Queueing, retries, and timeouts
On receipt of an API request, the Resource Coordinator (RC) attempts to distribute the request to one or more Data Access Processes (DAPs) according to its routing rules (see Routing). The DAPs execute the API and send their results to the chosen Aggregator, which aggregates and returns the results to the Gateway (GW). Certain conditions may cause the request to be delayed at different stages of the query path.
-
RC
Based on reference data, the RC may retry portions of a request.
-
RC to DAP
The RC may determine that no DAPs are able to satisfy one or more portions the query. In this case, the RC queues those request portion(s) until appropriate DAPs become available. See Queueing.
Note: Even if the RC queues some portions of the request, it sends out all portions that it's able to send immediately. Thus it is possible for some portions of the request to be executing in the DAPs while some portions are queued in the RC.
-
DAP
If a DAP purview changes after the RC sent work to it and before the DAP updated the RC, upon receipt of a request portion, the DAP may determine that there is a mismatch between the data it contains and the data the RC thought it had when it issued the request. In this case, the DAP requests that the RC retry this request portion and logs a purview mismatch.
If a request cannot complete within the specified timeout period, a timeout error is returned to the caller. See Timeouts.
Queueing
The RC only sends requests to feasible DAPs. The RC breaks up requests into portions based on label sets and/or time (see Routing). If there are no feasible DAPs to service a portion of the request, then the portion is queued. The RC is able to receive and process other requests while holding items in the queue. The RC moves request portions out of the queue as DAPs that can service them become available (see Dequeueing).
Queue size
Queue size is surfaced via the kxi_rc_queue_length metric.
Dequeueing
The RC attempts to dequeue request portions when a DAP does one of the following:
- Registers with the RC (on initial DAP-RC connection)
- Updates its status (after end-of-day/interval or log replay, see DAP availability)
- Completes a prior request
When a DAP does any of the above, the RC compares it to the items in the queue. The DAP can service an item in the queue if all the following conditions are true:
- The queued item's label set must be the same as the DAP's label set (see Labels).
- If at least one portion of the request has already been dispatched to one of the RC's DAPs for this label set, then this DAP's reference vintage must match the reference vintage of the label set at the time the first portion was dispatched. This ensures requests are always executed against a consistent reference vintage. Conversely, if no portion of the request has been dispatched for this label set, then the DAP must be up-to-date.
- If the request has a time component, the DAP's temporal purview (see Temporal purview) must intersect the request portion's time range.
If the DAP can service more than one item in the queue, then the RC chooses the oldest queued item. If the request has no time component, then the RC sends the entire queued item to the DAP and deletes the item from the queue. If the request does have a time component, then the RC sends only the intersection of the DAPs temporal purview with the time range of the request. The RC deletes the queued item and requeues any leftover portions, as illustrated in the following diagrams.
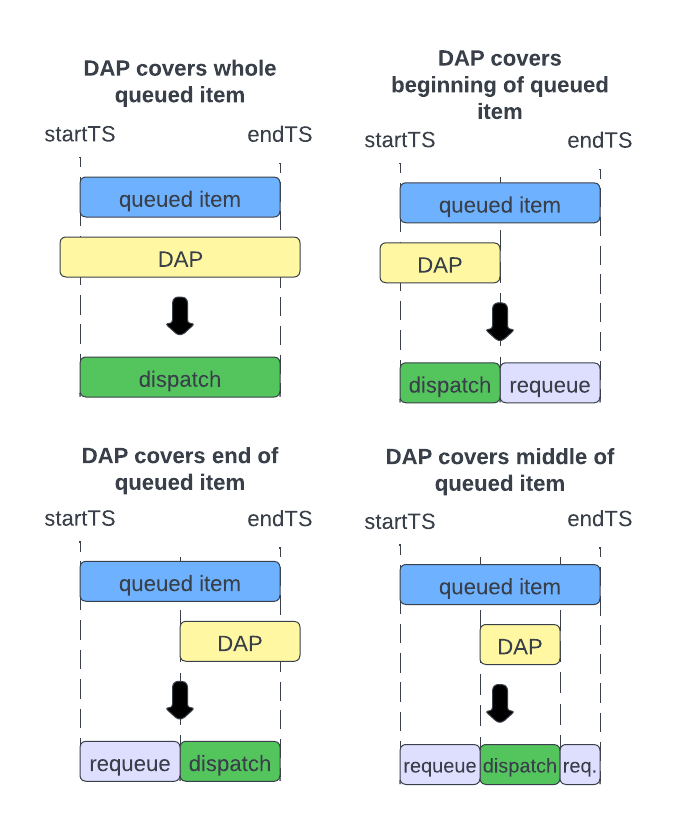
Retries
The RC retries requests (or portions of requests) if there has been a material change in the data reported by the DAPs while in a partially completed state. The situations in which this can happen are described below.
