Import
Import is a guided process for importing data from a number of different sources, including cloud and relational data services.

Available data sources to import data from.
Set up
-
Select a data source; a guided walkthrough for Object Storage, Kafka or SQL database imports are available.
-
Complete the workflow, then
Open Pipeline. -
Changes can be made in the pipeline; for example, for Kafka import it is necessary to include a Map function. Save the pipeline when complete.
-
Save the pipeline (giving it a name in the process).
-
Deploy the pipeline to an active assembly, or deploy the data assembly along with its associated import pipeline(s). A deployed data assembly that is ready to query will show a green circle with a tick inside it. The status of a pipeline will be available listed under Pipelines in the Overview page; a successfully deployed pipeline will be listed as
Runningunder Status and will have a green tick next to it.Guided Walkthrough
If using a guided walkthrough example, deploy the
insights-demoassembly before deploying the pipeline. -
Open a Query tab to query the data. Opening the SQL tab is the quickest way to get data:
SELECT * FROM tablename
Advanced Settings
Each pipeline created by the Import wizard will have an option for Advanced pipeline settings. It should be noted, no additional code is required for the standard import options described below. The Advanced settings include Global Code which is executed before a pipeline is started; this code may be necessary for Stream Processor hooks, global variables and named functions.
Schema Column Parsing
Parsing is done automatically as part of the import process. If defining a manual parse, ensure parsing is enabled for all time, timestamp, and string fields unless your input is IPC or RT.
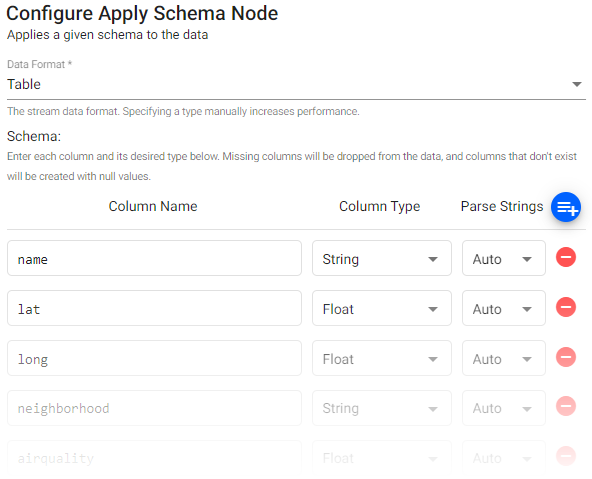
Parsing is done automatically, but it should be done for all time, timestamp and string fields if not automatic.
Kafka
Connect to an Apache Kafka distributed event streaming platform.
-
Define the Reader node with the Kafka broker details, port information and topic name.
Sample Kafka Reader Node
- Broker: kafka:9092
- Topic: trades
- Offset: Start
-
Event data on Kafka is of JSON type, so use a JSON decoder node to transform the data to a kdb+ friendly format. Data will be converted to a kdb+ dictionary. There is no need to change the default setting for this.
JSON decode
- Decode Each: false
-
Apply a Schema with the Transform node; this ensures data is of the correct datatype in the destination database.
Parse Stringscan be left asAuto; but ensure any time, timestamp and string data columns is set toOnorAuto. During the Import process you can select a schema from a selected assembly; it's recommend the following schema be configured as a table in an assembly schema - to this, use the assembly-wizard to create a database and add a schema table for the data to import.Sample Kafka transform for trades
- Date Format: Any
column name column type parse strings datetime Timestamp Auto ticker Symbol Auto price Float Auto size Integer Auto -
Write the data to a table.
- Database
- Select an database from the dropdown to assign the data, or create a database by clicking
 before returning to the pipeline to add this newly created database.
before returning to the pipeline to add this newly created database. - Table
- Select a table from the selected database to write the data too; this is typically the schema table from the previous step. If not already completed, create a table with a schema matching that of the previous step and assign it here. During the database wizard creation process is a step for creating a table (and schema); tables can be added to its schema.
- Deduplicate Stream
- Can remain checked.
