Database settings¶
This page describes the configuration options available under the Database Settings tab in the kdb Insights Enterprise Web Interface.
The following settings are configurable:
- Encryption - Encrypt or decrypt your database.
- Description - Add a short description for the database. This is optional but recommended as this data is returned by the getMeta API.
- Database Labels - Define correlations between different data split across multiple databases.
- Query Settings - Configure how data is queried from the system.
- Writedown Settings - Configure how data is stored in the system.
- Packages - Add custom code to a database.
Access Database Settings¶
The Database Settings tab is displayed when you create a new database or open an existing database by selecting it from the left-hand menu and clicking on the Database Settings tab.
The following screenshot shows all the options available. Note that the Advanced Settings are not shown by default.

Configuration using the CLI
Databases can also be configured using packages. Package-configured databases can be deployed using the kdb Insights CLI.
Encryption¶
Data at rest encryption (DARE) is enabled by default on new deployments in version 1.11 or later of kdb Insights Enterprise. Refer to Data at rest encryption (DARE) for details on how DARE is setup.
The current encryption status of your database is displayed, as an icon, beside the database name at the top of the Databases screen. The icon values are:
- Encrypted (shown below)
- Not Encrypted
- Encryption in progress
- Decryption in progress
- Encryption status is only available when the database is deployed
![]()
You can use the Encryption toggle to:
Encrypt a database¶
To enable data at rest encryption (DARE) on a database:
- Make sure the database is inactive. If it is not then you must tear it down.
- Click on the Database Settings tab and toggle Encryption to On.
-
A checklist and confirmation screen is displayed.
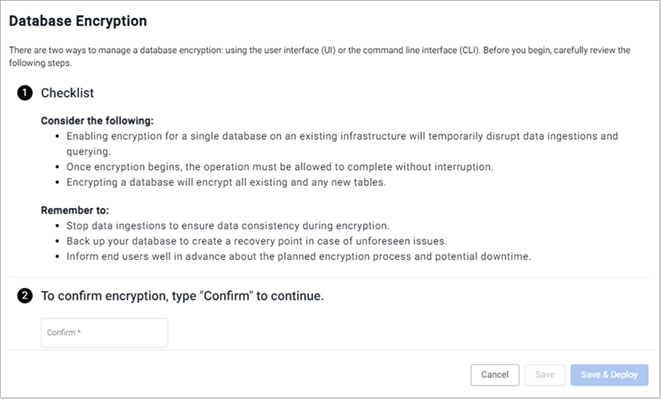
This advises you to:
Consider the following:
- Enabling encryption for a single database on an existing infrastructure temporarily disrupts data ingestions and querying.
- Once encryption begins, the operation must be allowed to complete without interruption.
- Encrypting a database encrypts all existing and any new tables.
Remember to:
- Stop data ingestions to ensure data consistency during encryption.
- Back up your database to create a recovery point in case of unforseen issues.
- Inform end users well in advance about the planned encryption process and potential downtime.
Review the checklist and take appropriate actions. Refer to the considerations section for more details.
-
When you are ready to proceed enter Confirm and click Save and Deploy. Encryption only starts when you deploy the database so if you click Save you have to then click Deploy to start the encryption.
Once you deploy a database to enable DARE, the encryption process starts immediately.
Error. No existing secret found for encryption. Please set an encryption secret and retry
The encryption secret contains the encryption key. For details on setting up an encryption key, refer to Encryption secret.
-
A progress indicator appears at the top of the screen and displays the number of tables that have been encrypted and the amount of time remaining.

Learn More
Clicking Learn More displays the notification that Database encryption is in progress. All data ingestions and querying are temporarily paused to maintain data consistency. Access to viewing and browsing remains available while editing and querying functions are disabled.
The progress indicator is not displayed if the encryption happens very quickly
Decrypt a database¶
To decrypt an encrypted database:
- Make sure the database is inactive. If it is not then you must tear it down.
