Get Data - Object Storage
The page provides a walkthrough to demonstrate how to ingest data from object storage into a database.
We have provided a weather dataset, hosted on each of the major cloud providers, for use in this walkthrough.
No kdb+ knowledge required
No prior experience with q/kdb+ is required to build this pipeline.
Before you create the pipeline to import data, ensure the insights-demo database is created, as described here.
The following sections describes how to:
- Create a pipeline. Create the weather pipeline and add it to the insights-demo package created here. This pipeline is comprised of the following nodes:
- Readers. To read data from its source. Either Google Cloud Storage, Amazon S3 or Microsoft Azure Storage.
- Decoders. To decode the ingested csv data.
- Schema. To convert the data to a type compatible with a kdb+ database.
- Writers. To write the data to a kdb Insights Enterprise database.
- Deploy the pipeline. To run the pipeline you have just created to ingest data into the insights-demo database.
- Teardown the pipeline. The pipeline can be torn down after data has been ingested. This frees up resources and is good practice.
Create the pipeline
Use the Import Wizard to create the pipeline:
-
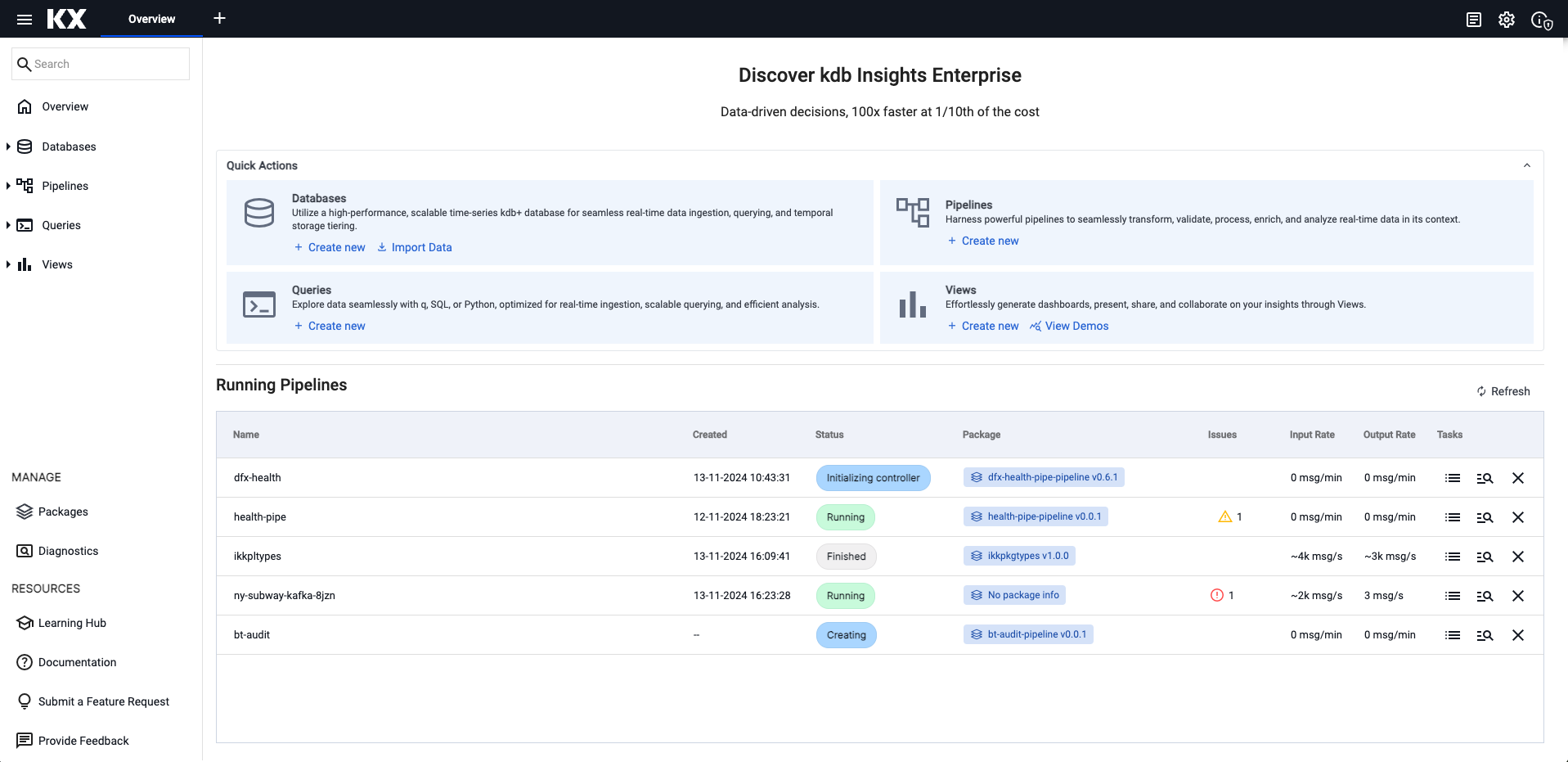
On the Overview page, choose Import Data under Databases on the Quick Actions panel.
