Kafka (Subway)
No kdb+ knowledge required
This example assumes no prior experience with q/kdb+ and you can replace the endpoints provided with other Kafka brokers to gain similar results.
Kafka (Subway)
Apache Kafka is an event streaming platform that can be easily published to and consumed by the KX Insights Platform. The provided Kafka feed has live alerts for NYC Subway trains containing details such as arrival time of train, stop location coordinates, direction and route details, all as part of the subway data set.
Creating the Pipeline
First select the import wizard; the import wizard can be accessed from the [+] menu of the Document bar or by clicking  from the left-hand icon menu or Overview page. All created pipelines, irrespective of source, are listed under Pipelines in the left-hand entity tree menu.
from the left-hand icon menu or Overview page. All created pipelines, irrespective of source, are listed under Pipelines in the left-hand entity tree menu.
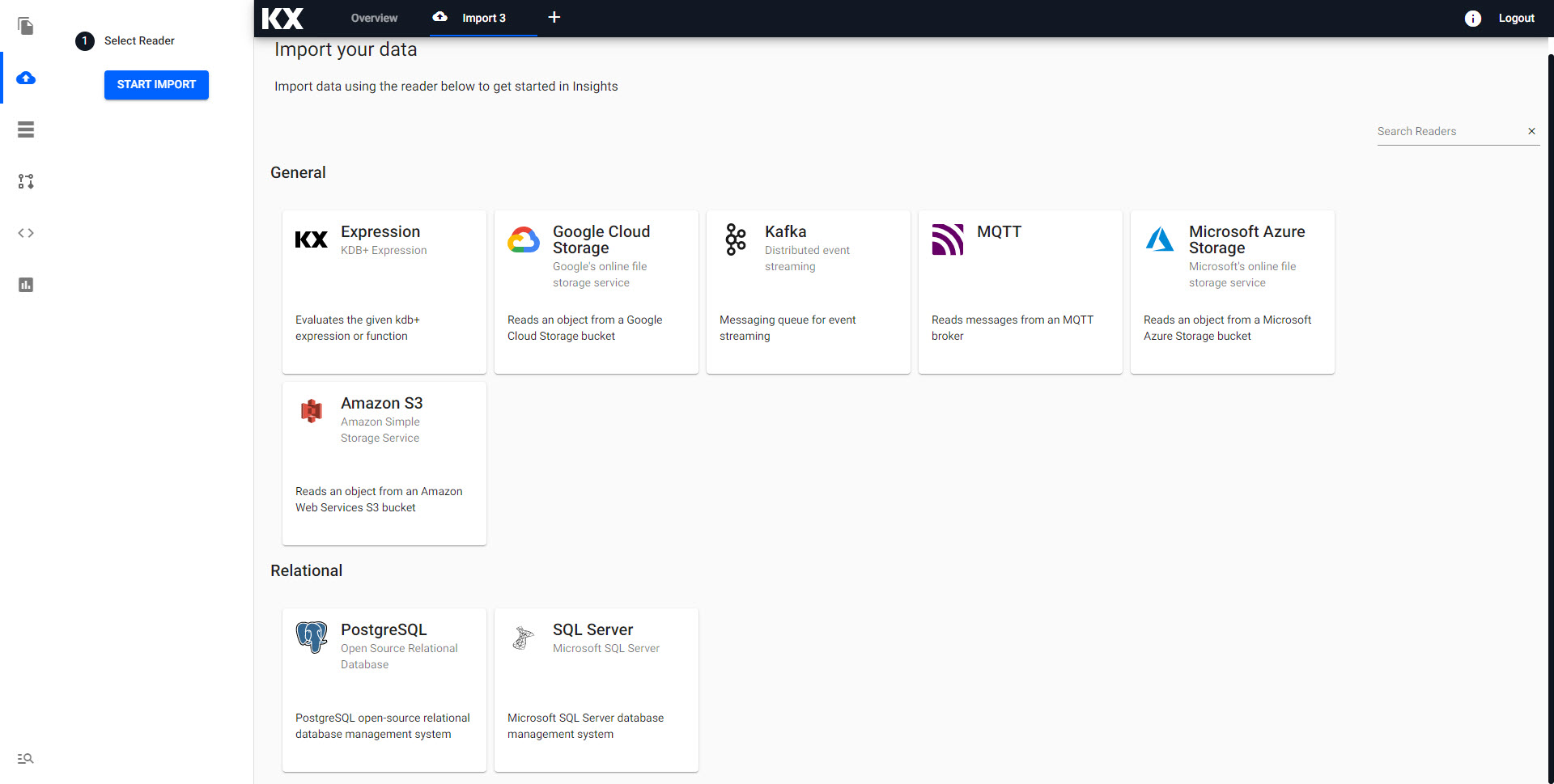
Select a Reader
Select Kafka from the import options
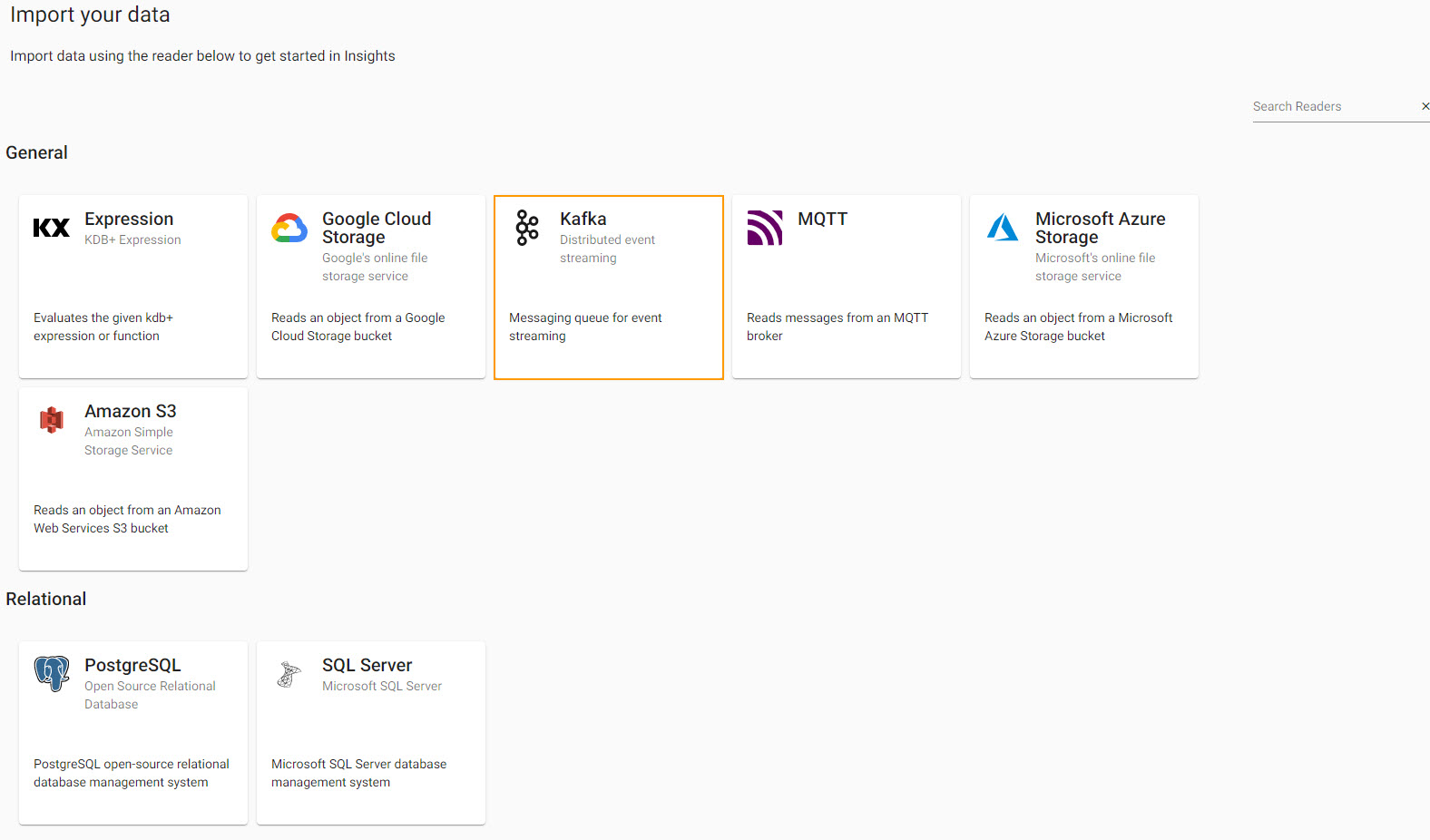
Configure Kafka
| setting | value |
|---|---|
| Broker* | 34.130.174.118:9091 |
| Topic* | subway |
| Offset* | End |
| Use TLS | No |
Click Next when done.
