Pipelines
A pipeline is a customizable data ingestion service. Open a Pipeline workspace from the Document bar or Perspective menu. Click-and-drag nodes from the left-hand entity tree into the central workspace. Select from readers, writers, functions, decoders and windows. Connect nodes together and configure each node's parameters to build the pipeline. Deploy, then explore the data. The video below demonstrates an example of a custom pipeline.
Set up
-
From the Document menu bar or Perspective icon menu on the left, open a pipeline.
-
Click-and-drag a node listed in the left-hand entity tree into the central workspace; for example, start with a Reader node.
Alternatively, quick start with Import
-
Build the pipeline by adding nodes to the workspace and joining them with the node-anchors. Nodes can be removed on a right-click, or added by click-and-drag from the entity tree, or a right-click in an empty part of the workspace. To change a connection, rollover to display the move icon and drag-connect, remove with a right-click. A successful pipeline requires a reader and writer node as a minimum.
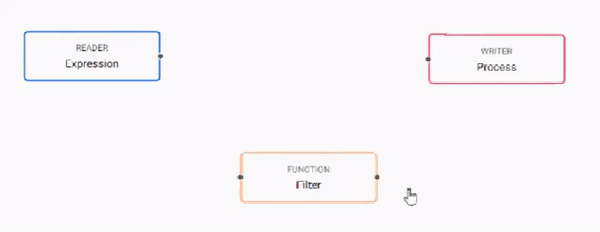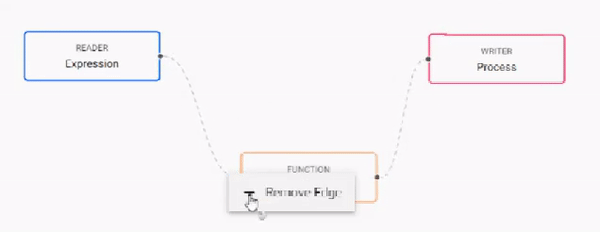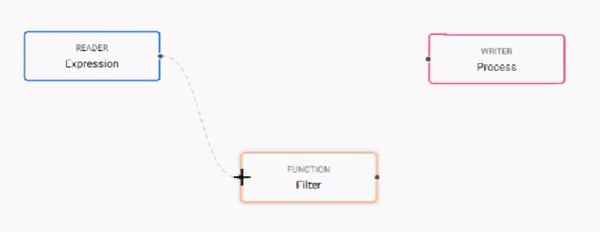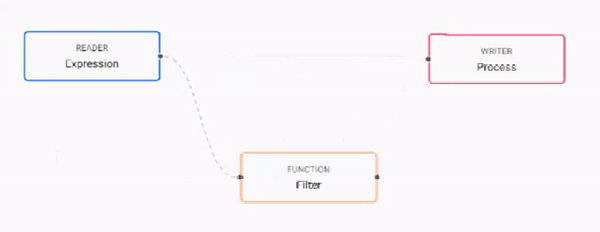
-
Configure each of the pipeline nodes; click-select to display node parameters in the panel on the right.
Example Pipeline
Reader Node: Expression
([] title:(`a`b`c); val:"j"$(3;2;3); header:(`$"header 1";`$"header 2";`$"header 3") )Function Node: Filter
// To filter in a Filter node {[data] `a = data`title }Writer Node: Process
- Mode: Upsert to table
- Handle: :insights-gui-data:6812
- Table: demotable
:in theHandlepropertyEnsure the
:is included before theinsightsin theHandleproperty; i.e.:insights-gui-data:6812 -
Click
Saveto save the pipeline;Deployto execute. -
Data from a successfully deployed pipeline can then be explored; open an Explore workspace in the Document menu bar from the "+" menu, or from the perspective icon bar on the left.
Set up
In order to use Kafka and Postgres pipelines, relevant charts must be installed, running, and accessible on the cluster. To install, refer to installation instructions.
Lower Case required
When configuring pipelines, lower case should be used in all instances of names and references.