-
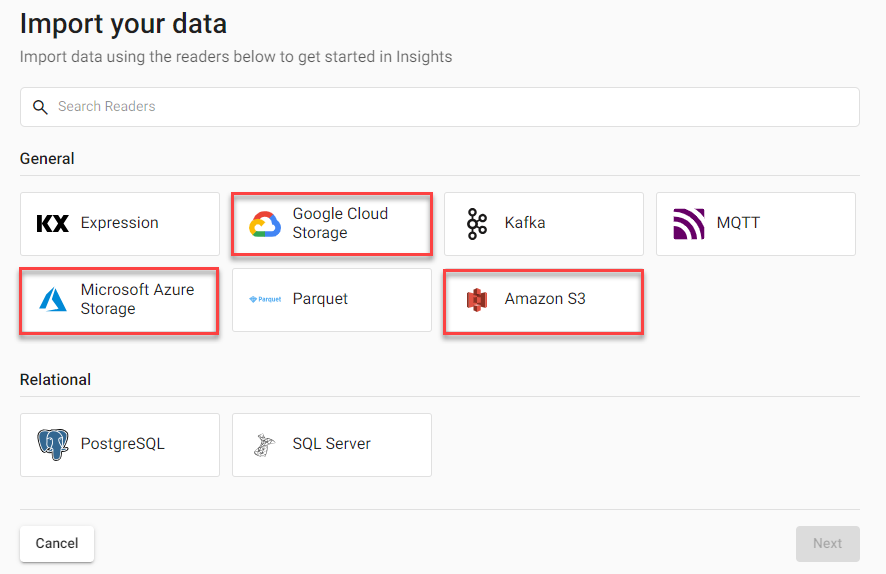
In the Import your data screen select a cloud provider; Google Cloud Storage, Microsoft Azure Storage, Amazon S3.
-
Complete the reader properties for the selected cloud provider.
Properties
Setting Value GS URI* gs://kxevg/weather/temp.csv Project ID kx-evangelism Tenant Not applicable File Mode* Binary Offset* 0 Chunking* Auto Chunk Size* 1MB Use Watching No Use Authentication No Properties
Setting Value MS URI* ms://kxevg/temp.csv Account* kxevg Tenant Not applicable File Mode* Binary Offset* 0 Chunking* Auto Chunk Size* 1MB Use Watching Unchecked Use Authentication Unchecked Properties
Setting Value S3 URI* s3://kxs-prd-cxt-twg-roinsightsdemo/weather.csv Region* eu-west-1 File Mode* Binary Tenant kxinsights Offset* 0 Chunking* Auto Chunk Size 1MB Use Watching No Use Authentication No -
Click Next to select a decoder.
-
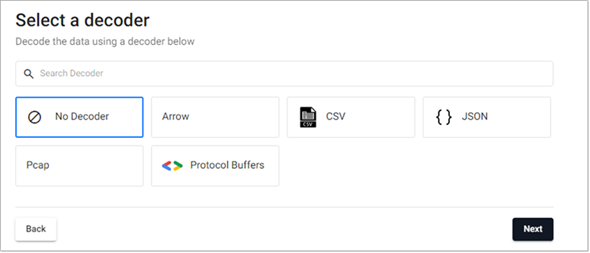
Select CSV, as shown below, as the weather data is a csv file.