Select a Decoder
Event data on Kafka is of JSON type; select the related decoder to transform the imported data to a kdb+ friendly format (a kdb+ dictionary).
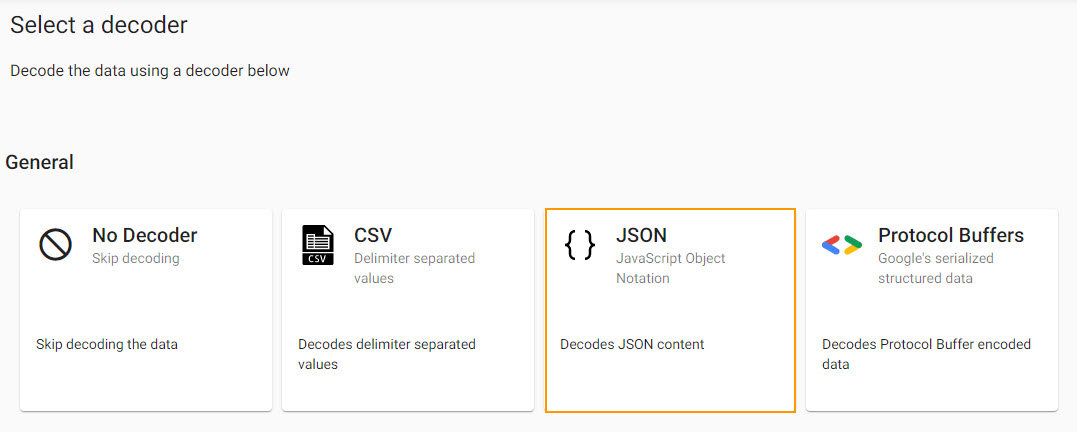
Click Next when done.
Configure JSON
The next step is a decoder step specific to JSON, and defines whther the decode parse should be done on each value. This can be left unchanged.
Click Next when done.
Configure Schema
Imported data requires a schema compatible with the KX Insights Platform. The insights-demo has a predefined set of schemas for each of the data sets available in Free Trial, referenced in the schema table. The configure schema step applies the kdb+ datatypes used by the destination database and required for exploring the data in Insights, to the data we are importing.
The next step applies a schema to the imported data.
| setting | value |
|---|---|
| Apply a Schema | Checked |
| Data Format | Table |
To attach the schema to the data set:
-
Leave the Data Format as the default value of
Any -
Click

-
Select the
insights-demoSchema from the dropdown
-
Choose the Table
subway
-
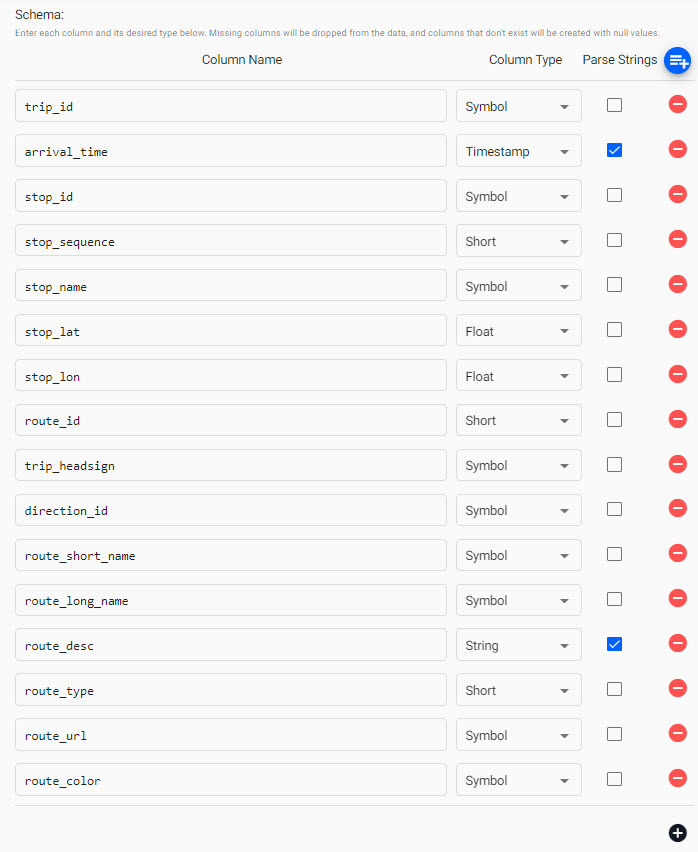
Check Parse Strings for the
arrival_timeandroute_desccolumns. This is an essential step, and may cause issues during pipeline deployment if incorrectly set.Parse Strings
This indicates whether parsing of input string data into other datatypes is required. Generally for all time, timestamp, and string fields, Parse Strings should be ticked unless your input is IPC or RT.
