Stream Processor
A high-performance, scalable, flexible stream processing system implemented in q
The kdb Insights Stream Processor is a stream processing service for transforming, validating, processing, enriching and analyzing real-time data in context. It is used for building data-driven analytics and closed loop control applications optimized for machine generated data from data sources, and delivering data and insights to downstream applications and persistent storage.
The Stream Processor allows stateful custom code to be executed over stream or batch data sources in a resilient manner, scaling up when data sources allow. This code can be used to perform a wide range of ingest, transform, process, enrich, and general analytics operations.
Stream processing
Stream processing is the practice of taking one or more actions on a series of data that originate from one or more systems that are continuously generating data. Actions can include a combination of ingestion (e.g. inserting the data into a downstream database), transformation (e.g. changing a string into a date), aggregations (e.g. sum, mean, standard deviation), analytics (e.g. predicting a future event based on data patterns), and enrichment (e.g. combining data with other data, whether historical or streaming, to create context or meaning).
These actions may be performed serially, in parallel, or both, depending on the use case and data source capabilities. This workflow of ingesting, processing, and outputting data is called a stream processing pipeline.
Use cases
There are many ways you can use a stream-processing system. Here are some examples.
- Process and react to realtime transactions (fraud detection, stock trading)
- Monitor and react to realtime sensor data from IoT devices in manufacturing, oil fields, etc.
- Monitor and react to distribution flows (railways, fleets, trucks, cars, shipments, inventory)
- Monitor and react to customer interactions for manufacturing, inventory, and marketing purposes
Architecture
At a high level, the kdb Insights Stream Processor is able to continuously
- read data from a variety of data sources (streams, batches, databases, files)
- transform, process, and enrich the data
- store the output to downstream data sources or applications
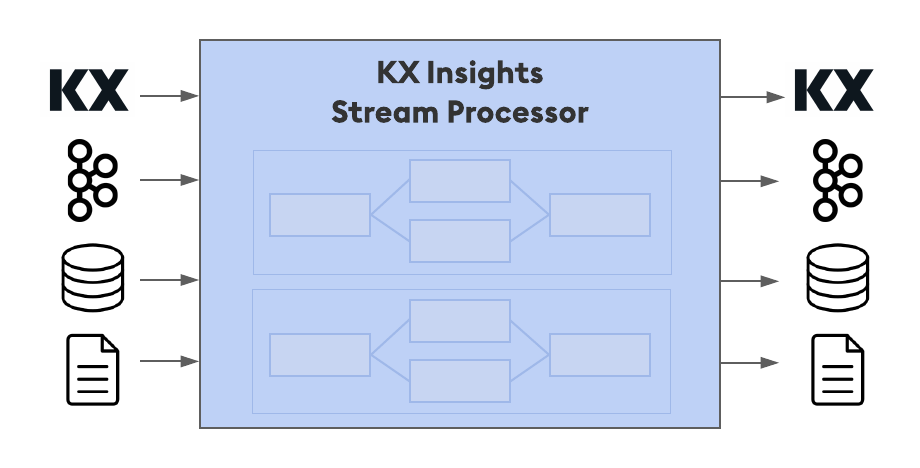
In a more detailed view, kdb Insights Stream Processor consists of three major components:
- Coordinators
- Controllers
- Workers
The Coordinator is a persistent service available when running in Kubernetes, responsible for submitting, managing, listing, and tearing down streaming jobs based on configuration and performance parameters. It will dynamically spawn Controllers (who then create Workers) based on the provided configuration.
Note
The Coordinator is only applicable when deploying in Kubernetes for dynamically provisioned pipelines. When running pipelines within Docker, only the Controller and Workers are required.
- Controllers
-
are responsible for setting up, managing, and monitoring a single pipeline. A Controller can distribute the pipeline’s load based on configuration and performance parameters (e.g. minimum workers, maximum workers, data source capabilities).
- Workers
-
are responsible for managing one or more operators in the pipeline (e.g. read, map, write, etc). Within an operator, actions are performed. Actions include reading, transforming, aggregating, filtering, enriching, and writing data. Actions are chained together to form a complete data pipeline.
Examples
Some examples show how data can flow through the kdb Insights Steam Processor.
Kafka pipeline
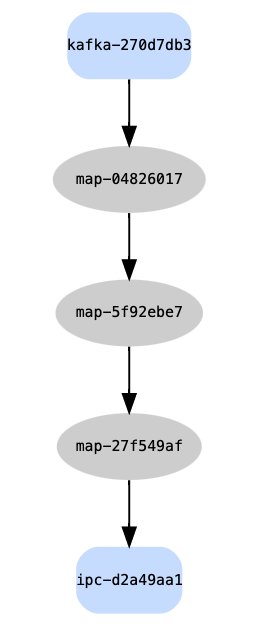
The code below is a pipeline specification. Generally speaking, a pipeline is created by chaining operators together between a data source and data sink.
In the example below, data is read from the Kafka topic trade_topic. The data is then decoded from JSON strings using .j.k. A new field is added
to each trade of the result of price * size. Then, to write to a kdb+ tickerplant, the data is translated into a tuple of (tableName; data) format.
Once transformed, the data is written to the tickerplant on localhost:5000.
