Writers
Write data to external or internal data source using the Stream Processor
Writers are a specialized type of operator that allow users to push data from a streaming pipeline to different external data sources.
See APIs for more details
A q interface can be used to build pipelines programatically. See the q API for API details.
A Python interface is included along side the q interface and can be used if PyKX is enabled. See the Python API for API details.
The pipeline builder uses a drag-and-drop interface to link together operations within a pipeline. For details on how to wire together a transformation, see the building a pipeline guide.
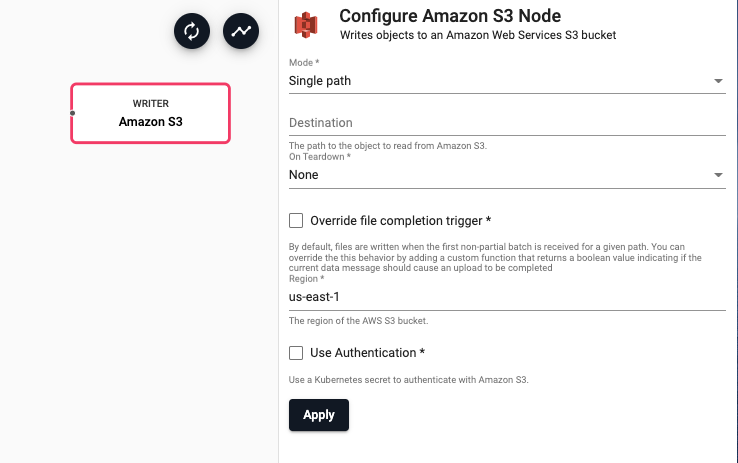
Amazon S3
Writes data to an object in an Amazon S3 bucket
See APIs for more details
q API: .qsp.write.toAmazonS3 •
Python API: kxi.sp.write.to_amazon_s3
Required Parameters:
| name | description | default |
|---|---|---|
| Mode | Indicates if this writer should write to a single file path or if it should use a function to derive a function path from the data in the stream | Single path |
| Destination | If 'Single path' is selected, the destination is the path of the object to write to in Amazon S3. If 'Dynamic path' is selected, destination is a function that accepts the current batch of data and returns a string of the object path in S3 to save data to | |
| On Teardown | Indicates the desired behavior for any pending data when the pipeline is torn down. The pipeline can perform no action ('None') and continue to buffer data until the pipeline starts again. This is recommended for most use cases. Alternatively, the pipeline can be set to 'Abort' any partial uploads. Or the pipeline can be set to 'Complete' any partial uploads. | None |
Optional Parameters:
| name | description | default |
|---|---|---|
| Override file completion trigger | When selected, an 'Is Complete' function is required to be provided. This allows the completion behavior for partial data to be customized | No |
| Is Complete | A function that accepts metadata and data and returns a boolean indicating if after processing this batch of data that all partial data should be completed. |
|
| Region | The AWS region of the bucket to authenticate against | us-east-1 |
| Use Authentication | Enable Kubernetes secret authentication. | No |
| Kubernetes Secret* | The name of a Kubernetes secret to authenticate with Azure Cloud Storage. |
* If Use Authentication is enabled.
Amazon S3 Authentication
To access private buckets or files, a Kubernetes secret needs to be created that contains valid AWS credentials. This secret needs to be created in the same namespace as the kdb Insights Enterprise install. The name of that secret is then used in the Kubernetes Secret field when configuring the reader.
To create a Kubernetes secret containing AWS credentials:
kubectl create secret generic --from-file=credentials=<path/to/.aws/credentials> <secret-name>
Where <path/to/.aws/credentials> is the path to an AWS credentials file, and <secret-name> is the name of the Kubernetes secret to create.
Note that this only needs to be done once, and each subsequent usage of the Amazon S3 reader can re-use the same Kubernetes secret.
