Schema configuration
This section describes the configuration options available under the Schema Settings tab in the kdb Insights Enterprise UI.
A schema is a description of a collection of tables. Schemas are used to describe all of the tables within a kdb Insights Database. Schemas can also be used in pipelines to transform datatypes to match a particular table.
A schema is comprised of one or more tables and metadata properties. Each table defines a set of fields (sometimes referred to as columns) and metadata information. Each field within a table must have a name and a type associated with it.
Partitioned tables
A schema must have at least one table that is a partitioned table.
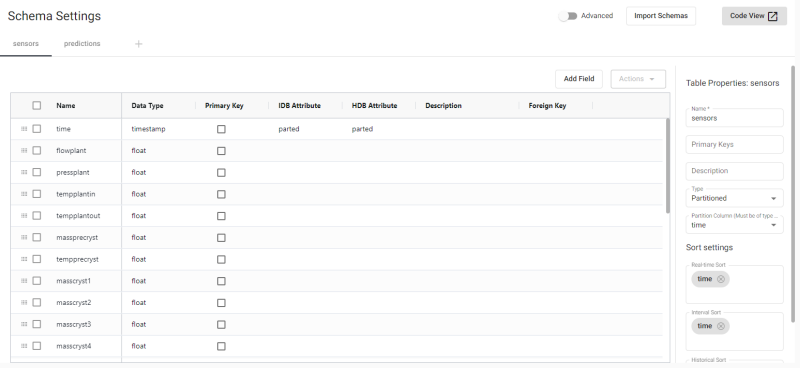
Tables can be added or removed from a schema, but schemas can only be changed when the associated database is torn down.
Configuration in YAML
Schemas can also be configured using YAML configuration file. YAML configured schemas can be added to databases.
Create a schema
Schemas are created in the Schema Settings tab of database.
A schema has a set of tables corresponding to the data stored in the database.
A new schema comes with a default table, table1, that can be changed or deleted. Every data table in a schema must have a Timestamp data type field - set as the partition - for storage on a kdb+ database. The Timestamp field represents the time characteristic in the data used for data tier migration.
Click Add Field to add data rows to the table. For large schemas pre-configured in JSON, use code view.
Additional schemas are saved as part of the parent database.
Table Properties
A table is a definition of a set of fields (columns) correlated by a common feature set. The definition of a table describes the types and purpose of the each field within that table, as well as some usage metadata properties.
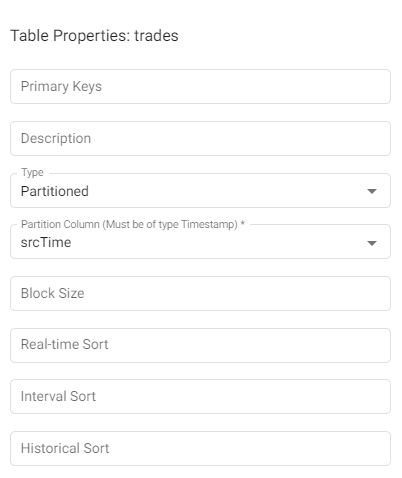
| name | description |
|---|---|
| Primary Keys | Names of fields to use as primary keys for this table. Primary keys are used for indicating unique data within a table. When provided, the table is keyed by these fields and any updates that have matching keys will update records with matching keys. |
| Description | A textual description for the table. This can be used to provide an overview of the data collected in the current table. |
| Type | The type of the table is how the table is managed on disk. For time based tables, use Partitioned. For supplementary data, use Splayed. Note that at least one of your tables must be Partitioned. |
| Partition Column | The name of the field within the table to use to partition the content. The field type it points to must be a timestamp. This value is required if the table type is set to partitioned. |
| Block Size | This value indicates when data should be written to disk. After this many records are received, data is written to disk. Writing more frequently increases disk IO but will use less memory. If omitted, the default value is 12 million records. |
| Real-time Sort | A list of fields to use for sorting fields in a memory tier. This typically corresponds to the data sort of the RDB tier. |
| Interval Sort | A list of fields to use for sorting fields in an ordinal partitioned tier. This typically corresponds to the data sort of the IDB tier. |
| Historical Sort | A list of fields to use for sorting fields in a normal disk tier. This typically corresponds to the data sort of the HDB tier. |
Keyed tables and object storage
Keyed tables will update values for records that have matching keys, except for data that has been migrated to an object storage tier. Once data has migrated to an object storage tier, it is immutable.
