Resource Settings¶
This page describes the configuration options available under the Resources tab in the kdb Insights Enterprise Web Interface.
When building a database and preparing for deployment, specific resources are allocated to facilitate the process. However, it's important to note that these resources may not be entirely sufficient based on the specific demands of your database.
To ensure a seamless deployment, the Resources tab, on the database screen gives you options to:
Adjust resources tab¶
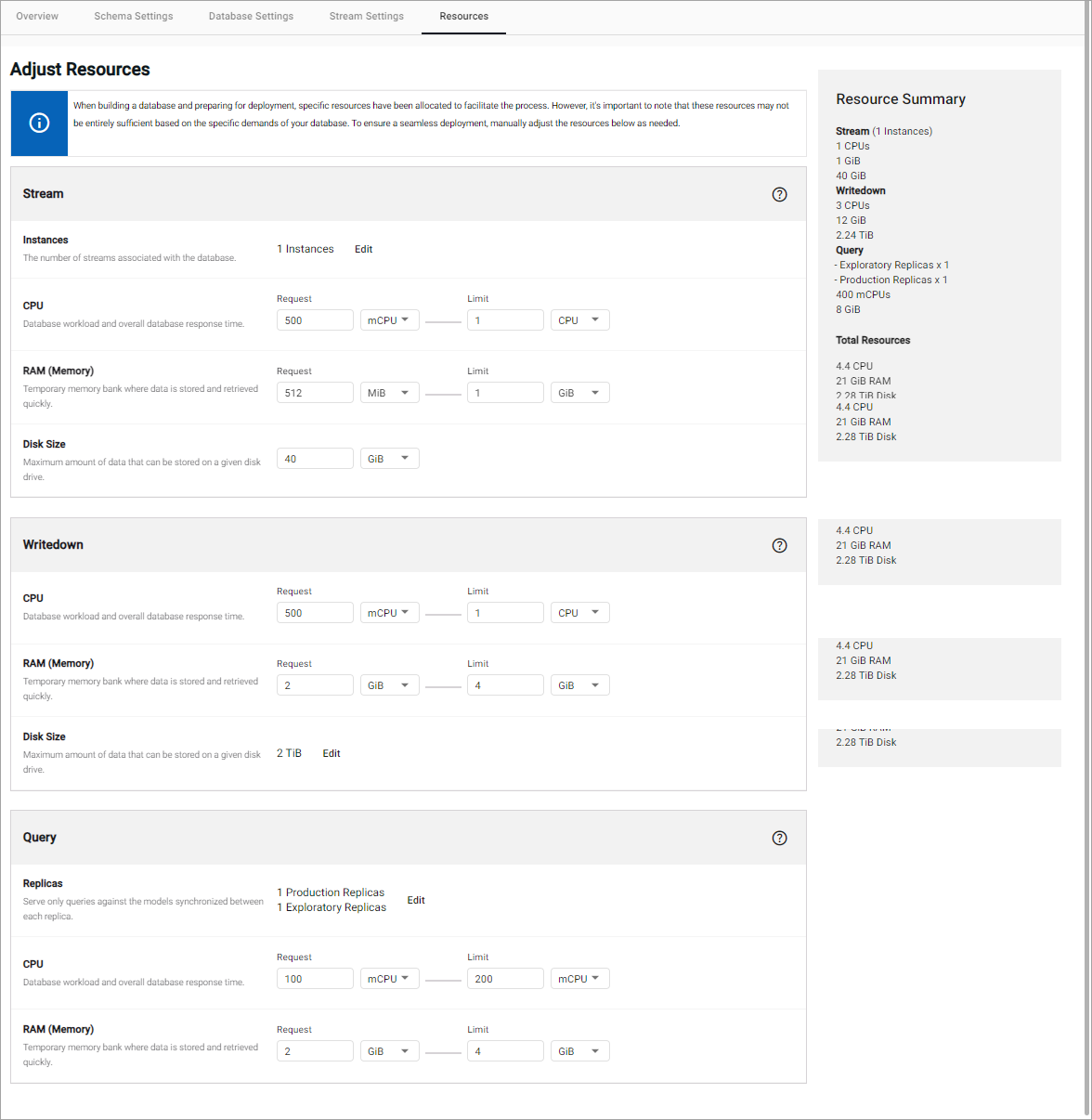
This tab allows you to define the following resource allocations manually:
Stream¶
Streams are responsible for moving data between components within kdb Insights Enterprise. They ensure a deterministic order of events from multiple producers in one unified log of the event sequence. The throughput and latency of the system is dependent on the compute resources allocated to a stream compared to how much data is moving through it. The compute resources for a stream allow you to tune your system for your desired throughput.