- Click on the Database Settings tab and toggle Encryption to Off.
-
A Database Decryption screen is displayed with a checklist for you to review and take appropriate actions before proceeding.
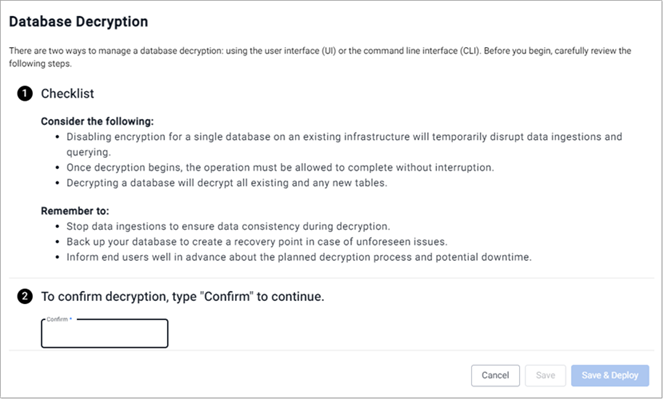
This advises you to:
Consider the following:
- Disabling encryption for a single database on an existing infrastructure temporarily disrupts data ingestions and querying.
- Once decryption begins, the operation must be allowed to complete without interruption.
- Decrypting a database decrypts all existing and any new tables
Remember to:
- Stop data ingestions to ensure data consistency during decryption.
- Back up your database to create a recovery point in case of unforseen issues.
- Inform end users well in advance about the planned decryption process and potential downtime.
-
Once you are ready to proceed enter Confirm and click Save and Deploy.
-
A progress indicator appears at the top of the screen and displays the number of tables that have been decrypted and the amount of time remaining.

Learn More
Clicking Learn More, on the progress indicator, displays the notification that Database decryption is in progress. All data ingestions and querying are temporarily paused to maintain data consistency. Access to viewing and browsing remains available while editing and querying functions are disabled.
The progress indicator is not displayed if the decryption happens very quickly
Database Labels¶