Field Properties
Fields describe the distinct features within a table with a unique name and datatype. Each row of data in the system for a given table must have a value for each field within a table.
Partition tables need a timestamp field
Partition tables require a timestamp field to order data and to propagate it through database tiers. The Partition Column field in the table must be set to the temporal field that will be used for ordering data.

Data rows are added with Add Field. Selected (checked) fields can be cloned, removed, positioned to the top or bottom, or have additional fields added above or below the selected row.
| name | description |
|---|---|
| Name | The name of the field in the table. The name must be unique within a single table and should be a single word that represents the purpose of the data within the field. This name must conform to kdb+ naming restrictions and should not use any reserved kdb+ primitives. See .Q.id for details. |
| Primary Key | If checked, adds the key to the set of primary keys in the table properties. |
| Data Type | The type of the field. See types below for more details. |
| RDB Attribute | Field attributes to apply when the table is in memory. This typically only applies to the RDB tier. See attribute details below for more information. |
| IDB Attribute (Ordinal Partitioning) | Field attributes to apply when the table is ordinal partitioned. This typically only applies to the IDB tier. See attribute details below for more information. |
| HDB Attribute (Temporal Partitioning) | Field attributes to apply when the table is partitioned on disk. This typically only applies to the HDB tier. See attribute details below for more information. |
| Description | A textual description of the field for documentation purposes. |
| Foreign | Indicates the values of this field are a foreign key into a field in another table. This value should be in the form of table.field, where the table is another table in the same schema and the field is in that table. If the foreign key value is provided, the field type must match the type of the field in the other table. |
Types
Field types support all of the base datatypes supported in kdb+. For fields containing only atom values, use the singular form of the data type. To indicate that a field is intended to support vectors of a given type, use the plural of the type name.
Type example
For a field of long numbers, use the type Long.
x
-
0
1
2
For a field of vectors of long integers, use Longs.
x
-
0 1 2
4 5 6
7 8 9
| name | type | description |
|---|---|---|
Any |
0h |
Allows for mixed types within a single field. Mixed types are useful for having mixed data or lists of strings but do have a performance trade-off and should be used sparingly. |
Boolean |
1h |
True or false values. |
Guid |
2h |
Unique identifiers in the form of 00000000-0000-0000-0000-000000000000. |
Byte |
4h |
Individual byte values on the range of 0x00 to 0xFF. |
Short |
5h |
A 2 byte short integer value in the range of -32767h to 32767h. |
Int |
6h |
A 4 byte integer value value in the range of -2147483647 to 2147483647. |
Long |
7h |
An 8 byte integer value with the maximum unsigned integer byte range. |
Real |
8h |
A 4 byte floating point value. |
Float |
9h |
An 8 byte floating point value. |
Char |
10h |
A byte value representing a character value. |
Symbol |
11h |
A symbol is a string of characters that is stored as an enumeration on disk. Reserve this datatype for repeated character values. Using this for unique character data will incur significant query performance overhead. |
Timestamp |
12h |
Stores a date and time as the number of nanoseconds since 2000.01.01. All partitioned tables should have at least one field that is a timestamp for partitioning its data on. |
Month |
13h |
Represents a month and year value without a day. |
Date |
14h |
Represents a month, year and day value as a date. |
Datetime |
15h |
A deprecated format for storing temporal values that uses a float as its underlying data structure. When using this datatype, it is possible to have two datetimes point to the same day but not be equivalent due to float precision. Use a timestamp over datetime whenever possible. |
Timespan |
16h |
Stores a time duration as a number of nanoseconds. |
Minute |
17h |
Stores hours and minutes of a timestamp. |
Second |
18h |
Stores hours, minutes and seconds of a timestamp. |
Time |
19h |
Stores hours, minutes, seconds and sub-seconds to nanosecond precision. |
Attributes
Attributes are a key performance tuning point for modifying the performance of queries in a kdb+ Insights database. Attributes can be set differently depending on the different tiers of your database and can be tuned to optimize performance at each tier. The following field attributes are available:
- None - requires a linear scan for filters against the field
- Sorted - ascending values - allows binary search for filters against the field
- Parted - (requires sorted) - maintains an index allowing constant time access to the start of a group of identical values
- Grouped - (does not require sorted) maintains a separate index for the field, identifying the positions of each distinct value. note - this index can take up significant storage space.
