Streams
A stream is the kdb Insights Enterprise deployment of a Reliable Transport (or RT) cluster. Streams come in two forms. Internal streams, which are required to process data between kdb Insights components within a deployment, and external streams, which connect an external data source to the database and provide highly available, high performance messaging.
In the kdb Insights Enterprise all data written to the database goes via the primary stream. External streams can be connected to a Stream Processor and transformed, or they can be directly connected to the database.
Configuration in YAML
This guide discusses how to configure a stream using the kdb Insights Enterprise user interface. Streams can also be configured using YAML configuration file. YAML configured streams can be deployed using the kdb Insights CLI
Managing streams
A single internal primary stream is created automatically when creating a new database. Simply create a new database via the component tree and navigate to the 'Stream Settings' tab.
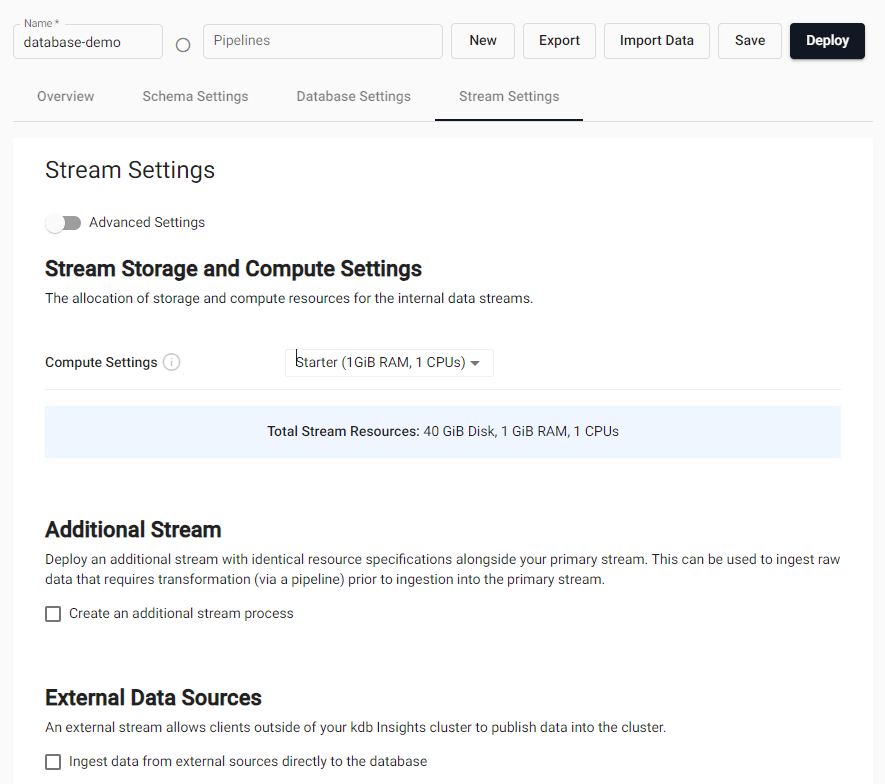
By default, the primary stream will be given the same name as the database within which it resides. This can be changed by toggling the Advanced Settings switch; a name field will appear. This name is required to be globally unique across all streams in all databases. This name is restricted to alpha numeric characters and dashes for name based data routing.
Once the stream has been configured, click the "Save" button to save the settings.
Stream compute
Streams are responsible for moving data between components within kdb Insights. They ensure a deterministic order of events from multiple producers in one unified log of the event sequence. The throughput and latency of the system is dependent on the compute resources allocated to a stream compared to how much data is moving through it. The compute resources for a stream allow you to tune your system for your desired throughput.
By default, the database streams are assigned the pre-configured Starter config as the compute setting. This can be changed to other configurations like Small, Medium, Large and Custom.
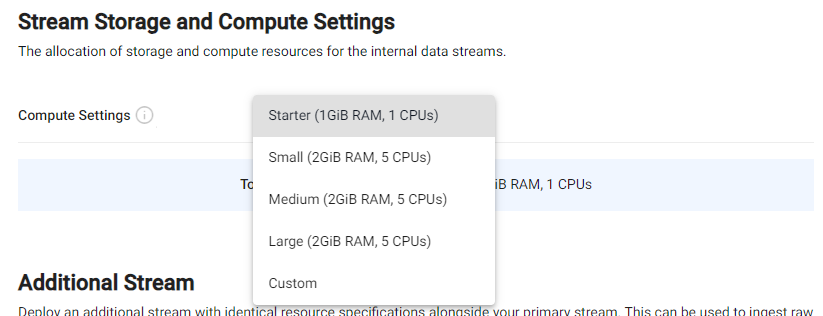
When the Custom compute setting is selected, the compute setting fields (CPU, Memory and Stream Size) become available for editing to your desired configuration.
