Previous KDB.AI Server Release Notes¶
This page provides a historical record of previous KDB.AI Server updates, including earlier features, fixes, and improvements. Use it as a reference when working with older versions.
v1.10.1¶
Release date: 2026-04-27
Fixes and improvements
-
This update includes several bug fixes and enhancements to improve KDB.AI performance and stability.
-
Critical Vulnerabilities and Exploits (CVEs) remediated in this release:
v1.10.0¶
Release date: 2026-04-16
KDB.AI Server 1.10.0 introduces GPU-accelerated vector search, expanded OAuth 2.0 support for Microsoft Entra ID, and configuration improvements. Key highlights include:
- Nvidia cuVS Integration (New)
- Microsoft Entra ID OAuth 2.0 setup guide (New)
- OAuth 2.0: app roles support (Improvement)
- OAuth 2.0: environment variable renames (Non-upward compatible)
- Security: CVE remediations
1. Nvidia cuVS Integration (New)¶
KDB.AI now supports GPU-accelerated similarity search via Nvidia's cuVS library using the CAGRA graph-based algorithm. Available through the kdbai-db-cuvs Docker image, CAGRA builds a k-nearest neighbor graph entirely on the GPU and runs parallelized beam search at query time, delivering significantly higher throughput than CPU-based indexes at scale.
Related content
Refer to the Nvidia cuVS Integration guide for system requirements, index configuration, VRAM planning, and search performance tuning.
2. Microsoft Entra ID OAuth 2.0 setup guide (New)¶
A new end-to-end guide covers configuring KDB.AI OAuth 2.0 authentication with Microsoft Entra ID – from creating the app registration and security groups in the Azure portal, to starting KDB.AI and verifying that ACL grants enforce access correctly.
Related content
Refer to the KDB.AI OAuth 2.0 with Microsoft Entra ID guide for the full walkthrough.
3. OAuth 2.0: app roles support (Improvement)¶
KDB.AI OAuth 2.0 now supports Entra ID app roles as an alternative to security groups. App roles are defined directly on the app registration and included automatically in the roles claim, with no additional token claim configuration required. ACL grants reference the role value by name rather than a group Object ID.
To use app roles, set OAUTH_GROUPS_CLAIM=roles in your KDB.AI configuration.
4. OAuth 2.0: environment variable renames (Non-upward compatible)¶
Several OAuth environment variable names have been renamed for consistency:
| Previous name | New name |
|---|---|
OAUTH_APP_NAME |
OAUTH_CLIENT_ID |
OAUTH_TENANT_ID |
OAUTH_TENANT_CLAIM |
OAUTH_GROUPS_ID |
OAUTH_GROUPS_CLAIM |
Breaking change
Update your configuration to use the new variable names before upgrading. The previous names are no longer recognized.
5. Security: CVE remediations¶
This release includes fixes for multiple Critical Vulnerabilities and Exploits (CVEs) to enhance system security and compliance:
- CVE-2026-4111
- CVE-2026-4519
- CVE-2025-14831
- CVE-2025-9820
- CVE-2025-15366
- CVE-2025-15367
- CVE-2026-0865
- CVE-2026-1299
- CVE-2026-25749
Upgrade procedures¶
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Stay tuned for the next release!
The KDB.AI Team
v1.9.0¶
Release date: 2026-02-26
The KDB.AI Server 1.9.0 release introduces OAuth 2.0 authentication and authorization and includes security updates addressing multiple CVEs. Key highlights include:
- OAuth 2.0 authentication and authorization (new)
- Security: CVE remediations (fixes and improvements)
1. OAuth 2.0 authentication and authorization (new)¶
KDB.AI Server now supports OAuth 2.0 authentication and authorization, enabling integration with external Identity Providers (IdPs) such as Keycloak, Microsoft Entra ID, and Okta. In this model:
- The IdP issues signed JWT access tokens.
- KDB.AI validates the token’s signature and issuer.
- Authorization uses the tenant and groups claims contained in the token.
- ACL grants define fine‑grained permissions at the database and table levels.
- A system administrator role can be assigned through specific tenant/group combinations.
This feature improves enterprise readiness by providing centralized identity management, tenant isolation, and group‑based authorization.
Related content
Refer to the OAuth 2.0 Authentication and Authorization how-to guide as well as to the q API, Python API, or REST API documentation in the References section for sample calls, expected responses, and troubleshooting tips.
2. Security: CVE remediations (fixes and improvements)¶
This release includes fixes for multiple Critical Vulnerabilities and Exploits (CVEs) to enhance system security and compliance. The following CVEs have been remediated:
- CVE-2025-68973
- CVE-2025-11187
- CVE-2025-15467
- CVE-2025-15468
- CVE-2025-15469
- CVE-2025-66199
- CVE-2025-68160
- CVE-2025-69418
- CVE-2025-69419
- CVE-2025-69420
- CVE-2025-69421
- CVE-2026-22795
- CVE-2026-22796
- CVE-2025-9086
- CVE-2025-13601
- CVE-2025-15281
- CVE-2026-0861
- CVE-2026-0915
- CVE-2025-12084
Upgrade procedures
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Thanks for reading. Stay tuned for the next release!
The KDB.AI Team
v1.8.2¶
Release date: 2026-01-21
Fixes and improvements
-
Fix docker pull error: Resolved an issue where certain image metadata could cause Docker pull failures with newer Docker Engine versions, resulting in errors such as
invalid reference (must be SemVer or 'latest'). Pull the latest kdbai-db image to resolve. -
Critical Vulnerabilities and Exploits (CVEs) remediated in this release:
v1.8.1¶
Release date: 2025-11-21
Fixes and improvements
This update includes several bug fixes and enhancements to improve KDB.AI performance and stability.
v1.8.0¶
Release date: 2025-11-06
KX-hosted KDB.AI Cloud is discontinued as of June 30.