- Unique - (requires all values be distinct) allows a constant-time lookup - typically used for primary keys
More information about attributes, their use, and tradeoffs is available in the kdb+ documentation.
Within the table configuration, an attribute property can be set on particular fields within the table. There are three levels of attributes that can be set, attrMem, attrOrd and attrDisk. The memory level attribute applies when data is in memory which is used for any real-time tiers (RDB) in your database configuration. The ordinal level attribute is used for data that is stored intermittently throughout the day. This applies to the IDB tier of a database. Lastly, the disk attribute applies to all disk tiers including the HDB and subsequent tiers such as object storage.
It is recommended that the parted attribute is used on any field that will be used for filtering most frequently. You can have multiple fields with a parted attribute if there are multiple fields frequently used for filtering. Note that setting the parted attribute does require a significant amount of memory when constructing the field query index at write down. Ensure that enough memory is allocated to the Storage Manager for an full day's worth of data for the largest field that has this attribute set.
Removing fields
Fields can be be removed from a schema from the three dot menu, "Remove Field(s)".
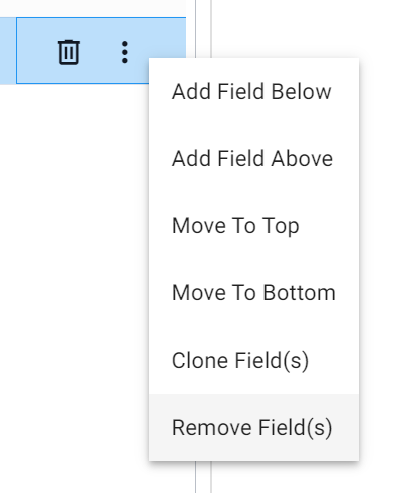
Clone fields
Fields and their properties and be cloned with "Clone Field(s)" from the three dot menu.
Editing a schema
A deployed schema cannot be edited until its associated database has been torn down.
Schema modifications
Schema modifications are supported for YAML based deployments; export the database and deploy it using the kdb Insights CLI. Then modify the schema.
Code view
Code view defines schemas using JSON. Schemas built using the code editor use table properties defined for the YAML schema configuration, encoded as JSON.