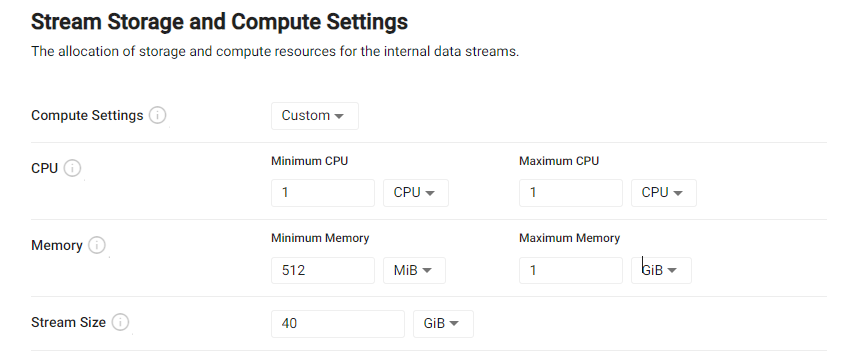
The grid below includes further details for these fields:
| name | description |
|---|---|
| Minimum CPU | The minimum amount of virtual CPU cycles to allocate to this stream. This value is measured in fractions of CPU cores which is either represented as mCPU for millicpu or just simply CPU for whole cores. You can express a half CPU as either 0.5 or as 500mCPU. |
| Maximum CPU | The limit of CPU available to for this stream to consume. During burst operations, this process may consume more than the limit for a short period of time. This is a best effort governance of the amount of compute used. |
| Minimum Memory | The minimum amount of RAM to reserve for this process. RAM is measured in bytes using multiples of 1024 (the iB suffix is used to denote 1024 byte multiples). If not enough memory is available on the current infrastructure, Kubernetes will trigger a scale up event on the install. |
| Maximum Memory | The maximum amount of RAM to reserve for this process. If the maximum RAM is consumed by this stream, it will be evicted and restarted to free up resources. |
| Stream Size | This is the amount of disk allocated to the stream to hold in-flight data. By default, this will hold 20GB. This should be tuned to hold enough data so that your system can recover from your maximum allowable downtime. For example, if your data was arriving at 1MB/s and you wanted to allow for a 2 hour recovery, you would need at least 120GB of disk space to hold those logs. |
Additional stream
If you require an additional stream to ingest raw data that requires transformation (via a pipeline) prior to ingestion into the database you can deploy an additional stream with identical resource specifications as the primary stream.
For example, a publishing client, such as a feedhandler, might send data in CSV or JSON format which needs to be decoded and have a schema applied before ingestion into the database.
To deploy an additional stream, click on the Create an additional stream process checkbox in the Additional Stream section.

Additional stream options
When checked there is an additional checkbox in the External Data Sources section, described below allowing this stream to be used by external sources.
Managing external streams
If you require data to be ingested into one of your streams (primary or additional) from outside the kdb Insights cluster using an external publishing client such as a feedhandler, you can choose to allow externally-facing ingress to a stream.
To allow ingestion of data from external sources to a stream, click on the checkbox relating to the appropriate stream in the External Data Sources section. Once checked, an additional configuration section for that stream will be visible where you can specify the external reference for the stream.

Additional stream checkbox
The additional stream checkbox will only be visible if the Create an additional stream process checkbox has been checked in the Additional Stream section see here.
The grid below includes further details for these two checkboxes:
| checkbox | relevant configuration section | description |
|---|---|---|
| Ingest data from external sources directly to the database | Stream Process | Data sent from external sources to he primary stream will be read by the database without any transformations being applied, therefore the data must be in a format the database can digest. |
| Ingest data from external sources to your additional stream | Additional Stream Process | Data sent from external sources to the additional stream can be transformed (via a pipeline) prior to ingestion into the database. |
External reference
If you choose to ingest data from external sources additional configuration is required to set an External Reference. This is then used as the SDK_CLIENT_UID configuration value by external clients to reference the stream for publishing from outside of the kdb Insights cluster.
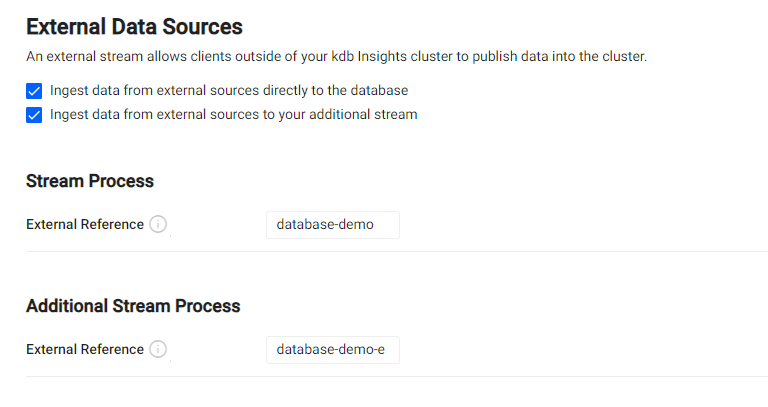
By default, the external reference to the streams will be initialized as follows:
- primary stream: database name
- additional stream: database name with a
-esuffix.
External reference
The external reference may only contain lower case alphanumeric characters, "-" or ".", and must start and end with an alphanumeric character.