kdb Insights Database
A high-performance, scalable, cloud-first time-series database
The kdb Insights Database is a distributed time-series database built upon kdb+, providing real-time data ingestion and query, temporal storage tiering, and scalable query routing.
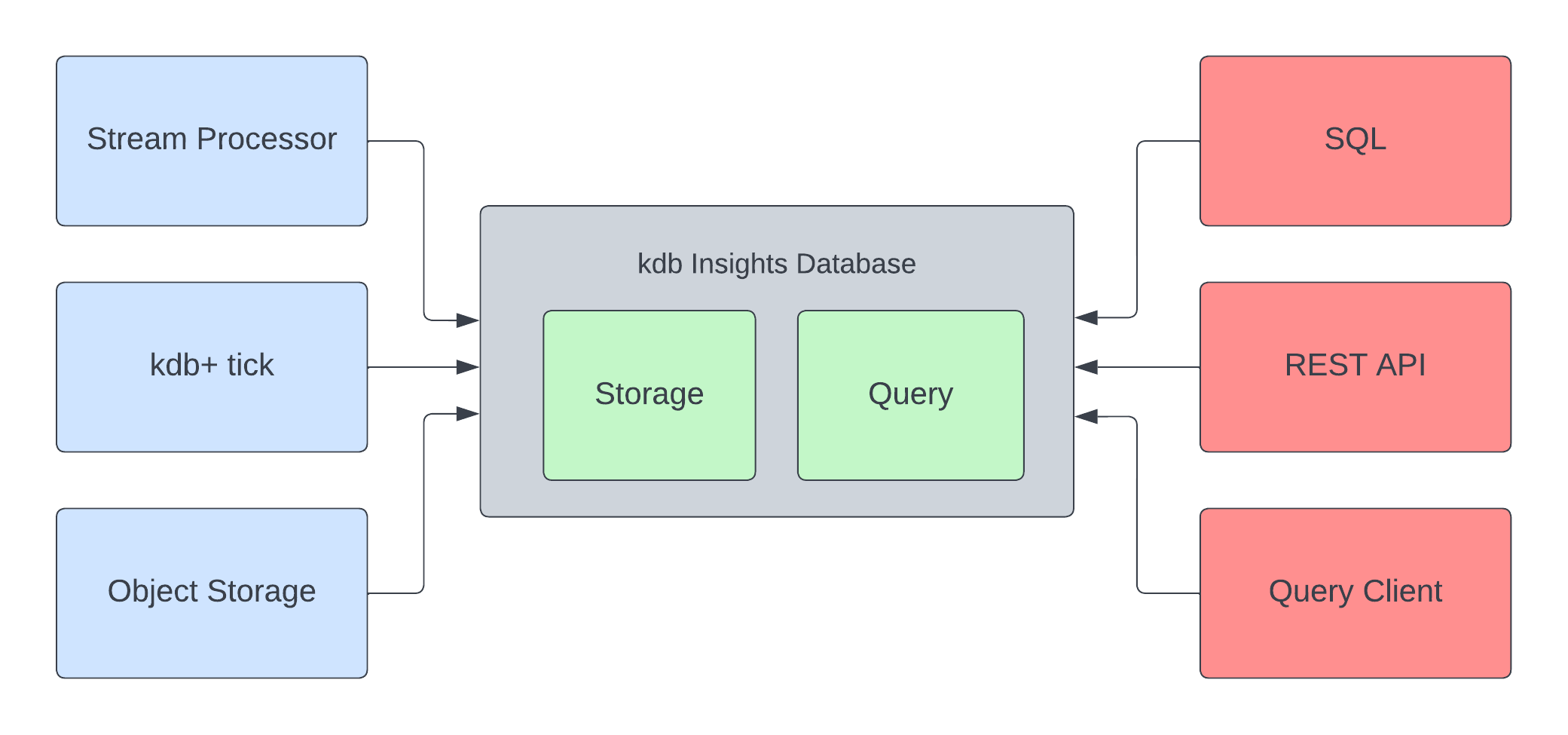
The kdb Insights Database is made up of the following components:
- Query - providing scalable query routing through labels and temporal purview for real-time or historical data
- Storage - providing fast and resilient data write-down
Use cases
The kdb Insights Database provides:
- SQL, qSQL, and structured APIs for querying via q IPC or REST.
- a parallelized write-down process resilient against failures.
