Functions
Apply a function to a data in a stream
An operator is a first-class building block in the stream processor API. Operators are strung together in a user’s program to transform and enrich data.
See APIs for more details
A q interface can be used to build pipelines programatically. See the q API for API details.
A Python interface is included along side the q interface and can be used if PyKX is enabled. See the Python API for API details.
The pipeline builder uses a drag-and-drop interface to link together operations within a pipeline. For details on how to wire together a transformation, see the building a pipeline guide.
Available Python functionality
It is only presently possible to use Python code for development of pipelines within map, apply, merge and filter nodes, in particular for definition of the function logic of the node. This is intended to be expanded to all nodes and all locations where code can be defined within the pipelines in coming releases.
Accumulate
Aggregates a stream into an accumulator
See APIs for more details
q API: .qsp.accumulate •
Python API: kxi.sp.accumulate
Required Parameters:
| name | description | default |
|---|---|---|
| Aggregator | An aggregator which takes the data from the current batch and the accumulator and returns an updated accumulator. See below for more details on the function arguments. | |
| Initial State | The initial state of the accumulator |
Optional Parameters:
| name | description | default |
|---|---|---|
| Transform Output | A function to transform the output before emitting it. This function is passed the value of the accumulator | Pass-through the result unchanged. |
Function is a ternary function, which is applied to incoming batches in the stream. The arguments of the function are:
Keep a running total of the price per symbol:
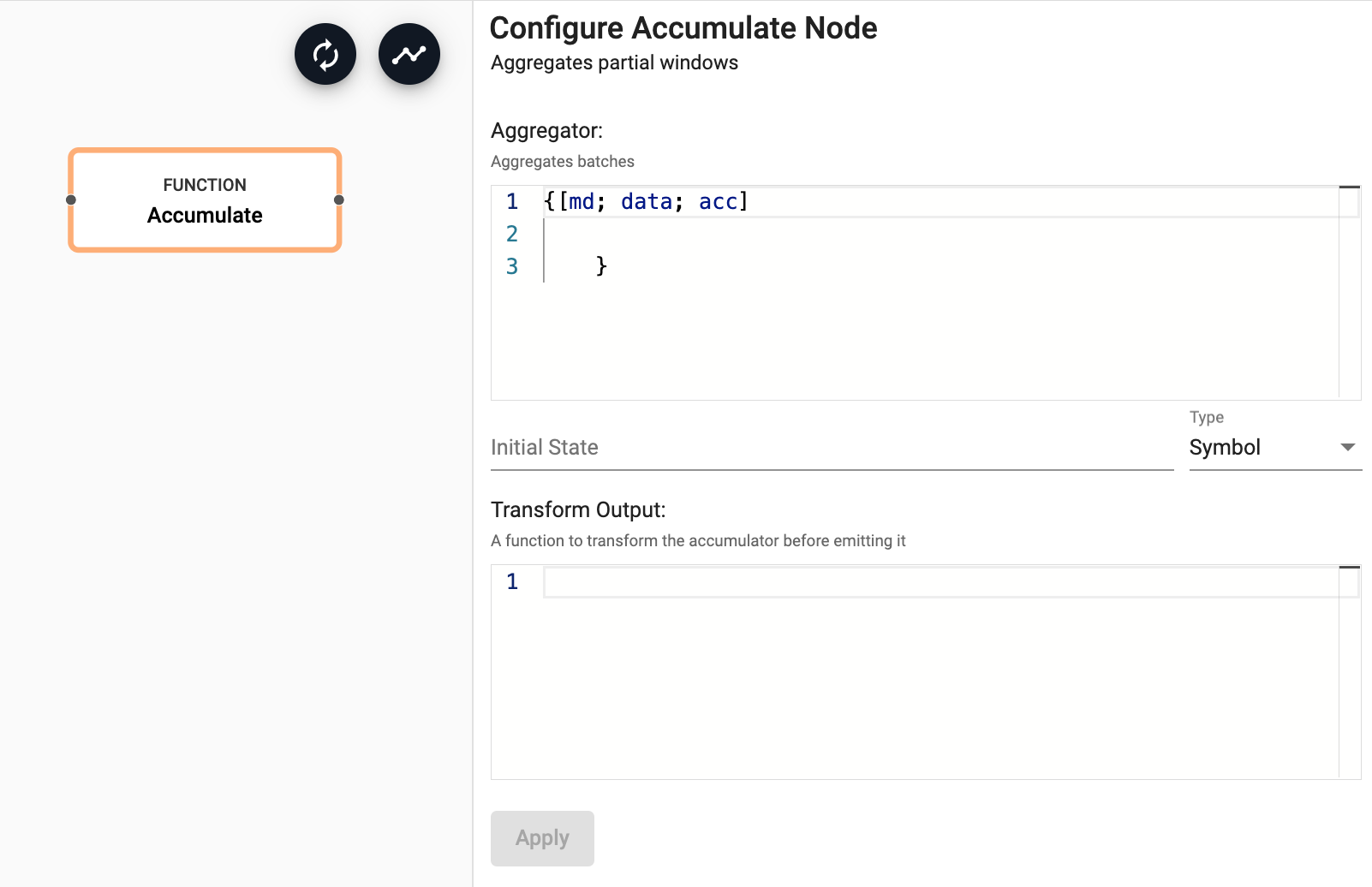
{[md; data; acc]
acc + select sum price by sym from data
}
where the initial state is set to:
([sym:`$()] price: `float$())
and the data is in the form of:
([] sym:10?3?`3; price:10?100f)