.qsp.run
.qsp.read.fromKafka
[`trade_topic;
("localhost:1234"; "localhost:1235")]
.qsp.map[.j.k]
.qsp.map
[{ update newcol: price * size from x }]
.qsp.map[{ (`trade; x) }]
.qsp.write.toProcess
[.qsp.use `handle`target!(`:localhost:5000; `.u.upd)]
This example is a simple linear transformation pipeline from Kafka source to tickerplant sink, and can be visualized using the pipeline REST API on the Controller or Worker when deployed:
# Controller exposed on port 6000
$ curl localhost:6000/description
Complex pipeline
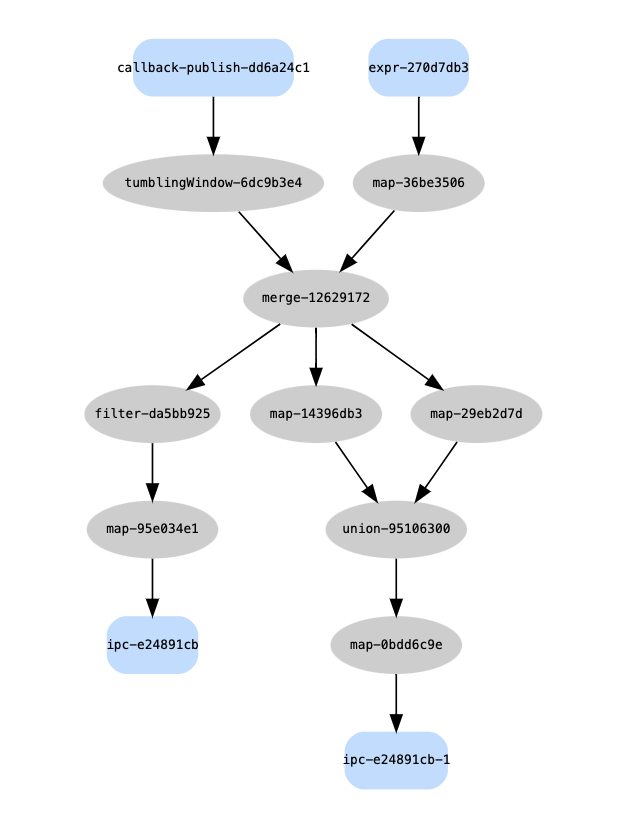
The Stream Processor API allows complex dataflows to be modeled in addition to the simple linear dataflows as in the previous example.
In this example, local data is generated to simulate sensor descriptions. (This could be a query to a historical kdb+ process.) Live data is then read from a callback and enriched with the reference data before being split into multiple calculations and anomalies. The resulting streams are written to a kdb+ tickerplant to make available to other subscribers and queries.
// Obtain reference data
refData: ([] id: 100?`4; name: {rand[20]?" "} each til 100)
// Create a stream from the reference data
refStream: .qsp.read.fromExpr["refData"]
.qsp.map[{ select from x where not name like "torque_*" }]
// Read trace records from a callback, window into 5 second intervals,
// and left join with the reference data
mergedStream:
.qsp.read.fromCallback[`publish]
.qsp.window.tumbling[00:00:05; `time]
.qsp.merge[refStream; {x lj `id xkey y}]
// Create a stream of anomalous sensor readings
anomalyStream: mergedStream
.qsp.filter[{90<x`val}]
.qsp.map[{ (`anomalies;x) }]
.qsp.write.toProcess[.qsp.use `handle`target!(`:localhost:5000; `.u.upd)]
// Create two streams with custom calculations on the trace readings
avgStream: mergedStream
.qsp.map[{ select calc:`avg, avg val by name from x }]
maxStream: mergedStream
.qsp.map[{ select calc:`max, max val by name from x }]
// Create a single stream of the multiple calculation streams
calcStream: maxStream .qsp.union[avgStream]
.qsp.map[{ (`calcs; x) }]
.qsp.write.toProcess[.qsp.use `handle`target!(`:localhost:5000; `.u.upd)]
// Run the full pipeline
.qsp.run (anomalyStream; calcStream)
The REST API can again be used to get the pipeline visual description:
To put these pipeline specifications in the context of the architecture described earlier, the operators could reside in a single Worker or be distributed across multiple Workers based on performance considerations. In the simplest case, one Worker could be used to handle the entire pipeline.
In a more complex scenario, each Worker could be assigned either a single partition of the stream, or a group of partitions. The partition identification and assignment to Workers is handled by each data source through the Data Source Plugin, and orchestrated by the Controller. In this way, the kdb Insights Stream Processor is scalable to handle various data volumes, velocities, or computational complexities.
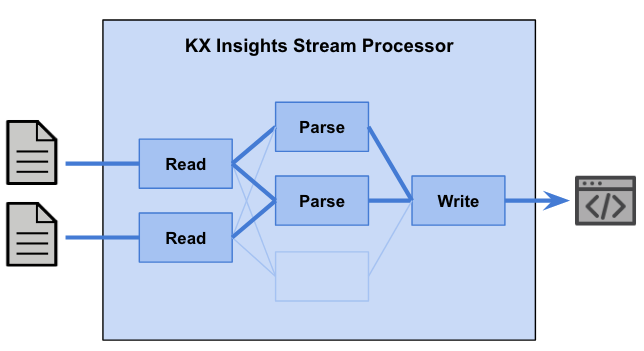
Operators and IO
Readers, writers, and operators are the core of the stream pipeline. As mentioned earlier, operators and IO are chained together to form a streaming data pipeline. Currently operators are provided for apply, map, filter, window, merge, and split stream operations and IO connectors are provided as listed in readers and writers.
- read connectors
- multiple window operators
- map operator
- apply operator
- filter operator
- merge/join operator
- split operator
- write connectors
Operators are responsible for progressing the flow of data, and track message metadata along with messages. The metadata associated with a message may be extended by passing through specific operators. For example, passing through a window operator will add a window property to the metadata denoting the start time of the window. Metadata is not exposed within operator user-defined functions unless explicitly asked for using .qsp.use.