Manage Functions within a Package
This page provides details on managing User-Defined Functions (UDFs) and User-Defined Analytics (UDAs) within a package in kdb Insights Enterprise.
Package functions can be used within kdb Insights Enterprise to:
-
Transform data within the stream processor using the function node.
-
Query data by using the package functions within the query scratchpad panel of the web interface or within the command line interface (CLI).
-
Enable custom RESTful queries of your package database.
How are UDFs and UDAs different?
User-Defined Functions (UDFs) and User-Defined Analytics (UDAs) serve distinct purposes within the kdb Insights system. While both UDFs and UDAs are functions, UDFs are typically loaded into the Stream Processor (SP) and do not read from the database, whereas UDAs are loaded into the Data Access Process (DAP) and interact with the database.
UDFs overview
User-Defined Functions (UDFs) are functions written in Python or q which are defined as named functions for use in a Stream Processor pipeline or the Scratchpad.
Motivation for UDFs
UDFs are useful for creating a set of parameterized functions that can be used during realtime streaming applications. When a UDF is created and pushed to the system, it can be loaded and run in a pipeline in order to perform some operation on the data while is is being streamed.
Define a UDF
The kdb Insights UDF API supports definitions in both Python and q. They are defined in packages using comments in q and decorators in Python. These constructs provide an association between the configuration of a UDF and the function linked with the UDF.
Create a file that contains the UDF definition
from kxi.packages.decorators import udf
@udf.*
// @udf.*
The example below shows how to create a UDF both in Python and q.
Creating a UDF
The code below provides an example of UDF that multiples a column value by a random number between 0 and 1:
import numpy as np
from kxi.packages.decorators import udf
@udf.name('custom_py_map')
@udf.description('Custom Python UDF making use of numpy')
@udf.tag('sp')
@udf.category('map')
def py_udf(table, params):
# Multiply the content of the column to be modified by random values between 0 and 1
n = len(table)
table[params['column']] = table[params['column']] * np.random.random(n)
return(table)
The code below provides an example of UDF that filters some column in table based on some threshold value:
// @udf.name("custom_map")
// @udf.description("Custom map function providing filtering against incoming data for a specified column and maximum threshold.")
// @udf.tag("sp")
// @udf.category("map")
.test.my_custom_udf:{[table;params]
select from table where params[`column]>params`threshold
}
The definition of the @udf.* decorators are as follows:
| value | description | required | default |
|---|---|---|---|
name |
The name by which the underlying UDF is known when referenced by kdb Insights Enterprise. | yes |
N/A |
description |
A user supplied description allowing you to discern the motivation for the UDF. | no |
"" |
tag |
User specified tag to provide a domain context that this UDF was designed for. For example fx, crypto, iot. It is purely descriptive, in order to help group UDFs. | no |
"" |
category |
A user specified category/list of categories which can be used to define where the UDF is to be deployed. For example @udf.category(["map", "filter"]) to define usage within a map and filter node of a Pipeline. |
no |
"" |
A minimal UDF requires only @udf.name("some-name") above the function declaration.
// @udf.name("minimal")
mini:{[table;params] table[`x] + 1}
from kxi.packages.decorators import udf
@udf.name('minimal')
def mini(table, params):
return table["x"] + 1
There is currently no manual way to update a package to reference a UDF.
That means you can't use the kxi package add udf command. The command below searches all files for @udf definitions and writes them to a udfs file.
kxi package refresh//push/packit
UDF constraints
The definition of your UDFs comes with the following constraints:
- UDFs only load the file within which they are defined.
- Ensure that all logic required to execute the UDF is self contained within the module.
- UDFs must take two or more parameters up to a maximum of eight.
- If using a different
udfnamespace, likeudfSuite1.name("some-udf")- Add
udfSuite1to the package manifest underudf_namespaces# manifest.yaml udf_namespaces: - udfSuite1
- Add
- If written in
q, the function must be defined:- Beneath the relevant
udf.*comment block. - With its full namespace definition (for example,
.myns.funcand not\d .myns). Refer to the note below.
- Beneath the relevant
Defining UDFs in q namespaces. See the examples below for details on how to write the UDFs in q so they work as intended.
\d .test
pi:3.14
square:{x wsum x}
// @udf.name("test")
// @udf.description("This is correct as UDF is resolved in correct namespace")
.test.user_defined_function:{[data;params]pi*square data}
\d .test
pi:3.14
square:{x wsum x}
// @udf.name("test")
// @udf.description("This is incorrect as UDF will not resolve .test namespace")
user_defined_func:{[data;params]pi*square data}
Loading files within packages
During development you may need to load code from other modules in packages.