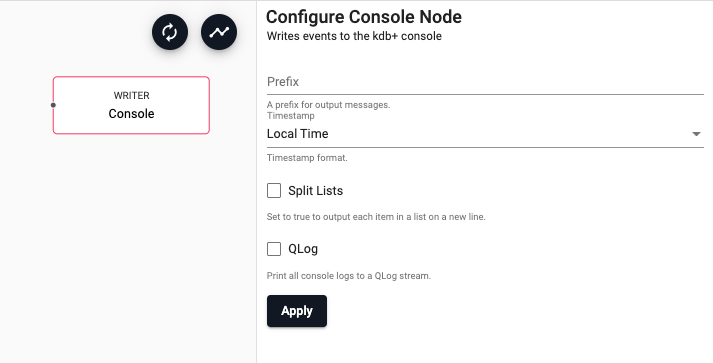
Console
Writes to the console
See APIs for more details
q API: .qsp.write.toConsole •
Python API: kxi.sp.write.to_console
Optional Parameters:
| name | description | default |
|---|---|---|
| Prefix | A customized message prefix for data sent to the console | "" |
| Timestamp | Indicates what timezone should be used for timestamps, either 'Local Time', 'UTC' or 'No timestamp' | 'Local Time' |
| Split Lists | Indicates if each element of a list should be on its own line or if it can all be on a single line | No |
| QLog | Logs written by the console output are in raw text format. Check this option to wrap all output in QLog format | No |
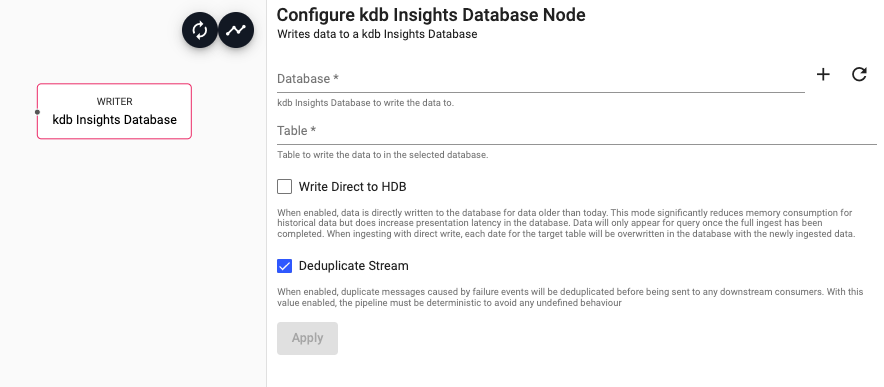
kdb Insights Database
Write data to a kdb Insights Database
See APIs for more details
q API: .qsp.write.toDatabase •
Python API: kxi.sp.write.to_database
Required Parameters:
| name | description | default |
|---|---|---|
| Database | The name of the database to write data to | |
| Table | The name of the table to insert data into |
Optional Parameters:
| name | description | default |
|---|---|---|
| Write Direct to HDB | When enabled, data is directly written to the database for data older than the purview of the HDB. For large historical ingests, this option will have significant memory savings. Note that when this is selected, data will not be available for query until the entire pipeline completes. | No |
| Deduplicate Stream | For deterministic streams, this option ensures that data that is duplicated during a failure event only arrives in the database once. Only uncheck this if your model can tolerate data that is duplicated but may not be exactly equivalent. | Yes |
Direct write overwrites partitions
