Exporter
The Exporter provides an interface for moving data out of the system. Data can be persisted to disk in a kdb+ format or can be exported to another format altogether.
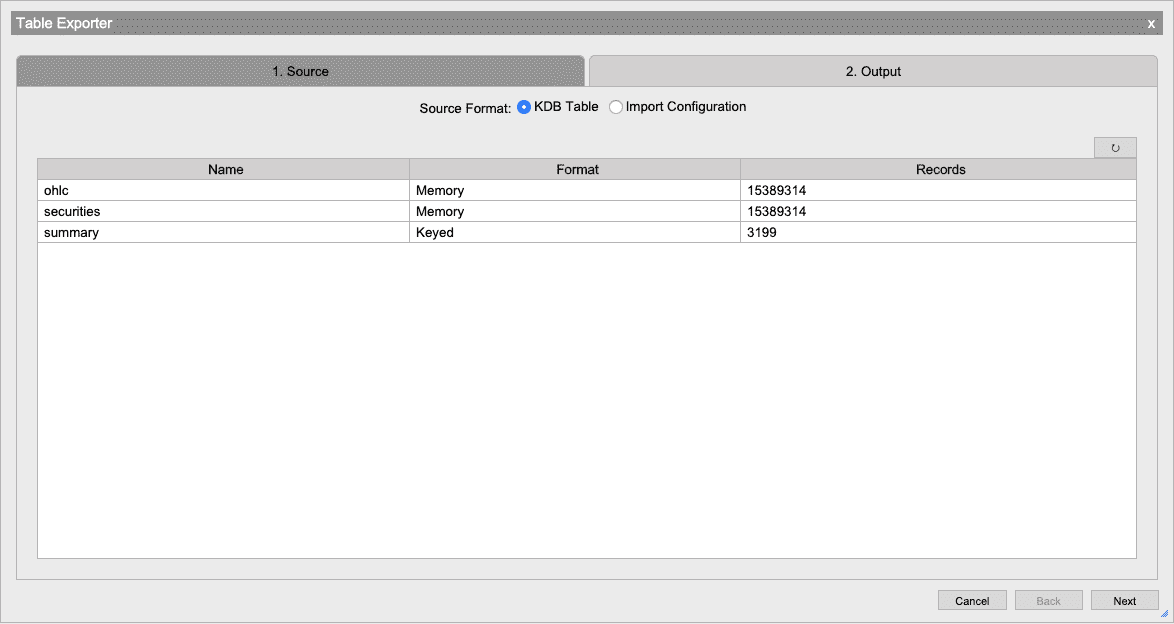
Source
Select the data that needs to be exported. If the table to be exported is loaded in memory, then select it from the table list.
Output
Output selection is very similar to that of the table Importer.
Select the desired output format from the Output Format dropdown. Once the format has been selected, the options area will be populated with the required settings for that format.
All of the required fields must be completed before selecting Finish.