Please transition to the self-hosted edition of KDB.AI, which can be deployed on-premises or in your own cloud environment.
Welcome to the KDB.AI Server 1.8.0 release. Key highlights include:
kdbai-clientnow supports Python 3.13.KDB.AI Serverv1.8.0 requireskdbai-client >= 1.8.0.-
CRUD stands for Create, Read, Update, and Delete - the four basic operations used to manage data in a database or persistent storage system:
updateanddeleteare supported for tables with no index,flat,qFlat,hnsw, andqHnswindexes.createandreadare supported for all indexes.
Related content
Refer to the q API, Python API, or REST API documentation in the References section for sample calls, expected responses, and troubleshooting tips.
-
Critical Vulnerabilities and Exploits (CVEs) remediated in this release:
- CVE-2025-5914
- CVE-2025-7425
- CVE-2025-49794
- CVE-2025-49796
- CVE-2025-6021
- CVE-2025-6020
- CVE-2025-8941
- CVE-2024-12718
- CVE-2025-4138
- CVE-2025-4330
- CVE-2025-4435
- CVE-2025-4517
- CVE-2025-6965
- CVE-2024-52533
- CVE-2025-4373
- CVE-2025-5702
- CVE-2025-8058
- CVE-2025-32988
- CVE-2025-32989
- CVE-2025-32990
- CVE-2025-6395
- CVE-2025-47268
- CVE-2025-48964
- CVE-2025-3576
- CVE-2025-25724
- CVE-2025-32414
- CVE-2025-32415
- CVE-2025-8194
- CVE-2025-47273
- CVE-2025-53905
- CVE-2025-53906
- CVE-2022-29458
Upgrade procedures
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Thanks for reading. Stay tuned for the next release!
The KDB.AI Team
v1.7.0¶
Release date: 2025-06-26
KX-hosted KDB.AI Cloud is discontinued as of June 30.
Please transition to the self-hosted edition of KDB.AI, which can be deployed on-premises or in your own cloud environment.
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Welcome to the KDB.AI Server 1.7.0 release, designed to improve authentication, clarify development standards, and provide greater transparency and flexibility in system configuration! Key highlights include:
- Dynamic Time Warping (DTW) search (New)
- Data deletion (New)
- Static authentication (New)
- Info API for system insight (New)
- Z-normalization update for Non-Transformed TSS (Improvement)
- Simplified dependency management (Improvement)
- Documentation updates (Improvement)
- Naming convention and reserved words (Non-upward compatible)
- KDB.AI Cloud retirement (Notice)
- Security fixes
1. Dynamic Time Warping (DTW) search (New)¶
KDB.AI now supports similarity search using Dynamic Time Warping (DTW), enabling dynamic and robust comparison of time-series patterns:
- Flexible temporal alignment: DTW aligns sequences that differ in speed or timing.
- Pattern-matching precision: Ideal for finance, audio, medical signals, and other shape-driven domains.
- Search-time configuration:
RR(ratio of warping radius) to limit alignment rangecutOffto skip high-distance matches for faster searches
Tip: Use a lower RR value when patterns are roughly time-aligned, and a lower cutOff value to increase performance for less-similar matches.
Related content
2. Data deletion (New)¶
KDB.AI now supports data deletion for tables with no index, flat index, qFlat index, or multi-indexes composed exclusively of flat or qFlat indexes, adding essential CRUD capabilities to your workflows.
Because deletion is irreversible and may be slow, review the documentation How To: Delete Data in KDB.AI before use.
3. Static authentication (New)¶
KDB.AI now supports static authentication, improving security and user management:
-
Flexible and secure authentication options: Ensures only authorized users can access the server.
-
Simplified setup process: Reduces configuration errors and makes it easier to manage authentication settings.
-
Seamless integration and secure connections: Allows users to leverage the latest features and improvements.
-
Clear and practical Docker examples: Makes it straightforward to implement authentication in Docker environments.
Related content
Visit the new Static authentication page to secure your server and manage user access efficiently.
4. Info API for system insight (New)¶
KDB.AI now includes a suite of Info endpoints that allow you to query the live state of your environment, helping you monitor system usage and validate configurations more effectively:
-
Query detailed metadata for tables, databases, sessions, and running processes via dedicated API calls.
-
Use System Info to get a consolidated snapshot of your system’s current health in a single call.
-
Structured responses make it easy to build monitoring dashboards or automate operational checks.responses support dashboards and automated monitoring
Related content
Refer to the q API, Python API, or REST API documentation in the References section for sample calls, expected responses, and troubleshooting tips.
5. Z-normalization update for Non-Transformed TSS (Improvement)¶
Use the normalize option to disable Z-normalization for non-transformed TSS searches:
-
Flexible search behavior: You can now choose whether to apply Z-normalization to non-transformed TSS searches based on your data and use case.
-
Greater control: Enable normalization for statistical consistency, or disable it for raw-value comparisons when precision matters.
-
Consistent defaults:
normalizeis enabled by default, maintaining current behavior unless explicitly changed.
Tip: set normalize to 0b (q API) or False (Pyhton API) in the options parameter to disable Z-normalization for raw-value comparisons.
Related content
- Learn how to perform a non-transformed TSS search — Step-by-step guidance on using TSS without data transformation, including the normalize option.
- Explore the KDB.AI APIs — Full reference for available endpoints and how to integrate them into your workflows (q API, Python API, and REST API).
6. Simplified dependency management (Improvement)¶
With the release of PyKX 3.1, KDB.AI now removes unnecessary version constraints for key dependencies, offering:
-
Greater flexibility: Looser version constraints for PyKX and Reranker allow for smoother upgrades and broader compatibility with other packages.
-
Easier environment management: Reduced risk of version conflicts when installing or updating dependencies in your environment.