Loading a module should not be done using \l in q. Instead, loading modules in your packages should be done using one of the below functions.
| Python | q |
|---|---|
kxi.packages.load |
.kxi.packages.load |
kxi.packages.packages.load_file |
.kxi.packages.file.load |
These functions load files relative to the root of the package being loaded or the package within which a UDF is being loaded.
Examples of their usage within package files are as follows:
from kxi.packages import packages
# Load the file src/example.py
packages.load_file("src/example.py")
// Load the file src/example.q
.kxi.packages.file.load["src/example.q"]
Locked files (q Only)
To facilitate the use of locked files, by default the loading functionality attempts to load the locked version of all files first, followed by the loading of unlocked files.
UDF example
Before doing the below walkthrough
It's expected that a you already have a package mypackage on your local system containing a database, pipeline, table etc.
This section describes how to add a UDF to the package that only returns the values where the columns x is less than 10.
We assume PKG=mypackage in the below steps
Update the local package
The below example shows how to add a simple UDF to a package.
Adding a simple UDF to a package
-
Create a file
src/myudf.qwithin themypackagedirectory that will contain the UDF.This file contains a UDF.
mkdir -p src/ cat << EOF > src/myudf.q // @udf.name("sp_map") // @udf.tag("sp") // @udf.category("map") .test.sp.map:{[table;params] select from table where x1<10 } EOFThe
@udf.categorydecorator ensures that this UDF is available for use within a "Map" node in the Pipeline Editor. -
Modify the