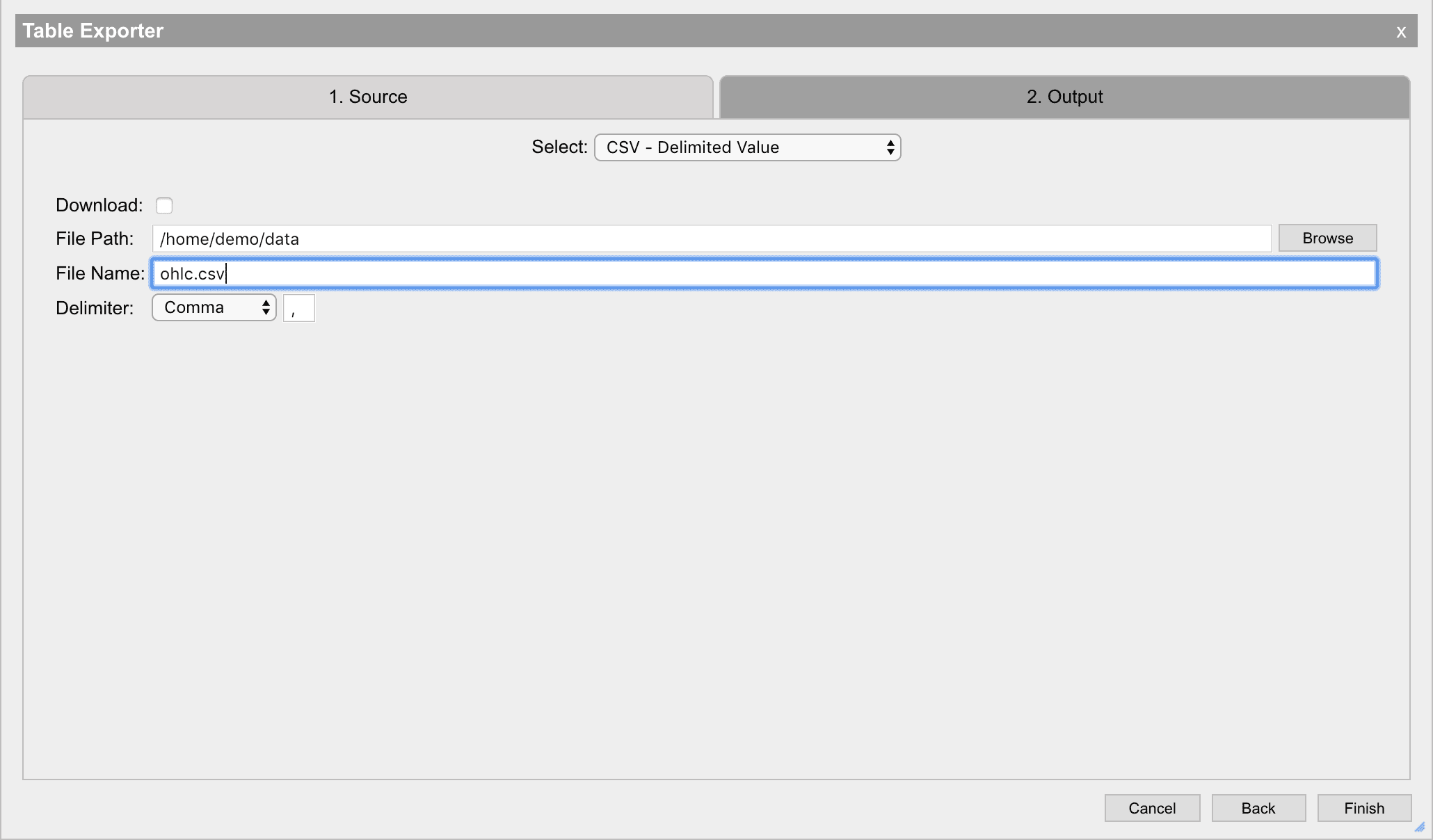
CSV – delimited value
Delimited value files can store simple normalized tables into a text format which can be be used to simply move data around. To export the data, select a location on disk, name the output file and select a delimiter. This will produce a file with the contents of the table in a text format using the provided delimiter. Selecting the Download option will download the output table to the user's local machine.
Nested or complex data
If a table contains nested data or complex data, it cannot be serialized into CSV format.