-
Open the Pipeline view
-
Include a Map function to convert the data from a kdb+ dictionary to a kdb+ table. This Map function should be inserted between the JSON Decoder of Step 2 and the Transform Schema of Step 3 in the pipeline view; see image below:

A completed Kafka pipeline.Map function
{[data] enlist data } -
Save the Pipeline
-
Deploy the Data assembly with associated Kafka pipeline.
-
Query the data. Use the trades topic as the
Output variable. This will be the name of the table to query when getting data; for example, SQL query:SQL query
SELECT * FROM trades -
Get Data
The Broker field can be the Kafka broker pod name when the Kafka broker is installed in the same Kubernetes namespace as the KX Insights Platform. If the Kafka cluster has been installed into a different Kubernetes namespace, then the field expects the full service name of the Kafka broker - i.e. kafka:9092, where default is the namespace that the Kafka cluster is in. The full-service name is set in the KX_KAFKA_BROKERS environment variable property in the Kafka Producer Kubernetes installation instructions.
See the guided walkthrough Kafka import example.
Kdb Expression
Import data directly using a kdb+ expression.
-
The Kdb Expression Reader starts with a code editor; add the following kdb+ data generator in the node editor:
kdb+ query
n:2000; ([] date:n?(reverse .z.d-1+til 10); instance:n?`inst1`inst2`inst3`inst4; sym:n?`USD`EUR`GBP`JPY; cnt:n?10) -
Configure the Schema to use. This can be done manually within the node, or preferably, loaded from a database.
- Data Format
Any- Schema
- Use the defined schema for the kdb expression import, created manually or imported from an existing schema.
Parse Stringscan be set toAutofor all columns; but ensure any time, timestamp and string data columns is set toOnorAuto.
column name column type parse strings date Timestamp Auto instance Symbol Auto symbol Symbol Auto cnt Integer Auto A schema can also be loaded from a database by clicking
 . Parsing of the data is defined as part of schema creation. Users of the guided walkthrough can add this schema to their existing
. Parsing of the data is defined as part of schema creation. Users of the guided walkthrough can add this schema to their existing insights-demoschema.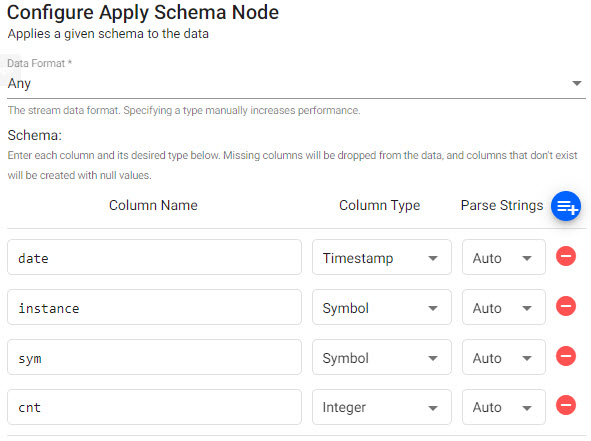
An expression pipeline schema. -
Configure the Writer.
- Database
- Select an database from the dropdown to assign the data, or create a database by clicking
 before returning to the pipeline to add this newly created database. With the guided walkthrough, the
before returning to the pipeline to add this newly created database. With the guided walkthrough, the insights-demodatabase can be used. - Table
- Select a table from the selected database to write the data too; this is typically the schema table from the previous step. If not already completed, create a table with a schema matching that of the previous step and assign it here. During the database wizard creation process there is a step for creating a table (and schema).
- Deduplicate Stream
- Can remain checked.
-
Open the Pipeline
-
Save the Pipeline
Saving an expression pipeline. -
Add the Pipeline to the assembly created during the configuration of the Writer node. Free Tier users can add the pipeline to their
insights-demoassembly. Save the assembly with the pipeline. -
Deploy the Data assembly with the associated Expression pipeline.