Database labels are metadata that are used to define correlations between different data split across multiple packages (shards). Labels are used during query routing to select specific subsets of a logical database. Labels appear in database tables as virtual columns

A database must have at least one label associated with it. Additionally, the combination of all assigned labels must be a unique set of values. Individual label values can be repeated, but the combination of labels must be unique to the particular database.
To add labels, click Add Label. Each label has the following properties:
- Label Name - When creating a new database a default Label Name of kxname is provided which maps to the database name. You may enter a new value for additional labels.
- Value - the label value.
Labels in SQL
When issuing a SQL query, labels must be referenced with a label_ prefix. For example, the label region is referenced as label_region in a SQL query.
Labels example¶
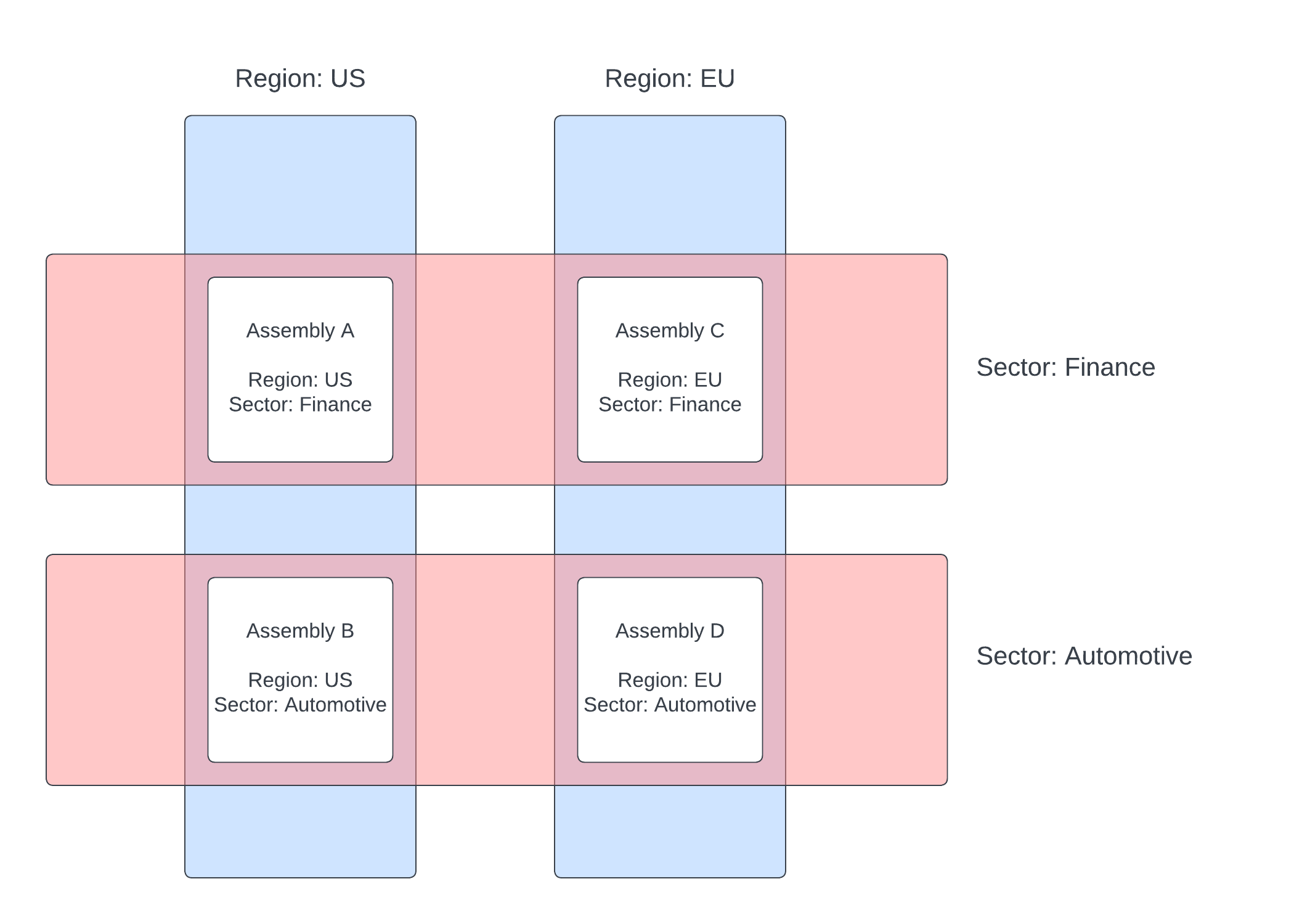
This example illustrates the power of labels by splitting data across two regions and two sectors, resulting in four packages:
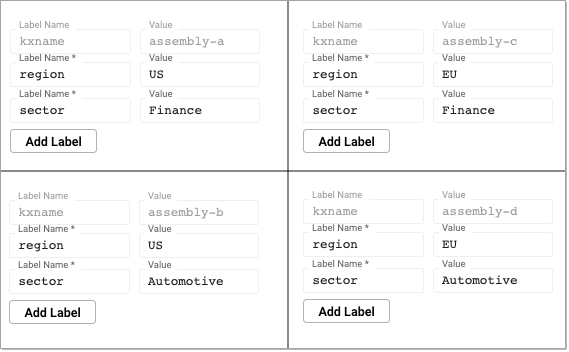
These four packages make up one logical database. Queries can be issued across the databases using the sector or region label. An individual database can also be directly queried using a combination of labels. You can query across all databases by omitting labels from the query. The kxname label can be used to target a specific database.