If the accumulator is a dictionary, it may be necessary to enlist the result in an output function (Transform Output) so the next operator receives a table; for example, {enlist x}.
Apply
Apply a function to incoming batches in the stream
See APIs for more details
q API: .qsp.apply •
Python API: kxi.sp.apply
The apply operator is useful for performing asynchronous operations or for modifying streaming metadata. Where possible, it is recommended to use Map over Apply it provides stronger determinism guarantees and is therefore more performant.
Determinism
Apply is treated as being non-deterministic and thus cannot be used in combination with other deterministic operators. See determinism for more details.
Required Parameters:
| name | description | default |
|---|---|---|
| Function | An operator that will apply a function over data in the stream and publish it downstream. The operator must end by pushing data downstream. See below for details. |
Optional Parameters:
| name | description | default |
|---|---|---|
| On Finish | A function run when the pipeline finishes or is torn down, to flush the buffer. It is passed the operator and metadata. |
Function is a ternary function, which is applied to incoming batches in the stream. The arguments of the function are:
Since apply is most often used with state, the operator and metadata arguments are implicitly added to the user-defined function.
Unlike other operators, apply is asynchronous, and data returned by it does not immediately flow through the rest of the pipeline. Instead, the operator must use .qsp.push to push data through the pipeline when ready.
This is often useful when combined with the state API for implementing custom window operation, running asynchronous external tasks (see task registration), and similar behaviors.
When apply is used to buffer data, the On Finish option should be used to flush the buffer when the pipeline finishes. It will be called once for every key in the state including the default key (empty symbol), with the metadata dictionary passed to it containing only the key.