-
Query the data. Select the data assembly associated with the Expression pipeline (it may be necessary to refresh the browser to populate the assembly drop down). Repeat the schema table name as the
Output variable. This will be the name of the table to query when getting data; for example, a SQL query in the SQL tab:SQL query
SELECT * FROM tablename -
Get Data
SQL Databases
Applicable to all supported SQL databases, including PostgreSQL and Microsoft SQL Server.
-
Define the Reader node, including any required authentication alongside server and port details.
Sample Postgres Reader Node
- Server: postgresql
- Port: 5432
- Database: testdb
- Username: testdbuser
- Password: testdbuserpassword
- query: select * from cars
Where Server is
postgresql.default.svc, thedefaultis the namespace, e.g.dbwill bepostgresql.db.svccase sensitive
Node properties and queries are case sensitive and should be lower case.
-
Define the Schema.
Parse Stringscan be set toAutofor all columns; but ensure any time, timestamp and string data columns is set toOnorAuto.Sample Postgres Configure Schema
- Data Format: Any
column name column type parse string Year Date Auto Name Symbol Auto Miles_per_Gallon Float Auto Cylinders Float Auto Displacement Float Auto Horsepower Float Auto Acceleration Float Auto Origin Symbol Auto 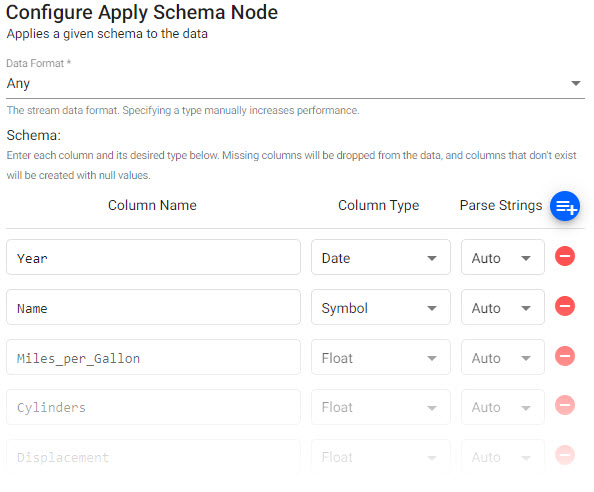
A schema for a sample pipeline. -
Configure the Writer
- Database
- Select an database from the dropdown to assign the data, or create a database by clicking
- Table
- Select a table from the selected database to write the data too; this is typically the schema table. In the Schema used by the database, create a table with a column layout matching the schema used in the previous step. It can be named "cars".
- Deduplicate Stream
- Can remain checked.
-
Open Pipeline
-
Save the Pipeline
-
Add the Pipeline to the assembly created during the configuration of the Writer node. Save the assembly with the pipeline.
-
Deploy the Data assembly with the associated Postgres pipeline.
-
Query the data. Select the data assembly associated with the PostgreSQL pipeline (it may be necessary to refresh the browser to populate the assembly drop down). Define an
Output variable, e.g. "cars", this will be the name of the table to query when usingkdb+\qorpythonin the scratchpad.For querying in the SQL tab:
SQL query
SELECT * FROM cars -
Get Data
See the guided walkthrough SQL database import example.
Cloud Storage Services
Organizations require data services which balance performance, control, security and compliance - while reducing the cost of storing and managing such vast amounts of data. Limitless scale is the reason object storage is the primary storage of cloud service providers, Amazon, Google and Microsoft. kdb Insights allows users take advantage of object storage and an example is available as part of a guided walkthrough
-
Define the Reader node with the S3 path details for how the file will be read and optionally, the Kubernetes secret for authentication. Default values can be used for all but
PathandRegion.Sample Amazon 3 Reader Node
- Path: s3://bucket/pricedata.csv
- Region: us-east-1
-
Define a CSV decoder node. Your imported data source requires a timestamp column to parse the data.
A sample CSV for a time column, category column and two value columns; float and integer
- Delimiter: ","
- Header: First Row
- Schema = ZSFI
-
Define the Transform Schema application
A sample Schema for a time column, category column and two value columns
- Data Format: Any
- Schema: Load a schema from a database by clicking ; create a database and schema if needed, or manually add the columns and column type for each of the source data columns in the Transform Node.
Parse Stringscan be set toAutofor all columns; but ensure any time, timestamp and string data columns is set toOnorAuto.
column name column type parse strings time Timestamp Auto sym Symbol Auto price Float Auto volume Integer Auto -
Define the table name to upsert the data too. Select the database and table to write the data too from the dropdown menu; this will be the same database and table from the schema creation step.
Writer Node
- Database: databasename
- Table: pricedata
-
Open the Pipeline
-
Save the Pipeline
-
Deploy the Data assembly with associated Amazon S3 pipeline.
-
Query the data. Select the assembly from the dropdown (it may be necessary to refresh the browser to view) and open the SQL tab. Define the
Output variableas "pricedata".SQL query
SELECT * FROM pricedata -
Get Data
Note that a Kubernetes secret is required if authenticating with Amazon S3. See the section on Amazon S3 Authentication for more details.
-
Define the Reader node with GCS details. Default values can be used for all but
PathandProject ID.Project IDmay not always have a customizable name, so its name will be contingent on what's assigned when creating your GCS account.Sample GCS Reader Node
- Path: gs://mybucket/pricedata.csv
- Project ID: ascendant-epoch-999999
-
Define a CSV decoder node. Your imported data source requires a timestamp column to parse the data.
A sample CSV for a time column, category column and two value columns; float and integer
- Delimiter: ","
- Header: First Row
- Schema = ZSFI
-
Define the Transform Schema application
A sample Schema for a time column, category column and two value columns
- Data Format: Any
- Schema: Load a schema from a database by clicking ; create a database and schema if needed, or manually add the columns and column type for each of the source data columns in the Transform Node.
Parse Stringscan be set toAutofor all columns; but ensure any time, timestamp and string data columns is set toOnorAuto.
column name column type parse strings time Timestamp Auto sym Symbol Auto price Float Auto volume Integer Auto -
Define the table name to upsert the data too. Select the database and table to write the data too from the dropdown menu; this will typically be the same database and table from the schema creation step.
Writer Node
- Database: databasename
- Table: pricedata
-
Open the Pipeline
-
Save the Pipeline
-
Deploy the Data assembly with associated GCP pipeline.
-
Query the data. Select the assembly from the dropdown (it may be necessary to refresh the browser to view) and open the SQL tab. Define the
Output variableas "pricedata".SQL query
SELECT * FROM pricedata -
Get Data
I want to learn more about Google Cloud Storage Authentication
-
Define the ACP Reader node with ACS details. Default values can be used for all but
PathandProject ID. A customizable account name is supported for ACS.Sample ACP Reader Node
- Path: ms://mybucket/pricedata.csv
- Account: myaccountname
-
Define a CSV decoder node. Your imported data source requires a timestamp column to parse the data.
A sample CSV for a time column, category column and two value columns; float and integer
- Delimiter: ","
- Header: First Row
- Schema = ZSFI
-
Define the Transform Schema application
A sample Schema for a time column, category column and two value columns
- Data Format: Any
- Schema: Load a schema from a database by clicking
 ; create a database and schema if needed, or manually add the columns and column type for each of the source data columns in the Transform Node.
; create a database and schema if needed, or manually add the columns and column type for each of the source data columns in the Transform Node. Parse Stringscan be set toAutofor all columns; but ensure any time, timestamp and string data columns is set toOnorAuto.
column name column type parse strings time Timestamp Auto sym Symbol Auto price Float Auto volume Integer Auto -
Define the table name to upsert the data too. Select the database and table to write the data too from the dropdown menu; this will be the same database and table from the schema creation step.
Writer Node
- Database: databasename
- Table: pricedata
-
Open the Pipeline
-
Save the Pipeline
-
Deploy the Data assembly with associated ACS pipeline.
-
Query the data. Select the assembly from the dropdown (it may be necessary to refresh the browser to view) and open the SQL tab. Define the
Output variableas "pricedata".SQL query
SELECT * FROM pricedata -
Get Data