-
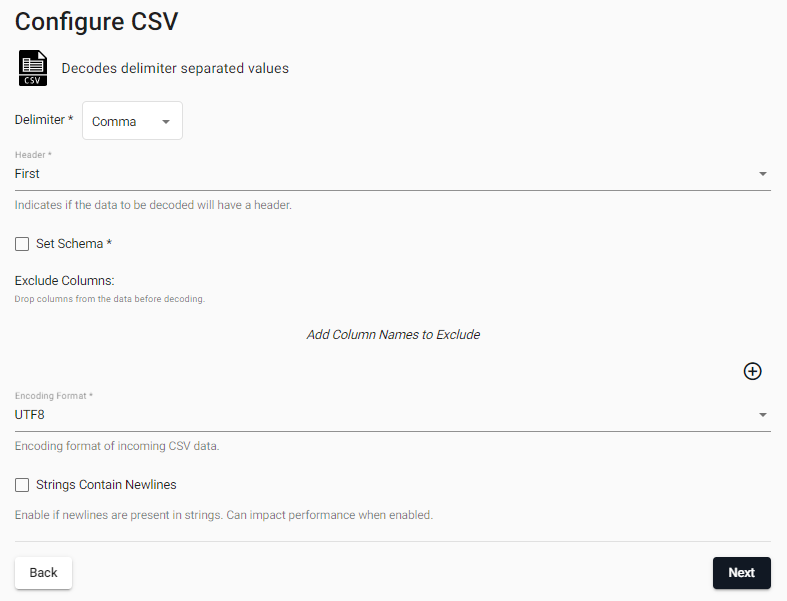
In the Configure CSV screen keep the default CSV decoder settings.
-
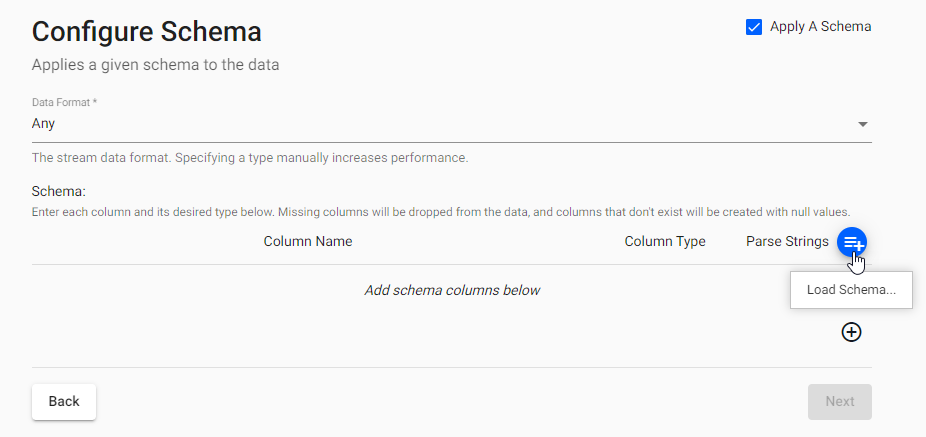
Click Next to open the Configure Schema screen.
-
In the Configure Schema screen:
Leave the following unchanged:
setting value Apply a Schema Enabled Data Format Any -
Click Load Schema
 set the following values:
set the following values: -
Select insights-demo as the Database.
- Select weather as the Table.

-
-
Click Load.
-
Click Next to open the Configure Writer screen.
-
Configure the writer settings as follows:
setting value Database insights-demo Table weather Leave the remaining settings unchanged.
-
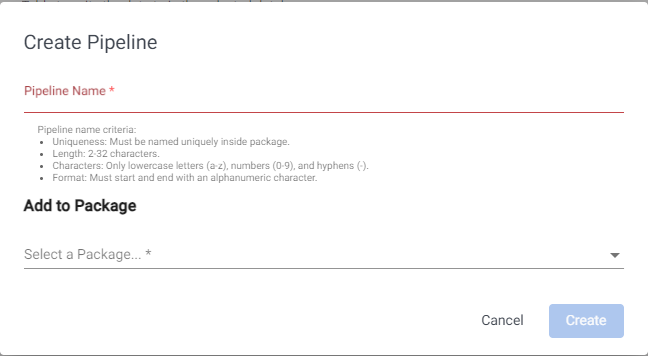
Click Open Pipeline to display the Create Pipeline dialog.
- Enter weather-1 as the Pipeline Name
- Click Select a Package and select insights-demo.
- Click Create.
If
insights-demois not available for selection, open the Packages Index and select Teardown from the actions menu besideinsights-demo. Ifinsights-demodoes not appear on packages list create it, as described here. -
You can review the Pipeline as shown below. Note that the first node in the pipeline differs depending on the selected reader type.