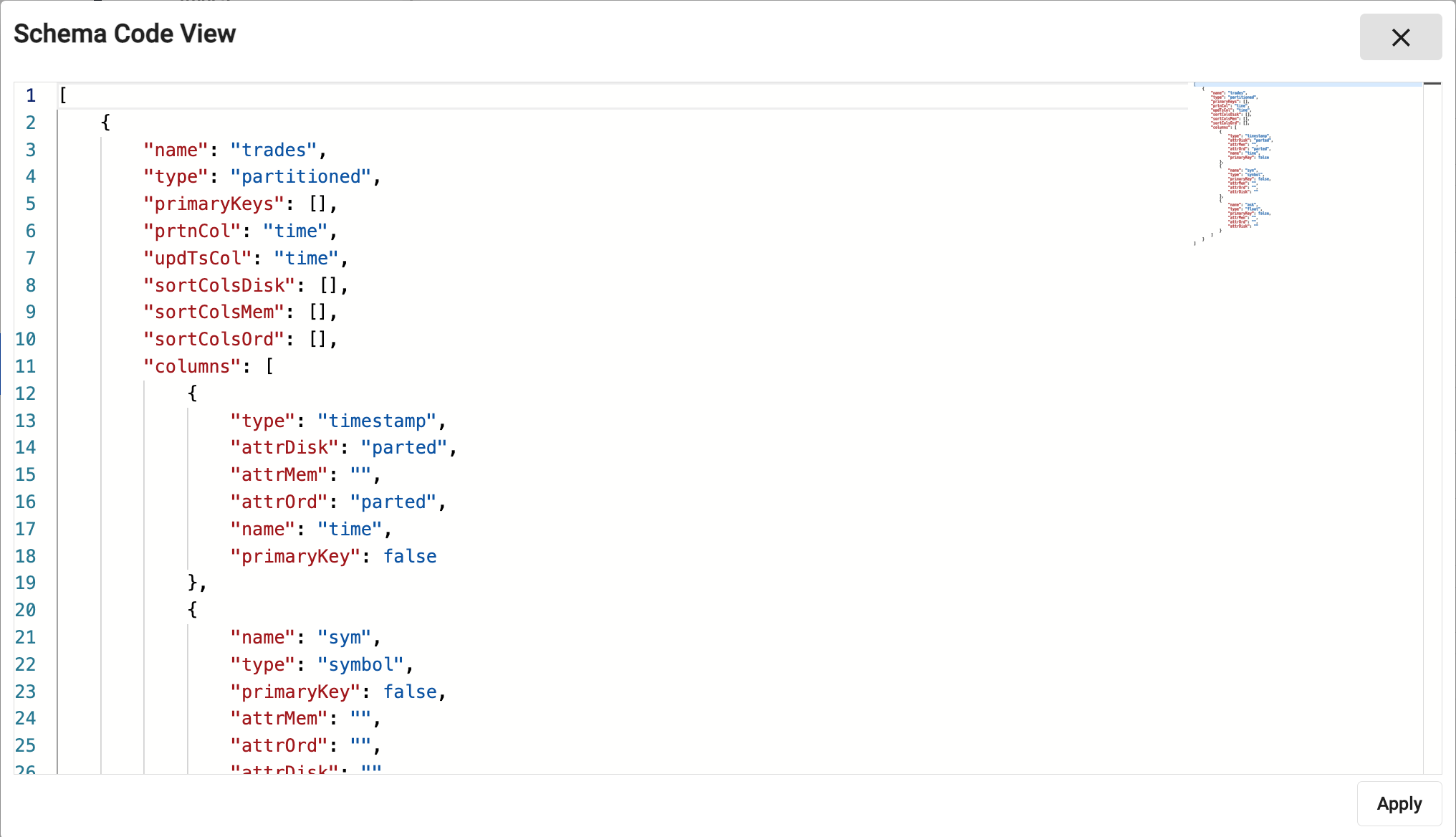
A validation check prevents submission of invalid code. Error details appear on hover-over of the underlined problem. In addition, on editing a property, a pop-up of supported attributes is offered:
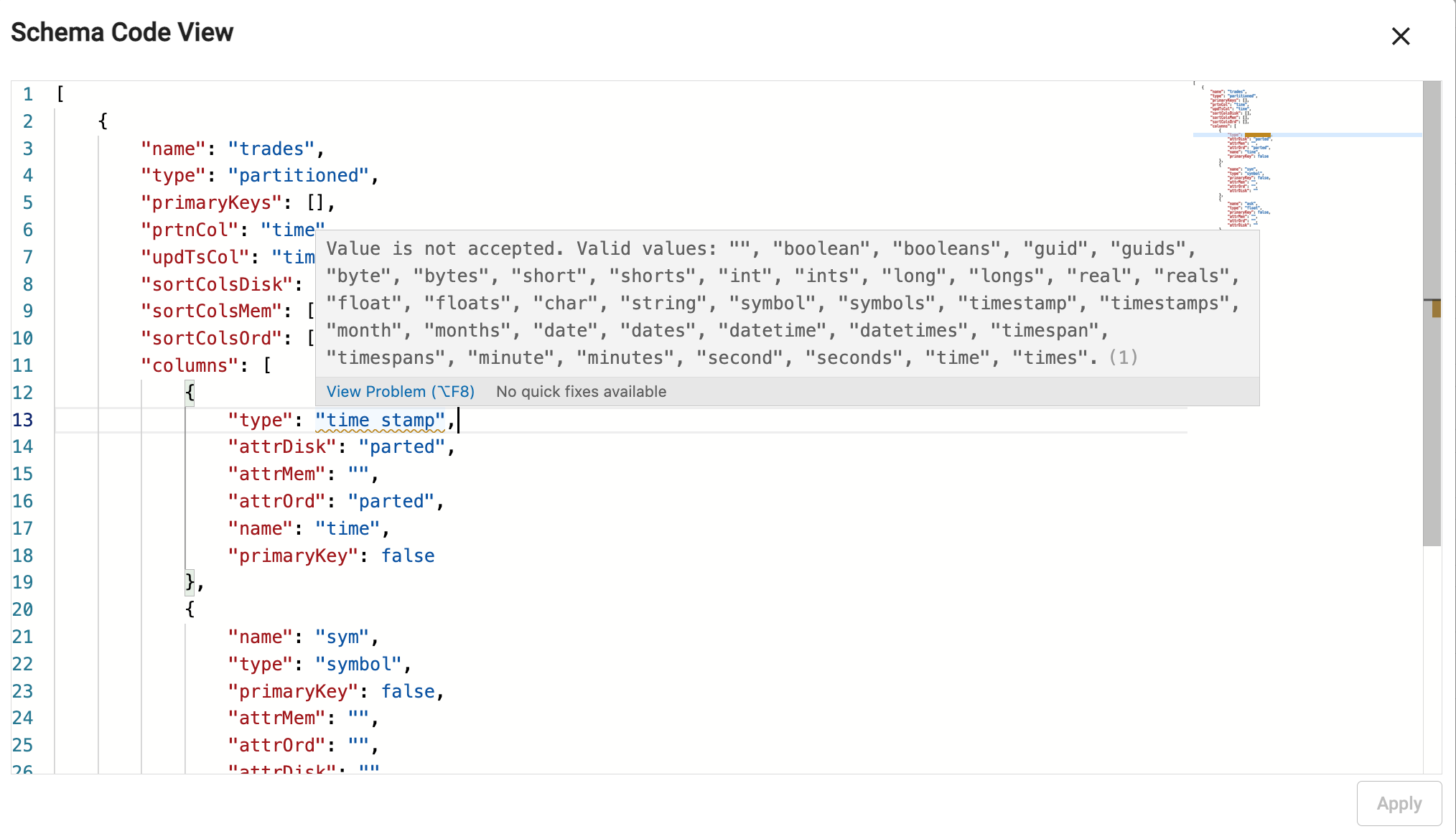
Upgrading schemas to the latest version of kdb Insights Enterprise
In early versions (before 1.5) of kdb Insights Enterprise, schemas could be created separately from databases. These schemas must be upgraded to the latest version of kdb Insights Enterprise. Any schema that is not assigned to a database must be assigned to a database. You can see if there are any schemas to upgrade by looking at the Upgrades icon in the sidebar.
![]()
After clicking on the upgrades icon, click on "Schemas" in the sidebar tree.
The list shows the schemas that need to be upgraded.