-
Faster setup: Simplified requirements make it easier to get up and running without dependency errors.
Tip: if you maintain your own environment files, you can now safely relax version constraints for PyKX and Reranker.
7. Documentation updates (Improvement)¶
New pages:
- Reference: Naming Convention and Reserved Words
- Learn: Dynamic Time Warping (DTW)
- How To: Set up Static Authentication in KDB.AI, Get System Usage Information, Use Dynamic Time Warping (DTW), Delete Data
Updated pages: How to Use Databases in KDB.AI, How to Manage Tables, q API References, Python API References, and REST API References.
8. Naming convention and reserved words (Non-upward compatible)¶
KDB.AI introduces comprehensive NUC (Non-Upward Compatible) naming convention and reserved words guidelines to enhance code clarity and prevent errors:
- Clear and maintainable code: Adhering to naming rules ensures your code is easy to read and maintain.
- Avoid syntax errors: Following the guidelines helps prevent syntax errors and unpredictable behavior.
- Descriptive and meaningful names: Using appropriate names for databases, tables, and columns avoids conflicts with reserved words.
- Best practices: The guidelines provide best practices for naming, ensuring compatibility and reducing potential issues.
Related content
Visit our new Naming Convention and Reserved Words page to ensure your code remains clear, maintainable, and error free.
9. KDB.AI Cloud retirement¶
As of June 30, KX-hosted KDB.AI Cloud is discontinued. Please, transition to the self-hosted edition of KDB.AI, which can be deployed on-premises or in your own cloud environment.
Set up KDB.AI Server to explore powerful new features in version 1.7, including improved search, indexing, and system insight APIs.
10. Security fixes¶
Critical Vulnerabilities and Exploits (CVEs) remediated in this release:
- CVE-2024-12797
- CVE-2019-12900
- CVE-2020-11023
- CVE-2024-2511
- CVE-2024-4603
- CVE-2024-4741
- CVE-2024-5535
Upgrade procedures¶
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Summary¶
KDB.AI Server 1.7.0 introduces enhancements across authentication, telemetry, search capabilities, configuration insight, and documentation. If you need help, contact support@kdb.ai or join our Slack channel.
Thanks for reading — stay tuned for the next release! The KDB.AI Team
v1.6.0¶
Release date 2025.01.24
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Welcome to the KDB.AI Server 1.6.0 release! Key highlights include:
- Enhanced install experience (Improvement)
- Query batching optimization (Improvement)
- Endpoint for external/reference tables (New)
- Enhanced search and query performance (Improvement)
- Reduced memory usage (Improvement)
- Insert data for partition tables (Bug fix)
- Table search conflict (Known issue)
- Documentation updates (Improvement)
1. Enhanced KDB.AI Server install experience (Improvement)¶
Experience a quicker and more streamlined KDB.AI Server installation:
- Reduced setup time: We've simplified the setup process to cut the installation time from several days to just 10-20 minutes, ensuring a quick start for all users.
- Simplified process: The installation now requires only 2 Docker commands, minimizing complexity and potential errors.
- Enhanced user experience: Then, you can easily access the quickstart sample, access the KDB.AI features and see the value they can bring to your projects.
Tip: Head to our updated Server Setup page to see how easy it is to get started with KDB.AI. Save time, reduce errors, and enhance your overall experience with our improved installation process.
2. Query batching optimization (Improvement)¶
Enhance your multi-query search performance with query batching optimization by:
- Batching across the same index: Perform multiple queries within the same index efficiently, reducing the need for repetitive search calls.
- Batching across multiple partitions: Execute queries across different partitions seamlessly, enhancing the flexibility and scalability of your searches.
- Batching across multiple columns: Handle queries involving multiple columns effectively, allowing for more comprehensive data retrieval.
The optimization does not affect how APIs are called or their functionality. They have been optimized to support batch queries without any changes required on your end.
Tip: Use the batching capabilities to streamline your search processes, save time, and improve the efficiency of your data retrieval operations. Perform comprehensive queries across multiple indices, partitions, and columns to enhance the robustness of your data analysis.
3. Endpoint for external/reference tables (New)¶
We added a new endpoint for external/reference tables: /api/v2/databases/{database}/tables/{table}/load.
- When to use it: You need to call this endpoint if any changes are made to an external table after the last search or query call.
- Benefit: This ensures that the latest data is loaded and available for subsequent searches or queries, improving data accuracy and consistency.
Tip: Make sure to call the new endpoint /api/v2/databases/{database}/tables/{table}/load from the q, Python, or REST APIs. This will help keep your database up-to-date and avoid unnecessary reloads, enhancing the efficiency of your operations.
4. Enhanced search and query performance (Improvement)¶
We have enhanced the search and query performance by optimizing the database load process.
- Previously: The server would load the database on each call, which could slow down operations.
- Now: The backend checks if the database is already loaded and only reloads it if there are changes.
- Result: This improvement ensures faster response times and more efficient search and query experience.
5. Reduced memory usage (Improvement)¶
Further enhancements to KDB.AI memory management have resulted in improvements to memory usage. KDB.AI Server 1.6.0 uses less memory by implementing a clean-up process after each search or query. This enhancement helps in maintaining optimal memory usage, ensuring that the system remains efficient and responsive even during intensive operations. You can now enjoy a smoother and more reliable performance with reduced memory overhead.
6. Insert data for partition tables (Bug fix)¶
- Issue: The insert operation was throwing an error when there were missing partitions in the input data.
- Resolution: The insert data bug for partition tables has been resolved, ensuring smooth data insertion even when some partitions are missing.
7. Table search conflict (Known issue)¶
You may experience issues when searching a table using the same name as a previously deleted table within the same server instance.
Impact: You may see the kdbai-001E error during search in some cases and in other cases you may receive incorrect search results.