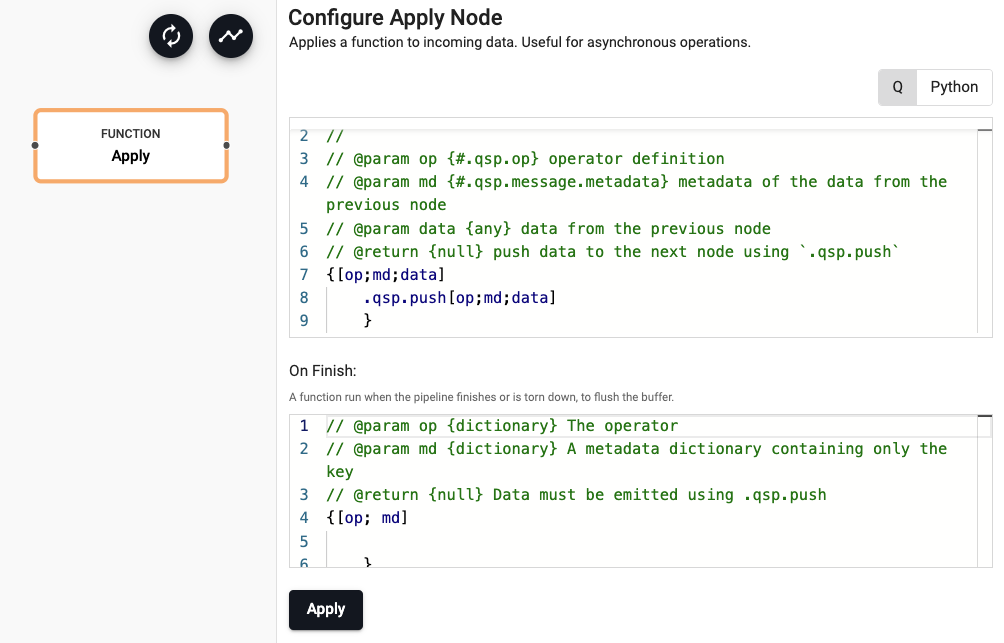
Buffer events in memory before running an analytic:
{[op; md; data]
$[10000 <= count state: .qsp.get[op; md] , data;
// If we've hit 10000 events, clear the state and push the buffer
[.qsp.set[op; md; ()]; .qsp.push[op; md; state]];
// Otherwise, update the buffer
.qsp.set[op; md; state]
]
}
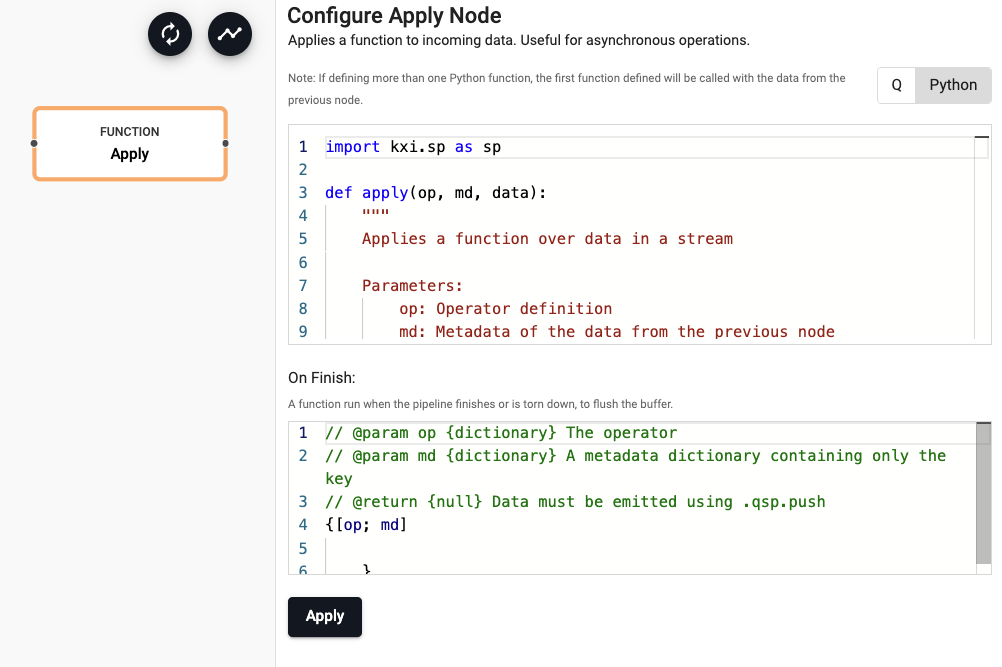
import kxi.sp as sp
import pykx as kx
def apply(op, md, data):
state = kx.q(',', sp.get(op, md), data)
if 10000 <= len(state):
sp.set(op, md, [])
sp.push(op, md, state)
else:
sp.set(op, md, state)
On Finish
{[op; md] .qsp.push[op; md] .qsp.get[op; md]}
Filter
Filter elements out of a batch, or a batch from a stream
See APIs for more details
q API: .qsp.filter •
Python API: kxi.sp.filter
Required Parameters:
| name | description | default |
|---|---|---|
| Function | A function that will filter out data from a stream. The function is passed the data in the current batch and must return either a boolean atom or a vector of the same length. If an atom is returned, the whole batch is accepted or rejected. If a vector is returned, only the values that are true will be kept, the rest are discarded |
Optional Parameters:
| name | description | default |
|---|---|---|
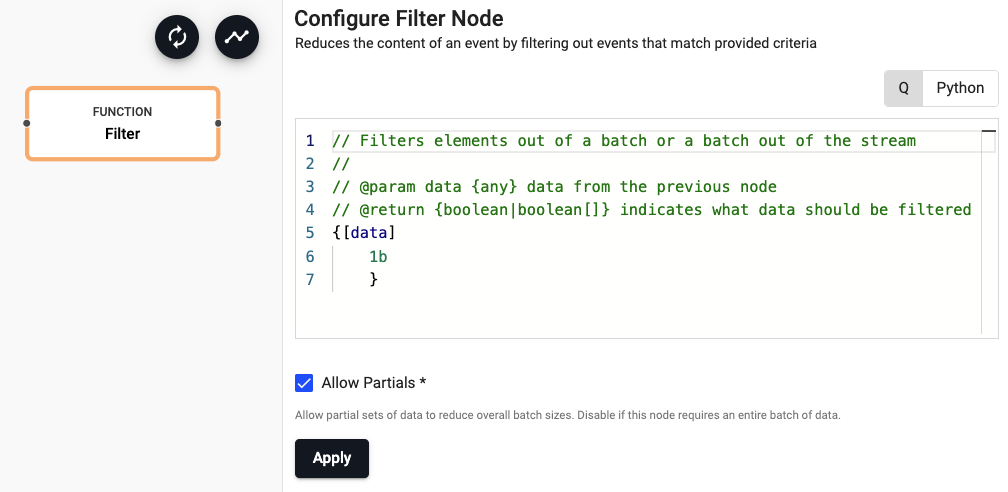
| Apply Partials | Some source nodes can push partial data through a pipeline to reduce batch sizes. For example, a file reader might break the file down into smaller chunks and push each chunk through the pipeline. If the operator requires the entire batch of data, then uncheck 'Allow Partials' to force the batch to be buffered to completion before calling this operator. | Yes |
Example:
// @param data {any} data from the previous node
// @return {boolean|boolean[]} indicates what data should be filtered
{[data]
`trade ~ first data
}
import pykx as kx
def filter_func(data):
return (data[0] == b'trade').all()
Key By
(Beta Feature) Keys a stream on a value in the stream
Beta Features
Beta feature are included for early feedback and for specific use cases. They are intended to work but have not been marked ready for production use. To learn more and enable beta features, see enabling beta features.
See APIs for more details
q API: .qsp.keyBy •
Python API: kxi.sp.key_by
Required Parameters:
| name | description | default |
|---|---|---|
| Function | A function that extracts a value from data in the stream and uses it to key the data stream. The return is used as the key for the values within the current batch. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Field | The field parameter can be used to extra data from a stream by index or by key. When a field is supplied, the function parameter is unnecessary. |
Map
Apply a function to data passing through the operator
See APIs for more details
q API: .qsp.map •
Python API: kxi.sp.map
Maps data from one value to another while preserving shape. The provided function is given the current batch of data as the first parameter and expected to return data.
