Use Code in a Package
This page provides an overview of how to use code in a kdb Insights Enterprise package.
Once a package containing User Defined Analytics (UDAs) and User Defined Functions (UDFs) has been uploaded to kdb Insights Enterprise, there are three components that can utilize them:
- Scratchpads. Use a Query Window to call code defined in a package.
- Stream Processor. Use the pipeline editor to call UDFs and UDAs.
- Querying. Use the Query Window, Views or REST to call UDAs.
The Web Interface does not currently support the creation or modification of UDAs and UDFs in a package, these need to be managed using the CLI.
Scratchpads
As discussed within the analyzing your data section of the documentation, packages and UDFs can be used within the scratchpad panel of the Query window.
The following examples show you how you can interact with a package test_pkg generated using the Python or q APIs:
import kxi.packages as pakx
import pykx as kx
# List available packages
pakx.packages.list()
# List available UDFs
pakx.udfs.list()
# Load a package and test available variable has been loaded
pakx.packages.load('test_pkg', '1.0.0')
kx.q('.test.variable')
# Retrieve a defined UDF and output it's definition
udf = pakx.udfs.load("custom_map", "test_pkg")
udf
# Generate some test data to use the udf
test_data = kx.q('([]100?1f;100?1f)')
udf(test_data, {'column': 'x1', 'threshold': 0.5})
// List available packages
.kxi.packages.list.all[]
// List available UDFs
.kxi.udfs.list.all[]
// Load a package and test available variable has been loaded
.kxi.packages.load["test_pkg";"1.0.0"]
.test.variable
// Retrieve a defined UDF and output it's definition
udf:.kxi.udfs.load["custom_map";"test_pkg"]
udf
// Generate some test data to use the udf
testData:([]100?1f;100?1f)
udf[testData;`column`threshold!(`x1;0.5)]
Stream Processor
Within the Stream Processor, you can utilize your UDFs in the Function node definitions using Python or q.
For more information on retrieval and wrapping of these functions for use with the Stream Processor, refer to UDFs. In both cases, the Stream Processor pipeline being deployed is as follows:
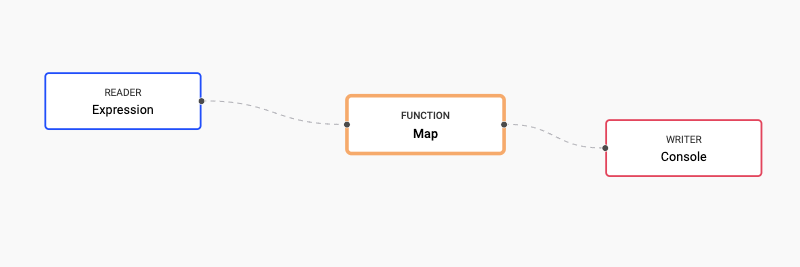