Retries happen automatically, and are generally opaque to the caller; on a successful query, the only evidence of the retry is found in the RC and/or DAP logs. However, if the number of retries exceeds the maximum configured number of retries (controlled by the KXI_SG_MAX_RETRY environment variable in the RC, which by default is 3), then the request fails. See Troubleshooting.
Purview version and reference vintage mismatch
There are two high watermark values that the DAPs and RCs maintain in order to guard against race conditions where the data the DAP holds changes at the same moment the RC selects it to service a request.
-
Purview version:
At registration and after each end-of-interval or end-of-day event, the DAP sends an increment value to the RC.
-
Reference vintage:
At registration and on each reference data update, the DAP sends its latest stream position to the RC .
When sending a request to a DAP, the RC includes both the purview version and the reference vintage in the request header. On receipt of the request, the DAP checks that these header values match the corresponding current high watermarks. If both values match, the DAP processes the request as normal. If either value doesn't match, the DAP responds to the RC with a RETRY return code (see Codes). The RC attempts a retry if the maximum retry threshold has not been met. The RC retries all required tiers for the entire label set.
Reference vintage change
The RC sends requests only to DAPs that are up to date. When the RC sends a request portion to a DAP, it "locks" the reference vintage for that DAP's label set. That is, all future portions for that label set are sent only to DAPs of the same reference vintage. For a single label set, if at any point in time all the following conditions are true:
- there is queued entry for the label set,
- the reference vintage for the label set is locked,
- the reference vintage for all DAPs of the label set are greater than the locked reference vintage,
then the RC retries the request portion for that label set.
Example:
Suppose we have two assemblies labelled as follows:
# Assembly 1.
labels:
foo: bar1
# Assembly 2.
labels:
foo: bar2
The RC receives a request with the following purview: `foo`startTS`endTS!(`bar1`bar2;-0Wp;0Wp). The DAPs at its disposal are:
dap |
avail |
foo |
startTS |
endTS |
refVintage |
|---|---|---|---|---|---|
dap-1-1 |
0b |
bar1 |
-0Wp |
2022.12.05D |
10 |
dap-1-2 |
0b |
bar1 |
-0Wp |
2022.12.05D |
10 |
dap-2-1 |
1b |
bar1 |
2022.12.05D |
0Wp |
10 |
dap-3-1 |
1b |
bar2 |
-0Wp |
2022.12.05D |
20 |
dap-4-1 |
0b |
bar2 |
2022.12.05D |
0Wp |
20 |
The RC sends portion foo=bar1 for [2022.12.05D;0Wp) to dap-2-1, locking refVintage=10 for foo=bar1. Likewise, the RC sends portion foo=bar2 for [-0Wp;2022.12.05D) to dap-3-1, locking refVintage=20 for foo=bar2. The remaining portions of the request are queued (see Routing for more information on RC routing decisions).
Suppose that, while the request portions are queued, the RC receives an update from dap-4-1 that its reference vintage is now 21. The RC retries the request for label foo=bar2, since it can no longer satisfy [2022.12.05D;0Wp) at reference vintage 20.
Suppose further that the RC receives an update from dap-1-1 that its reference vintage is now 11. The RC does nothing since dap-1-2 is still at reference vintage 20 and can satisfy the request. Note, however, that the RC will not send this request to dap-1-1, since its reference vintage (21) no longer matches the request's reference vintage for this label (20).
Special behavior - SQL
The retry logic for the .kxi.sql API differs in the following ways.
- In addition to the circumstances listed above, retries are also triggered on date rollover. That is, if the RC attempts to dequeue an item for a SQL request and the date has changed since the request was first queued, then the RC triggers a retry.
- When a retry is triggered, if the date has changed, or if any DAP purview has changed, the request is completely restarted (all portions for all label sets).
Timeouts
Timeouts occur when the request cannot be completed in the allotted time. The default timeout for API requests is controlled by the KXI_SG_TIMEOUT environment variable. If left undefined, the default timeout is 30 seconds (see Configuration). Timeout can also be set on a per-request basis in the timeout parameter in the request's opts dictionary (see Querying methods ). Both the GW and the RC monitor outstanding requests for timeouts. One or the other (but not both) may issue a timeout response in the case that a request times out. Both the GW and RC issue the following return and application codes in the response header :
| code | name | value |
|---|---|---|
return code (rc) |
TIMEOUT |
45 |
application code (ac) |
ERR |
10 |
The Application Information (ai) of the response differs depending on the source. See RC timeout message and GW timeout message.