Required Parameters:
| name | description | default |
|---|---|---|
| Function | A unary function that is applied to data and returns the result. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Apply Partials | Some source nodes can push partial data through a pipeline to reduce batch sizes. For example, a file reader might break the file down into smaller chunks and push each chunk through the pipeline. If the operator requires the entire batch of data, then uncheck 'Allow Partials' to force the batch to be buffered to completion before calling this operator. | Yes |
Example:
// @param data {any} data from the previous node
// @return {any} data to pass to the next node
{[data] update price * size from data }
import pykx as kx
def update_functions(data):
return kx.q.qsql.update(data, {'volume' : 'price*size'})
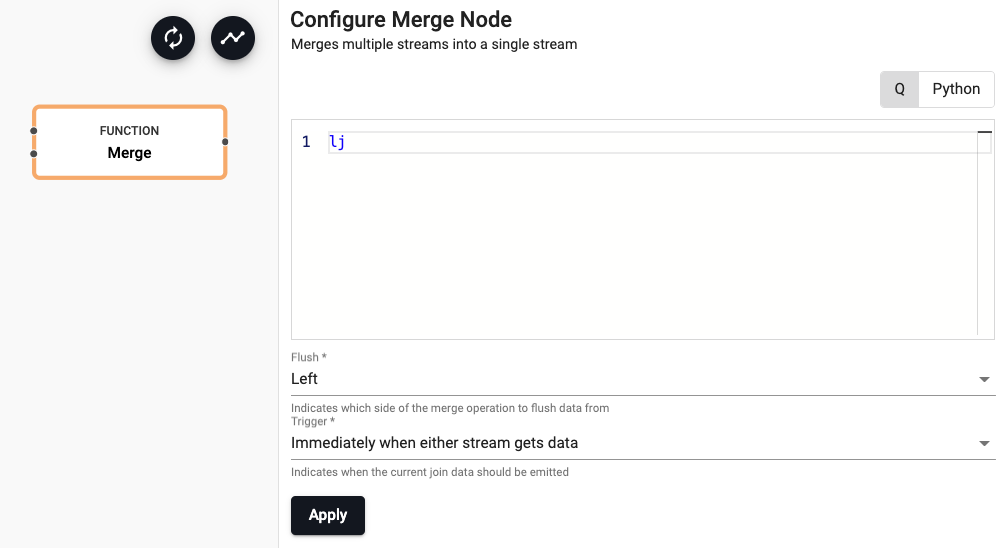
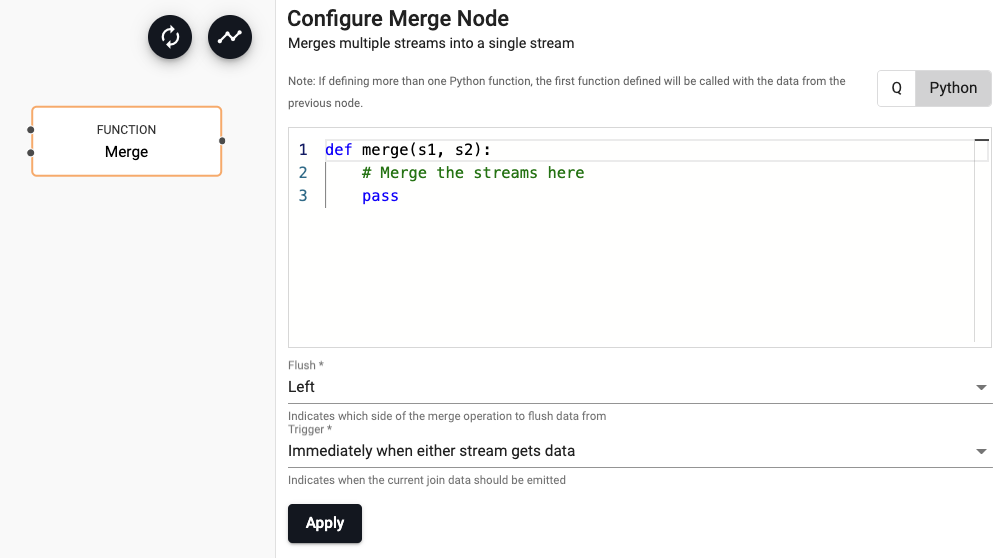
Merge
Merge two data streams
See APIs for more details
q API: .qsp.merge •
Python API: kxi.sp.merge
Merge can be used to join and enrich streams with other streams, with static data, or to union two streams into a single stream.