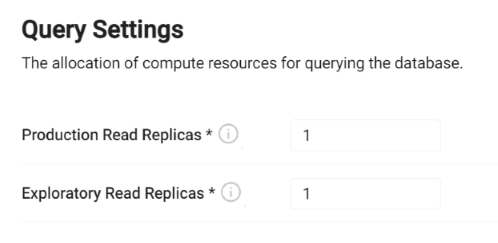
Query settings¶
Query settings configure how data is queried from the system. This configuration determines how much redundancy is provided to query environments in the system.
| Name | Description |
|---|---|
| Production Read Replicas | This is the total number of production data access instances that are to be launched. For testing purposes, a count of 1 is sufficient. When running in a production cluster, the number of replicas must be increased to match the desired amount of availability. Use a minimum of 3 replicas when running in a production configuration to achieve redundant replication. By default, production replicas only serve the getData API. To enable SQL queries, see the SQL support guide. |
| Exploratory Read Replicas | This is the number of available query instances for running experimental queries in an explore session. By default, these read replicas have SQL support enabled and allow a high degree of freedom of queries. This value must be configured to reflect the desired availability for exploratory queries within the system. |
Read replicas disabled
The message Exploratory read replicas used for querying are disabled. Changes to these settings will not take effect until it is enabled is displayed when Query Environments are disabled. Refer to System Information to check the status and Query Environments for details about enabling them.
Query size limitations¶
| Method | Limit | Streaming | Compression | Notes |
|---|---|---|---|---|
| SQL Queries | No Limit | Yes, if response exceeds KXI_SG_STREAM_THRESHOLD |
No | No size limitation when routing through the Service Gateway. |
| User Defined Analytics (UDAs) | No Limit | Yes, if response exceeds KXI_SG_STREAM_THRESHOLD |
No | No size limitation when routing through the Service Gateway. |
getData APIs |
No Limit | Yes, if response exceeds KXI_SG_STREAM_THRESHOLD |
No | No size limitation when routing through the Service Gateway. |
| RESTful Queries | No Limit | No | No | Results are not streamed and are uncompressed. |
| QSQL Queries | No Limit | Yes, if response exceeds KXI_SG_STREAM_THRESHOLD |
No | Direct queries to a database are not limited. |
| Service Gateway Queries | No Limit | Yes, if response exceeds KXI_SG_STREAM_THRESHOLD |
No | JSON responses are uncompressed. |
The Service Gateway supports returning JSON responses in a streaming fashion over HTTP without compressing the result. This reduces the RAM needed by the Service Gateway to handle larger payloads. The environment variable KXI_SG_STREAM_THRESHOLD configures the chunk size for splitting the overall response. This capability is automatic in the Service Gateway and does not require any configuration.
Environment Variables¶
To configure the environment variables defined in the query processes during startup:
-
Click Add Variable and complete the key-value pair, where the key is the name of a variable and the value is the desired setting.
- Query Setting: Refer to Data access process environment variable list for the complete list of options.
Writedown settings¶
Writedown settings configure how data is stored in the system. Database writedown receives data from an incoming stream and stores it in a tier. For high availability, replicas can be used for redundant writedown processes.
The writedown settings shown below are described in the following sections.
Writedown settings¶
The writedown settings are displayed as shown below, and described in the following table.

| Name | Description |
|---|---|
| EOD Parallelization Type | When data is written to disk, parallelization is used to maximize throughput. Data can either be split by partition or by table when writing in parallel. For most cases, using Partitioned provides the best throughput. For cases where you have a significant number of tables, it may be more efficient to write each table in parallel. |
| Sort Limit | When performing a sort at the end of day writedown, this limit is used to chunk the sorting of the table. This value must be set less than the allocated writedown compute. Setting a sort limit reduces writedown throughput but it is useful to set this value when wide tables are being used to reduce the amount of required memory. |
| Writedown Batch Size | During writedown, data can be split into chunks to reduce memory footprint. This value lets you set a row limit to split data on during writedown. |
Environment variables¶
To configure the environment variables defined in the writedown processes during startup:
-
Click Add Variable and complete the key-value pair, where the key is the name of a variable and the value is the desired setting.
- Writedown Settings: Refer to Storage Manager environment variable list for the complete list of options.