The following steps illustrate how to use the UDF custom_map stored a test_pkg package.
-
Define an Expression node as follows:
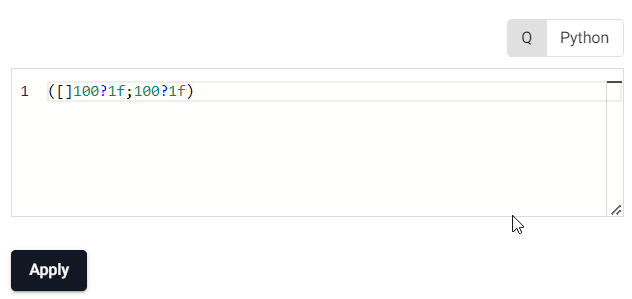
([]100?1f;100?1f) -
Define a Map node to call the
custom_mapstored atest_pkgpackage as follows: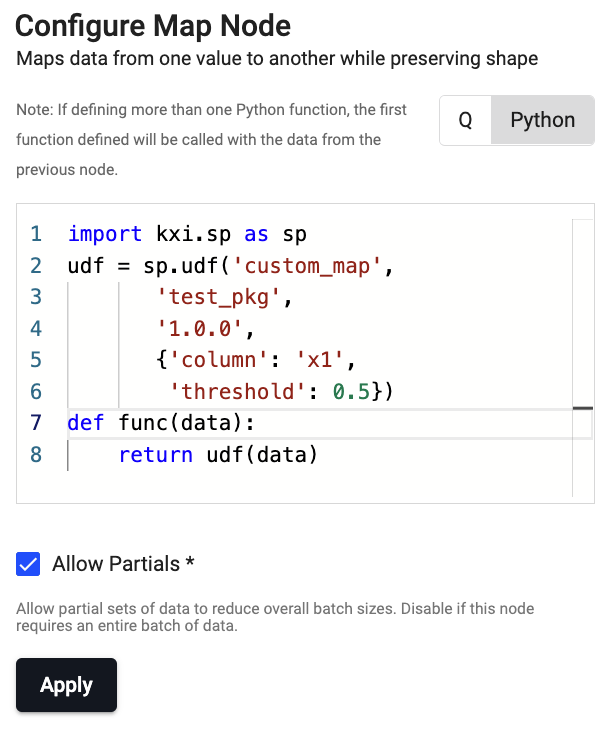
SP Python Node Code
import kxi.sp as sp udf = sp.udf('custom_map', 'test_pkg', '1.0.0', {'column': 'x1', 'threshold': 0.5}) def func(data): return udf(data)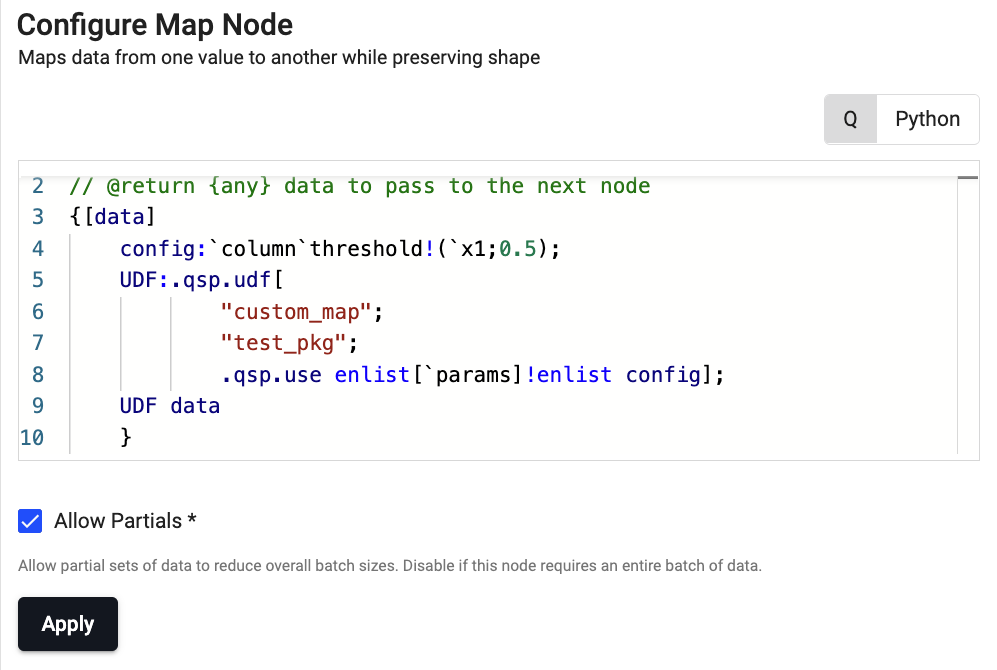
SP q Node Code
{[data] config:`column`threshold!(`x1;0.5); UDF: .qsp.udf[ "custom_map"; "test_pkg"; .qsp.use enlist[`params]!enlist config]; UDF data } -
Define a Console node to display the results.
-
Connect the nodes together.
Deploy the package
Make sure to deploy the package containing the code to be able to use the UDF.
Query
User Defined Analytics (UDAs) can be loaded by the Data Access Processes and Aggregator to allow users to call the UDAs from the Query Window, Views or from outside kdb Insights Enterprise.
Adding a UDA to enable custom RESTful queries of your package database involves the steps below:
-
Adding the
database(and optionallyagg&rc) component(s) to the package -
Adding the UDA entrypoint file(s) to the package with the appropriate name (
data-access,aggregator,resource-coordinator) -
Registering the function in the entrypoint file as a UDA
-
Pushing & deploying the package to kdb Insights Enterprise
For more information, refer to the instructions on how to create UDAs.
Once added and registered, it is possible to call the new UDAs using RESTful calls. See UDA REST example for further information.
For more information on the definition of custom UDAs and the addition of custom code to the various database components, refer to UDA overview.
Using the global Aggregator
Deploying UDAs to aggregator and resource coordinator without including them in the package is not recommended, but is possible if you can't add an agg and rc to the package.
If you are using the global Aggregator included in the kdb Insights Enterprise base installation, rather than a dedicated Aggregator defined in the package, you must also load the aggregation function into the global Aggregator.