Required Parameters:
| name | description | default |
|---|---|---|
| Function | A function that receives the input of data from two streams when the 'Trigger' condition is met. The first parameter is the left data (or top connection) and the second is the right data (or the bottom connection) | lj |
Optional Parameters:
| name | description | default |
|---|---|---|
| Flush | Indicates which side of the union to flush data from; select between Left, Right, Both or None |
Left |
| Trigger | Indicates when the current join data should be emitted; select between Immediately when either stream gets data, When left stream gets data, When right stream gets data, or When both have data |
Immediately when either stream gets data |
Example:
```q
lj
```
```python
import pykx as kx
def py_merge(data1, data2):
return kx.q.lj(data1, data2)
```
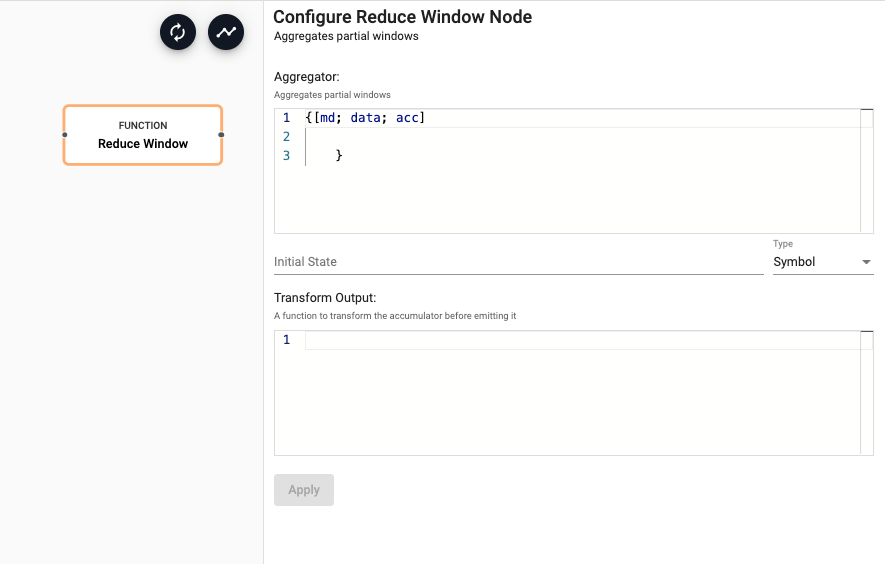
Reduce Window
Aggregate partial windows
See APIs for more details
q API: .qsp.reduce •
Python API: kxi.sp.reduce
A window may include more records than can fit in memory. As such, it may be necessary to reduce the buffered records into a smaller, aggregated value at regular intervals. If the window operator uses the count trigger option, a partial window will be emitted when the number of buffered records exceeds the count trigger. Partial windows will also be emitted when a stream goes idle. These partial windows can be aggregated using the function provided in this reduce operator. When the window is complete, this operator will emit the result of reducing the partial windows.
The reduce operator runs a function on each incoming batch to update the accumulator for that window. Each window has a separate accumulator. For partial windows, such as those emitted by the count trigger or idle streams, the accumulator will be updated but not emitted. When a window is closed, such as when the high-water mark passes the end of the window, the accumulator will be updated for that final batch, and then it will be emitted.