Resolution: Perform the following steps, depending on your use case and restriction:
- Restart the server instance to resolve the issue and create your table again using the same name.
- If you cannot restart the server, then create a table with a new name.
There is no risk of data loss due to this issue as it involves table deletion.
8. Documentation updates (Improvement)¶
- New page: All integrations.
- Updated pages: API references ( q, Python, REST), Server Setup.
Upgrade procedures¶
To use the latest version, upgrade your instance or download and set up KDB.AI Server.
Summary¶
We hope you appreciate all the enhancements and the new endpoint we introduced in v1.6.0. Enjoy exploring all the updates! If you need help, reach out to our Support Team at support@kdb.ai or join our Slack channel.
Thanks for reading. Stay tuned for the next release!
The KDB.AI Team
v1.5.0¶
Release date 2024.11.28
Welcome to the KDB.AI Server 1.5.0 release, designed to elevate your data management and search capabilities to new heights! Key highlights include:
- Partitioning in KDB.AI (New)
- Enhanced non-transformed TSS (Improvement)
- Range-based similarity search for qFlat index (New)
- Optimized search relevance with reranking capability (New)
- Multithreading in KDB.AI (New)
- Memory-mapping parameter for qHNSW (New)
1. Partitioning in KDB.AI (New)¶
Manage large data volumes more effectively by partitioning tables on metadata columns!
- Improved efficiency: Partitioning distributes the workload across multiple shards on disk, enhancing query performance and resource utilization.
- Enhanced scalability: By partitioning data, vector databases can handle larger datasets more effectively, allowing for horizontal scaling.
- Similarity-based partitioning: Group similar vectors together to reduce cross-shards-on-disk search times and improve query efficiency.
Tip: Learn about partitioning and how to partition data in KDB.AI. Use cases include time-series data management, geographic data segmentation, and optimizing data retrieval based on specific criteria.
2. Enhanced non-transformed TSS (Improvement)¶
Unlock the power of KDB.AI’s enhanced non-transformed Temporal Similarity Search:
- Expanded numeric search: We've broadened our search capabilities to include all numerical formats (for example,
reals,longs,ints, andshorts), not justfloats, allowing more flexibility in your data searches. - Optional matching vector inclusion: Retrieve the matching vector from your search results for more detailed insights. You’re no longer limited to just the row containing the first element of the matching vector!
- Search by unique column values: Perform searches on each distinct value of a specific column (for example, each ticker symbol), or multiple columns. This eliminates the need for multiple searches and filtering on each unique value.
Tip: Include the matching vector in search results to help your analysts make better decisions. Search by unique column values to streamline data filtering, save time and reduce financial analysis errors. Perform comprehensive queries and enhance the robustness of research analysis with the expanded numeric column search.
3. Range-based similarity search for qFlat index (New)¶
Discover the benefits of setting a distance threshold to improve classification accuracy.
- Customizable queries: Use the keyword
rangeto find all vectors within a distance you define. - Efficient search: Perform similarity searches for all vectors within a specified distance threshold, enhancing search efficiency across large datasets.
- Improved relevance: Range search helps you define relevance more precisely and optimize it for a specific dataset, ensuring more accurate and meaningful results.
Tip: Range-based similarity search for qFlat indexing is particularly beneficial for classification tasks, as it helps provide more precise results compared to traditional k-nearest neighbors searches.
4. Optimized search relevance with reranking capability (New)¶
Unlock the power of KDB.AI’s integration with top rerankers like Cohere, Jina AI, and Voyage, designed to let you reorder query results to match your preferences!
- Enhanced relevance: Rerankers use advanced natural language processing to grasp the intent behind queries, ensuring the most relevant search outcomes.
- Handling complex queries: Rerankers excel at capturing nuances and context, delivering accurate results for even the most complex or ambiguous queries.
- Optimization for specific metrics: Customize search results to meet your unique business goals by optimizing for specific metrics beyond simple relevance.
Tip: Explore reranking in KDB.AI. Enhance search relevance and personalization by learning how to integrate rerankers like Cohere, Jina AI, and Voyage AI within your KDB.AI databases.
5. Multithreading in KDB.AI (New)¶
Boost your application's performance with multithreading! Configure the number of THREADS each worker uses to optimize parallel execution of tasks.
- Parallel task execution: Setting the
THREADSenvironment variable allows tasks to be executed simultaneously across multiple threads, significantly speeding up processing times. - Adaptability: Easily adjust the number of threads to match your server's resources and workload requirements, ensuring optimal performance.
- Optimized resource use: Multithreading distributes the workload more effectively, improving resource utilization and query performance.
Tip: Utilize multithreading for tasks such as qHNSW insert, qFlat/qHNSW searches across partitions, and TSS search across partitions to see significant performance improvements. For a comprehensive understanding of how multithreading works and how to optimize the THREADS variable, refer to the dedicated Multithreading page.
6. Memory-mapping parameter for qHNSW (New)¶
Take your data processing to the next level with the new mmapLevel parameter for qHNSW! This parameter allows you to control how vectors and node connections are accessed during computation.
- Flexible memory access: The
mmapLevelparameter offers three memory mapping options:0for fully in memory,1for vectors memory mapped and nodes in memory, and2for both vectors and node connections memory mapped. - Default setting: If not specified,
mmapLeveldefaults to1, balancing memory usage and performance. - Enhanced control: Adjust the
mmapLevelto suit your specific use case and optimize resource utilization. For example,0grants the fastest performance, while2is the slowest but conserves memory.
Tip: Use mmapLevel to fine-tune your qHNSW index settings for tasks requiring different memory and performance characteristics. For more details on configuring mmapLevel, refer to the How to use indexes - qHNSW documentation.
Documentation¶
- New pages: Tables, Reranking concepts, How to use rerankers in KDB.AI, Partitioning concepts, How to partition data in KDB.AI, and Multithreading.