Click Next when done.
Configure Writer
The final step in pipeline creation is to write the imported data to a table in the database. With Free Trial we will use the insights-demo database and assign the imported data to the subway table.
| setting | value |
|---|---|
| Database | insights-demo |
| Table | subway |
| Deduplicate Stream | Yes |
Click  when done. This will complete the import and open the pipeline in the pipeline viewer
when done. This will complete the import and open the pipeline in the pipeline viewer
Writer - KX Insights Database
The Writer - KX Insights Database node is essential for exploring data in a pipeline. This node defines which assembly and table to write the data too. As part of this, the assembly must also be deployed; deployments of an assembly or pipeline can de done individually, or a pipeline can be associated with an assembly and all pipelines associated with that assembly will be deployed when the latter is deployed.
Pipeline view
The pipeline view allows you to review and edit your pipeline by selecting any of the nodes.

Additional functionality is required to convert this particular Kafka import to a kdb+ table before it's deployed. This can be done by inserting a Function node into the pipeline created by the import wizard.
From the Pipeline entity-tree menu, select the Map function and drag this inside the pipeline workspace
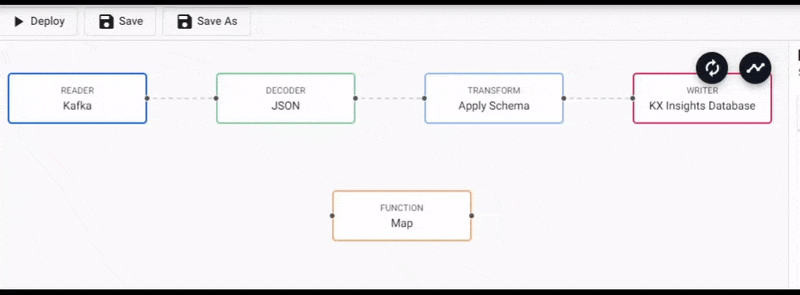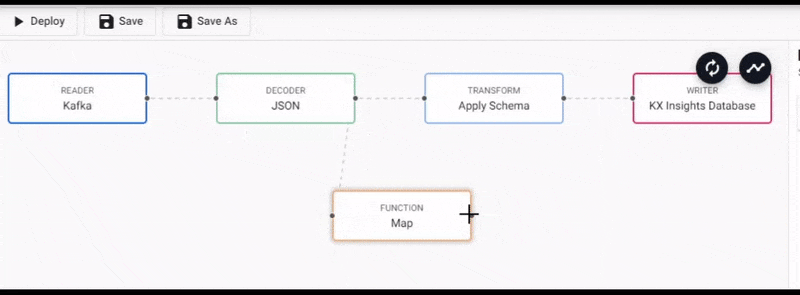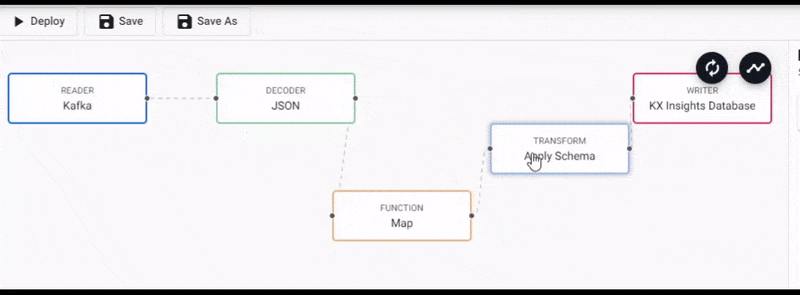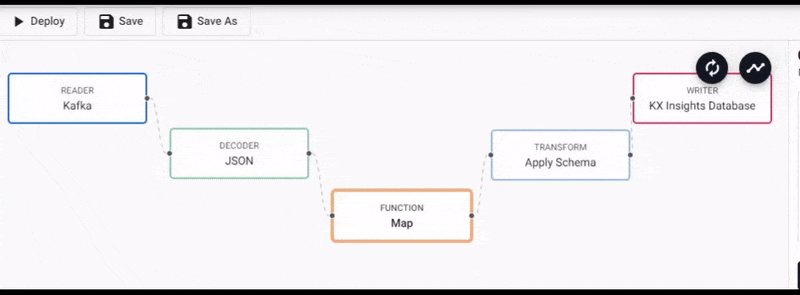
We will connect this to the pipeline between the Decoder and Transform nodes and right-click on the connection between the Decoder and Tranform nodes to remove it, as shown below.
Select the Map function node to edit its properties
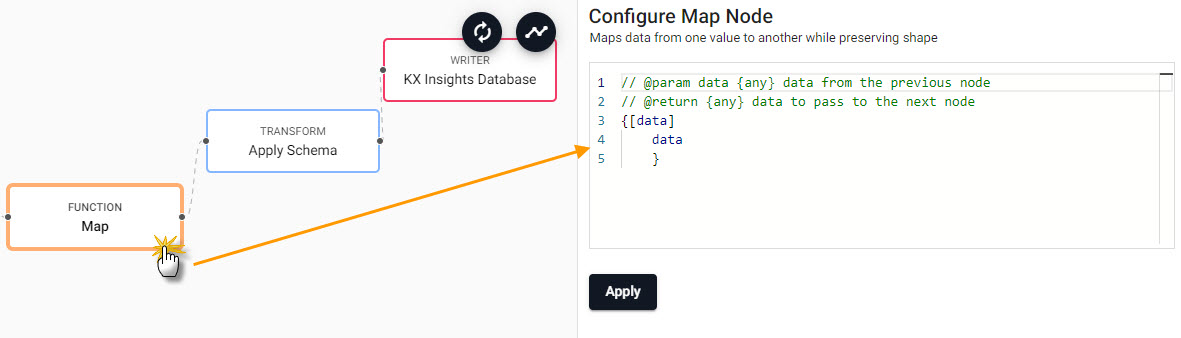
The Map function will transform the kdb+ dictionary format using enlist. To achieve this, copy-and-paste into the Configure Map Node code editor the following kdb+/qand select Apply.
{[data]
enlist data
}Save the pipeline; the pipeline name should be unique; for Free Trial, there is a pipeline already named subway, so give this new pipeline a name like subway-1.

The newly created pipeline will now feature in the list of pipelines in the left-hand-entity tree.
Deploying
The next step is to deploy your pipeline that has been created in the above Importing stage; for Free Trial, there is a pipeline already named health, so give this new pipeline a name like health-1.
-
Save your pipeline giving it a name that is indicative of what you are trying to do.
-
Select Deploy.
-
Once deployed you can check on the progress of your pipeline back in the Overview pane where you started.
-
When it reaches
Status=Runningthen it is done and your data is loaded.
