Readers
A reader reads data from an external or internal data source into the Stream Processor.
Reading data enables both streaming and batch data to be ingested into kdb Insights Enterprise.
Refer to the following APIs for more details
A q interface can be used to build pipelines programatically. See the q API for API details.
A Python interface is included along side the q interface and can be used if PyKX is enabled. Refer to the Python API for more details.
The pipeline builder uses a drag-and-drop interface to link together operations within a pipeline. For details on how to wire together a transformation, refer to the Building a pipeline guide.
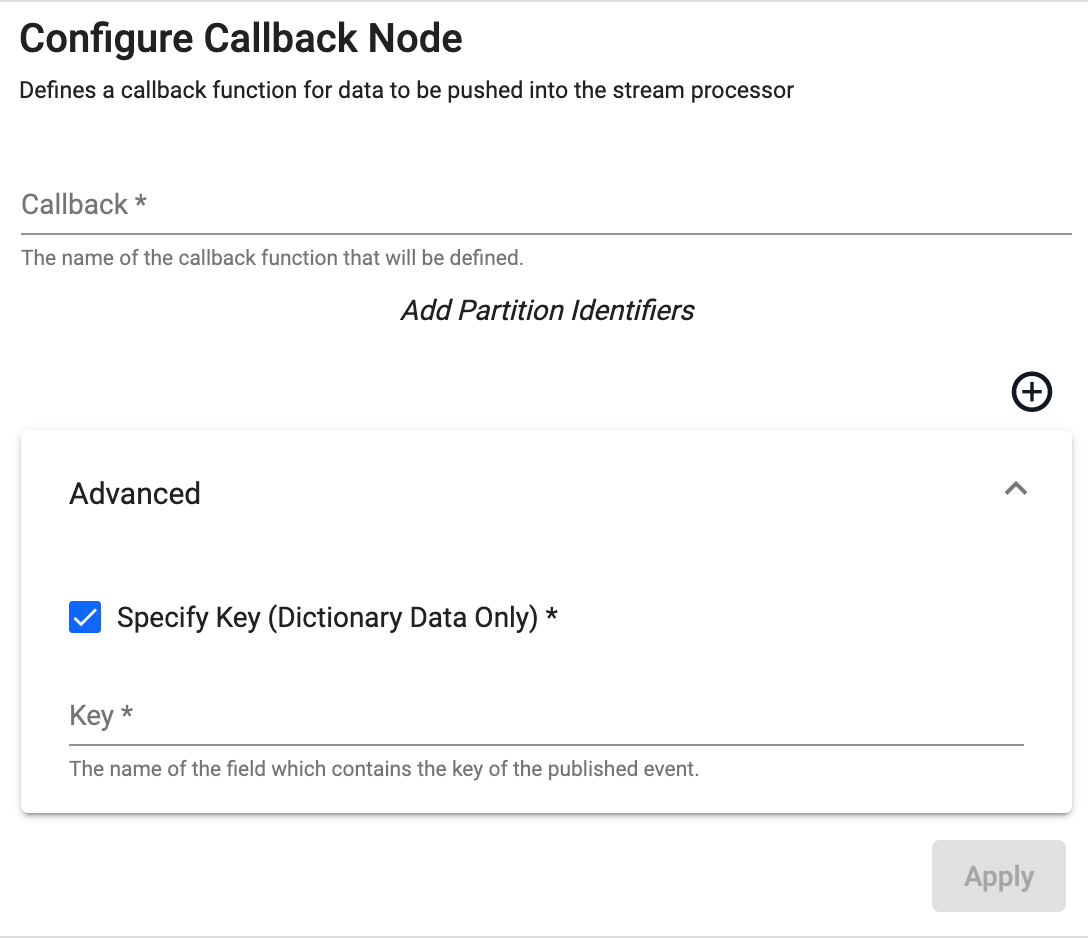
Callback
Receives data from a callback from the local process or over IPC.
Refer to the following APIs for more details
q API: .qsp.read.fromCallback •
Python API: kxi.sp.read.from_callback
Required Parameters:
| name | description | default |
|---|---|---|
| Callback | The name of the callback function where data will be received. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Specify Key | Whether to specify a key field for the event. Can only be checked for dictionary events. | No |
| Key | Name of the field which contains the key of the published event. Only available when Specify Key is checked. |
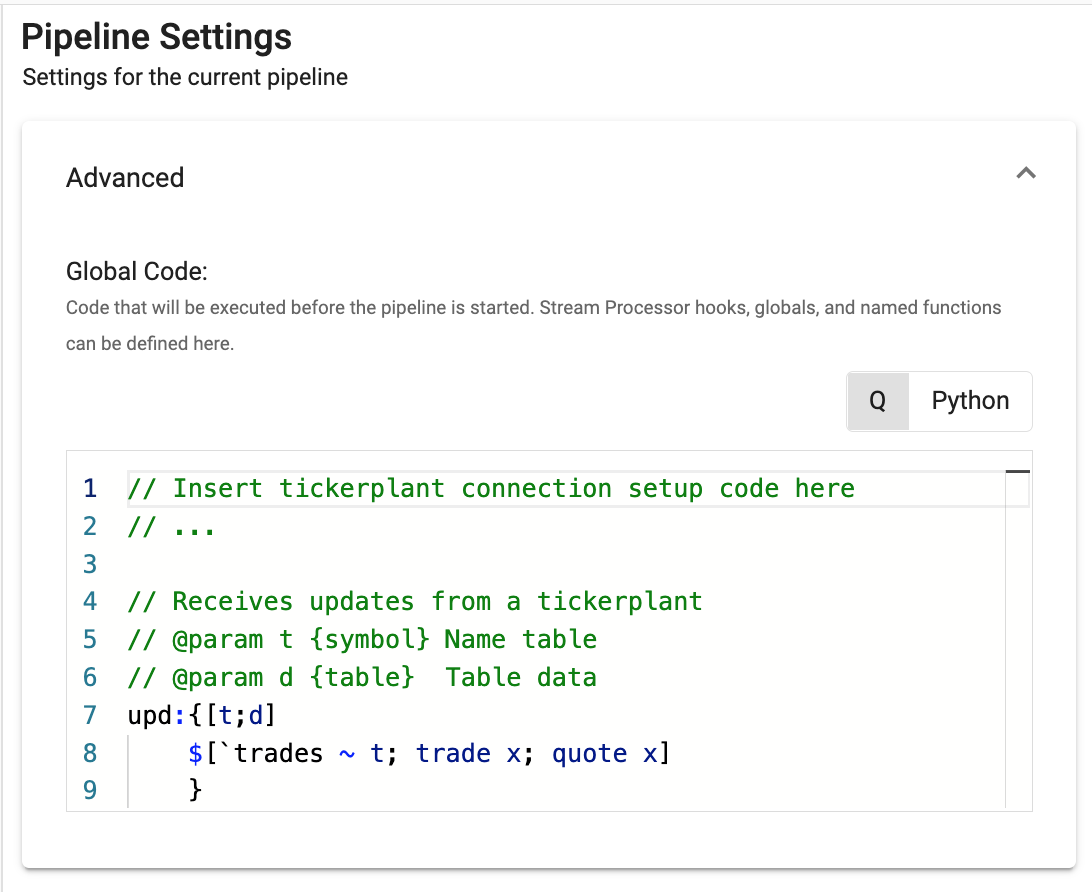
Example: Publishing from a tickerplant
A tickerplant is a message bus that typically sends data to subscribers in the form of (table; data). In this example, we will subscribe to a tickerplant with a trades and a quotes table with independent callback readers.
First, drag out a callback reader and set the name to be callback name to trade.

Second, drag out a callback reader and set the name to be callback name to quote.

Finally, setup some global code for establishing a connection to the tickerplant and dispatching to the appropriate callback function based on the table name.