- Updated pages: Supported data types, Ingest data, How to perform Non-transformed TSS, How to use an index, Manage tables, and API references ( q, Python, REST).
Summary¶
We hope you appreciate the enhancements and new features in v1.5.0. Enjoy exploring all the updates! If you need help, reach out to our Support Team at support@kdb.ai or join our Slack channel.
Thanks for reading. Stay tuned for the next release!
The KDB.AI Team
v1.4.0¶
Release date 2024.10.21
Welcome to the KDB.AI Server 1.4.0 release, crafted to make your vector search experience faster, more consistent and powerful! Key highlights:
- macOS support
- Database layer
- Multiple indexes
- q API
- Version information
- Enhanced REST API
- Optimized kdb+ integration
- Enhanced symbol management
1. macOS support (New)¶
We're excited to announce that KDB.AI is now fully supported on macOS via Docker, bringing you the following benefits:
- Enhanced Performance: Optimized for macOS to ensure smooth and efficient operation.
- Seamless Integration: Easily integrate KDB.AI with your existing macOS workflows and applications.
Tip: macOS users can set up and leverage KDB.AI’s advanced features directly on their devices, boosting productivity and streamlining data management tasks.
2. Database layer (New)¶
We're introducing a new database layer above tables for better data management. Also, you can reference external database tables, such as kdb+ HDB tables.
- Scalability: Reduces redundancy and simplifies handling large datasets, making it more scalable for enterprise use.
- Automatic Setup: A default database is created automatically to ease the initial setup process.
Tip: Use the database layer to organize multiple tables and indexes efficiently, reducing complexity in large-scale environments.
3. Multiple indexes (New)¶
We're thrilled to support multiple indexes that can share the same embedding column. This means there’s no need to duplicate the embeddings. Get ready for:
- Flexible Index Management: Create and manage multiple indexes on a single table for diverse querying needs.
- Simultaneous Searches: Execute searches across different indexes at the same time, ideal for multimodal datasets.
- Dimensional Experimentation: Support for indexes with different dimensions to refine search accuracy.
Tip: Leverage multiple indexes to perform hybrid searches, combining dense and sparse indexes for comprehensive results.
4. q API (New)¶
A fully documented public q API is here, allowing q developers to use KDB.AI’s features within their q environment, empowering you with:
- Reduced Friction: Provides a consistent toolset for developing advanced applications.
- Enhanced Capabilities: Leverage KDB.AI’s power directly in q programming.
Tip: Use the q API to integrate KDB.AI’s advanced search functionalities into your existing q-based applications effortlessly.
5. Version information (New)¶
Quickly access KDB.AI server version information for compatibility checks in q API, Python API, and REST API.
- Deployment Management: Helps ensure consistency across different environments.
- Simplified Troubleshooting: Facilitates easier management of deployments.
Tip: Regularly check version information to maintain compatibility and streamline troubleshooting.
6. Enhanced REST API (Improvement)¶
1.4.0 brings improved adherence to RESTful conventions for a more user-friendly experience:
- Consistent Error Handling: Better error management and troubleshooting tips for reliable application development.
- Developer-Friendly: Enhances the overall developer experience with more intuitive API interactions.
Tip: Use the enhanced REST API to build robust applications with consistent error handling and improved debuggability.
7. Optimized kdb+ integration (Improvement)¶
- Direct Access: Query kdb+ tables directly from KDB.AI, maintaining data integrity while utilizing advanced search features.
- Time Series Analysis: Run Time Series Similarity (TSS) searches on kdb+ tables for insightful decision-making.
- Optimized Indexing: Create indexes on kdb+ data within KDB.AI without altering original tables.
Tip: Use direct table access to seamlessly integrate kdb+ data with KDB.AI’s search capabilities, streamlining your data analysis workflows.
8. Enhanced symbol management (Improvement)¶
Symbol atoms are stored in symfiles, which are used to enumerate symbols in splayed or partitioned databases. Using symbols instead of strings can cause inefficiencies, especially when symfiles become large due to numerous non-distinct values. Using Python bytes objects to avoid too many symbols helps, providing:
- Optimized Storage: Helps in reducing symfile size and improving performance.
- Performance Management: Prevents degradation from large, non-distinct symbol values.
- Effective Data Handling: Ensures efficient data processing and retrieval.
Tip: Use strings instead of symbols for large numbers of distinct values to keep symfile sizes manageable. Symbols are effective when you have many repeated values. If each value occurs only once, use strings instead. For more details, refer to the Kx documentation.
Summary¶
We hope you enjoy the v1.4.0 enhancements and new capabilities. Feel free to explore these updates. If you need assistance, reach out to our Support Team at support@kdb.ai or join our Slack channel.
For a complete list of past features and improvements, visit the previous KDB.AI Server release notes.
Thanks for reading. Stay tuned for our next release!
The KDB.AI Team
v1.3.0¶
Release date 2024.09.19
Requires Python client >= 1.3.0
Welcome to the KDB.AI Server 1.3.0 release! Key highlights:
- Fuzzy filtering on metadata
- On-disk index: qHNSW
- Early Access program
- Data migration
- Integration with Unstructured.io
1. Fuzzy filtering on metadata (New)¶
We’ve added support for fuzzy filtering on metadata, allowing for more flexible and approximate matching in queries. This enhancement significantly improves search relevance and result accuracy, making it easier to find what you’re looking for even with imperfect data.
Fuzzy filters are the ultimate game changers when dealing with data that might include errors, typos, or variations. For instance, applying fuzzy filters to searches allows you to locate documents with terms similar to your query, even if they aren’t an exact match.
Tip
Fuzzy filters have a wide range of applications across various domains. Key use cases include spell checking, data cleaning, autocomplete and suggestions, information retrieval, product matching in e-commerce, name matching in databases, geographic search, and code search.