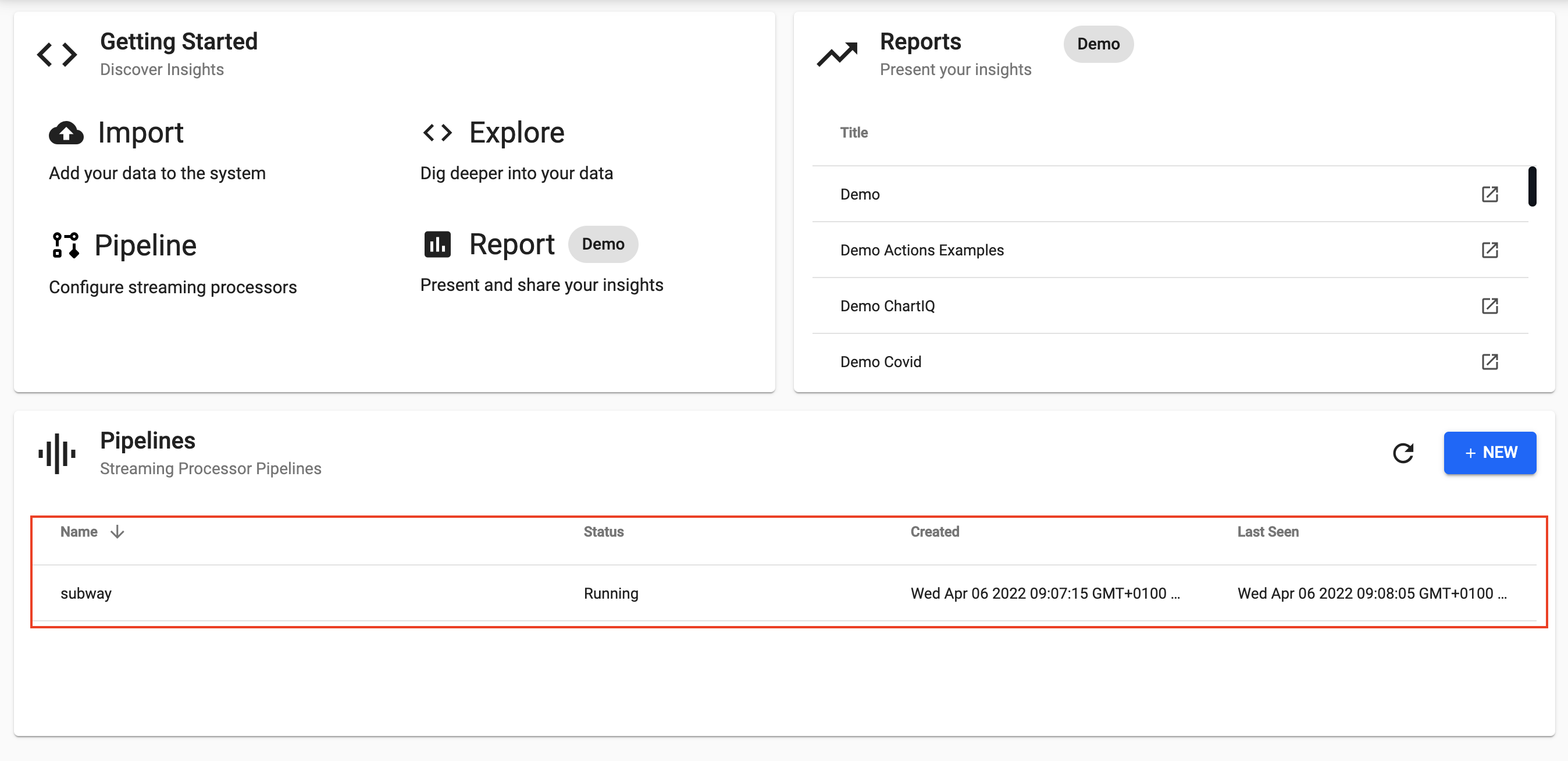
I want to learn more about Pipelines
Exploring
Select Explore from the Overview panel to start the process of exploring your loaded data. See here for an overview of the Explore Window.
In the Explore tab there are a few different options available to you, Query, SQL and q. Let's look at SQL.
You can run the following SQL to retrieve count of the subway table.
SELECT COUNT(*) FROM subwayOutput Variable and then select Get Data to execute the query.