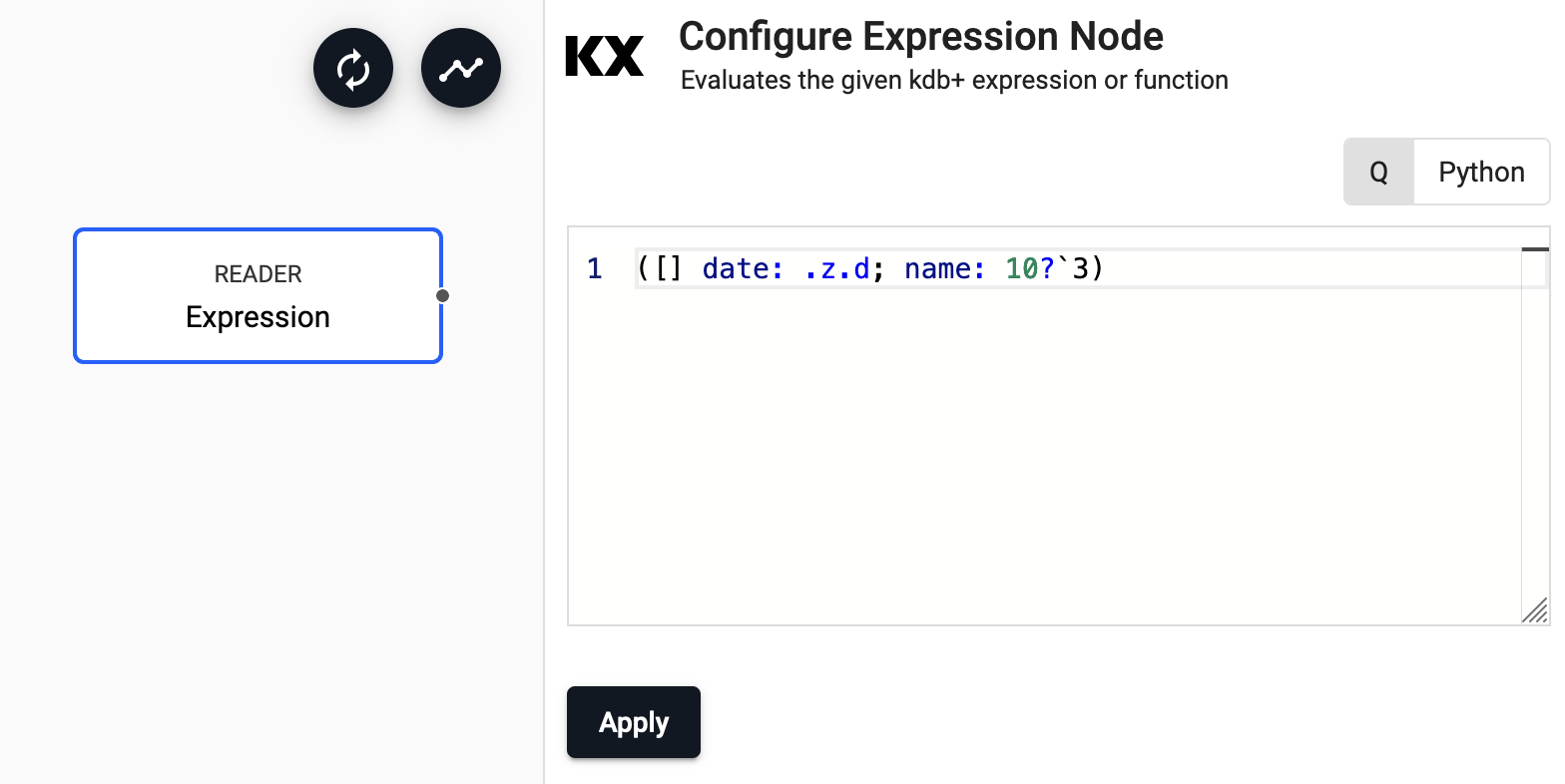
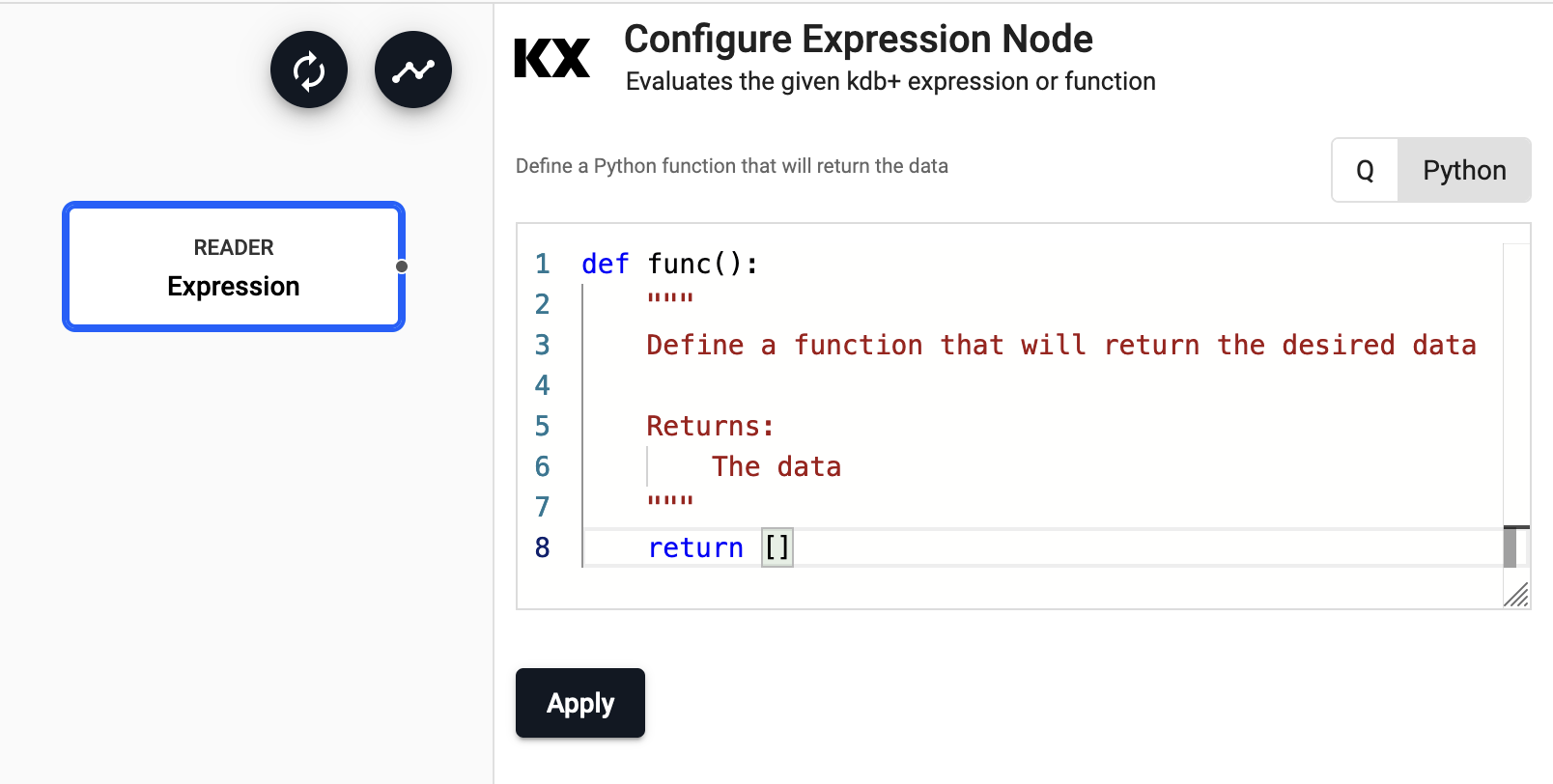
Expression
Runs a kdb+ expression.
Refer to the following APIs for more details
q API: .qsp.read.fromExpr •
Python API: kxi.sp.read.from_expr
The expression reader executes a snippet of kdb+ code and passes the result into the pipeline. This operator is mostly used for testing pipelines with mock data.
Required Parameters:
| name | description | default |
|---|---|---|
| Expression | A snippet of kdb+ code or a Python function to be evaluated. The last statement in this code snippet will be treated as the data source. |
Example: Generating data
The code snippet below generates a sample table with 2000 rows for testing:
n:2000;
([] date:n?(reverse .z.d-1+til 10);
instance:n?`inst1`inst2`inst3`inst4;
sym:n?`USD`EUR`GBP`JPY;
num:n?10)
import pandas as pd
import numpy as np
from datetime import datetime,timedelta
def gen():
n=2000
dates = [datetime.today().date() - timedelta(10-i,0,0) for i in range(10)]
return pd.DataFrame({'date' : np.random.choice(dates,n),
'instance' : np.random.choice(["inst1","inst2","inst3","inst4"],n),
'sym' : np.random.choice(["EUR","USD","GBP","JPY"],n),
'num' : np.random.randint(0,10,n)})
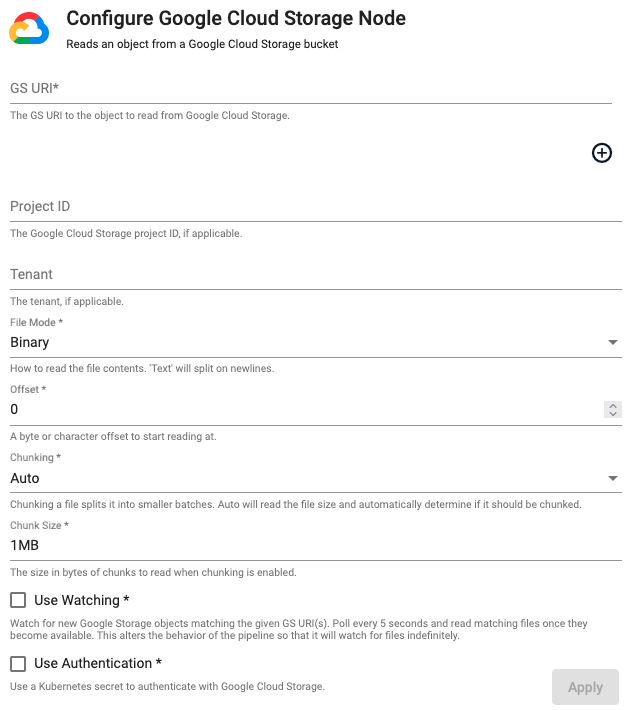
Google Cloud Storage
Reads an object from Google Cloud Storage.
Refer to the following APIs for more details
q API: .qsp.read.fromGoogleStorage •
Python API: kxi.sp.read.from_google_storage
Required Parameters:
| name | description | default |
|---|---|---|
| Path | Click the "+" button to add one or more Cloud Storage URIs to read from a Google cloud storage bucket. Glob patterns are supported. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Project ID | Google Cloud Storage Project ID, if applicable. | |
| Tenant | The authentication tenant, if applicable. | |
| File Mode | The file read mode. Setting the file mode to Binary will read content as a byte vector. When reading a file as text, data will be read as strings and be split on newlines. Each string vector represents a single line. Note that reading as Binary will work for both text and binary data, but reading as Text will only work for text data. |
Binary |
| Offset | A byte or character offset to start reading at. | 0 |
| Chunking | Splits file into smaller batches. Auto will read file size and determine if it should be chunked. |
Auto |
| Chunk Size | File size of chunks when chunking is enabled. | 1MB |
| Use Watching | Watch for new Google Storage objects matching the given Cloud Storage URI(s). | No |
| Use Authentication | Enable Kubernetes secret authentication. | No |
| Kubernetes Secret | The name of a Kubernetes secret to authenticate with Google Cloud Storage. Only available if Use Authentication is checked. |
No |
Watching
Usually this will be paired with a glob pattern for the Path. The pipeline will poll every 5 seconds and read matching files once they become available. The reader will continually watch for new files matching the file path provided using the watch method.
When using watching the pipeline will continue watching until there is manual intervention to finish the pipeline.
Watching should not to be used with a Database Writer using the direct write option
When using the Watching option it is not possible to pair this with a Database Writer using direct write since direct write relies on a definitive finish point which is not guaranteed when using this option.
Google Cloud Storage Authentication
Google Cloud Storage Authentication uses kurl for credential validation.
Environment variable authentication
To setup authentication using an environment variable, set GOOGLE_STORAGE_TOKEN in Google's gcloud CLI
gcloud auth print-access-token
Kubernetes secrets for authentication
A Kubernetes secret may be used to authenticate files. This secret needs to be created in the same namespace as the kdb Insights Enterprise install. The name of that secret is then used in the Kubernetes Secret field when configuring the reader.
To create a Kubernetes secret with Google Cloud credentials:
kubectl create secret generic SECRET_NAME DATA
SECRET_NAME is the name of the secret used in the reader. DATA is the data to add to the secret; for example, a path to a directory containing one or more configuration files using --from-file or -from-env-file flag, or key-value pairs each specified using --from-literal flags.
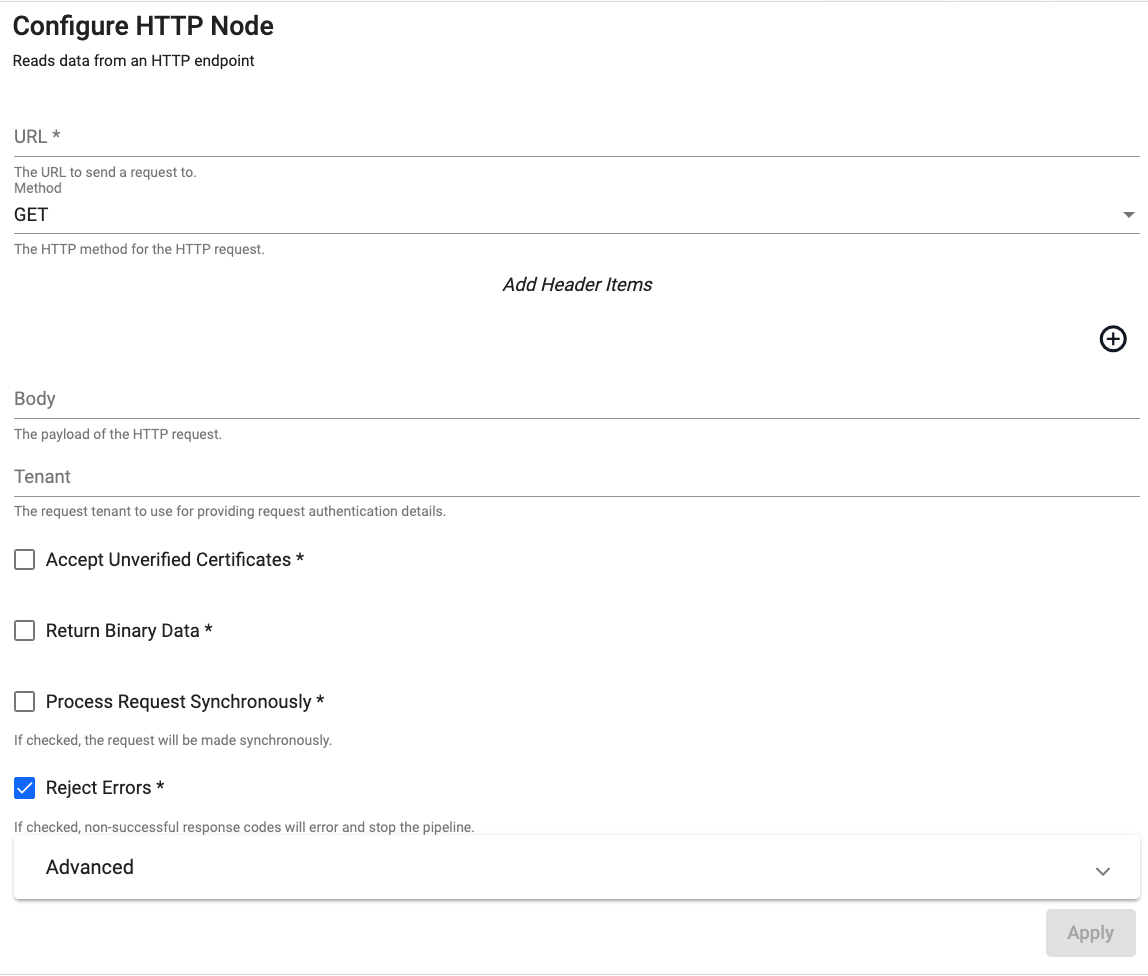
HTTP
Requests data from an HTTP(S) endpoint.
Refer to the following APIs for more details
q API: .qsp.read.fromHTTP •
Python API: kxi.sp.read.from_http
Required Parameters:
| name | description | default |
|---|---|---|
| URL | The URL to send the request to. The URL must include the protocol (http or https), the domain name (example.com) and port if necessary (example.com:8080) as well as the request path. For example: http://code.kx.com/q/ref. |
|
| Method | The method to use for sending the HTTP request. This must be one of GET, POST PUT, HEAD or DELETE. |
GET |
Optional Parameters:
| name | description | default |
|---|---|---|
| Body | The payload of the HTTP request. The body of the request is any content that needs to be included when sending the request to the server. | |
| Header | A map of header fields to send as part of the request. | |
| Tenant | The request tenant to use for providing request authentication details. | |
| Accept Unverified Certificates | When checked, any unverified server SSL/TLS certificates will be considered trustworthy | No |
| Return Binary Data | When checked, payload will be returned as binary data, otherwise payload is treated as text data. | No |
| Process Request Synchronously | When checked, a synchronous request will block the process until the request is completed. Default is an asynchronous request. | No |
| Reject Errors | When checked, a non-successful response will generate an error and stop the pipeline. | Yes |
Advanced Parameters:
| name | description | default |
|---|---|---|
| Follow Redirects | When checked, any redirects will automatically be followed up to the Max Redirects value. |
Yes |
| Max Redirects | The maximum number of redirects to follow before reporting an error. | 5 |
| Max Retry Attempts | The maximum number of times to retry a request that fails due to a timeout. | 10 |
| Timeout | The duration in milliseconds to wait for a request to complete before reporting an error. | 5000 |
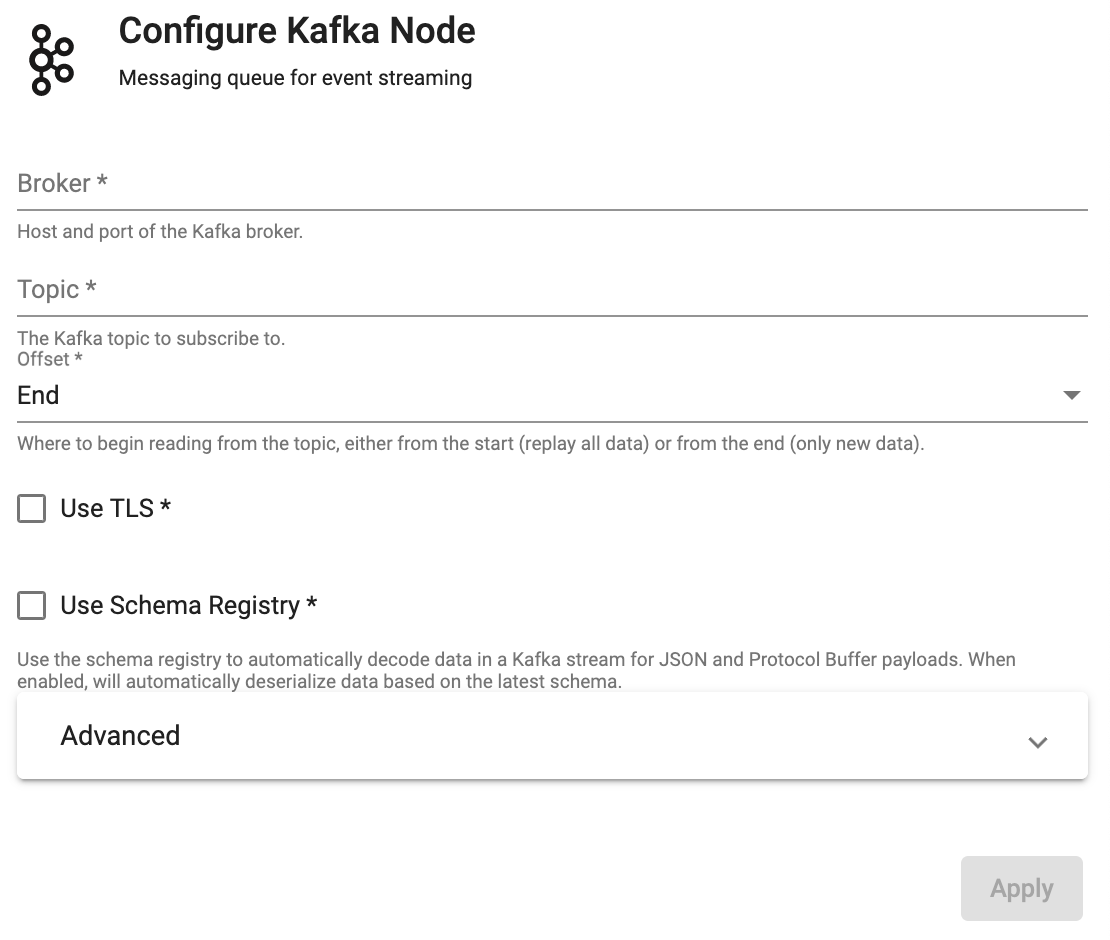
Kafka
Consume data from a Kafka topic.
Refer to the following APIs for more details
q API: .qsp.read.fromKafka •
Python API: kxi.sp.read.from_kafka
Kafka is a scalable streaming message queue for processing streaming data. Refer to the Kafka ingestion example for details about setting up a Kafka broker and ingesting data.
Required Parameters:
| name | description | default |
|---|---|---|
| Broker | Location of the Kafka broker as host:port. If multiple brokers are available, they can be entered as a comma separated list. | |
| Topic | The name of the Kafka topic to subscribe to. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Offset | Read data from the Start of the Topic; i.e. all data, or the End; i.e. new data only. |
End |
| Use TLS | Enable TLS for encrypting the Kafka connection. When selected, certificate details must be provided with a Kubernetes TLS Secret | No |
| Kubernetes Secret | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. Only available if Use TLS is selected. |
|
| Certificate Password | TLS certificate password, if required. Only available if Use TLS is selected. |
|
| Use Schema Registry | Use the schema registry to automatically decode data in a Kafka stream for JSON and Protocol Buffer payloads. When enabled, will automatically deserialize data based on the latest schema. | No |
| Registry | Kafka Schema Registry URL. Only available if Use Schema Registry is selected. |
|
| As List | Set to true for Kafka Schema Registry messages to omit field names when decoding Protocol Buffer schemas, and instead return only the list of values. Only available if Use Schema Registry is selected. |
No |
Refer to this guide from Kubernetes for more details on setting up TLS Secrets
Advanced Parameters:
| name | description | default |
|---|---|---|
| Retry Attempts | The maximum number of retry attempts allowed. | 10 |
| Retry Wait Time | The amount of time to wait between retry attempts. | 2s |
| Poll Limit | Maximum number of records to process in a single poll loop. | 1000 |
| Use Advanced Kafka Options | Set to true and click the "+" button to add one or more key-value pairs, where the keys are Kafka configuration properties defined by librdkafka. | No |
Use Advanced Kafka Options
Allows more flexible options for security protocol configuration or changes to fetch intervals, as seen when subscribing to an Azure Event Hub Kafka connector.
Offset Committing and Group Permissions
The Kafka reader will automatically commit offsets when reading from a broker. This is essential for exactly once semantics and fault tolerance. The error "Local: Waiting for coordinator" will occur when attempting to commit offsets if you do not have sufficient group permissions. The broker should be configured so that the user has group Describe permissions. Since The Kafka Reader will generate a random group ID, ensure the user is permissioned for all group names on the broker.
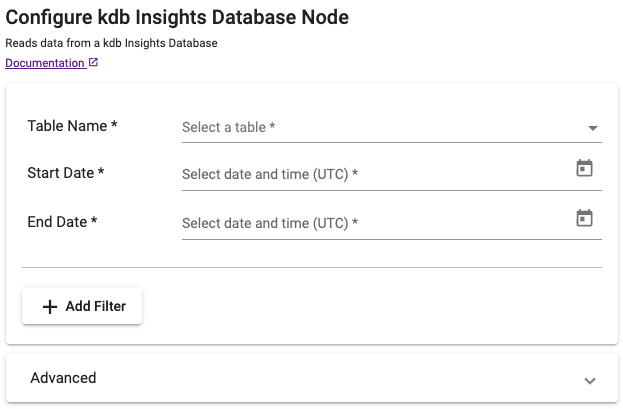
kdb Insights Database
Read from a kdb Insights Database.
Refer to the following APIs for more details
q API: .qsp.read.fromDatabase •
Required Parameters:
| name | description | default |
|---|---|---|
| Table Name | The name of the table to retrieve data from. | |
| Start Date | The inclusive start time of the period of interest. | |
| End Date | The exclusive end time of the period of interest. |
Optional Parameters Location
To view the Optional Parmeters listed below, click Add filter to reveal a drop-down of these options. The drop-down then refreshes to reveal futher options specific to your choice.
Optional Parameters:
| name | description | default |
|---|---|---|
| filter | A function that returns true for rows to include. | |
| filter by label | When multiple databases each have a table matching the table name, filtering by label can select a subset of those. | |
| sort | A column to sort by (ascending). | |
| define aggregation | Apply an aggregation over a column for the rows matching the query, assigning the result to a new column. | |
| group aggregation by | Group the result of the query by the specified column before running the aggregation. | |
| Retry Attempts | Maximum number of retry attempts allowed. | 5 |
| Retry Wait Time | Wait time between retry attempts. | 2 seconds |
Run a query, optionally including aggregations, against a table.
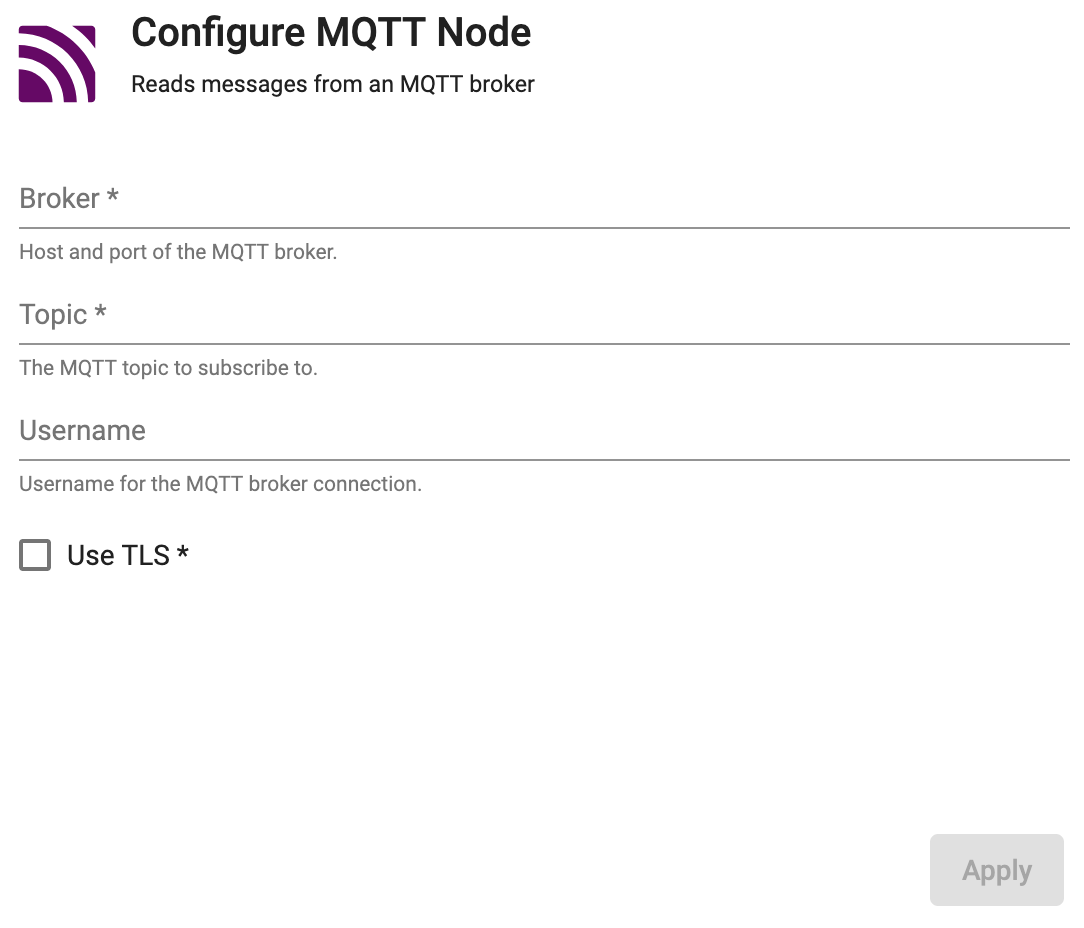
MQTT
Subscribe to an MQTT topic.
Refer to the following APIs for more details
q API: .qsp.read.fromMQTT •
Python API: kxi.sp.read.from_mqtt
Read messages from an MQTT broker. MQTT is a lightweight, publish-subscribe, machine to machine network protocol for message queuing service. It is designed for connections with remote locations that have devices with resource constraints or limited network bandwidth.
Required Parameters:
| name | description | default |
|---|---|---|
| Broker | Location of the MQTT broker as protocol://host:port. |
|
| Topic | The name of the MQTT topic to subscribe to. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Username | Username for the MQTT broker connection. | |
| Use TLS | Enable TLS for encrypting the Kafka connection. When selected, certificate details must be provided with a Kubernetes TLS Secret | No |
| Kubernetes Secret | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. Only available if Use TLS is selected. |
|
| Certificate Password | TLS certificate password, if required. Only available if Use TLS is selected. |
Refer to this guide from Kubernetes for more details on setting up TLS Secrets
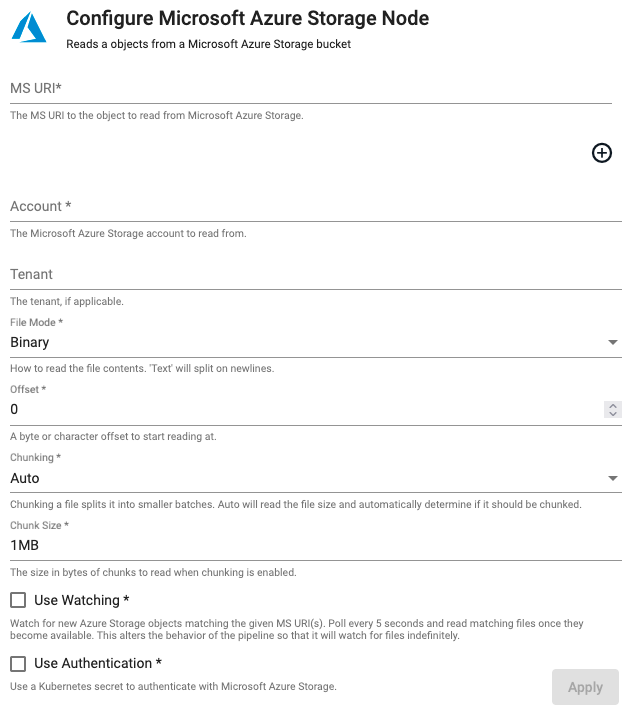
Microsoft Azure Storage
Reads an object from Microsoft Azure Storage.
Refer to the following APIs for more details
q API: .qsp.read.fromAzureStorage •
Python API: kxi.sp.read.from_azure_storage
Required Parameters:
| name | description | default |
|---|---|---|
| Path | Click the "+" button to add one or more Blob Storage URIs to read from an Azure cloud storage bucket. Glob patterns are supported. | |
| Account | The name of the Azure Storage Account hosting the data. | $AZURE_STORAGE_ACCOUNT |
Optional Parameters:
| name | description | default |
|---|---|---|
| Tenant | The authentication tenant, if applicable. | |
| File Mode | The file read mode. Setting the file mode to Binary will read content as a byte vector. When reading a file as text, data will be read as strings and be split on newlines. Each string vector represents a single line. Note that reading as Binary will work for both text and binary data, but reading as Text will only work for text data. |
Binary |
| Offset | A byte or character offset to start reading at. | 0 |
| Chunking | Splits file into smaller batches. Auto will read file size and determine if it should be chunked. |
Auto |
| Chunk Size | File size of chunks when chunking is enabled. | 1MB |
| Use Watching | Watch for new Azure Storage objects matching the given URI(s). | No |
| Use Authentication | Enable Kubernetes secret authentication. | No |
| Kubernetes Secret | The name of a Kubernetes secret to authenticate with Google Cloud Storage. Only available if Use Authentication is checked. |
Watching
Usually this will be paired with a glob pattern for the Path. The pipeline will poll every 5 seconds and read matching files once they become available. The reader will continually watch for new files matching the file path provided using the watch method.
When using watching the pipeline will continue watching until there is manual intervention to finish the pipeline.
Watching should not to be used with a Database Writer using the direct write option
When using the Watching option it is not possible to pair this with a Database Writer using direct write since direct write relies on a definitive finish point which is not guaranteed when using this option.
Microsoft Azure Authentication
Microsoft Azure Storage Authentication uses kurl for credential validation.
Environment variable Authentication
To set up authentication with an environment variable, set AZURE_STORAGE_ACCOUNT to the name of the storage account to read from, and AZURE_STORAGE_SHARED_KEY to the one of the keys of the account. Additional details on shared keys usage available here.