Discover the concepts behind fuzzy filtering and head to our How to use fuzzy filters section to learn how to apply this method to your searches.
2. On-disk index: qHNSW (New)¶
Introducing the qHNSW index, a high-performance Hierarchical Navigable Small Worlds (HNSW) index that you can store and access directly on disk. This means you can use large indexes without the need for equivalent amounts of RAM, optimizing performance and resource utilization.
When stored on disk, the qHNSW index maintains its hierarchical graph structure, where vertices are connected based on their distances. This setup is crucial for enabling quick and efficient traversal through the graph during searches.
Tip
qHNSW can be extremely handy in several use cases such as web searches, e-commerce, Content-Based Image Retrieval (CBIR), genomic data search, protein structure search, geospatial applications, and financial fraud detection.
Read more about the differences between in-memory vs. on-disk indexes, then learn how to use the qHNSW index.
3. Early Acesss for KDB.AI integration with kdb+ (New)¶
We're thrilled to unveil an Early Access program for KDB.AI integration with kdb+. Participants will be provided with code samples to facilitate an understanding of how to set up this integration. If you're keen on joining, please send us an e-mail to obtain early insights and contribute to the development journey.
More about kdb+/q
kdb+ is a powerful column-based relational time series database (TSDB) with in-memory (IMDB) abilities. Built on top of the q programming language, kdb+ allows to operate directly on data. kdb+ is widely used in High-Frequency Trading (HFT) for storing, analyzing, processing, and retrieving large datasets at high speed.
- Watch this 15-episode series of "Intro to kdb+ and q" tutorials
- Install kdb+
- Get started with q and kdb+
4. Data migration (Improvement)¶
For users of previous versions such as 1.1.0 or 1.2.0 who wish to retain their existing data, please reach out to KX for detailed migration instructions. Our team is ready to assist you in ensuring a smooth transition to the latest version. Feel free to reach out if you have any questions or need further assistance!
5. Integration with Unstructured.io (New)¶
KDB.AI is now a destination connector on Unstructured.io, a popular ETL (Extract, Transform, Load) platform for unstructured data. This makes it much easier to ingest various complex documents into your KDB.AI vector database.
The benefits of this integration are:
- Supports formats like plain text (TXT, XML), documents (CSV, HTML, PDF, and PPTX) and images (PNG, JPG).
- Simplifies and speeds up the efficient transformation of unstructured data into structured formats.
- More accurate LLM-generated RAG responses based on the ingestion of semantically relevant data into your vector database.
Tip
Rely on this integration to process and analyze unstructured data effectively and achieve effortless document extraction. Get ready to improve recommendation systems and chatbots by seamlessly handling both structured and unstructured data.
To see the integration at work, go to the Unstructured integration page and follow the steps.
Summary¶
We hope you enjoy the v1.3.0 enhancements, new index and integrations. Feel free to explore these updates. If you need assistance, reach out to our Support Team at support@kdb.ai or join our Slack channel.
Thanks for reading. Stay tuned for our next release!
The KDB.AI Team
v1.2.4 release notes¶
Release date 2024.08.15
Fixes and improvements
- This update includes several bug fixes and enhancements to improve KDB.AI performance and stability.
- v1.2.2 and v1.2.3 introduced a series of internal changes that significantly enhance KDB.AI reliability and performance.
v1.2.0¶
Release Date 2024.06.27
Welcome to the KDB.AI Server 1.2.0 release! Let's look at the highlights:
- Higher performance – launching a series of significant performance enhancements.
- On disk indexes: qFlat – a Flat index that's not memory bound, leading to major infrastructure savings.
Now check out what's in store for each:
1. Higher performance (Improvement)¶
KDB.AI Server 1.2.0 brings considerable speed-ups, demonstrating KDB.AI’s ability to help you build fast, efficient, accurate, cost-predictable, and scalable solutions for your organization’s projects.
2. On-disk indexes: qFlat (New)¶
Managing indexes on-disk, as opposed to in-memory, provides a low-memory solution for working with large datasets of vector embeddings. That's why the 1.2.0 release introduces an on-disk alternative to the in-memory Flat index.
Labelled qFlat, this index supports all the API create and search capabilities. The only difference is that you need to specify qFlat instead of flat if you prefer the on-disk index to the in-memory one.
Tip
Pick qFlat over Flat if you prioritize capacity over speed. Keep in mind that on-disk is slower but cost-effective, while in-memory is faster but more expensive.
Read more about the differences between in-memory vs. on-disk indexes, then learn how to use the qFlat index.
Note
Please ensure that your data explicitly matches the data type required by your table schema. Not doing this may result in a type error. The example below ensures the correct data type for the StockPrice column.
import numpy as np
table_schema = {
"columns": [
{"name": "StockPrice", "pytype": "float32"},
# rest of schema
]}
df = pd.DataFrame()
df = ReadStockData('stock_price_data.csv')
# Ensure correct stock price type
df['StockPrice'] = [np.float32(x) for x in df.StockPrice]
Summary¶
We hope you'll make the best of the v1.2.0 performance improvements and the new qFlat index. Now feel free to try them out. If you need any help, email our Support Team at support@kdb.ai or join our Slack channel.
Download the latest KDB.AI Server version!
Thanks for reading. Stay tuned for the next release!