- separation of write-down operations from other system processes and their functions, e.g. serving queries.
- a tiered database that seamlessly moves data through the tiers, including object storage.
- configurable compression for tiers of the database.
- a sharded data model facilitating query routing via metadata and temporal range.
- capability for single-shard and multi-shard queries.
- a uniform view of data across all tiers within all shards.
- callback registration for custom q APIs and lifecycle hooks.
Components
The kdb Insights database is composed of a number of core components that distribute the workload of storing and querying data.
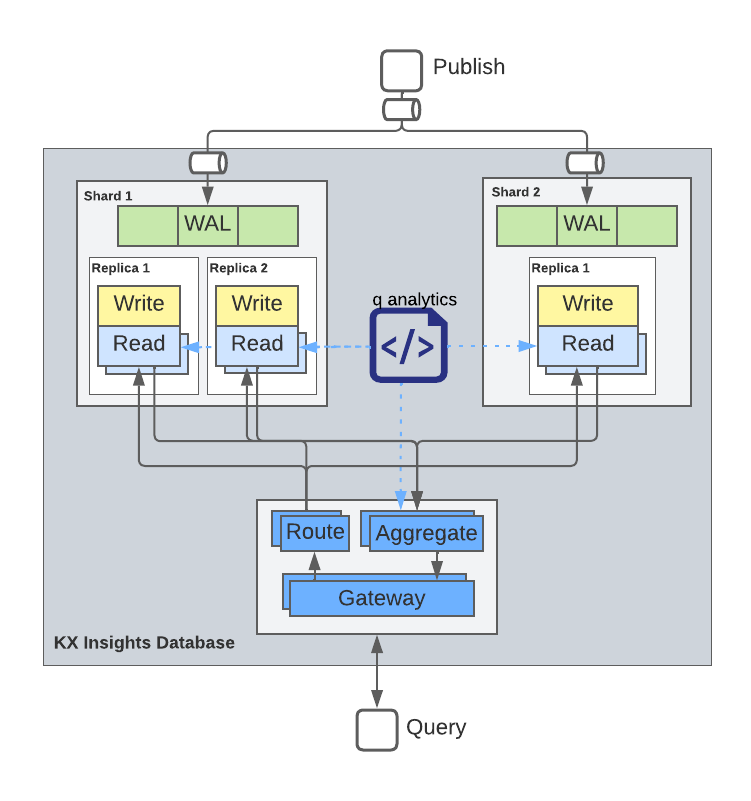
- Service Gateway (Gateway, Route, Aggregate) - providing scalable query routing through labels and temporal purview
- Data Access Process (Read) - providing read access to data, whether real-time or historical
- Storage Manager (Write) - providing fast and resilient data write-down
When assembled together, these components provide the data resilience, data read/write, and query capabilities for high-performance real-time and historical data analytics.
Core concepts
Assembly (shard)
Each kdb Insights Database is configured via a combination of environment variables and an assembly file. The assembly configuration outlines the database schema, storage volumes and tiering, and read/write processes.
Each assembly is a unit that defines a single semantic data shard. Separate assemblies could be created that are semantically similar (share a schema, but differ in label metadata) for volume scaling, or could instead be semantically different, containing an entirely different database schema. The query routing offered by the Service Gateway is capable of connecting to, and serving queries for, any number of semantically similar or distinct data shards at once, providing the capability for cross-shard query and join.
Thus, the Service Gateway is the only component of the kdb Insights Database that does not exist within an assembly, since it provides uniform access to many at once.
Data tiers
As real-time data ages, it is written down by the Storage Manager from fast storage volumes to more cost-effective, though slower, volumes, including object storage as a final volume.
- RDB - real-time in-memory database - (most recent) data, this is the fastest tier.
- IDB - intra-day disk database - data older than the RDB holds, but not yet written to the HDB.
- HDB - historical disk database - data older than the current day, written into daily partitions, and segmented across storage media.
Each of these tiers are independent referred to as Data Access Processes with a unique temporal purview.
Temporal purview
The temporal purview of a Data Access Process refers to the timespan of data that is provides access to. The DAPs share their purview as metadata to the Service Gateway, along with their label metadata, to aid in query routing. Unlike labels, a DAP's temporal purview changes throughout the life of the process as data ages and is moved through storage media.
For example, an RDB will have a data purview for the last 10 minutes of data, an IDB will have a 10 minute lag of the RDB up to the last day and the HDB will have anything older than the last day.