The following table provides further details for these fields:
| Name | Description |
|---|---|
| Instances | The number of stream process instances. |
| CPU | The request and limit amount of virtual CPU cycles to allocate to this stream. - Request specifies the initial resource allocation- Limit specifies the max amount that can be assigned under normal operations. During burst operations, this process may consume more than the limit specified, but only for a short period of time before scaling back down to within the specified ranges. These values are measured in fractions of CPU cores which is either represented as mCPU for millicpu or just simply CPU for whole cores. You can express a half CPU as either 0.5 or as 500mCPU. |
| RAM (Memory) | The request and limit amount of RAM to allocate to this process. - Request specifies the initial resource allocationLimit specifies the max amount that can be assigned under normal operations. If the memory available on the current infrastructure is insufficient, Kubernetes triggers a scale-up event on the install. Kubernetes also evicts and restarts pods of other over-resourced streams to free up resources to pods that require them. RAM is measured in bytes using multiples of 1024 (the iB suffix is used to denote 1024 byte multiples). |
| Disk Size | This is the amount of disk allocated to the stream to hold in-flight data. By default, this holds 5GiB, if you are using a 3-node RT cluster 15GiB will be allocated to the stream. This must be tuned to hold enough data so that your system can recover from your maximum allowable downtime. For example, if your data was arriving at 1MB/s and you wanted to allow for a 2 hour recovery, you need at least 120GB of disk space to hold those logs. |
Writedown¶
This is the amount of compute resources to allocated to each database writedown process.
| Name | Description |
|---|---|
| CPU | The request and limit amount of virtual CPU cycles to allocate to this instance. - Request specifies the initial resource allocation- Limit specifies the max amount that can be assigned under normal operations. During burst operations, this process may consume more than the limit specified, but only for a short period of time before scaling back down to within the specified ranges. This value is measured in fractions of CPU cores which is either represented as mCPU for millicpu or just simply CPU for whole cores. You can express a half CPU as either 0.5 or as 500mCPU. |
| RAM (Memory) | The request and limit amount of RAM to reserve for this process. RAM is measured in bytes using multiples of 1024 (the iB suffix is used to denote 1024 byte multiples). If enough memory is not available on the current infrastructure, Kubernetes triggers a scale up event on the install. This is the limit amount of RAM to reserve for this process. If the RAM limit is consumed by this instance, it is evicted and restarted to free up resources. |
| Disk Size | The maximum amount of data that can be stored on a given disk drive. |
Query¶
This is the amount of compute resources to allocate to each of the production and exploratory query instances. Both types of instances use the same compute profile.
Query compute settings allow you to tailor your settings to optimize query performance. These settings are split into Replicas, CPU, and RAM (Memory) allocations that can be assigned to the query instances. The request values represent the amount of a resource that is required to serve queries.
If there are not enough resources available to satisfy the request ask, Kubernetes triggers a scale up event to acquire more resources. Limit values are best effort limits that are applied to query processes. If the limit amount is reached, the query instance is evicted and forced to restart, releasing any resources back to the pool of available resources.
The following table explains these settings.
| Name | Description |
|---|---|
| Replicas | The number of production and exploratory replicas. When Query Environments are disabled, the number of Exploratory Replicas defaults to 0 on database creation. |
| CPU | The request and limit amount of virtual CPU cycles to allocate to this instance. - Request specifies the initial resource allocation- Limit specifies the max amount that can be assigned under normal operations.During burst operations, this process may consume more than the limit specified, but only for a short period of time before scaling back down to within the specified ranges. This value is measured in fractions of CPU cores which is either represented as mCPU for millicpu or just simply CPU for whole cores. You can express a half CPU as either 0.5 or as 500mCPU. |
| RAM (Memory) | The request and limit amount of RAM to reserve for this process. RAM is measured in bytes using multiples of 1024 (the iB suffix is used to denote 1024 byte multiples). If enough memory is not available on the current infrastructure, Kubernetes triggers a scale up event on the install. The limit amount of RAM to reserve for this process. If the RAM limit is consumed by this instance, it is evicted and restarted to free up resources. |
Resource summary¶
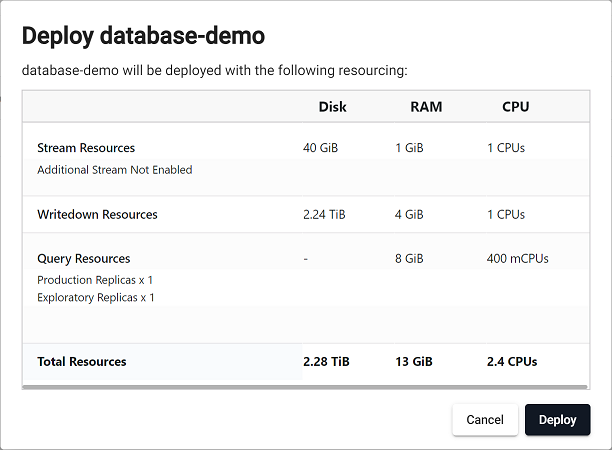
The Resource Summary, on the right side of the screen, provides a summary of the current resources allocated to the database, under the following headings:
It also gives a summary of total resources in terms of CPUs, RAM, and Disk.
This resource summary information is also shown in a summary when you deploy a database as shown below.