrays, corresponding only to the Protocol Buffer stream data. Otherwise, by default the decoded result is a table corresponding to both the schema and data in the stream. | No |
Definition Example:
In this example, the operator is configured to read the "Person" message and decode data with the
defined fields. Because As List is unchecked, the resulting data will be a table with the columns
name, id and email.
Code Snippet
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}