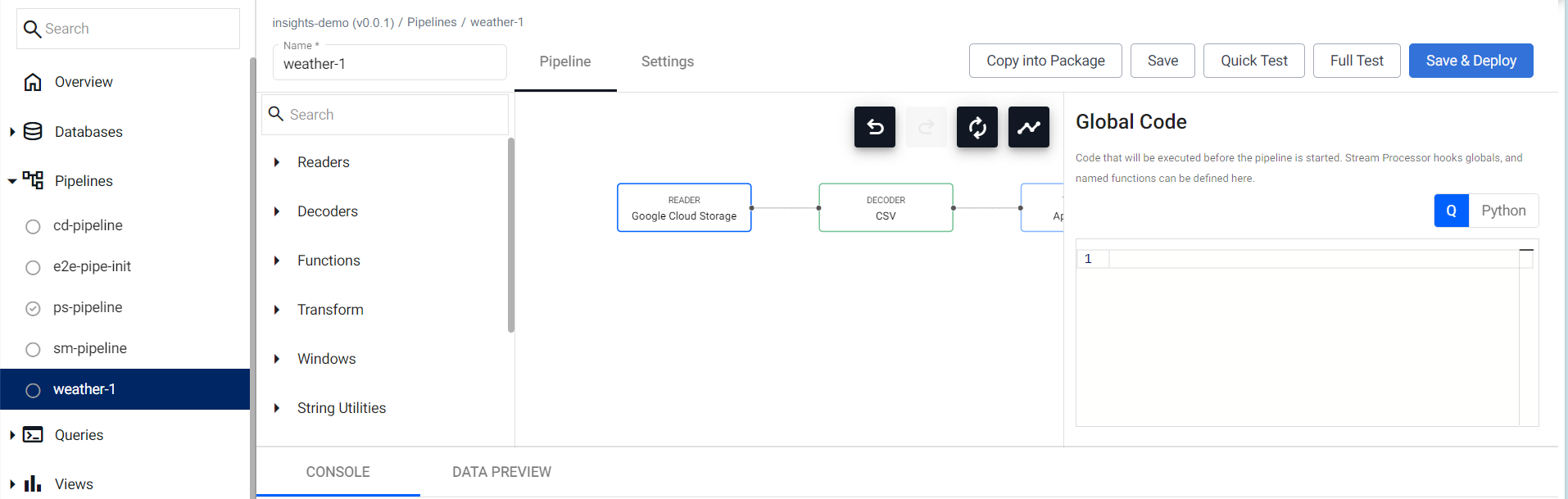
-
Click Save.
At this stage you are ready to ingest the data.
Deploy the pipeline
Deploy the package containing the database and pipeline in order to ingest the data into the database.
- Go to the Package Index page and click on the three dots beside insights-demo package and click Deploy.
Note
It may take Kubernetes several minutes to spin up the necessary resources to deploy the pipeline.
If the package or its database are already deployed you must tear it down. Do this on the Package Index page by clicking on the three dots beside insights-demo package and click Teardown.
-
You can check the progress of the pipeline under the Running Pipelines panel of the Overview tab. The data is ready to query when Status = Finished.

Pipeline warnings
Once the pipeline is running some warnings may be displayed in the Running Pipelines panel of the Overview tab, these are expected and can be ignored.
Pipeline teardown
Once the CSV file has been ingested, the weather pipeline can be torn down. Ingesting this data is a batch ingest operation, rather than an ongoing stream, so it is ok to teardown the pipeline once the data is ingested. Tearing down a pipeline returns resources, so is a good practice when it is no longer needed.
-
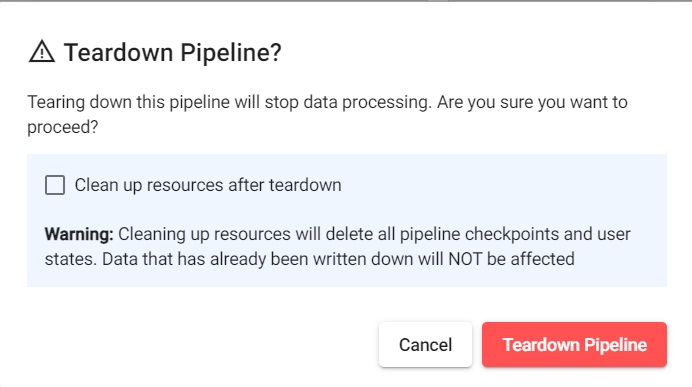
Click X in Running Pipelines on the Overview tab to teardown a pipeline.
-
Check Clean up resources after teardown as these are no longer required now that the CSV file has been ingested.
-
Click Teardown Pipeline.
Troubleshoot pipelines
If any errors are reported they can be checked against the logs of the deployment process. Click View diagnostics in the Running Pipelines section of the Overview tab to review the status of a deployment.

Next steps
Now that data has been ingested into the weather table you can:
Further reading
Use the following links to learn more about specific topics mentioned in this page: