Database configuration
A database configuration is a description of the structure of a data set, its life cycle, and the services that operate upon it. This description is used by kdb Insights services to self-configure and coordinate among themselves, and also provides room for user extension.
Database configuration is organized in an assembly file, a YAML configuration file for describing a logical shard of a database. An assembly has the following top-level structure:
name short name for this assembly (required) description purpose of the assembly (optional) labels user defined keys and values used for representing the purview of the assembly (optional) tables schemas for the tables operated upon within the assembly (dictionary) mounts mount points for stored data (dictionary) bus configuration of the message bus used for coordination between elements (dictionary) elements services that should run within the assembly, and any configuration they each require (dictionary)
This document focuses on the top level sections mentioned above. The components that typically would be under elements are described in respective documentation.
Deployment
To see a deployment example of data access processes with the other components of a database, see the Docker deployment example.
User interface configuration
This guide discusses configuration using YAML files. If you are using kdb Insights Enterprise, you can configure your system using the kdb Insights user interface
Example configuration
name: Trade data
labels:
region: amer
assetClass: fx
tables:
trade:
description: Trade data
type: partitioned
shards: 11
blockSize: 10000
prtnCol: realTime
primaryKeys: [sym, realTime]
sortColsOrd: sym
sortColsDisk: sym
columns:
- name: time
type: timespan
- name: sym
description: Symbol name
type: symbol
attrMem: grouped
attrDisk: parted
attrOrd: parted
- name: realTime
type: timestamp
- name: price
description: Trade price
type: float
- name: size
description: Trade size
type: long
quote:
description: Quote data
type: partitioned
shards: 11
blockSize: 10000
prtnCol: realTime
sortColsOrd: sym
sortColsDisk: sym
columns:
- name: time
type: timespan
- name: sym
description: Symbol name
type: symbol
attrMem: grouped
attrDisk: parted
attrOrd: parted
- name: realTime
type: timestamp
- name: bid
description: Bid price
type: float
- name: ask
description: Ask price
type: float
- name: bidSize
description: Big size
type: long
- name: askSize
description: Ask size
type: long
bus:
stream:
protocol: rt
topic: stream
mounts:
rdb:
type: stream
partition: none
baseURI: none
idb:
type: local
partition: ordinal
baseURI: file:///data/db/idb
hdb:
type: local
partition: date
baseURI: file:///data/db/hdb
elements:
dap:
instances:
rdb:
mountName: rdb
idb:
mountName: idb
hdb:
mountName: hdb
sm:
source: stream
tiers:
- name: rdb
mount: rdb
- name: idb
mount: idb
schedule:
freq: 0D00:10:00 # every 10 minutes
- name: hdb
mount: hdb
schedule:
freq: 1D00:00:00 # every day
snap: 01:35:00 # at 1:35 AM
retain:
time: 2 days
Labels
Database labels are metadata that are used to define correlations between different data split across multiple assemblies (shards). Labels are used during query routing to select specific subsets of a logical database. Labels appear in database tables as virtual columns
A database must have at least one label associated with it. Additionally, the combination of all assigned labels must be a unique set of values. Individual label values can be repeated, but the combination of all of them must be unique to the particular assembly.
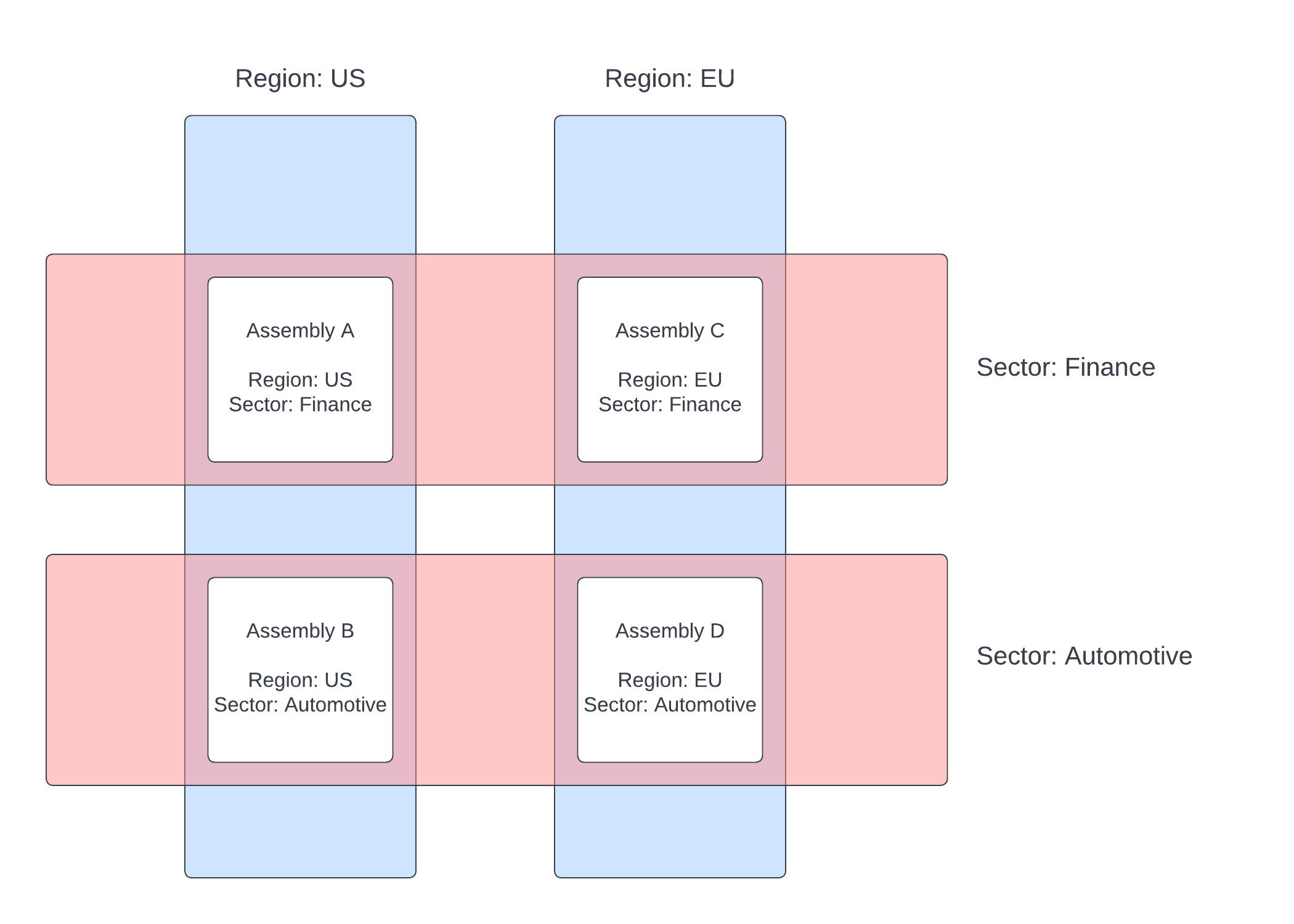
Labels example
This example illustrates the power of labels by splitting data across four assemblies, paring a region and a sector criteria across them.
# assembly-a.yaml
labels:
region: US
sector: Finance
# assembly-b.yaml
labels:
region: US
sector: Automotive
# assembly-c.yaml
labels:
region: EU
sector: Finance
# assembly-d.yaml
labels:
region: EU
sector: Automotive
These four assemblies make up one logical database. Queries can be issued across the assemblies using the sector or region label. An individual assembly can also be directly queried using a combination of labels. You can query across all assemblies by omitting labels from the query.
Labels in SQL
When issuing an SQL query, labels should be referenced with a label_ prefix. For example, the label region would be referenced as label_region in the query.
Tables
Table schemas describe the metadata and columns of tables within a given assembly. In order to distribute data across multiple assemblies, the tables in those assemblies must have a matching schema.
Mismatched schemas
If you have multiple assemblies with a table of the same name and you issue a query without labels selecting one or the other, you will get a mismatch error on your query. Table names are global to your install. Therefore, tables with the same name in different assemblies must all have the same schema.
See how to configure a schema and tables
Mounts
Assemblies store data in multiple places. The Storage Manager (SM) component migrates data between a hierarchy of tiers, each with its own locality, segmentation format, and rollover configuration. Other components might use entries in this section to coordinate other forms of data storage and access. The mounts section define the locations where data will be stored.
mounts:
rdb:
type: stream
partition: none
baseURI: none
idb:
type: local
partition: ordinal
baseURI: file:///data/db/idb
hdb:
type: local
partition: date
baseURI: file:///data/db/hdb
For each mount, the following fields can be configured.
| name | type | required | description |
|---|---|---|---|
type |
string | Yes | Indicates the type of this mount as one of stream, or local. See mount types below for more details. |
partition |
string | Yes | Indicates the partitioning scheme for this mount. This can be one of none, ordinal or date. See mount partitioning below for details. |
baseURI |
string | Yes | The location to store data on this mount. For stream mounts, this value must be set to none. For local mounts, this value should point to a file location where data for this mount will be stored. Each mount must have a unique baseURI for writing data. All directories under the baseURI path will be managed by the Storage Manager and are subject to change. The URI should be in the form of file:// followed by an absolute path to the data location. For example, file:///data/db/hdb. Note that the prefix is file:// and the path is /data/db/hdb leading to a triple ///. |
Mount types
Mounts can either be a stream mount or a local mount. Stream mounts are used for data in-flight and are always associated with a real-time tier. Stream tiers must have a partition and baseURI of none.
Local mounts are data that are co-located with the database and are available as part of a local file system. Local file systems must have a partition of either ordinal or date. The baseURI must point to a <mount_path>/<path> that is accessible by the database for writing. The location on this path will be managed by the Storage Manager. The same <mount_path> can be used by multiple mounts, but each mount must have a unique <path> within that mount for writing data.
Mount partitioning
Data on disk is organized into partitions to optimize for writedown or for querying. For local mounts, the method of partitioning can be configured to use a specific value of the data or can simply use the order that the data arrives. The table below outlines the possible partition configuration options.
| name | description |
|---|---|
none |
Disables partitioning and stores data in arrival order. |
ordinal |
This configuration stores data using a virtual numeric column that increments according to the tier's schedule. It is recommended that this partitioning mode is used for an IDB tier. Ordinal partitions are reset when data is rolled to the next tier. See below for an example of how ordinal partitioning is laid out on disk. |
date |
Date partitioning uses the timestamp column set in the schema's prtnCol setting to lay out data on disk by date. It is recommended that this partitioning mode is used for an HDB tier. See below for an example of date partitioning is laid out on disk. |
Partition example
To illustrate how data is laid out on disk, this example uses the configuration below to partition an IDB tier as ordinal partitioned and the HDB tier as date partitioned.
tables:
trade:
type: partitioned
prtnCol: time
columns:
- name: time
type: timestamp
- name: sym
type: symbol
- name: price
type: float
- name: size
type: long
mounts:
rdb:
type: stream
partition: none
idb:
type: local
partition: ordinal
baseURI: file:///data/db/idb
hdb:
type: local
partition: date
baseURI: file:///data/db/hdb
elements:
sm:
source: stream
tiers:
- name: rdb
mount: rdb
- name: idb
mount: idb
schedule:
freq: 0D00:10:00
- name: hdb
mount: hdb
schedule:
freq: 1D00:00:00
snap: 01:00:00
Ordinal partition example:
As data is migrated into the IDB, it will be partitioned on disk using an ordinal number until an EOD occurs. Each ordinal is an interval of data set by the tier's schedule value. Each time the interval triggers an EOI, a new ordinal is created and the data from the previous tier (typically RDB) will be migrated into a single ordinal.
In our example, we have a table called trade. After 3 EOIs, the IDB would have the following layout on disk. Each ordinal will have a 10 minute window of data because the IDB schedule is set to 10 minutes.
/data/db/idb
├── 0
│ └── trade
│ ├── price
│ ├── size
│ ├── sym
│ └── time
├── 1
│ └── trade
│ ├── price
│ ├── size
│ ├── sym
│ └── time
├── 2
│ └── trade
│ ├── price
│ ├── size
│ ├── sym
│ └── time
└── sym
Date partition example:
At the end of the day, data will migrate from the IDB to the HDB and change partitioning schemes. In this example, data will change from being ordinal partitioned to being date partitioned using the time column of our trade table. This will remove the data from the IDB and reset its ordinal partitioning. Data will now be in the HDB in the following format.
/data/db/hdb
├── 2023.01.01
│ └── trade
│ ├── price
│ ├── size
│ ├── sym
│ └── time
├── 2023.01.02
│ └── trade
│ ├── price
│ ├── size
│ ├── sym
│ └── time
├── 2023.01.03
│ └── trade
│ ├── price
│ ├── size
│ ├── sym
│ └── time
└── sym
Supported file systems
A mount points to a physical disk location that will hold the data in your database. This data is written by the Storage Manager and read by Data Access Processes. To facilitate high availability of data, data must be replicated between multiple nodes for redundancy. This requires a read-write-many configuration for the disk. There are a number of options for network-based file systems that facilitate this requirement.
Single node installs
For an install that is running on a single node, any file system that supports concurrent reads and writes can be used.
Network File Systems
Each of the supported cloud vendors have a version of a Network File System (NFS). This provides an easy-to-use option for getting a mount up and running. For more performance-critical workloads, it is recommended that a more tunable file system be selected.
- Amazon EFS
- Google Filestore
- Microsoft Azure Files
Rook Ceph
Rook is an open source, distributed storage system with a native Kubernetes operator for Ceph. kdb Insights Database supports the following Rook Ceph configurations with a replication of 3 requiring at least three worker nodes.
When using a host storage cluster configuration, Rook configures Ceph to store data directly on the host. This requires nodes with locally-attached SSD volumes.
This configuration provides the best performance. In order to achieve a higher level of resiliency, it is preferable to separate Rook nodes from application nodes. This can be done using labels, taints and tolerations. See Segregating Ceph from user applications.
Zapping devices
Some cloud service providers present locally attached SSDs with a pre-existing file system. In order to use these SSDs with Rook, the file system must be removed by zapping the device
When using a PVC cluster configuration, Ceph persistent data is stored on volumes requested from a storage class of your choice. The storage can be external to the nodes, providing increased volume resiliency at the cost of reduced performance.
Lustre
Lustre is another open source, distributed storage system. Unlike Rook Ceph, Lustre does not provide a default cloud storage class provisioner. Instead, vendor-specific options, such as AWS FSx for Lustre are available.
Using an FSx for Lustre storage provisioner creates new volumes with a root owner. Services in kdb Insights run as a nobody user by default, which will prevent components such as the kdb Insights Database from being able to write to the top-level directory of a mounted volume.
To use the Storage Manager in a Docker deployment with Lustre, ensure that the container is enabled to run as the root user.
services:
sm:
user: root
To use the Storage Manager in a Kubernetes deployment with Lustre, ensure that the pod securityContext and container securityContext enable it to run as root.
spec:
securityContext:
runAsNonRoot: false
containers:
- name: sm
securityContext:
runAsUser: 0
Root Squash
To limit access to operations of a pod running as root, it is recommended that root squash is enabled on the storage provisioner. To allow access for the nobody user, ensure that RootSquash users include 65534.
Bus
A data bus is a communication medium for data and control events to be processed by the database. Data buses are generally referred to as streams, but the terms stream and bus can be used interchangeably. Bus configuration is generally configured to use kdb Insights Reliable Transport, but custom interfaces are also supported. See the stream configuration page to configure the details of a bus.
The Storage Manager element must have a source stream configured for bi-directional communication. The database will use the configured bus for sending control events to issue EOIs, EODs, etc. The RDB tier will also use a stream parameter as its source for receiving data. These values must be configured to point at the same stream to have a deterministic sequence of events.
Elements
Assemblies compose a number of elements together to deploy a logical workload with streams, pipelines and databases. The elements key breaks down the configuration for each of these various pieces.
elements:
sm: {}
# ..
dap: {}
# ..
sp: {}
# ..
rt: {}
# ..
Storage configuration is located under an sm key. Query configuration is located under a dap key. Stream configuration is located under an rt key. And pipeline configuration is under an sp key.