Menu
Deploy
Execute the pipeline
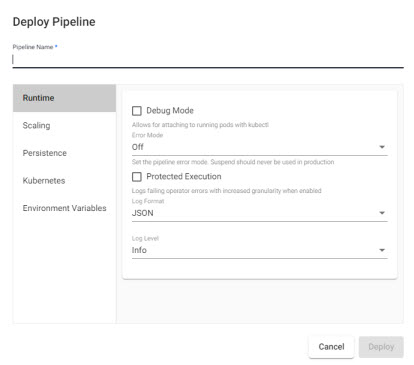
- Pipeline Name
- Name of pipeline. Pipelines names should be lowercase, alphanumeric with hyphens, and less than 40 characters.
Runtime
| item | description |
|---|---|
| Debug Mode | Enable facility to debug pipeline. |
| Error Mode | Select between Off, Suspend or Dump Stack. Don't use Suspend in a Production Environment. |
| Protected Execution | Enabled for greater granularity in error reporting. When enabled, operating performance may be impacted. |
| Log Format | Define debug reporting format; select between JSON or Text formats. |
| Log Level | Select between Info, Trace, Debug, Warning, Error or Fatal. |
Scaling
- Minimum number of Workers
- Maximum number of Workers
- Define the minimum and maximum number of pipeline workers that can be created to run this pipeline. Default Minimum number of Workers as
1, Maximum number of Workers as10. - Maximum number of Worker Threads
- Current maximum limit is 16.
Persistence
Configure a custom image for different SP cluster components.
Controller
Kubernetes persistence configuration.
| item | description |
|---|---|
| Disabled | Enabled by default, click to disable. |
| Storage Class | Kubernetes storage class name; e.g. standard. |
| Storage Size | Size volume allocated to each controller; defaults to 20Gi. |
| Checkpoint Frequency | Check frequency in milliseconds, defaults to 5,000. |
Storage Class
Ensure Storage Class is set to a valid class. This is defined in the cluster and may be different across cloud providers i.e. GCP: standard, AWS: gp2, Azure: default. This information can be retrieved by running:
kubectl get storageclassWorker
Kubernetes persistence configuration.
| item | description |
|---|---|
| Disabled | Enabled by default, click to disable. |
| Storage Class | Kubernetes storage class name; e.g. standard. |
| Storage Size | Size volume allocated to each Worker; defaults to 20Gi. |
| Checkpoint Frequency | Check frequency in milliseconds, defaults to 5,000. |
Kubernetes
- Label
- Add a label and value to created resources.
- Image Pull Secrets
- Add Kubernetes secret reference name; for example,
kx-access
Environment Variables
- Variable
- Value
- Add listed variable and values.
For more information on Kubernetes configuration.
Save
Save the pipeline.
Monitor
A read-only view of the pipeline
Edit
Unlocks the pipeline workspace for changes.
Options
| icon | function |
|---|---|
 |
Reset view |
 |
Automatically layout pipeline |
Configuration
Right-hand-panel contains details of the selected node
Nodes
Click-and-drag nodes from the left-hand entity tree into the Pipeline workspace.
Readers
Choose from cloud, file or relational services. Data can be collated from more than one source using multiple reader nodes.
- Click to edit
- Right-click to remove
Callback
Defines a callback in the q global namespace.

- Callback
- The name of the callback function to be defined.
Expression
Runs a kdb+ expression

- Expr
- q expression.