Options
| field | description |
|---|---|
| Delimiter | The delimiter character for the file. An option can be selected from the drop down or a custom character can be put in the adjacent text field. |
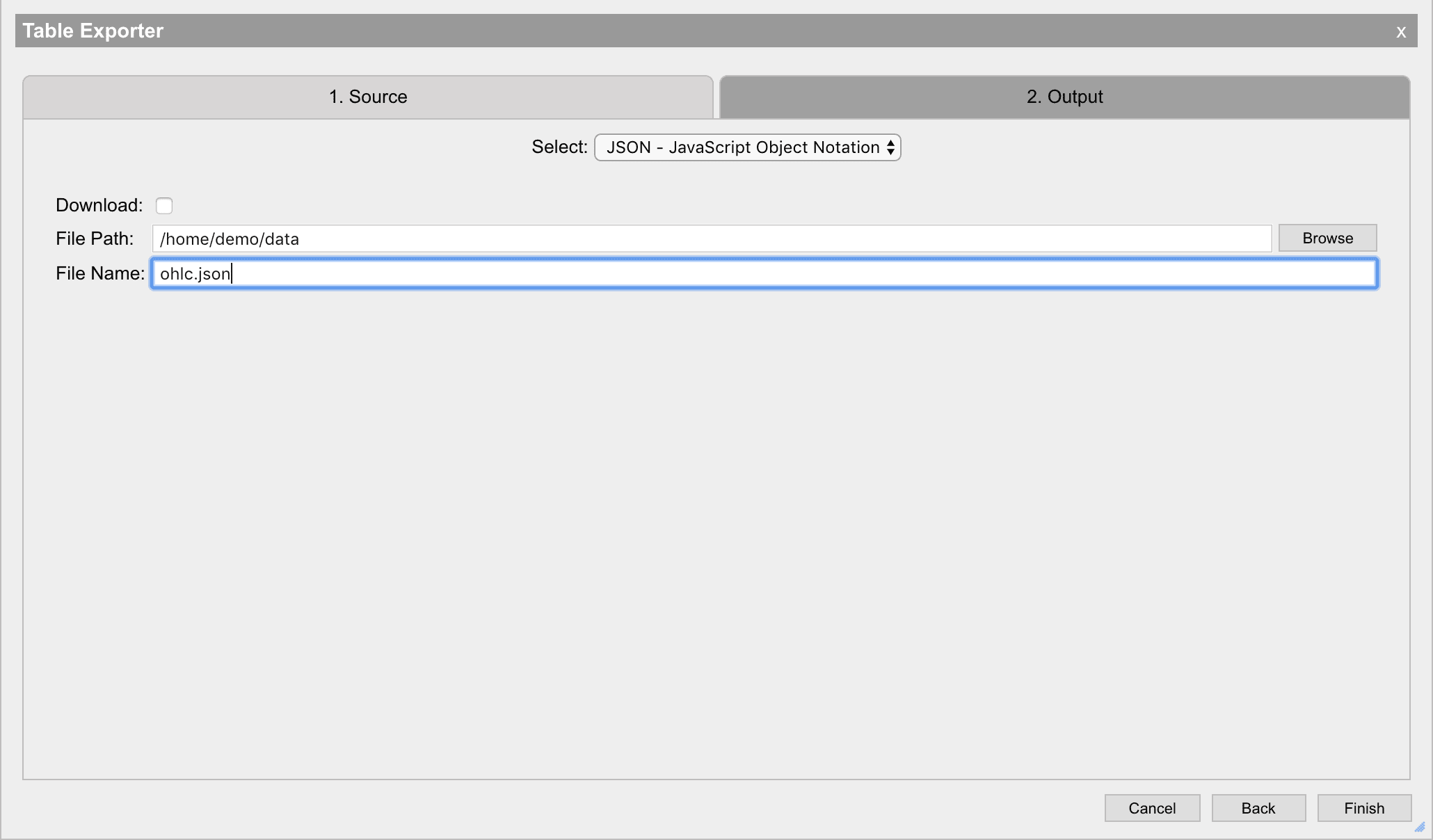
JSON - JavaScript object notation
JSON is a popular structured text format that can be used to store a table as an array of objects. To export data in this format, enter a file path and file name for the output file and press Next. JSON can be used to represent much more complex data than but will produce much larger output files due to its syntax.