When ingesting with direct write, each date for the target table will be overwritten in the database with the newly ingested data.
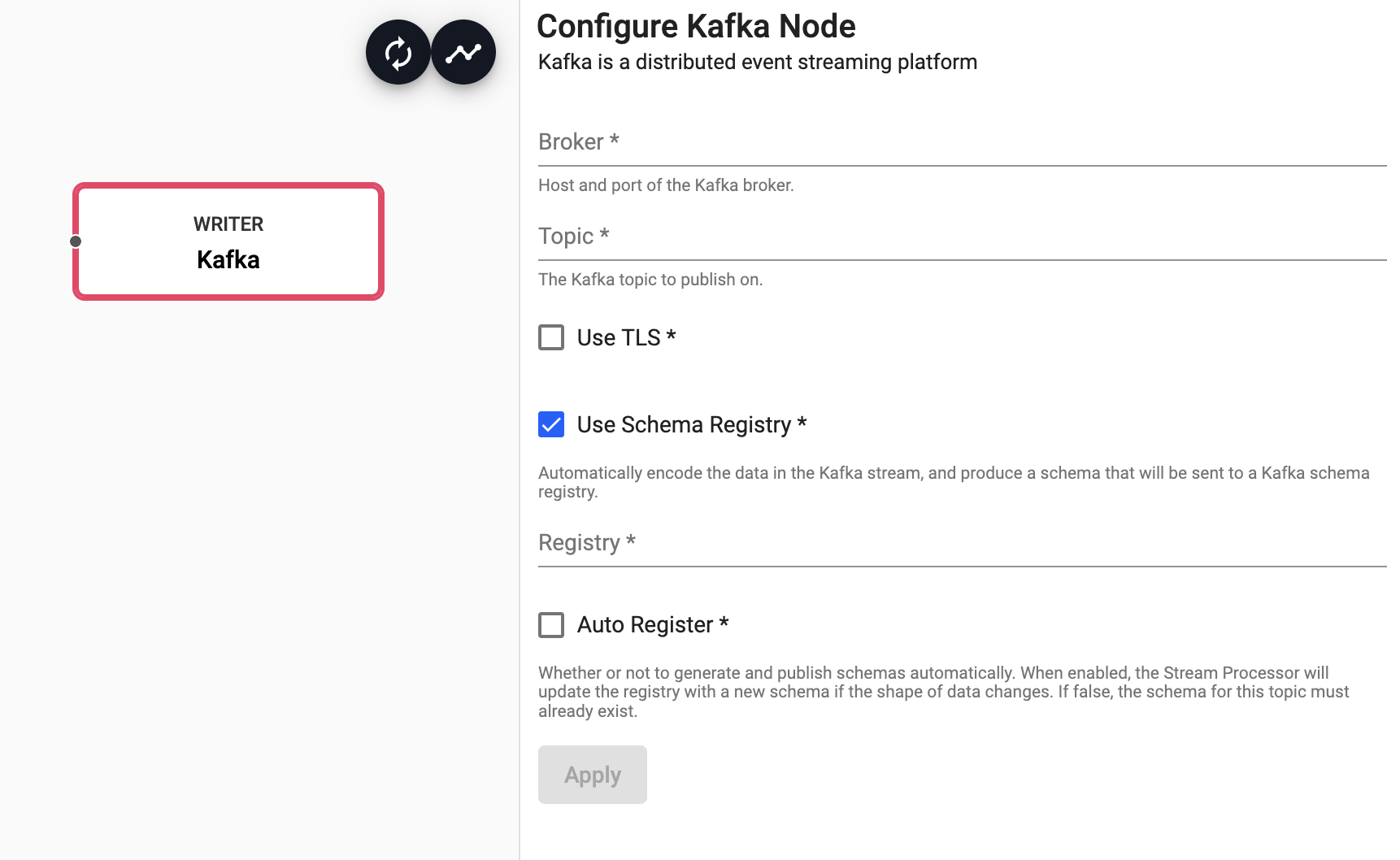
Kafka
Publish data on a Kafka topic
See APIs for more details
q API: .qsp.write.toKafka •
Python API: kxi.sp.write.to_kafka
Required Parameters:
| name | description | default |
|---|---|---|
| Broker | Location of the Kafka broker as host:port. If multiple brokers are available, they can be entered as a comma separated list | |
| Topic | The name of the Kafka topic to subscribe to. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Use TLS | Enable TLS for encrypting the Kafka connection. When selected, certificate details must be provided with a Kubernetes TLS Secret | No |
| Kubernetes Secret* | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. | |
| Certificate Password* | TLS certificate password, if required. | |
| Use Schema Registry | Automatically encode the data in the Kafka stream, and produce a schema that will be sent to a Kafka schema registry. | No |
| Registry** | Kafka Schema Registry URL | |
| Auto Register** | Whether or not to generate and publish schemas automatically. When enabled, the Stream Processor will update the registry with a new schema if the shape of data changes. If false, the schema for this topic must already exist. | No |
* If TLS enabled.
** If Schema Registry enabled.
See this guide for more details on setting up TLS Secrets
kdb
(Beta Feature) Encodes kdb Arrow data
Beta Features
Beta feature are included for early feedback and for specific use cases. They are intended to work but have not been marked ready for production use. To learn more and enable beta features, see enabling beta features.