init.qfile which is your default entrypoint in order to ensure that your new file gets loaded by default.cat << EOF > init.q // Load the src/myudf.q file relative to package root .kxi.packages.file.load["src/myudf.q"] EOF
Push the changes
To update the package created in the previous section in kdb Insights Enterprise push and deploy the package:
kxi pm push $PKG --force --deploy
push vs deploy
pushmakes the UDF available to be loaded by any process running on kdb Insights Enterprisedeployrestarts the components defined in the package to ensure they reload the changes"
Invoking a UDF
Within kdb Insights Enterprise, UDFs can be used in the following contexts:
-
An interactive Scratchpad/Query Session, using:
-
- As an input to any Function node that supports code.
- This allows persisted custom logic to be stored as part of a pipeline.
In a query session
To use your UDF in a kdb Insights Enterprise Query session, open the Query tab and fill in the form with the following parameters:
| Parameter | Description |
|---|---|
| Table Name | The name of the table. For example, mytab. |
| Start Date | The format for the start date is YYYY-MM-DD. For example, 2024-03-13. |
| End Date | The format for the end date is YYYY-MM-DD. For example, 2024-03-16. |
| Output Variable | Insert the output variable here. For example, mytab. |
Then click the Run Query button.
Once this is done, you can leverage your code in the UI in the following ways:
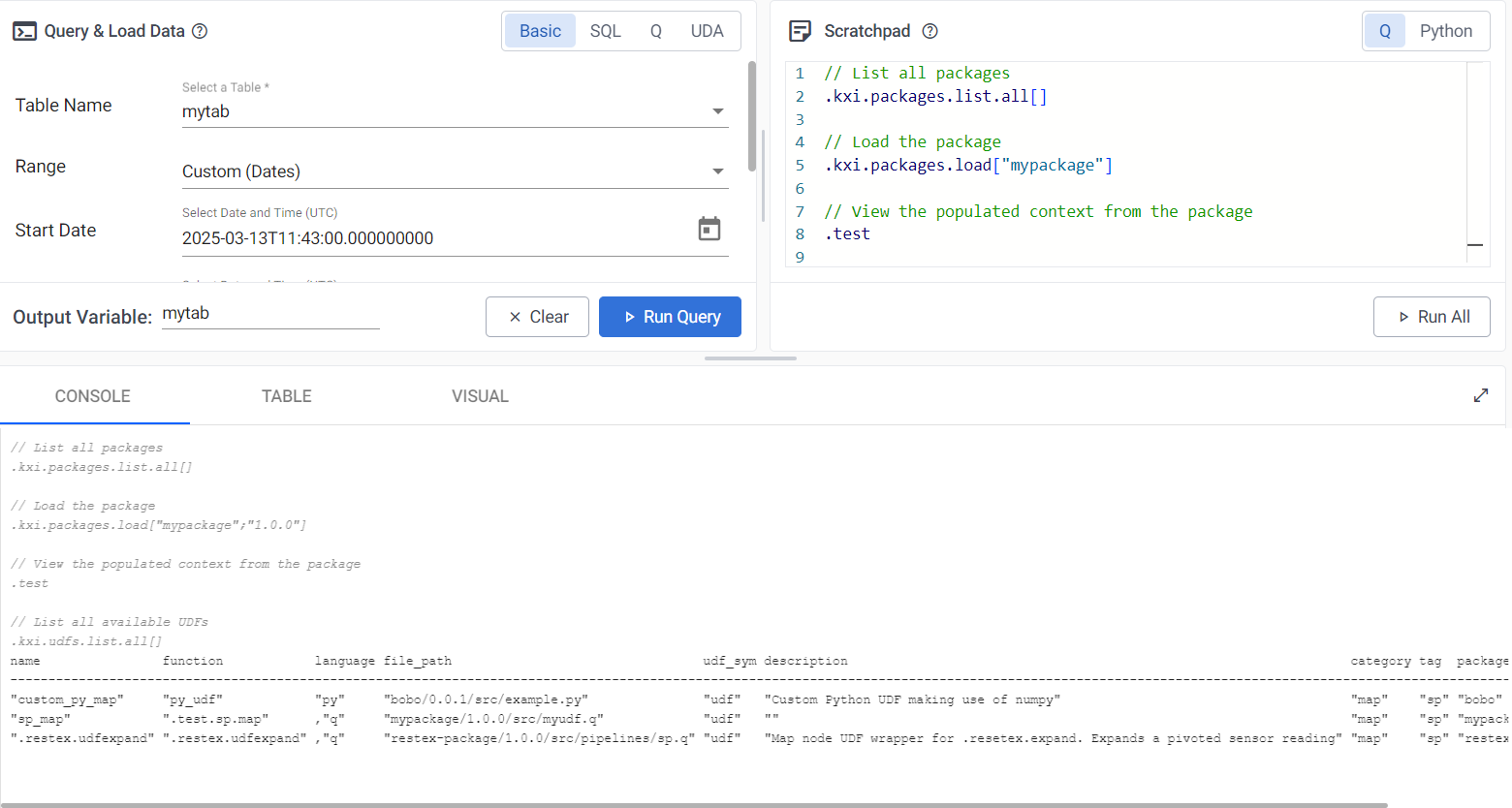
List and load package contents within a Query session.
```bash // List all packages .kxi.packages.list.all[]
// Load the package .kxi.packages.load["mypackage"]
// Verify the UDF is defined in your scratchpad .test
// List all available UDFs
.kxi.udfs.list.all[]
```
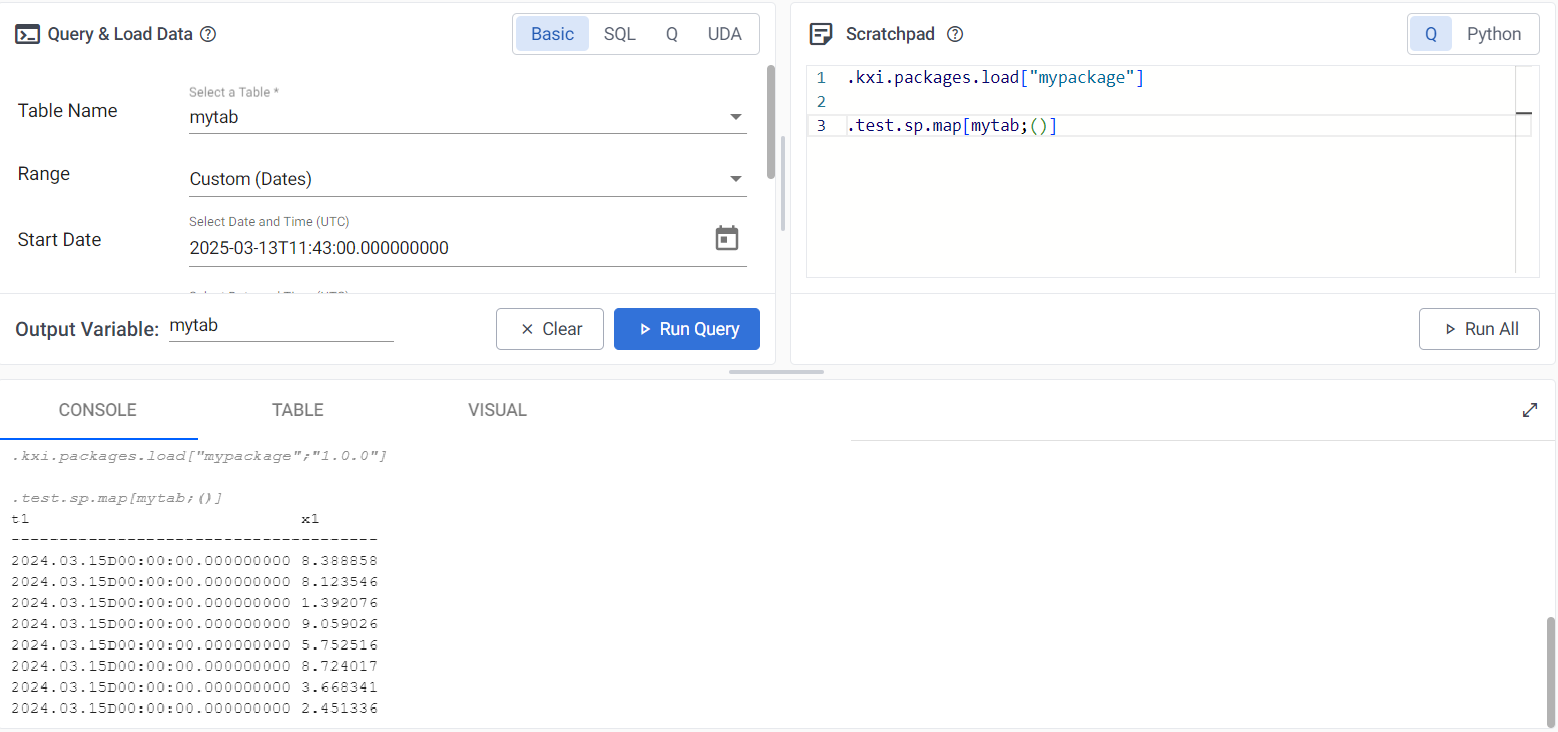
Using the UDF within a scratchpad.