Tier settings¶
Tiers are used for accessing data with different levels of compute depending on the age of the data.
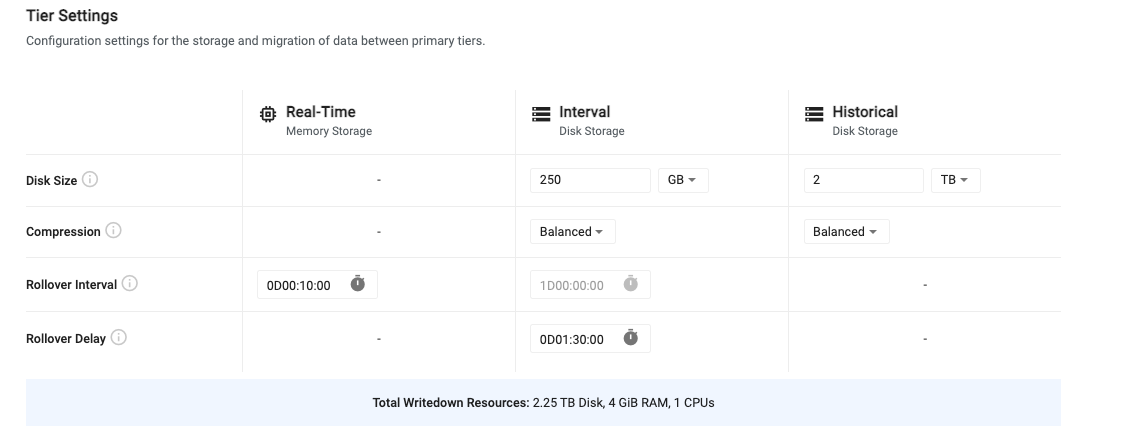
The three types of tiers are:
- Real-Time - Recent data is stored in a real-time tier that provides fast access at a high resource cost.
- Interval - Recent, but slightly older data is stored in an interval tier. This data is written to disk but is quickly accessible as it remains mapped to memory for quick access.
- Historical - Data that is older than a day is moved to an historical tier for longer term storage. This tier uses less resources but still allows for fast access to historical data.
For older, less relevant data, additional historical tiers can be configured to migrate data to object storage. Here, data is very cheap to store for long periods of time, but it is also much slower to access.
Tier settings allow you to configure the lifecycle of data as it propagates across the three primary tiers. The following table outlines the default tier settings.
| Name | Description |
|---|---|
| Disk Size | For interval and historical tiers, this is the amount of disk space allocated for storing data on disk. The interval tier only needs to store enough data to hold a single day, while the historical tier must hold all data that isn't migrated out of the system. |
| Compression | Tier compression configures how data is compressed when written to disk on the interval and historical data tiers. The compression settings use the compression options provided with kdb+. Compression settings can be set to one of the provided presets or can be tuned with custom settings. - Fast - Uses Snappy compression with a block size of 12. This provides the fastest writedown and retrieval of data but only provides minimal compression. - Balanced - Uses QIPC compression with a block size of 14. This provides a moderately fast writedown and retrieval rate while offering moderate compression. - High Compression - Uses LZ4HC compression set at a maximum compression level of 12 with a block size of 20. This provides the highest rate of compression, but the slowest writedown and retrieval. - Custom - Compression can be disabled by setting this value to Custom and choosing a Compression Algorithm of None. There are three preconfigured compression settings or custom. See custom compression settings for more details. |
| Compression Algorithm | This is the algorithm to use for data compression. Different algorithms provide different levels of flexibility to tune the level of compression and the block size used for compressing. See the compression algorithms table below for details on what values are available. |
| Compression Level | This is available for some algorithms and is the ratio of compression to apply to the data. A higher level provides more compression, but requires more passes of the data and can be slower for writedown and retrieval. See the compression algorithms table below for the available options. |
| Block Size | When applying compression, data is split into logical blocks for chunking compression. The block size is a power of 2 between 12 and 20 indicating the number of bytes to include in each block. For example, a block size of 20 means 2 to the power of 20, or 1 MB block size. |
| Rollover Interval | This value is the frequency at which data migrates between tiers. - By default, data moves from the real-time tier to the interval tier every 10 minutes. - Data then moves from the interval tier to the historical tier once per day. This value is currently not configurable. |