The KDB.AI team
v1.1.0¶
Release date 2024.03.13
The KDB.AI Server 1.1.0 release is here! This time we focused on enhancing your KDB.AI toolset with three new searches and an integration. Here are the highlights:
1. Hybrid search – combines a sparse vector search with a dense vector search.
2. Transformed TSS – temporal similarity search for transformed data.
3. Non-transformed TSS – temporal similarity search for non-transformed data.
4. LlamaIndex integration – you can now find KDB.AI in the LlamaIndex library.
5. Azure ML integration - includes the latest OpenAI release 1.17.0 and more notebooks to run tests on.
Now let's see what's in store for each new addition:
1. Hybrid search (NEW)¶
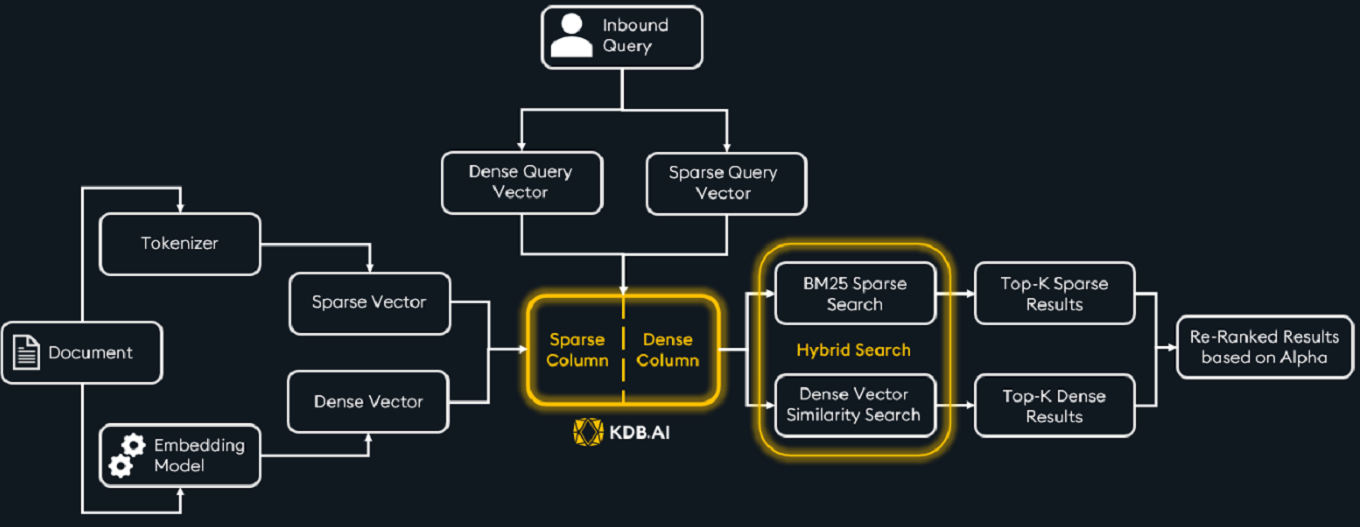
KDB.AI Server 1.1.0 brings a specialized vector search that increases the result relevancy across your applications. It's called a hybrid search and it’s a mix of two powerful search methods:
-
The precision of keyword-based sparse vector search.
-
The contextual understanding of semantic dense vector search.
This means that with KDB.AI, you can now combine and re-rank the results based on a user-set alpha value that weighs the importance of each search type.
Tip
Hybrid search is particularly useful in content recommendation systems, customer support automation, legal document search or human resources and recruitment.
Discover more uses cases on our Learning hub, head to our docs to understand the concepts behind this search method, or even better, learn how to conduct a hybrid search.
2. Transformed temporal similarity search (NEW)¶
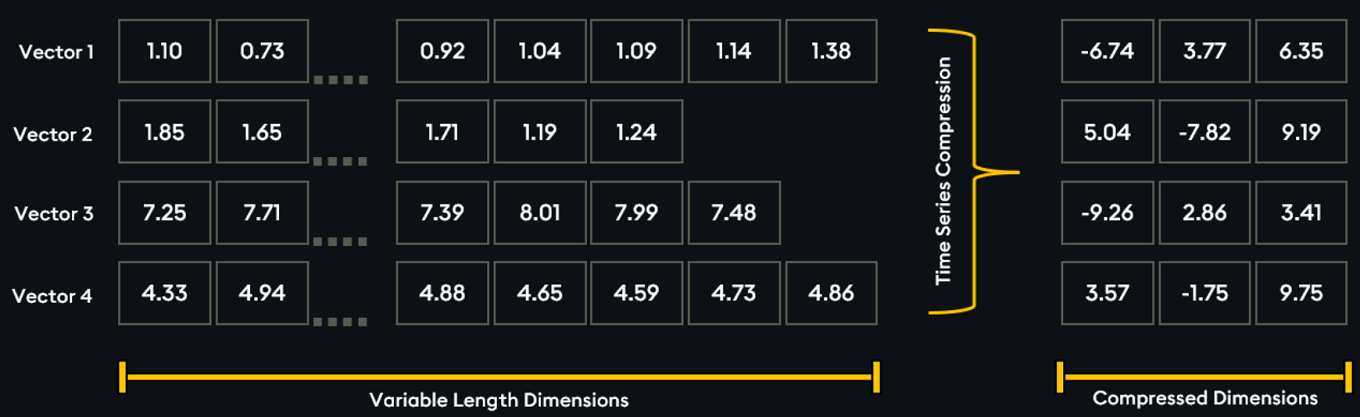
Looking for a compression model that dimensionally reduces time series windows by over 99%, while faithfully preserving the original data’s shape? Using the Transformed TSS method, KDB.AI can store and perform lightning-fast vector searches on time-series data.
This breakthrough enables rapid and profound analytical insights, based on the following:
-
1% of embedding size, 10x increase in search performance.
-
Memory and disk storage can be 1/100th of the original size.
-
Embeddings are auto generated at ingestion; no need for an external model/LLM.
-
When low latency results are more important than low latency data availability.
Leveraging windowed time series data compressed with Transformed TSS on KDB.AI enables the deciphering of emerging trends.