Kubernetes secrets for authentication
A Kubernetes secret may be used to authenticate files. This secret needs to be created in the same namespace as the kdb Insights Enterprise install. The name of that secret is then used in the Kubernetes Secret field when configuring the reader.
To create a Kubernetes secret with Azure credentials:
kubectl create secret generic --from-literal=token="$AZURE_STORAGE_TOKEN" ms-creds
For further information about Kubernetes Secrets.
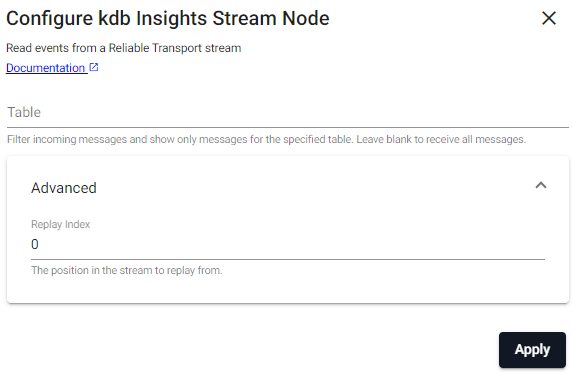
kdb Insights Stream
Reads data from a kdb Insights Stream.
Refer to the following APIs for more details
q API: .qsp.read.fromStream •
Python API: kxi.sp.read.from_stream
Insights streams
Required Parameters:
| name | description | default |
|---|---|---|
| Table | Filter incoming messages to show only messages for the specified table. If no filter is provided, all messages in the stream are consumed. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Replay Index | The position in the stream to replay from. | 0 |
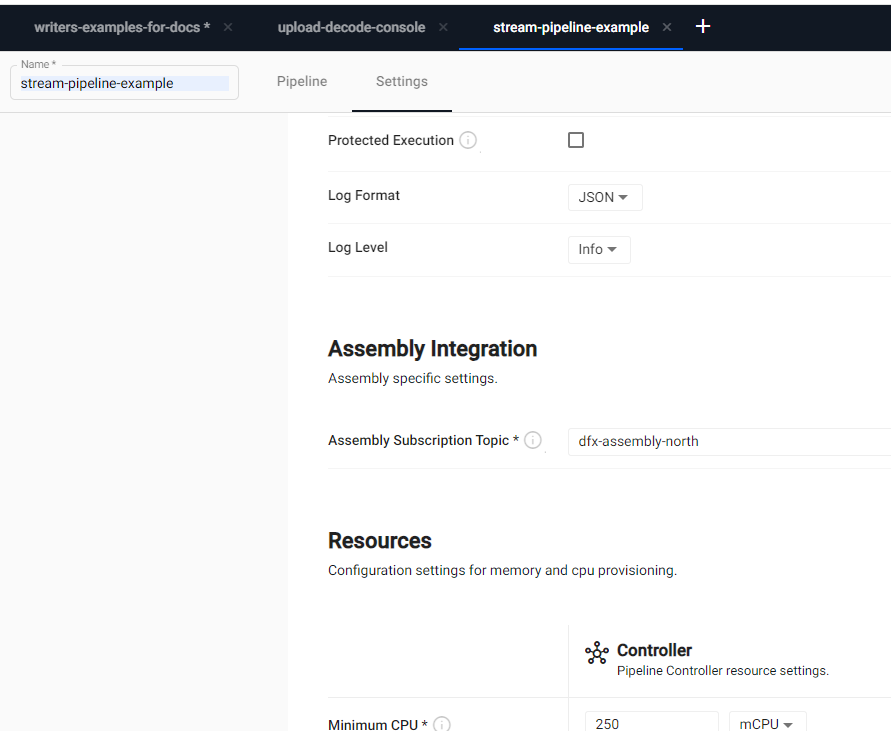
To read data from a stream, an assembly must be provided. This is done prior to pipeline deploy time. Visit the Settings tab in the pipeline editor and fill in the Assembly Integration field with the assembly name and topic name.
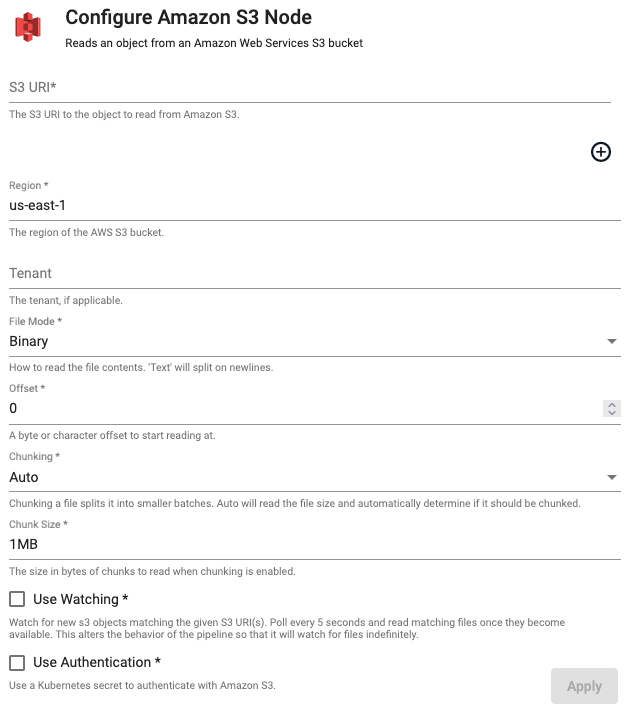
Amazon S3
Reads an object from Amazon S3.
Refer to the following APIs for more details
q API: .qsp.read.fromAmazonS3 •
Python API: kxi.sp.read.from_amazon_s3
Required Parameters:
| name | description | default |
|---|---|---|
| Path | Add one or more S3 URIs to read from an Amazons S3 Cloud Storage bucket |
Optional Parameters:
| name | description | default |
|---|---|---|
| Region | The AWS region of the bucket to authenticate against | us-east-1 |
| Tenant | The authentication tenant, if applicable. | |
| File Mode | The file read mode. Setting the file mode to Binary will read content as a byte vector. When reading a file as text, data will be read as strings and be split on newlines. Each string vector represents a single line. Note that reading as Binary will work for both text and binary data, but reading as Text will only work for text data. |
Binary |
| Offset | A byte or character offset to start reading at. | 0 |
| Chunking | Splits file into smaller batches. Auto will read file size and determine if it should be chunked. |
Auto |
| Chunk Size | File size of chunks when chunking is enabled. | 1MB |
| Use Watching | Watch for new S3 objects matching the given S3 URI(s). | No |
| Use Authentication | Enable Kubernetes secret authentication. | No |
| Kubernetes Secret | The name of a Kubernetes secret to authenticate with Google Cloud Storage. Only available if Use Authentication is checked. |
Watching
Usually this will be paired with a glob pattern for the Path. The pipeline will poll every 5 seconds and read matching files once they become available. The reader will continually watch for new files matching the file path provided using the watch method.
When using watching the pipeline will continue watching until there is manual intervention to finish the pipeline.
Watching should not to be used with a Database Writer using the direct write option
When using the Watching option it is not possible to pair this with a Database Writer using direct write since direct write relies on a definitive finish point which is not guaranteed when using this option.
Amazon S3 Authentication
To access private buckets or files, a Kubernetes secret needs to be created that contains valid AWS credentials. This secret needs to be created in the same namespace as the kdb Insights Enterprise install. The name of that secret is then used in the Kubernetes Secret field when configuring the reader.
To create a Kubernetes secret containing AWS credentials:
kubectl create secret generic --from-file=credentials=<path/to/.aws/credentials> <secret-name>
Where <path/to/.aws/credentials> is the path to an AWS credentials file, and <secret-name> is the name of the Kubernetes secret to create.
Note that this only needs to be done once, and each subsequent usage of the Amazon S3 reader can re-use the same Kubernetes secret.