Labels
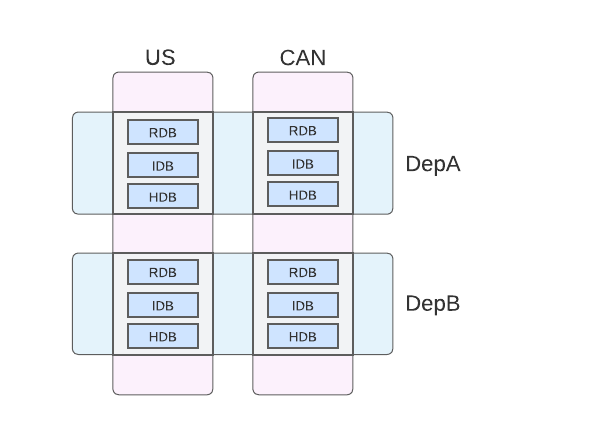
Each assembly is annotated with key-value label metadata, such as:
# assembly-us-depa.yaml
labels:
region: US
department: DepA
# assembly-can-depa.yaml
labels:
region: CAN
department: DepA
# assembly-us-depb.yaml
labels:
region: US
department: DepB
# assembly-can-depb.yaml
labels:
region: CAN
department: DepB
If these four assemblies each contain an RDB, IDB, and HDB, then the data is laid out across Data Access Processes as:
The Service Gateway can then route queries to the appropriate Data Access Processes, combining the results as necessary.
For example, the below API query to getData requests data for all assemblies with region=CAN, and requests only data earlier than the current day, so all region=CAN will contribute one HDB to satisfy the query.
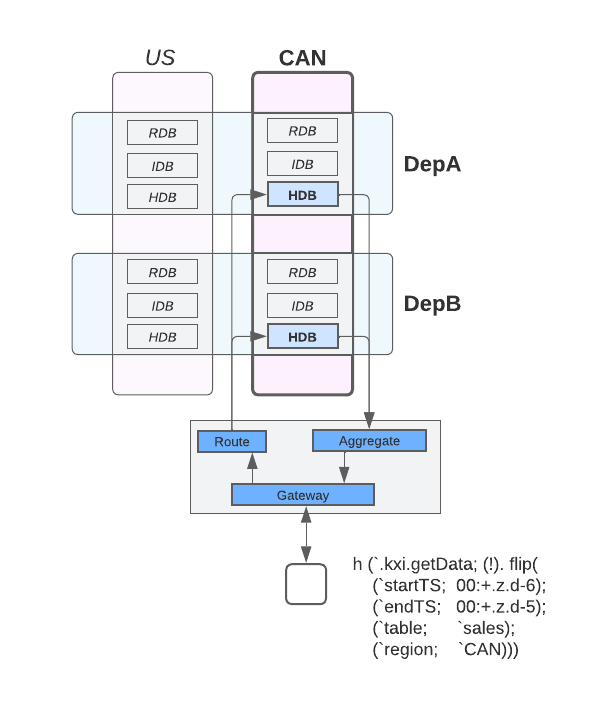
The partial results from each HDB will then be combined by the Aggregator component of the Service Gateway.
Tables are global
Queries without labels are global and will aggregate data from all assemblies that have the the target table. This can lead to a mismatch error if there are multiple versions of the same table and no labels are provided in the query. Use labels in your query whenever you want to select a specific table from a single assembly.
Schema and attributes
While the table schema within each DAP type (RDB, IDB and HDB) is the same (each contains the same set of tables, columns, and their types), each can have different column attributes set to facilitate different query patterns.
The use of attributes has a significant impact on query performance and write-down characteristics, so query patterns should be considered when designing a schema. The following column attributes are available:
- no attributes - requires a linear scan for filters against the column
- sorted - ascending values - allows binary search for filters against the column
- parted - (requires sorted) - maintains an index allowing constant time access to the start of a group of identical values
- grouped - (does not require sorted) maintains a separate index for the column, identifying the positions of each distinct value. NOTE - this index can take up significant storage space.
- unique - (requires all values be distinct) allows a constant-time lookup - typically used for primary keys
More information about attributes, their use, and tradeoffs is available in the kdb+ documentation.
Next Steps
To learn more about configuring a database, see database configuration.
To learn more about querying a database, see database queries.
To learn more about database storage, see database storage options.