.kxi.packages.load["mypackage"]
.test.sp.map[mytab;()]
In a pipeline
Use the UDF in a Function node within a Pipeline Editor.
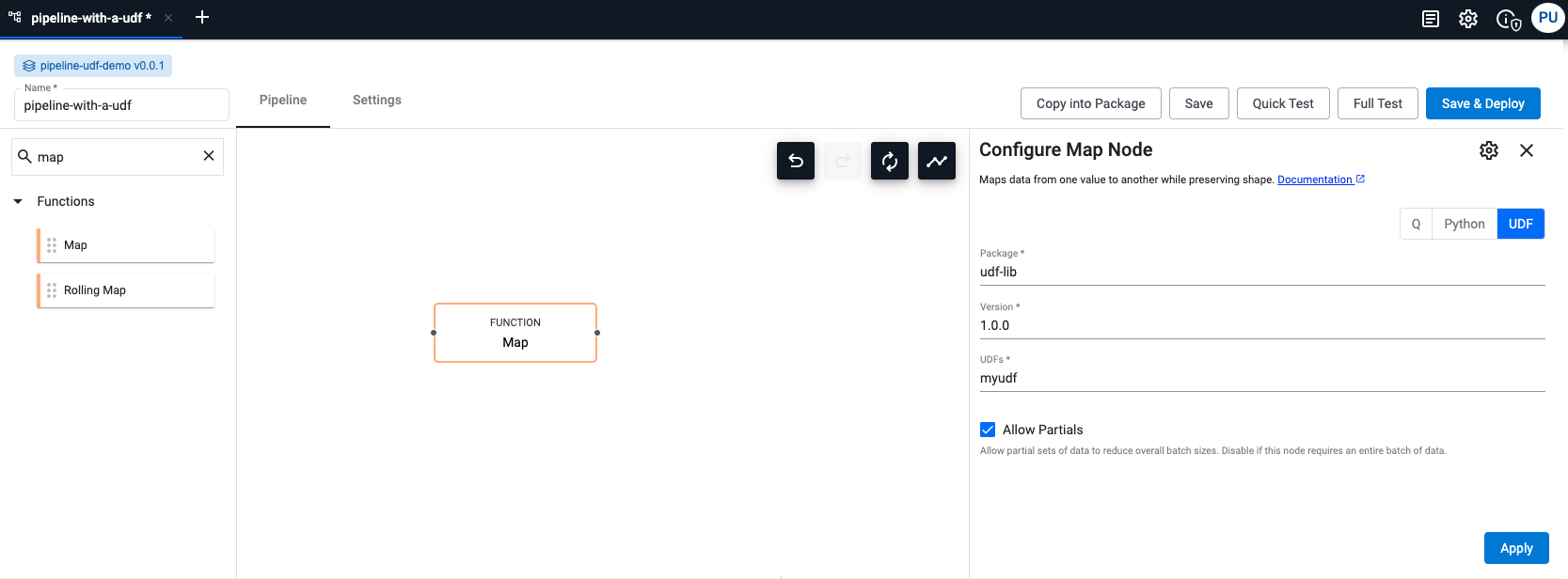
To retrieve the UDFs, you can use the APIs:
Create, define, and register a UDA
User Defined Analytics (UDAs) are custom analytics functions you can create to perform specific data analysis tasks for reading data from the database.
User Defined Analytics (UDAs) enable you to define new APIs that are callable through the Service Gateway (SG). UDAs augment the standard set of APIs available in the kdb Insights system with application logic specific to your business needs.
For more information on UDAs, follow the links below:
Next steps
- Learn how to manage dependent and patch components in kbd Insights Enterprise.