Google Cloud Storage
Read data from Google Cloud Storage
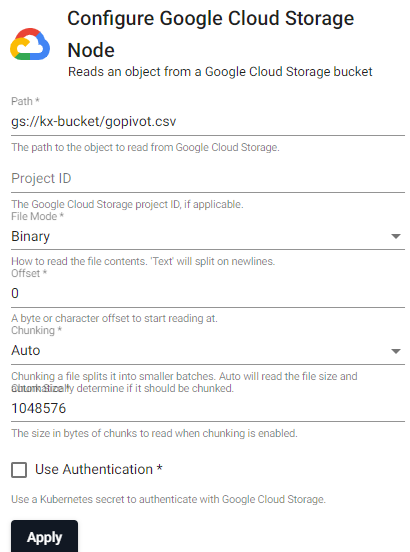
| item | description |
|---|---|
| Path | The path of an object to read from Google Storage, e.g. gs://bucketname/filename.csv |
| Project ID | Google Cloud Storage Project ID, if applicable. |
| File Mode | The file read mode. Setting the file mode to binary will read content as a byte vector. When reading a file as text, data will be read as strings and be split on newlines. Each string vector represents a single line. |
| Offset | A byte or character offset to start reading at. Set at 0. |
| Chunking | Splits file into smaller batches. Auto will read file size and determine if it should be chunked. |
| Chunk Size | File size of chunks when chunking is enabled. |
| Use Authentication | Enable Kubernetes secret authentication. |
| Kubernetes Secret | The name of a Kubernetes secret to authenticate with Google Cloud Storage. |
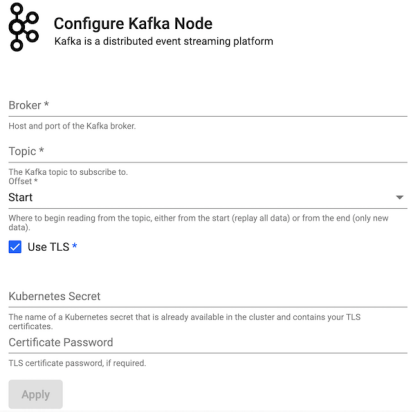
Kafka
Consume data from a Kafka topic. Publish data on a Kafka topic. Kafka is a distributed event streaming platform. A Kafka writer will publish data to a Kafka broker which can then be consumed by any downstream listeners. All data published to Kafka must be encoded as either strings or serialized as bytes. If data reaches the Kafka writer that is not encoded, it is converted to q IPC serialization representation.
| item | description |
|---|---|
| Brokers | Location of the Kafka broker as host:port. |
| Topic | The name of the Kafka topic. |
| Offset | Read data from the Start of the Topic; i.e. all data, or the End; i.e. new data only. |
| Use TLS | Enable TLS. |
| Kubernetes Secret | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. |
| Certificate Password | TLS certificate password, if required. |
Postgres
Execute query on a PostgreSQL database. PostgreSQL is an open-source relational database management system.
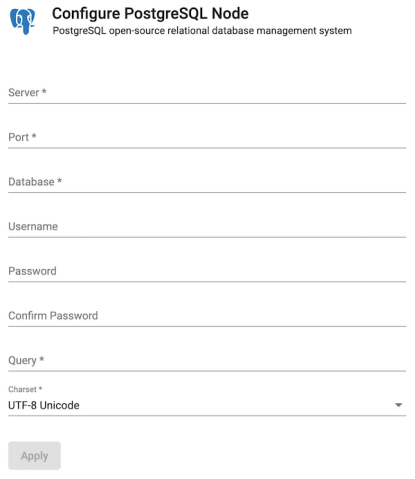
| item | description |
|---|---|
| Server | Define connection details; for example, postgresql.db.svc. |
| Port | Connection Port. |
| Database | Database name. |
| Username | User access to database. |
| Password | User password to database. |
| Confirm Password | Required authentication and confirmation. |
| Query | SQL query; for example, select * from datasourcename. |
| Charset | Defaults to UTF-8 Unicode. |
KX Insights Stream
Reads data from a KX Insights Stream.

| item | description |
|---|---|
| Topic | Topic name. |
| Index | Set replay position in the stream to replay from; default is 0. |
Amazon S3
Read data from Amazon Simple Storage Service.

| item | description |
|---|---|
| Path | The path of an object to read from S3, e.g., s3://bucket/file.csv. |
| Region | The region of the AWS S3 bucket. |
| File Mode | The file read mode. Setting the file mode to binary will read content as a byte vector. When reading a file as text, data will be read as strings and be split on newlines. Each string vector represents a single line. |
| Offset | A byte or character offset to start reading at. Set at 0. |
| Chunking | Splits file into smaller batches. Auto will read file size and determine if it should be chunked. |
| Chunk Size | File size of chunks when chunking is enabled. |
| Use Authentication | Enable Kubernetes secret authentication. |
| Kubernetes Secret | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. |
Amazon S3 Authentication
To access private buckets or files, a Kubernetes secret needs to be created that contains valid AWS credentials. This secret needs to be created in the same namespace as the KX Insights Platform install. The name of that secret is then used in the Kubernetes Secret field when configuring the Amazon S3 reader.