If no output function is specified, the accumulator will be emitted. If the accumulator is a dictionary, an output function like {enlist x} can be used to emit tables.
Any partial windows will be emitted on teardown.
Required Parameters:
| name | description | default |
|---|---|---|
| Aggregator | An aggregator which takes the data from the current batch and the accumulator and returns an updated accumulator. See below for more details on the function arguments. | |
| Initial State | The initial state of the accumulator |
Optional Parameters:
| name | description | default |
|---|---|---|
| Transform Output | A function to transform the output before emitting it. This function is passed the value of the accumulator | Pass-through the result unchanged. |
Function is a ternary function, which is applied to incoming batches in the stream. The arguments of the function are:
If the accumulator is a dictionary, it may be necessary to enlist the result in an output function (Transform Output) so the next operator receives a table; for example, {enlist x}.
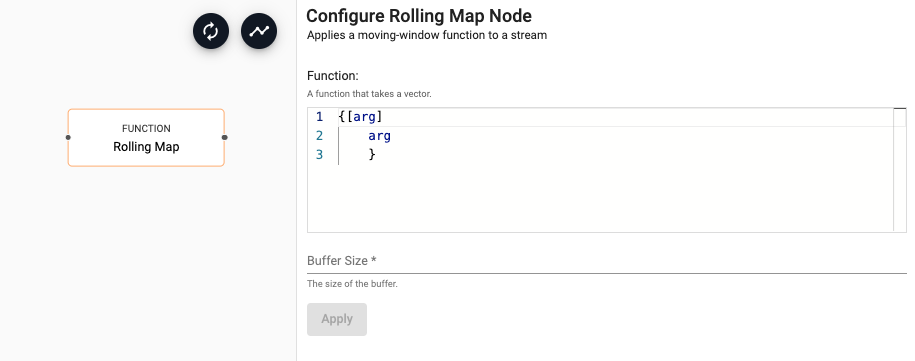
Rolling Map
(Beta Feature) Applies a moving-window function to a stream
Beta Features
Beta feature are included for early feedback and for specific use cases. They are intended to work but have not been marked ready for production use. To learn more and enable beta features, see enabling beta features.
See APIs for more details
q API: .qsp.rolling •
Python API: kxi.sp.rolling
Required Parameters:
| name | description | default |
|---|---|---|
| Function | A unary function that takes a vector and returns a moving window over the data | |
| Buffer Size | The size of the data to window |
Split
Split the current stream
See APIs for more details
q API: .qsp.split •
Python API: kxi.sp.split
Splits a stream into multiple streams for running separate analytics or processing. The split node has no configuration.
SQL
Perform an SQL query over data in a stream
See APIs for more details
q API: .qsp.sql •
Python API: kxi.sp.sql
Required Parameters:
| name | description | default |
|---|---|---|
| Query | An SQL query to be performed over table data in the stream |
Queries must
- conform to ANSI SQL and are limited to the documented supported operations
- reference a special
$1alias in place of the table name
If data in the stream is not table data, an error will be signaled. Choosing to pass a schema will allow the query to be precompiled enabling faster processing on streaming data.
Select average price by date:
select date, avg(price) from $1 group by date
Union
Unite two streams

See APIs for more details
q API: .qsp.union •
Python API: kxi.sp.union
Unifies multiple streams into a single stream. Similar to a join, with the difference that elements from both sides of the union are left as-is, resulting in a single stream.
Required Parameters:
| name | description | default |
|---|---|---|
| Flush | Indicates which side of the union to flush data from; select between Left (the top connector), Right (the bottom connector), Both or None. | Both |
| Trigger | Indicates when the current join data should be emitted; select between Immediately when either stream gets data, When left stream gets data, When right stream gets data, or When both have data | Immediately when either stream gets data |