kdb+ Database Initial Import Overview
This page explains how to import an existing kdb+ database into kdb Insights Enterprise.
kdb Insights Enterprise allows you to work with existing kdb+ databases. To do this, the Storage Manager (SM) needs to adjust the database to its own format. Once adjusted, this guarantees atomicity during write-down; and at the same time ensures that a database is mountable by a kdb+ process at any point in time. To achieve this, SM uses symbolic links to represent a standard kdb+ segmented database, while keeping the backing data in a proprietary structure.
Three scenarios are supported:
- Partitioned database on disk
- Partitions only in object storage
- Partitions on disk and partitions in object storage (the same date partition can't exist in both)
Splayed and basic tables are also supported. These can only exist on local storage.
Data in object storage is excluded from this transformation, and kept in standard kdb+ format.
Import Phases
The initial import has two phases:
- Copy kdb+ to target the data
- Configure and deploy the database
Copy kdb+ data to target
First, you must copy the kdb+ database to the target filesystem. In many cases this is a PVC on a Kubernetes cluster. The example below shows how the data is easily migrated with the aid of the PVC and POD creation yaml.
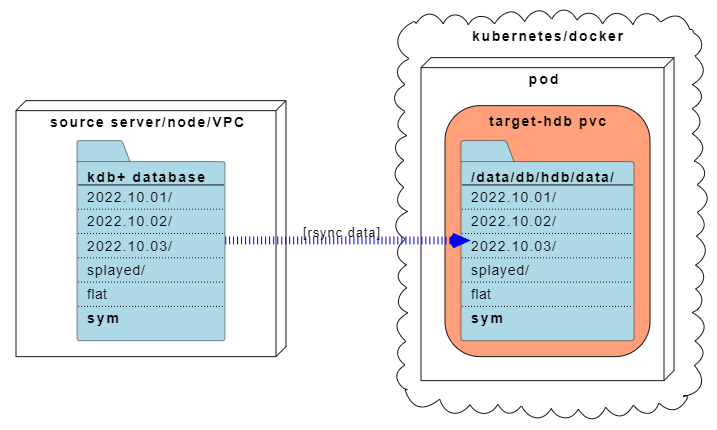
Configure and deploy kdb+ Insights database
After the data has been copied to the target filesystem, the next step is to configure a database, assume ownership of that PVC and allow kdb Insights to start managing it.
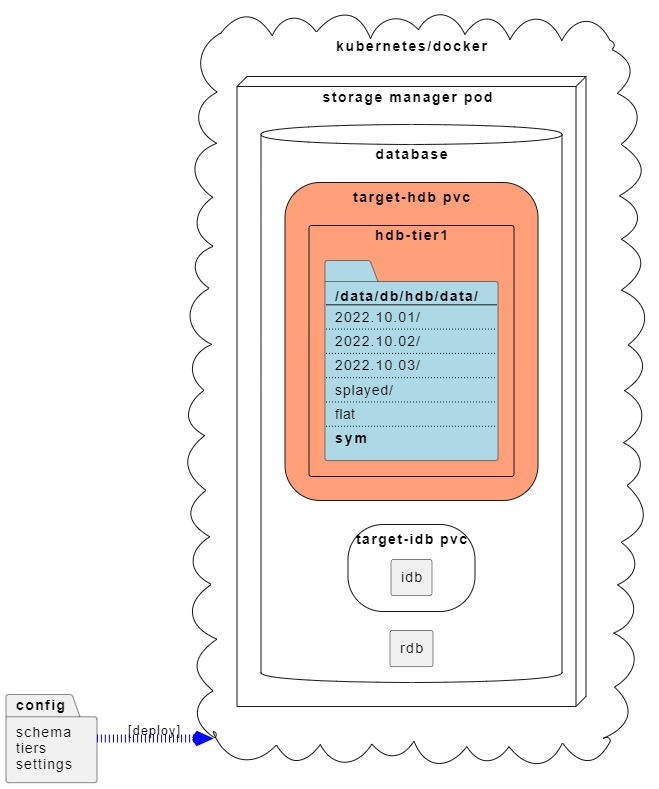
After deploying the database, the data is now available for query.
Next steps
- To quickly try out this method, follow our quick start.
- Alternatively, follow the initial import process.