To create a Kubernetes secret containing AWS credentials:
kubectl create secret generic --from-file=credentials=<path/to/.aws/credentials> <secret-name>Where
Note that this only needs to be done once, and each subsequent usage of the Amazon S3 reader can re-use the same Kubernetes secret.
SQL Server
Read data from Microsoft SQL Server database management system.
| item | description |
|---|---|
| Server | Server host address. |
| Port | Connection Port. |
| Database | Database name. |
| Username | User access to database. |
| Password | User password to database. |
| Confirm Password | Required authentication and confirmation. |
Writers
Console
Writes events to the kdb+ console. Can be used for simple streams running on a local deployment. By default, all vectors (lists of the same type) are printed on a single line. By enabling the Split Lists option, vectors will be printed on separate lines. Lists of mixed type are always printed on separate lines.
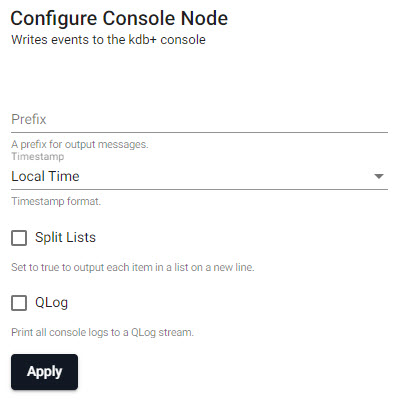
| item | description |
|---|---|
| Prefix | A string for output messages. |
| Timestamp | Choose between Local Time, UTC, No Timestamp or empty for no timestamp. |
| Split Lists | When enabled, each item in a list appears on a new line. |
| QLog | When enabled, prints all console logs to a QLog stream. |
Kafka
Publish data on a Kafka topic. Kafka is a distributed event streaming platform. A Kafka producer will publish data to a Kafka broker which can then be consumed by any downstream listeners. All data published to Kafka must be encoded as either strings or serialized as bytes. If data reaches the Kafka publish point that is not encoded, it is converted to q IPC serialization representation.
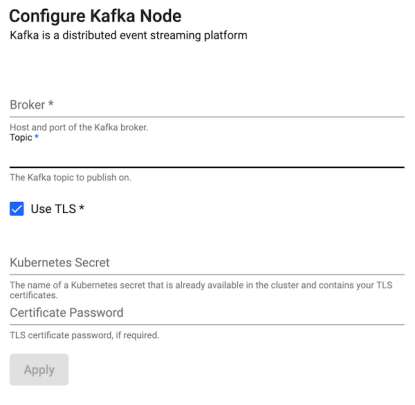
| item | description |
|---|---|
| Brokers | Define Kafka connection details as host:port information - for example: localhost:9092. |
| Topic | The name of the Kafka data service to publish on. |
| Use TLS | Enable TLS. |
| Kubernetes Secret | The name of a Kubernetes secret that is already available in the cluster and contains your TLS certificates. |
| Certificate Password | TLS certificate password, if required. |
Process
Writes events to another kdb+ process, publishes data to a table or invokes a function with that data.
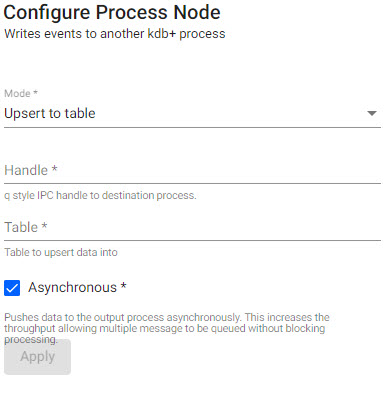
| item | description |
|---|---|
| Mode | Select between Upsert to table or Call function. |
| Handle | q style IPC Handle to destination process, includes port details to write to. |
| Table | The name of table to upsert data to for further exploration. |
| Asynchronous | When enabled, push to the output process asynchronously. This increases the throughput allowing multiple messages to be queued without blocking processing. |
KX Insights Stream
Writes events to a KX Insights stream.