RC timeout message
The RC checks for timed out requests on a timer. The timer runs every 10 seconds. Note, however, that the DAP and Agg run their request execution using the timeout system command. Thus, the DAP or Agg may respond to the RC and notify it of the timeout immediately. For requests spanning multiple RCs, a secondary RC may be the first to detect the timeout, in which case it notifies the primary RC. In either case, the (primary) RC's timeout logic remains the same. The RC attempts to give as much detail as possible for why the request timed out in the ai field of the response header. The timeout message is of the following form.
Request timed out, [rc=<rc host/port>;status="<request status>";...] ...
There is one [...] block for each RC participating in the request, with the primary RC appearing first, followed by the secondary RCs (if any). Each [...] block always contains the RC's address, the request status, and some number of additional fields, which depend on the request status. The possible statuses, the additional fields they report, and some examples, are all described below.
-
allocating
The RC has not completed allocating the request, i.e. one or more request portions are queued. The RC reports one, but not both, of the following additional fields:
-
error: String whose value is always"Empty queue encountered". This indicates that the request is in the "allocating" status, but no queued items for the request could be found. This indicates a bug. -
queue: String describing why each queued portion could not be allocated to DAPs. The string consists of one or more[...]blocks, the contents of which are determined by the routing properties of the data (i.e. table) being requested (see Routing - Table):-
If requesting partitioned data,
[labels=<dictionary>;startTS=<timestamp>;endTS=<timestamp>;reason=<string>;dap=<list of dap host/ports>] -
If requesting sharded, non-partitioned data,
[labels=<dictionary>;reason=<string>;dap=<list of dap host/ports>] -
If requesting non-sharded, non-partitioned data,
[reason=<string>;dap=<list of dap host/ports>]
In the above,
labels: Key-value pairs of this portion of the request.startTS: Start time (inclusive) of this portion of the request.endTS: End time (exclusive) of this portion of the request.dap: List of DAPs (host/port) that could have satisfied this portion of the request, but could not be allocated becausereason. Note that this list is empty if no DAP could satisfy this request portion.-
reason: String description of the reason the DAPs listed could not be enlisted to service this portion of the request. Possible reasons include:-
"No DAP covers labels/time range"Indicates that no DAPs exist for this label set that cover the specified time range. Note that this is accompanied by an empty
daplist. -
"Busy executing another API"Indicates that the listed DAPs are unavailable because they are currently executing other requests.
-
"Unavailable for unspecified reasons"Indicates that the listed DAPs are unavailable, but they are not executing other requests. Reasons for DAPs being unavailable are listed in DAP availability.
-
"DAP reference vintage <number> does not match {queue|global} reference vintage <number>"Indicates that the listed DAPs are of an outdated or incorrect reference vintage. We use "queue" to reference the "locked" reference vintage if the reference vintage has been locked for this request portion (seeReference vintage change), and "global" to reference the maximum reference vintage among all DAPs within the label set if the reference vintage has not been locked for this request portion (see DAP up-to-dateness).
-
"Unknown reason for not assigning request portion to DAP(s)"Indicates that the RC cannot determine why it did not allocate this request portion to one or more of the listed DAPs. This likely indicates a bug.
-
There is one
[...]block per distinct request portion andreason. Note that a request portion may have been allocated to a DAP for more than one reason. In this case,reasonis a comma-delimited list of all applicable reasons. -
Example:
// Error, indicates a bug. [rc=`:127.0.0.1:5060;status="allocating";error="Empty queue encountered"] // Nominal case - partitioned data. [rc=`:127.0.0.1:5060;status="allocating";queue="\ [labels=`label1`label2!`a`x;startTS=2022.10.05D00:00:00.000000000;endTS=2022.10.06D00:00:00.000000000;reason=\"No DAP covers labels/time range\";dap=`symbol$()] \ [labels=`label1`label2!`b`y;startTS=2022.10.08D00:.000000000;endTS=0Wp;reason=\"Busy executing another API, DAP reference vintage 19 does not match queue's reference vintage 15\";dap=,`:dap-rdb:5080]"] // Nominal case - sharded, non-partitioned data. [rc=`:127.0.0.1:5060;status="allocating";queue="\ [labels=`label1`label2!`a`x;reason=\"Busy executing another API\";dap=`:dap-rdb-0:5080`:dap-idb-0:5090`:dap-hdb-0:5100] \ [labels=`label1`label2!`b`y;reason=\"Unknown reason for not assigning request portion to DAP(s)\";dap=dap=`:dap-rdb-1:5080`:dap-idb-1:5090`:dap-hdb-1:5100]"] // Nominal case - non-sharded, non-partitioned data. [rc=`:127.0.0.1:5060;status="allocating";queue="\ [reason=\"Busy executing another API\";dap=`:dap-rdb-0:5080`:dap-idb-0:5090`:dap-hdb-0:5100] \ [reason=\"Unavailable for unspecified reasons\";dap=`:dap-rdb-0:5080`:dap-idb-0:5090`:dap-hdb-0:5100]"]In addition to the above reasons, there is one additional reason that may occur only for the
.kxi.sqlAPI:"Required DAPs dropped". This indicates that the request specifically required the listed DAPs, but they dropped from the RC undected. This indicates a bug. -
-
executing
The RC has fully allocated the request to the DAPs, but one or more DAPs have not completed executing. The RC reports the following additional fields:
dap: List of DAPs (host/port) that are currently executing.