Tip
By providing fast comparison between current data and vast historical datasets, Transformed TSS is a game changer for financial and market predictions; online advertisement optimization, or retail customer understanding.
Head to the KDB.AI Learning hub for detailed use cases, read the docs to understand the main concepts behind this search method, then learn how to perform a Transformed TSS search.
3. Non-transformed temporal similarity search (NEW)¶

KDB.AI Non-Transformed TSS is a groundbreaking algorithm for near real-time similarity searches across fast-moving time series data. This new feature provides:
-
A precise and efficient method to analyse patterns and trends in time series data.
-
No need to embed, extract, or store time series vectors in the database.
-
The ability to re-configure search without requiring the overhead of re-indexing.
Tip
By enabling pattern matching, outlier detection, and near real-time analysis of datasets, you can count on Non-Transformed TSS for financial market analysis, sensor monitoring, cybersecurity threat detection and prevention, and healthcare monitoring.
Explore more use cases on the KDB.AI Learning hub, read our docs to learn the key terms, and learn how to execute a Non-Transformed TSS search.
4. LlamaIndex integration (NEW)¶
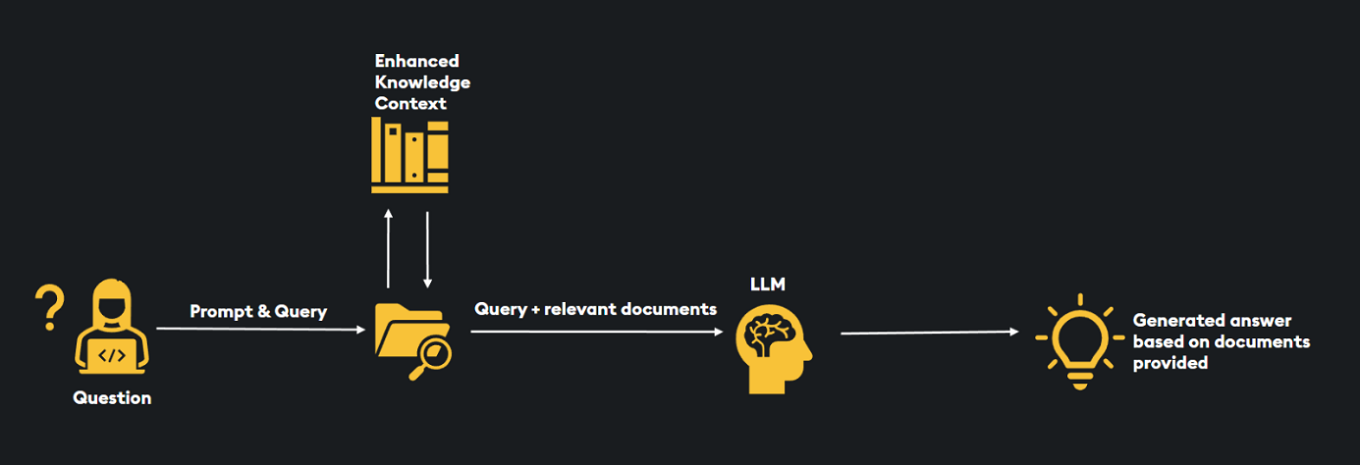
We're thrilled to introduce the integration of KDB.AI on LlamaIndex, a platform that simplifies the storage and retrieval of public and private datasets for RAG-enabled applications. With LlamaIndex and KDB.AI, developers can easily build popular RAG-enabled applications quickly and at scale, without worrying about the technical details and complexities.
The KDB.AI and LlamaIndex integration:
-
Enables LLMs to return dynamic and timely information.
-
Helps reduce memory requirements.
-
Enhances accessibility when contrasted with processing searches via raw embeddings.
-
Augments the LLM’s native output, resulting in a more precise and contextually relevant response to the user’s question.
Tip
You can combine LlamaIndex and KDB.AI to improve variety of applications, such as: document Q&A, data-augmented chatbots, knowledge base, FAQs, workflows, procedures, structured analytics, and content generation (blogs, articles, books, etc.).
Read more details on our LlamaIndex integration page and try our Advanced RAG with temporal filters using LlamaIndex and KDB.AI vector store notebook.
5. Azure ML integration (Improvement)¶
The Azure Marketplace package allows you to deploy an Azure ML studio, with an integrated KDB.AI Server 1.1.0. This includes the following third party dependencies:
-
KDB.AI client 1.1.0
-
LangChain OpenAI 0.1.1
-
OpenAI 1.17.0
Discover 6 new example notebooks, together with a much richer and extended set of data you can leverage to run your notebook tests on.
Read more about the Azure setup.
Summary¶
We hope you’re as excited as we are about the new KDB.AI Server searches and the LlamaIndex integration. Try them out and email our Support Team at support@kdb.ai or join our Slack channel if you need any help.
Download the latest KDB.AI Server version!
Thanks for reading. Stay tuned for the next release!
The KDB.AI team
v1.0.0¶
Release date 2023.11.27
New
- Introducing REST API support, including
insertandtrainfunctions.
v0.2.0¶
Release date 2023.11.03
Fixes and improvements
- Minor fixes and performance improvements
v0.1.2¶
Release date 2023.10.17
Fixes and improvements
- For KDB.AI Server instances it is no longer required to specify a hostname with an ordinal parameter (-h). If a hostname does have an ordinal parameter then the environment variable
RT_NO_ORDINALmust be set to0.
v0.1.1¶
Release date 2023.09.27
Fixes and improvements
-
Fixed issues with training functionality surrounding CPU instructions on certain machines.
-
Improved behavior surrounding synchronous API calls, including
createanddrop. -
Improved responses from similarity search API by removing unneeded empty rows.
v0.1.0¶
Release date 2023.09.12
New
Introducing the first public release of KDB.AI.
- Supported by Python clients with version less than or equal to
0.1.1