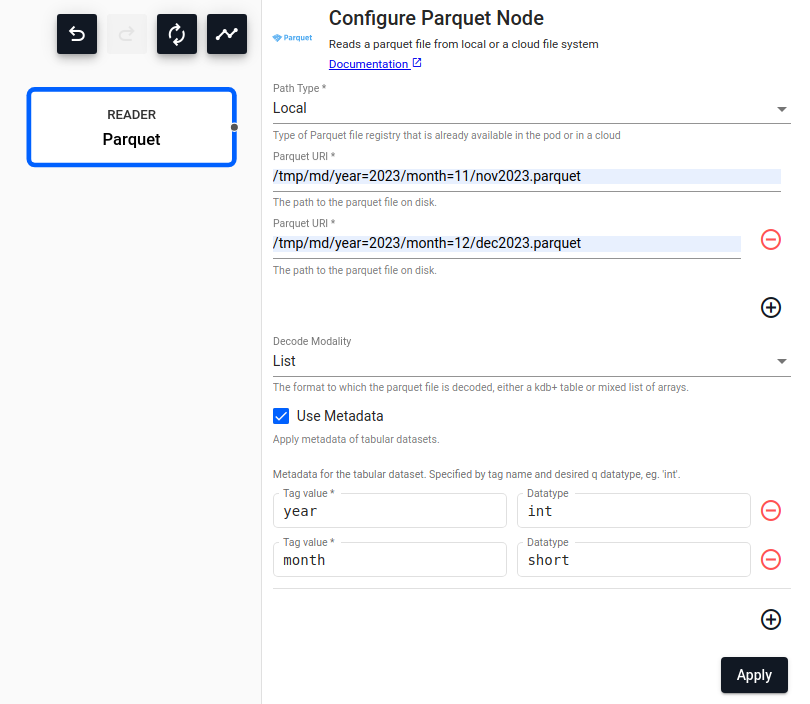
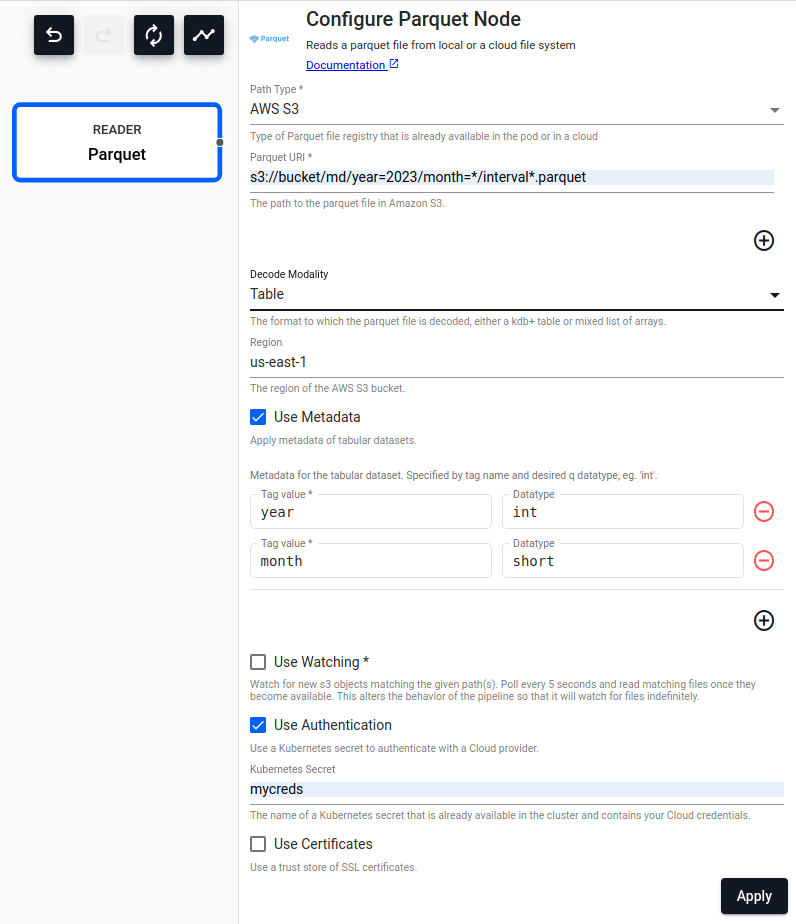
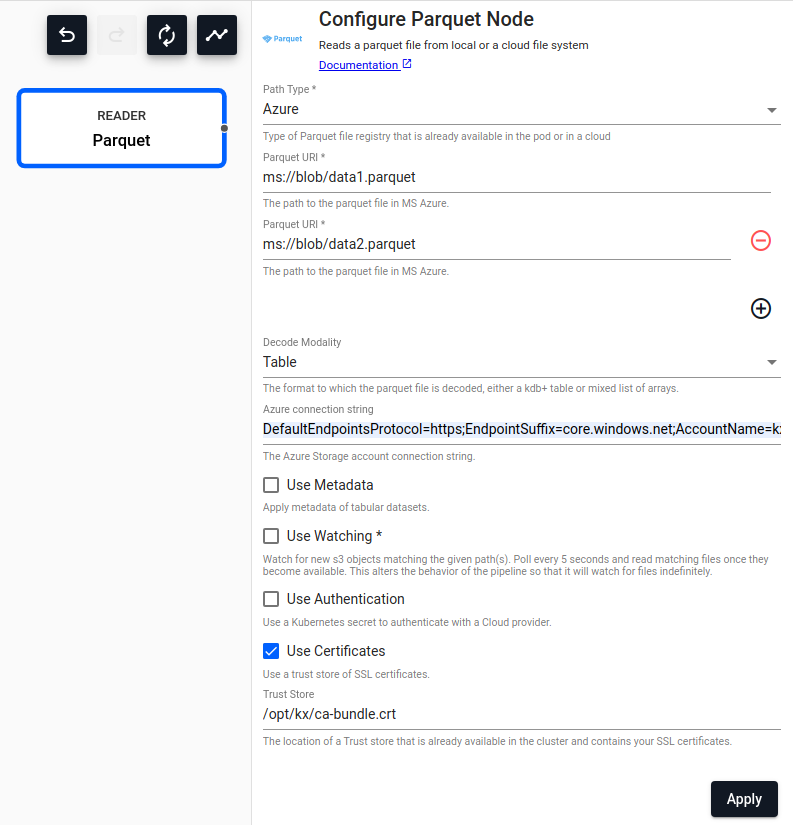
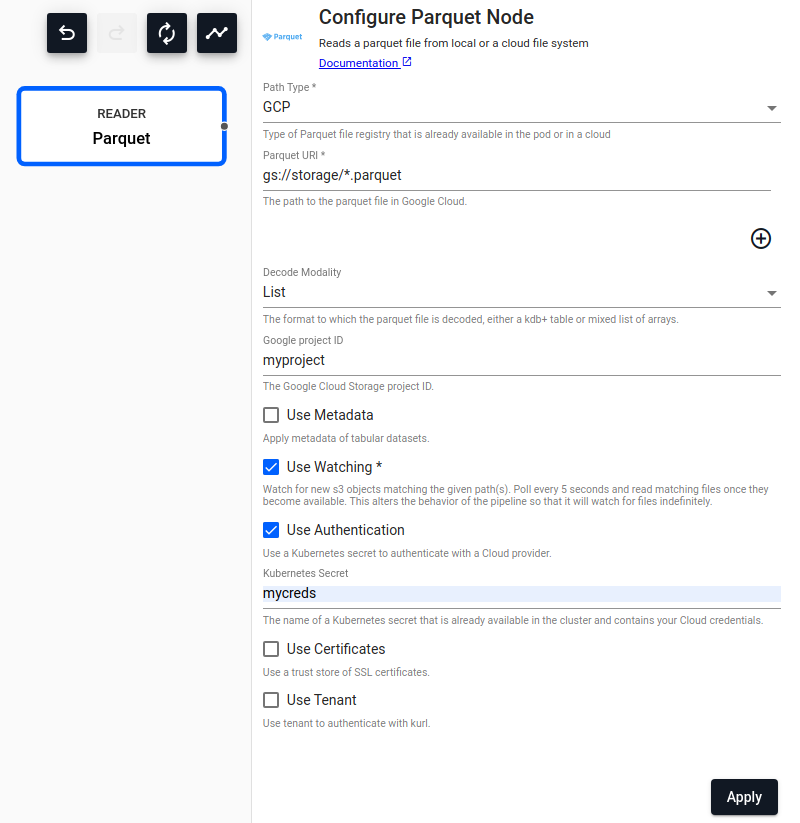
Parquet
.Reads a parquet file.