| Rollover Delay | The length of time to delay the rollover of data to the next tier. This value must be less than the Rollover Interval for the same tier. - The EOI Rollover Delay (moving data from the RDB to the IDB) is defaulted to 00:00:00 causing EOIs to be triggered at multiples of the Rollover Interval counted from 2000-01-01 00:00:00. The value is defined in the package as the offset value. Note: An EOI moves any data it finds in the RDB to the IDB at the time it is triggered.- For the EOD Rollover Delay (moving data from the IDB to the HDB) is defaulted to 00:00:00. The value is defined in the package as the snap value. Note: When a delay is set only the EOD time is delayed, the time range of data being moved to the next tier is unaffected. Any late data that arrives before the EOD is triggered belonging to the previous date partition is written to that partition. Any late data that arrives after the delay belonging to the previous date partition is written at the next EOD. |
| Rollover Time | This is required when an additional historical tier is added. In this situation, the Retention Time must be configured. Enter the amount of time that the historical tier holds data before migrating it to the additional historical tier. |
Compression Algorithms¶
Setting the compression algorithm changes the settings that are available for configuration.
- All compression algorithms have an option to configure their block size but only certain algorithms can change the compression level.
- To disable compression, select None as the compression algorithm.
- The following table details compression level settings available for each algorithm. For algorithms that offer levels, the higher the level, the smaller the data is on disk, at the expense of more time and resources to perform the compression.
| Name | Levels | Description |
|---|---|---|
| None | - | Disable compression. |
| QIPC | - | Uses native QIPC compression to reduce file sizes on disk. |
| GZIP | 0-9 | Uses GZIP to compress data offering, where the level is the number of passes of each block of data to make to reduce data size. |
| Snappy | - | Snappy provides a fast compression algorithm focused on speed over compression ratios. |
| LZ4HC | 0-16 | LZ4HC offers very fast compression while also allowing tuning of the compression level to reduce footprint. |
| ZSTD | -7-22 | ZSTD offers very fast compression of low entropy columns. Use low compression level (like 1) if you optimize for compression (write) speed and increase level to achieve better compression ratio. Avoid high levels (above 14). |
Refer to File compression for more details.
Additional historical tiers¶
By default, historical data migrates to the final historical tier and remains there until all available disk space is consumed. If you have data that you query infrequently, but you want to maintain for extended periods of time, you can migrate that data to an object storage tier using an Additional Historical Tier. Data that is migrated to an object storage tier can be persisted for an unlimited duration but is significantly slower to access. Object storage offers inexpensive elastic storage allowing you to hold massive volumes of data at a fraction of the cost of holding it on a persistent disk.
To add an additional historical tier, click Add Historical Sub Tier and set the values described below.