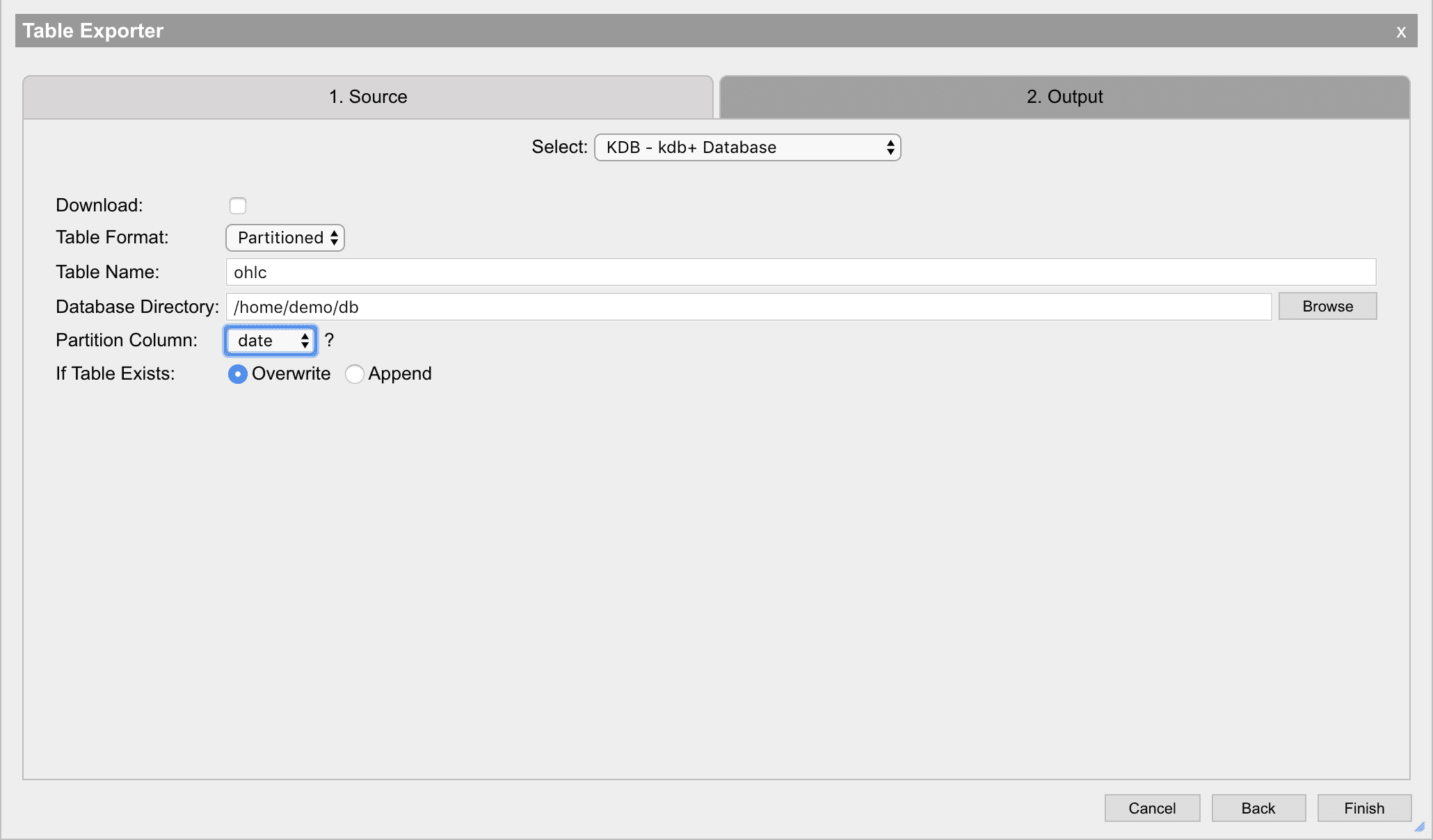
KDB - kdb+ database
The Exporter can be used to write data back to disk as a kdb+ table. This will write the data in one of the available table formats on disk.
If the Download option is selected, only Serialized will be available in the Table Format dropdown. This is single file database structure for kdb+ tables.
Partitioned database selection has an extra field for selecting the Partition Column. This column will be used to separate the data into partitions. A restriction of kdb+ is that the type of this column must be either a date, month, long, int or short. The column selected will be renamed by kdb+ when loaded back into the process to one of date, month, year or int.