Example:
[rc=`:127.0.0.1:5060;status="executing";dap=`:dap-rdb:5080`:dap-idb:5090] -
completed
Only reported from secondary RCs. All DAPs for this RC have completed the request, hence the request timed out elsewhere. This status provides no additional fields to the timeout message.
Example:
[rc=`:127.0.0.1:5060;status="completed"] -
aggregating
Only reported from the primary RC. All DAPs (from all RCs) have completed execution and the response is waiting for aggregation to finish. The RC reports the following additional fields:
agg: The address of the aggregator responsible for aggregating the request.
Example:
[rc=`:127.0.0.1:5060;status="aggregating";agg=`:127.0.0.2:5070] -
pending aggregation
Only reported from the primary RC when there is at least one secondary RC participating in the request. All DAPs from the primary RC have completed, but at least one DAP from a secondary RC has not yet completed. The DAP(s) that have not completed should appear in
[...]block(s) of their respective secondary RCs under the "executing" status. The (primary) RC reports the following additional field:agg: The address of the aggregator responsible for aggregating the request.
Example:
[rc=`:127.0.0.1:5060;status="pending aggregating";agg=`:127.0.0.2:5070] [rc=`:127.0.0.3:5060;status="executing";dap=,`:dap-hdb:5100] -
inactive
The request is inactive. This occurs if the request has errored, but a response has not yet been issued to the caller. This can occur, for example, if a DAP errors when executing the API, but successfully reports its error to the aggregator. In this case the RC leaves the aggregator to respond, but the timeout may occur before the aggregator has had a chance to do so. The additional fields reported by vary by case.
- If there are DAPs within this RC that have not completed their portion of the request:
dap: List of DAPs (host/port) that are currently executing.
- If all DAPs within this RC have completed the request and this RC is the primary RC:
agg: The address of the aggregator responsible for aggregating the request.
- If all DAPs within this RC have completed the request and this RC is a secondary RC, then the RC does not report any additional fields.
Example:
[rc=`:127.0.0.1:5060;status="inactive";agg=`:127.0.0.2:5070] - If there are DAPs within this RC that have not completed their portion of the request:
-
received too late
Only reported from a secondary RC. This status occurs during race conditions where the secondary RC receives the request from the primary RC only after it has already timed out. The RC does not include any additional fields.
Example:
[rc=`:127.0.0.1:5060;status="received too late"] -
unknown
A timeout has been issued, but the status of the request for this RC is unknown or unexpected. If this appears for the primary RC, it indicates a bug. However, for a secondary RC, this typically indicates that it has not reported its status to the primary RC within the configured time threshold. When the primary RC detects a timeout, it allows a certain number of 10 second timer iterations for the secondary RCs to report their request statuses. The number of iterations the primary RC is prepared to wait is controlled by the
KXI_SG_MULTI_RC_TO_MAX_WAITenvironment variable. If not specified, the default is 1 (see Configuration). If not all secondary RCs have reported within this number of iterations, the primary RC composes the timeout message and leaves any unreported secondary RCs in the "unknown" state. This is accompanied by a debug log message in the primary RC ("Exhausted number of retries waiting for other RCs to report timeout (max=%n), composing incomplete timeout message"). This does not necessarily indicate a bug, however, unreported secondary RCs may be burdened by high request loads.Example:
[rc=`:127.0.0.1:5060;status="unknown"]
In the case that the RC errors when composing the timeout message (bug), the ai field of the response header is simply "Request timed out, but error encountered composing message: " followed by the error it encountered.
GW timeout message
The GW times out a request only when the RC has failed to do so within an acceptable period of time. This behavior is controlled by the KXI_SG_TIMEOUT_MARGIN environment variable (see Configuration). If unset, the default is 30000 (i.e. 30 seconds). The GW waits KXI_SG_TIMEOUT_MARGIN milliseconds after a request has timed out for the RC to issue the timeout response. If the RC has not done so within that time, the GW issues the timeout response. The ai of the response is a generic "Request was timed out by the service gateway", since, unlike the RC, it has no inside knowledge of the request status.