| item | description |
|---|---|
| Topic | Topic name mapped-to from published tickerplant, writes data conforming to the standard RT API. |
| Prefix | A prefix to identify the Sequencer the topic belongs to. This should match the topicPrefix of the Sequencer from the Insights assembly configuration. |
Functions
Functions for transforming data in a streaming process pipeline.
Apply
Applies a function to incoming data. Useful for asynchronous operations. Data returned by it does not immediately flow through the rest of the pipeline. Instead, the provided function must use .qsp.push to push data through the pipeline when ready.
- Editor
- Code Editor
Example:
// @param data {any} data from the previous node
// @return {any} data to pass to the next node
Filter
Filter elements out of a batch, or a batch from a stream. The filter is a unary function returning a boolean atom or vector, either filters elements out of a batch, or filter out a batch in its entirety from a stream.
- Editor
- Code Editor
Example:
// @param data {any} data from the previous node
// @return {any} data to pass to the next node
{ `trade ~ first x }Map
Maps data from one value to another while preserving shape. The provided function is given the current batch of data as the first parameter and expected to return data.
- Editor
- Code Editor
Example:
// @param data {any} data
// @return {boolean | boolean[]} records to keep
{ update price * size from x }Merge
Merge can be used to join and enrich streams with other streams, with static data, or to union two streams into a single stream.
- Editor
- Code Editor
Example
// We can use `lj` to merge streams if the right stream contains a keyed common column with the left stream.
lj| item | description |
|---|---|
| Flush | Indicates which side of the union to flush data from; select between Left, Right, Both or None. |
| Trigger | Indicates when the current join data should be emitted; select between Immediately when either stream gets data, When left stream gets data, When right stream gets data, or When both have data. |
Split
Splits a stream into multiple streams for running separate analytics or processing.
SQL
Perform an SQL query [query]
Where
queryis a SQL query, performs it on table data in the stream.
Queries must
- conform to ANSI SQL and are limited to the documented supported operations
- reference a special $1 alias in place of the table name
- Editor
- Code Editor
Example:
select date, avg(price) from $1 group by dateUnion
Unions multiple streams into a single stream. Similar to a join, with the difference that elements from both sides of the union are left as-is, resulting in a single stream.

| item | description |
|---|---|
| Flush | Indicates which side of the union to flush data from; select between Left, Right, Both or None. |
| Trigger | Indicates when the current join data should be emitted; select between Immediately when either stream gets data, When left stream gets data, When right stream gets data, or When both have data. |
Decoders
Decode data formats into kdb.
CSV
Parse CSV data to a table.
| item | description |
|---|---|
| Delimiter | Field separator for the records; default to ,. |
| Header | Defines whether source CSV file has a header row; default to Always, alternatives are First Row and Never. |
| Schema | Schema of output data. A list of types to cast the data to as q type characters. |
Schema example
"SS*ip"
- See Column Types for more information.
JSON
Decodes JSON Content.
- Decode Each
- When enabled, parsing is done by each value
JSON schema
The JSON decoder expects to receive a JSON string that defines an array of objects that contain <column name>: <value> pairs, e.g. [{column1: 1, column2: 1}, {column1: 2, column2: 2 }]
Protocol Buffers
Decodes Protocol Buffer encoded data.
| item | description |
|---|---|
| Message Name | Name of the Protocol Buffer message object to use for decoding objects |
| Message Definition | The definition of the Protocol Buffer message format to decode. |
| Includes Fields | When enabled, the output will include field names and values |
Definition Example
"Person { string name = 1; int32 id = 2; string email = 3; }"
Encoders
Converts data to the following formats.
JSON
Batches default to a single JSON Object
- Split
- When enabled, split encodes each value in a given batch separately. When the input is a table, Split will encode each row as its own JSON object
Protocol Buffers
| item | description |
|---|---|
| Message Name | Name of the Protocol Buffer message object to use for encoding objects |
| Message Definition | The definition of the Protocol Buffer message format to encode. |
| Payload Type | Select between Automatic, Table, Dictionary, List, or Lists. Indicates the message payload to pass into the stream. Used to optimize data shape when known. Defaults to Automatic, but Payload Type should be set if data shape is known. |
Windows
Aggregates streams based on event or system time.