Refer to the following APIs for more details
q API: .qsp.read.fromParquet •
Python API: kxi.sp.read.from_parquet
Required Parameters:
| name | description | default |
|---|---|---|
| Path Type | Type of Parquet file registry in the cluster or in a cloud the file will be read from, either Local, AWS S3, AZURE or GCS. |
Local |
| Path | Path to one or more parquet file(s) being read from disk or Amazon S3/MS Azure/Google Cloud. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Decode Modality | Either Table or List. |
Table |
| Region | The AWS region to authenticate against, if Path Type is AWS S3. |
us-east-1 |
| Azure Connection String | The Azure Storage account connection string, if Path Type is Azure. |
|
| Google project ID | The Google Cloud Storage project ID, if Path Type is GCP. |
|
| Use Watching | Watch for new Cloud Storage objects matching the given path. Only available if Path Type is not Local. |
No |
| Use Authentication | Enable Kubernetes secret authentication. | No |
| Kubernetes Secret | The name of a Kubernetes secret to authenticate with a Cloud Storage. Only available if Use Authentication is enabled. |
|
| Use Certificates | Use a trust store of SSL certificates. | No |
| Trust Store | Location of default trust store of SSL certificates. Only available if Use Certificates is enabled. |
/opt/kx/ca-bundle.crt |
| Use Tenant | Use tenant for Kurl authentication, if Use Watching is enabled. |
No |
| Tenant | The authentication tenant, if applicable. Only available if Use Tenant is enabled. |
No |
Limitations
The reader may not handle parquet files which are larger then the total amount of memory or the size of the temporary Storage Directory. To handle such files, you can partition them into separate tabular datasets.
For details on configuring Amazon S3 Authentication, refer to Amazon S3 Authentication.
For details on configuring Azure Authentication, refer to Microsoft Azure Authentication.
For details on configuring Google Cloud Storage, refer to Google Cloud Storage Authentication.
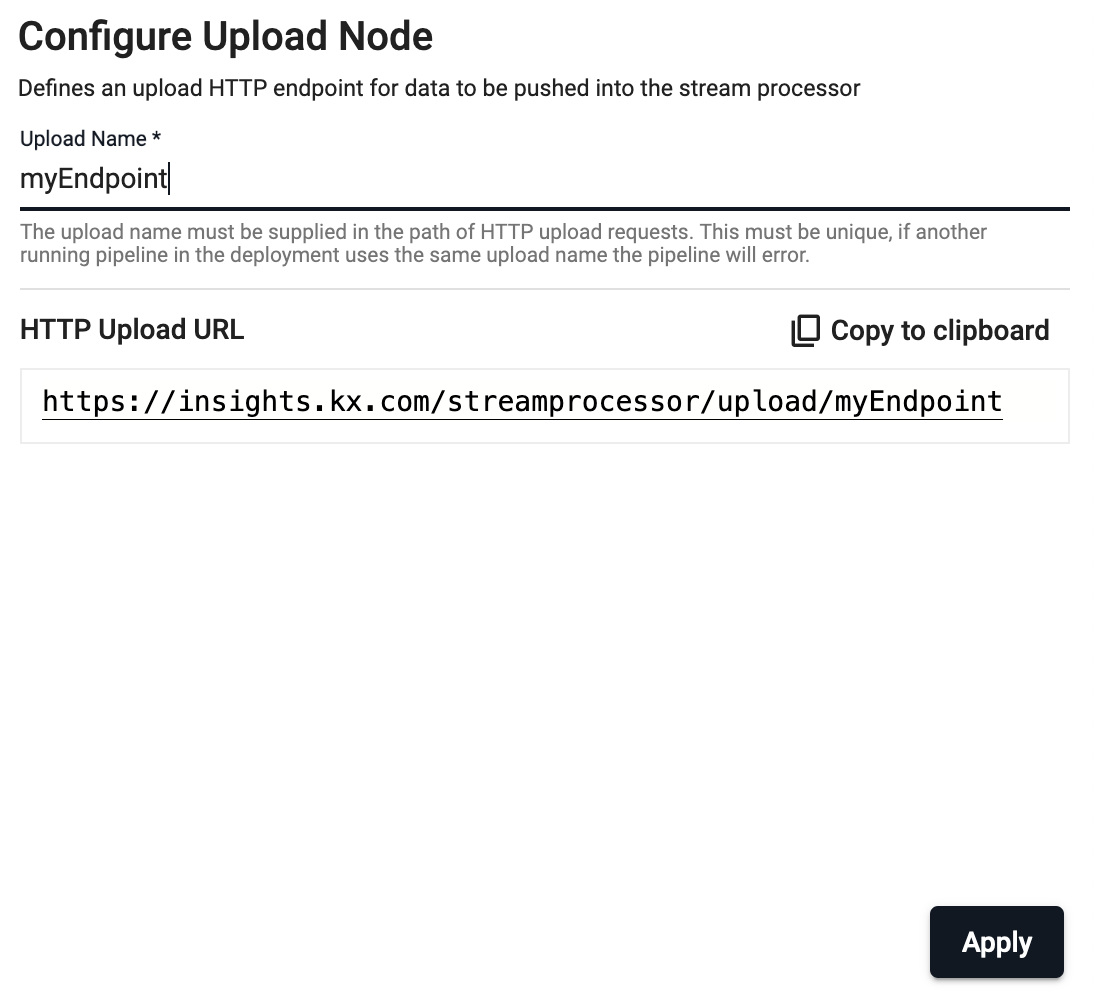
Upload
Reads data supplied through an HTTP endpoint.
Refer to the following APIs for more details
q API: .qsp.read.fromUpload •
Python API: kxi.sp.read.from_upload
Required Parameters:
| name | description | default |
|---|---|---|
| Endpoint Name | Unique name for this Upload node. This must be supplied in the path of HTTP upload requests. The fully qualified request path will be displayed once this is entered, e.g. https://insights.example.com/streamprocessor/upload/<Endpoint Name>. |
Required |
Example
Once the pipeline is deployed you can upload files using HTTP by editing the template curl command:
curl -X POST "https://insights.kx.com/streamprocessor/upload/{Endpoint Name}?table=z&finish=true" \
--header "Content-Type: application/octet-stream" \
--header "Authorization: Bearer $INSIGHTS_TOKEN" \
--data-binary "@my/file.csv"
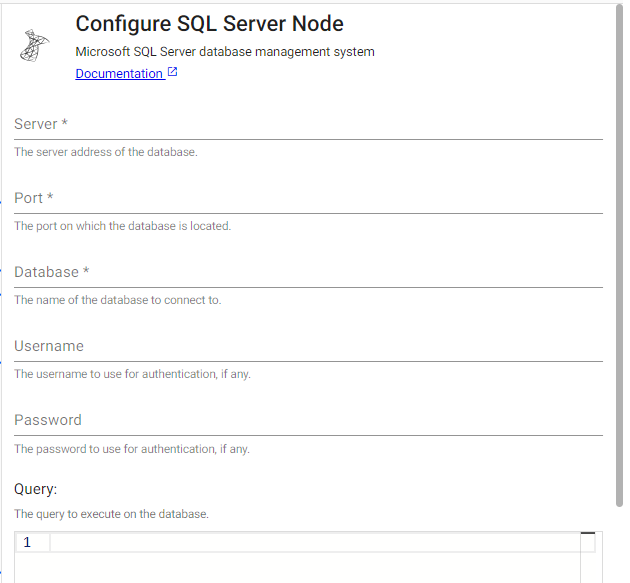
PostgreSQL
Execute a query on a PostgreSQL database.

Refer to the following APIs for more details
q API: .qsp.read.fromPostgres •
Python API: kxi.sp.read.from_postgres
Required Parameters:
| name | description | default |
|---|---|---|
| Server | The hostname of the database to issue a query against. | |
| Port | The port to use for connecting to the database server. | |
| Database | The name of the database to issue a query against in the target server. | |
| Query | An SQL query to issue against the target database for pulling data into the pipeline. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Username | The user account to use when establishing a connection to a PostgreSQL server. Note that if the username is provided, a password prompt will appear during deploy time. |
SQL Server
Execute a query on a SQL Server database.
Refer to the following APIs for more details
q API: .qsp.read.fromSQLServer •
Python API: kxi.sp.read.from_sql_server
Required Parameters:
| name | description | default |
|---|---|---|
| Server | The hostname of the database to issue a query against. | |
| Port | The port to use for connecting to the database server. | |
| Database | The name of the database to issue a query against in the target server. | |
| Query | An SQL query to issue against the target database for pulling data into the pipeline. |
Optional Parameters:
| name | description | default |
|---|---|---|
| Username | The user account to use when establishing a connection to a SQL server. Note that if the username is provided, a password prompt will appear during deploy time. |