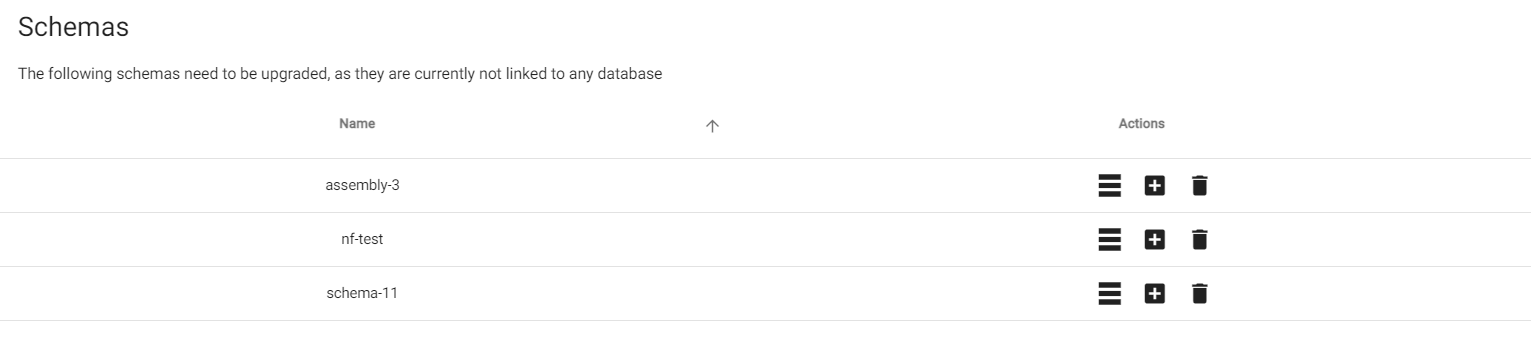
Now, each of these schemas can be upgraded by choosing one of these three options, add to database, create new database, or delete schema.

Add to database
This action adds the schema to an existing database. Click on the "Add to database" button for the schema you want to upgrade.
![]()
A dialog opens with a list of databases to select from.
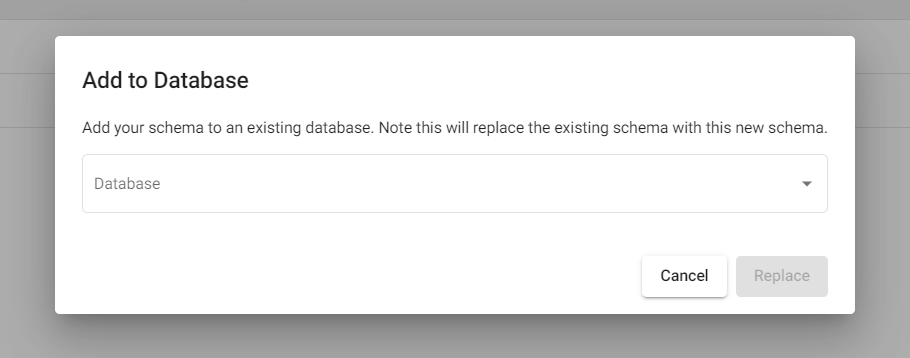
Select a database and click on the "Replace" button to add the schema to this database.

Create new database
This action creates a new database and associated schema. Click on the "Create new database" button for the schema you want to upgrade.
![]()
A dialog opens; enter the name of the new database.
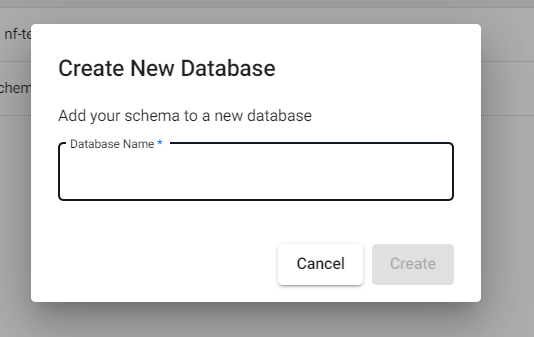
Click on the "Create" button to add the schema to this new database.

Delete schema
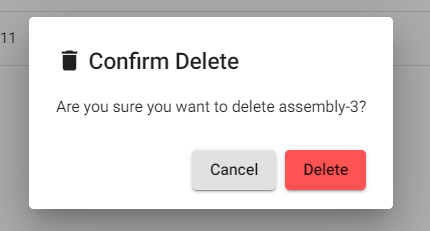
- To delete a schema, click Delete.
![]()
- Click Delete to confirm the deletion.
Next steps
Now that your schema has been configured, continue by creating a database to complete the configuration of the database. If you already have a database, you may be ready to move to deploying the database.