Count Window
Splits the stream into evenly sized windows
| item | description |
|---|---|
| Size | The number of records in each window |
| Frequency | The number of records between the starts of consecutive window |
Global Window
Global windows aggregate until the custom trigger fires
| item | description |
|---|---|
| Trigger | A function that returns the indices to split the buffer on |
| Mixed Schemas | Set to true to allow batches to have different schemas |
Sliding
Aggregates the stream using event time over a given period and duration. Stream aggregation can result in overlapping windows depending on applied event times. A window is triggered when a timestamp is encountered past the end of that window. After that, subsequent events with a timestamp within that window will be discarded.
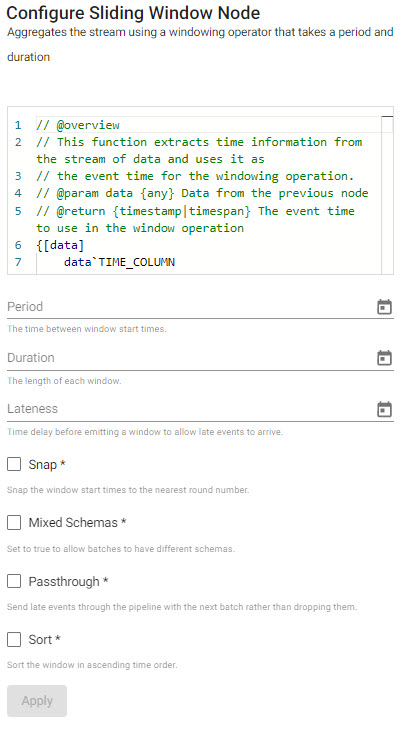
| item | description |
|---|---|
| Editor | Define Time Assigner Function; a function to extract a vector of event times from a batch. It must return a list of timestamps, e.g. "{x`time}" |
| Period | The time between window start times (time period; e.g. 0D00:00:05). |
| Duration | How much data should be contained in each window (time period; e.g. 0D00:00:10). |
| Lateness | How far past the end of a window the watermark goes before the window is finalized and emitted. Defaults to 0D00:00:00. A new timestamp will trigger when the timestamp exceeds the sum of the start time, window duration and lateness. |
| Snap | When enabled, snaps the window start time to the nearest round number. |
| Mixed Schemas | When enabled, allows batches to have different schemas (or allow non-table batches). Throughput is higher if batches are tables rather than a list of tuples, and higher again if all tables share the same schema. |
| Passthrough | When enabled, will send late events through the pipeline with the next batch rather than dropping them. |
| Sort | Sort records in ascending order by timestamp when enabled. Example "A Period of 5 seconds and a Duration of 10 seconds will trigger a window every 5 seconds, containing the previous 10 seconds of data." |
Period and Duration settings
If the Period and Duration time settings are equivalent, then the result is tumbling windows. If the Duration is longer than the Period, the result is overlapping windows. If the Period is longer than the Duration, the result is hopping windows.
Timer
Aggregates the stream by processing time; fires by time period or when record buffer is exceeded. Timer windows aggregate the stream by processing time, with much less overhead than other windowing operations. Any data in the buffer will be emitted each period. As event time is ignored, data will not be dropped for being late. Because these windows ignore event time, this will work on streams that do not have event times. Due to variance in when the timer fires, window durations may not be exactly equal, as is the case for sliding and tumbling windows.