See APIs for more details
q API: .qsp.write.toKDB •
Python API: kxi.sp.write.to_kdb
Required Parameters:
| name | description | default |
|---|---|---|
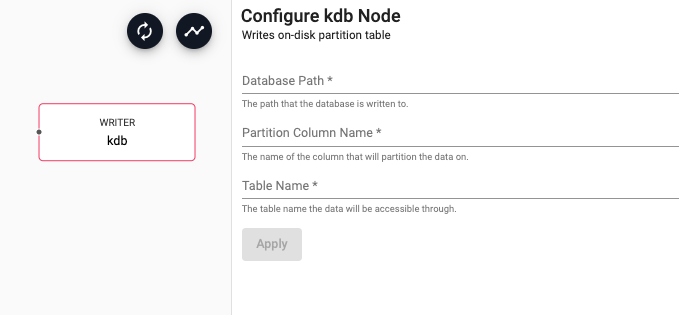
| Database Path | The path on disk to write the database to | |
| Partition Column Name | The column name within the data to use as the partition column of the database. The partition column must have a type of date, int or month |
|
| Table Name | The name of the table to write data to within the database |
Process
Write data to a kdb+ process
See APIs for more details
q API: .qsp.write.toProcess •
Python API: kxi.sp.write.to_process
Required Parameters:
| name | description | default |
|---|---|---|
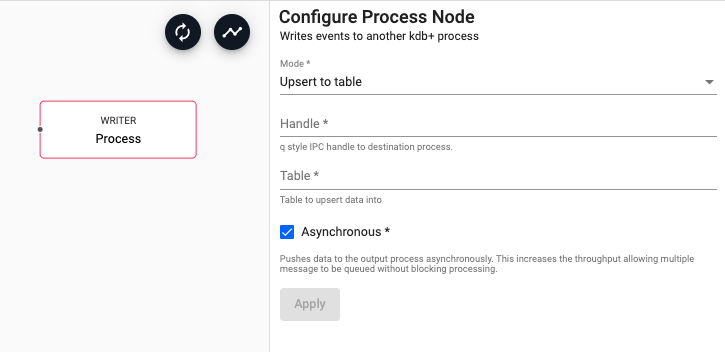
| Mode | Chose for data to either be added to a table in the remote process or to call a function. | Upsert to function |
| Handle | An IPC handle to a destination process (ex. tcps://10.0.1.128:8080). |
Optional Parameters:
| name | description | default |
|---|---|---|
| Table | When using 'Upsert to function' mode, this is the table name to write data to in the remote process. | |
| Function | When using 'Call function' mode, this is the name of the function to invoke in the remote process. | |
| Parameter | When using 'Call function' mode, these are additional arguments to pass to the remote function call. The last parameter is always implicitly the data to be sent. | |
| Asynchronous | Indicates if data should be sent to the remote process asynchronously. If unchecked, the pipeline will wait for the remote process to receive each batch of data before sending the next. Disabling this will add significant processing overhead but provide greater reliability. | Yes |
kdb Insights Stream
Write data using a kdb Insights Reliable Transport stream
See APIs for more details
q API: .qsp.write.toStream •
Python API: kxi.sp.write.to_stream
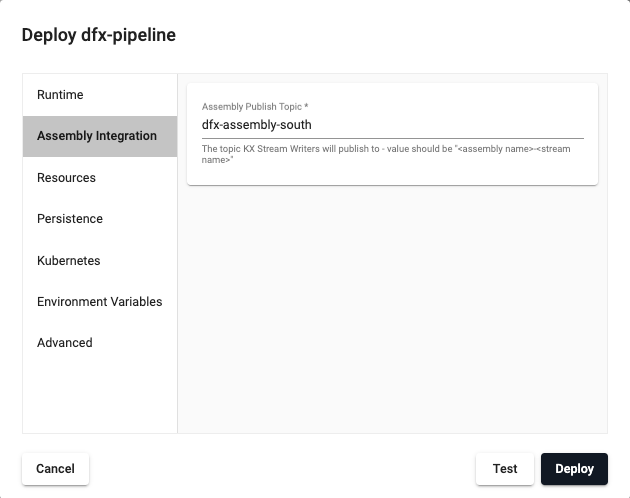
Insights streams
Optional Parameters:
| name | description | default |
|---|---|---|
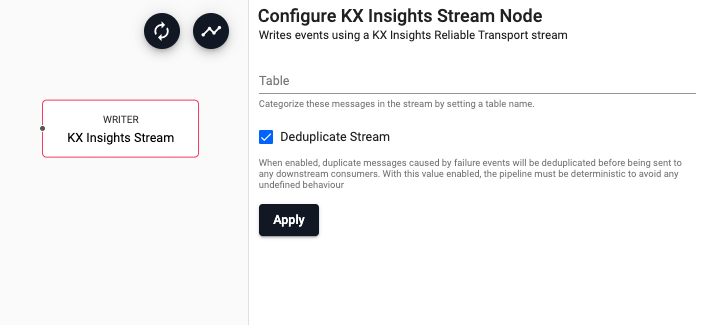
| Table | Wraps outbound data with the given table name as part of the message. Without this field, data is sent using the key name as the table name. Leave this blank for pipelines that both read and write from a stream. | |
| Deduplicate Stream | For deterministic streams, this option ensures that data that is duplicated during a failure event only arrives in the database once. Only uncheck this if your model can tolerate data that is duplicated but may not be exactly equivalent. | Yes |
To write data to a stream, an assembly must be provided. This is done at pipeline deploy time. When you click the Deploy button and select the Assembly Integration tab. On this page, you need to set the assembly name and topic name.