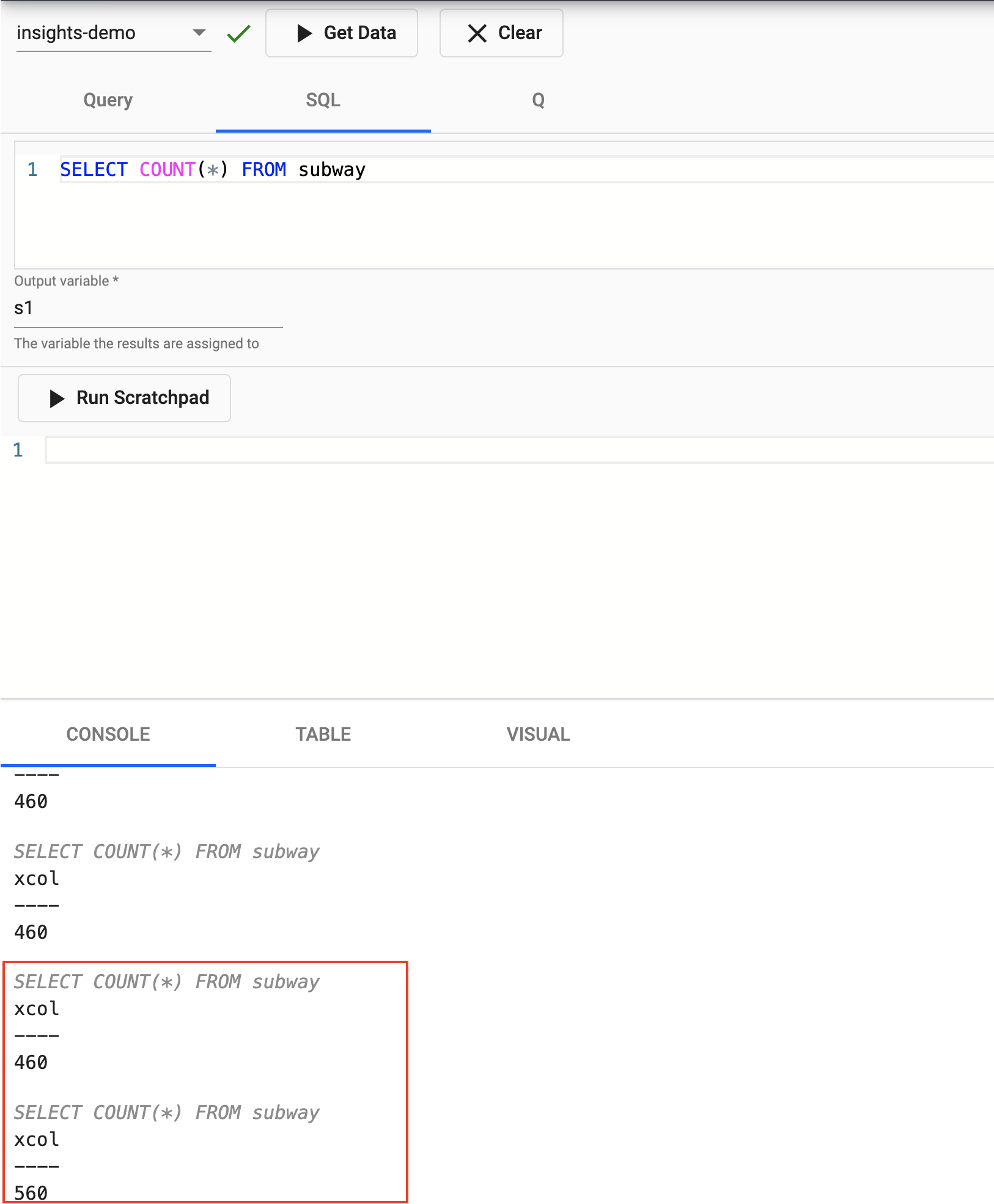
Rerunning this query a short while later you should notice the number increase as new messages appear on the Kafka topic and are ingested into the kdb+ table. You have just successfully setup a table consuming live events from a Kafka topic with your data updating in real time.
Refresh Browser
You may notice a delay when waiting for your SQL output but this is as expected due to the frequency of the live data. If this is the case, it is a good idea to refresh your browser and retry.
Troubleshooting
If the tables are still not outputting after refreshing your browser, try our Troubleshooting page.
Let's ingest some more data! Try next with the PostgreSQL Dataset on Health Data.