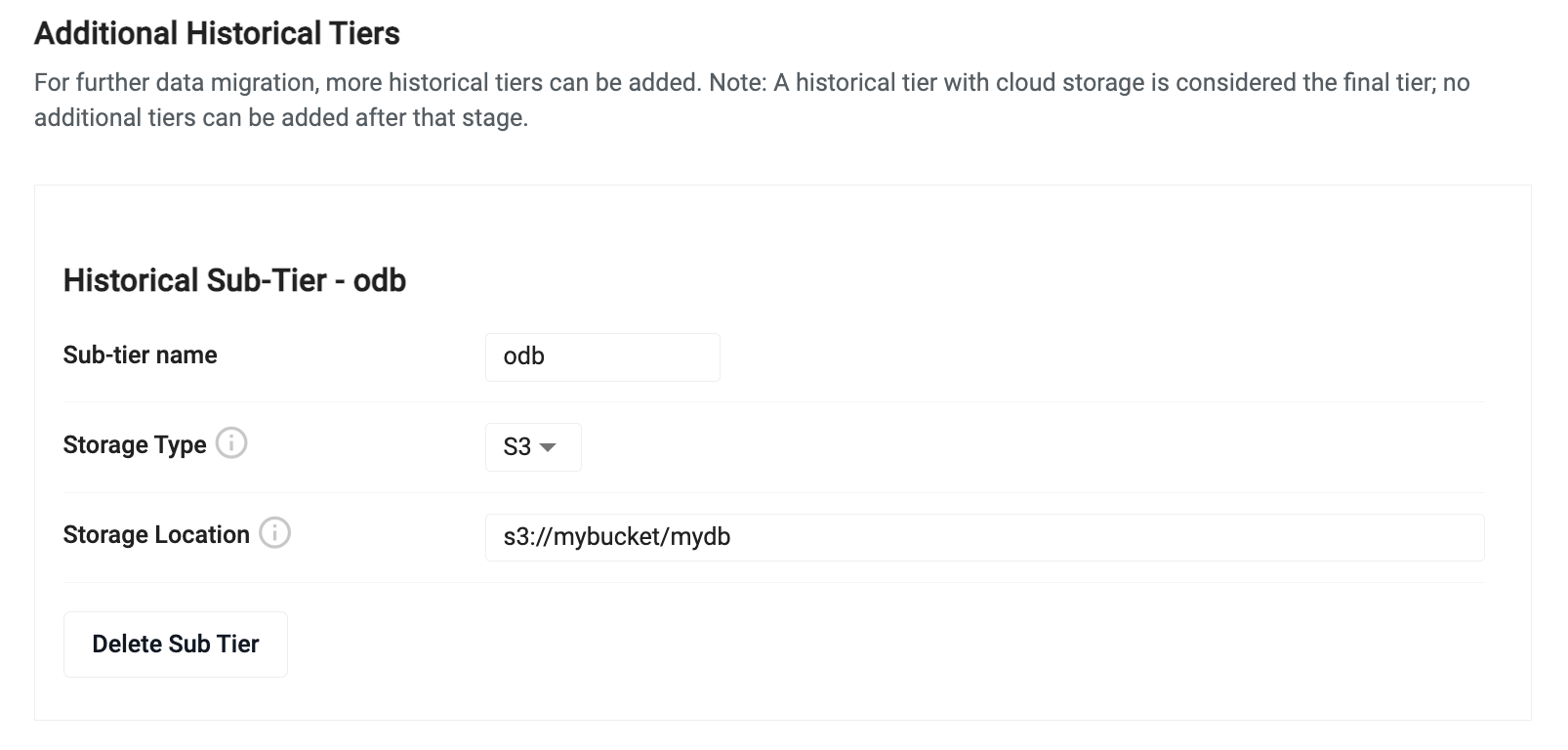
| Name | Description |
|---|---|
| Sub-tier name | Enter a name for the sub-tier. |
| Storage Type | Select a storage type. The historical tier requires you to have an existing bucket. Select the vendor type for the desired bucket: - S3 - Amazon S3 - Azure - Azure Blob Storage - GCP - Google Cloud Platform |
| Storage Location | Enter a location within that bucket to act as the root of the database. |
| Inventory Path | The bucket/storage that the inventory is written to. |
Packages¶
Packages can be used to add User Defined Analytics (UDAs) to databases for advanced queries. Packages can be added to kdb Insights Enterprise by installing them from the kdb Insights CLI.
This option is displayed when you enable the Advanced Settings toggle at the top of the database document.
To add a package click Add Package and complete the following values:
| Name | Description |
|---|---|
| Name | Select the name of the package being loaded. This field contains a list of all packages on the package manager service (this includes all views/pipelines/databases). |
| Version | Select the version of the package being loaded. The versions listed relate to the package selected in the Name field. |