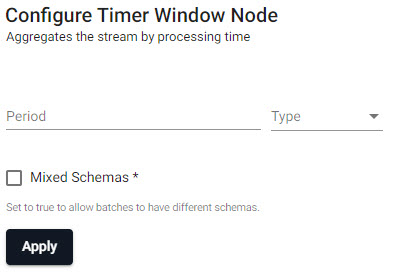
| item | description |
|---|---|
| Period | How often the window should fire (time period; e.g. 0D00:00:05). |
| Mixed Schemas | When enabled, allows batches to have different schemas (or allow non-table batches). Throughput is higher if batches are tables rather than a list of tuples, and higher again if all tables share the same schema. |
Tumbling
Aggregates the stream using non-overlapping windows based on event time. A window is triggered when a timestamp is encountered past the end of that window. After that, subsequent events with a timestamp within that window will be discarded.
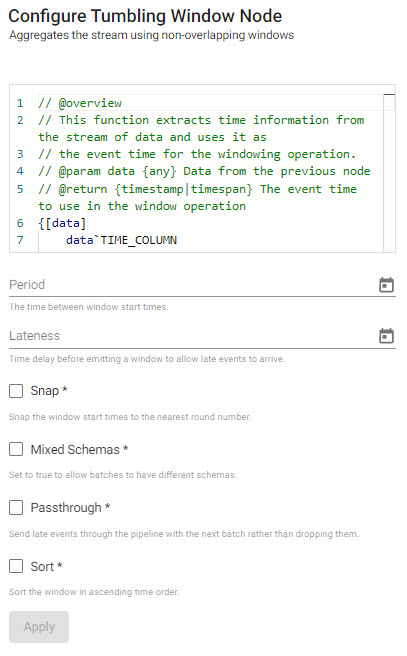
| item | description |
|---|---|
| Editor | Define Time Assigner Function; a function to extract a vector of event times from a batch. It must return a list of timestamps, example "{x`time}". |
| Period | The time between window start times (time period; e.g. 0D00:00:05). |
| Lateness | How far past the end of a window the watermark goes before the window is finalized and emitted. Defaults to 0D00:00:00. A new timestamp will trigger when the timestamp exceeds the sum of the start time, window duration and lateness. |
| Snap | When enabled, snaps the window start time to the nearest round number. |
| Mixed Schemas | When enabled, allows batches to have different schemas (or allow non-table batches). |
| Passthrough | When enabled, will send late events through the pipeline with the next batch rather than dropping them. |
| Sort | Sort records in ascending order by timestamp when enabled. |
Global
Aggregates the stream until the custom trigger fires.
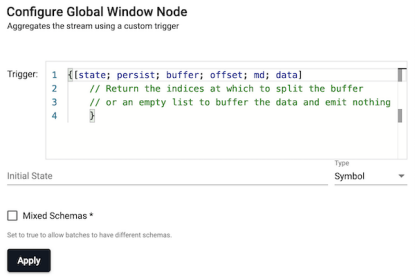
| item | description |
|---|---|
| Trigger | A function that returns the indices to split the buffer on. |
| Initial State | The initial state that is passed to the trigger function. |
| Mixed Schemas | When enabled, allows batches to have different schemas (or allow non-table batches). Throughput is higher if batches are tables rather than a list of tuples, and higher again if all tables share the same schema. |
The trigger is a function that takes a number of parameters:
- State
- A function to persist state
- The buffered records
- An offset of where the current batch starts
- The current batch's metadata
- Current batch's data
As batches are ingested, the trigger function will be applied to the batch, and data will be buffered. However, the buffering behavior will depend on the output of the trigger function:
- If the trigger function returns an empty list, the incoming batch will be buffered and nothing will be emitted.
- If the trigger function returns numbers, the buffer will be split on those indices, with each index being the start of a new window.
Last data batch
The last list will remain in the buffer. This last list can be emitted by returning the count of the buffer as the last index. To map indices in the current batch to indices in the buffer, add the offset parameter to the indices.
The buffered records cannot be modified from the trigger function.
Batches with mixed schemas are only supported when using the Mixed Schema option.
Caveat when using Mixed Schemas
When this is set, the buffer passed to the trigger will be a list of batches, rather than a single table. The indices returned by the trigger function will still work as though the buffer were a single list.
The trigger function is passed state, which is initially defined by setting theinitialState parameter, and can be modified by passing the new value to the persist function.
Time Assigner Function
A time assigner function's arguments are the message’s data, and the function is expected to return a list of timestamps with a value for every record in data.