White paper
Predicting floods with q and machine learning¶
The Frontier Development Lab (FDL) is a public-private partnership run annually with both the European Space Agency (ESA) and National Aeronautics and Space Administration (NASA). The objective of FDL is to bring together researchers from the Artificial Intelligence (AI) and space science sectors to tackle a broad spectrum of challenges in the space industry. The projects this year include challenges in lunar and heliophysics research, astronaut health and disaster prevention. This paper will focus on the Disaster Prevention, Progress and Response (Floods) challenge, for which KX was a partner.
The need for AI in disaster prevention¶
Floods are one of the most destructive natural disasters worldwide. All regions can be affected by flooding events and, with the increased variability in weather patterns due to global warming, this is likely to become even more prevalent. The speed at which flooding events can occur, and difficulties in predicting their occurrence, create huge logistical problems for both governmental and non-governmental agencies. Over the past 10 years, floods have caused on average 95 deaths a year in the US alone, making them one of the deadliest weather-related phenomenon. Worldwide, floods cost in excess of 40 billion dollars per year, impacting property, agriculture and the health of individuals.
For the duration of the project, we collaborated with the United States Geological Survey (USGS), a scientific agency within the US Department of the Interior. The objective of the organization is to study the landscape of the US and provide information about its natural resources and the natural hazards that affect them. Currently, hydrologists use physical models to help predict floods. These models require predictions to be carefully calibrated for each stream or watershed and careful consideration must be taken for dams, levees, etc. Producing these models is extremely costly due to resource requirements. This limits the areas within the US that can use such systems to better prepare for flood events.
The challenge¶
To predict the flood susceptibility of a stream area, the project was separated into two distinct problems.
Monthly model
Predicting, per month, if a stream height will reach a flood threshold or not. These flood thresholds were set by the National Oceanic and Atmospheric Administration (NOAA) and were location-specific. Knowing which areas are susceptible to flooding, allows locations to better prepare for a flood event.
Time-to-peak model
Predicting the time to peak of a flood event. When a major rain event occurs, knowing how long it will take for a river to reach its peak height is necessary in order to inform potentially affected individuals if and when they need to evacuate. This can help to reduce structural damage and loss of life during a disaster.
Dependencies¶
All development was done with the following software versions:
kdb+ 3.6
Python 3.7.0The following Python modules were also used:
TensorFlow 1.14.0
NumPy 1.17.2
pandas 0.24.2
Matplotlib 2.2.2
scikit_learn 1.1.0
xgboost 0.9.0
gmaps 0.9.0
geopandas 0.5.1
ipywidgets 7.5.1In addition, a number of kdb+ libraries and interfaces were used:
embedPy 1.3.2
JupyterQ 1.1.7
ML toolkit 0.3.2The data¶
This project focuses on six states within the US, over a period of 10 years. Data was taken from ~800 gauge sites, between July 2009 and June 2019. Not all gauge sites had continuous historical data over the period, but all the available data for each site was used.
The six states were: New Jersey, Nebraska, South Carolina, New York, South Dakota, and Virginia. The primary reason for choosing these states, was that they exhibit similar climate and landscape to one another. Climate and landscape play a major role in predicting floods, meaning that building a model to predict flood forecasting for the entire US would be extremely difficult as the climates and landscapes vary dramatically between locations. After discussions with hydrologists at USGS, it was decided that focusing on a subset of areas with similar geographies would help to ensure that the models being produced created meaningful results that could be used in a real world scenario.
Required datasets and providers:
USGS¶
USGS provided its Surface Water dataset. This consisted of the height of a stream as measured by gauges for over 11,000 sites in the US. The data was updated every 15 minutes, with some locations having historical data for over 50 years. As previously mentioned, the data chosen in this case was a subset of these sites based on geographical location.
q)meta max_ht_str
c | t f a
-------| -----
site_no| C
date | d
height | f PRISM¶
The PRISM Climate Group provides climate observations across the whole of the US. This data contains information on total precipitation, minimum/maximum temperature and dew point for each requested latitude and longitude. Spatial and climate datasets are then developed to reveal short and long-term climate patterns. This dataset was used to extract daily precipitation readings from the site locations for each day during the requested 10-year period.
q)meta precipall
c | t f a
-------| -----
site_no| s
long | f
lat | f
elv | f
date | d
ppt | f National Land Cover Database (NLCD)¶
The NLCD database was collected using Landsat. The Landsat satellite program is a NASA/USGS collaboration which provides the longest continuous space-based record of Earth’s landscape. Landsat’s ground resolution and observation wavelengths allow the current use of land and its change over time to be detected and documented. This provides information such as land-use classification (urban, agriculture, forest, etc.), how well the land allows water to pass through it (impervious surface information) and tree cover. This dataset has updated records every five years from 2006. The granularity of this dataset is related to how quickly land use changes over time.
q)meta nlcd
c | t f a
---------| -----
site_no | s
INTPTLAT | f
INTPTLON | f
Measure | f
REACHCODE| f
distance | f
imp | f
year | j National Hydrology Dataset Plus (NHDPlus)¶
NHDPlus is a geo-spatial hydrologic framework dataset associated with USGS, released in 2006. It is based off the NHD dataset, which provides information about the streams, rivers, canals, lakes and ponds throughout the US. The features used from this dataset were the catchment and watershed (an area of land containing streams that drain into a single stream/river) area characteristics at the stream site locations. Catchment areas are particularly important, as these are the areas of a river/stream in which water is collected and accumulates. This is vital information for predicting whether a flood is likely to occur or not.
A description of some important features contained within this dataset are found below:
CatAreaSqKm Area of catchments
WsAreaSqKm Area of all watersheds
Elev Mean of all elevation
WtDep Mean of all water table depths
Om Mean of all organic matter
Perm Mean of all permeability of soils
RckDep Mean of all depth to bedrock of soils
Clay Mean of all clay values
Sand Mean of all sand values
Runoff Mean of all runoff values
WetIndex Mean wetness index
BFI Ratio of base flow to total flow as a percentage
DamNrmStor Volume of all reservoirs per unit areaq)meta basin
c | t f a
--------------------| -----
site_no | s
CatAreaSqKm | f
WsAreaSqKm | f
CatAreaSqKmRp100 | f
WsAreaSqKmRp100 | f
CanalDensCat | f
CanalDensWs | f
ElevCat | f
ElevWs | f
..Flooded Locations And Simulated Hydrographs Project (FLASH)¶
FLASH is a database containing information about flood events within the US. The main goal of the FLASH project was to improve the accuracy and timing when predicting these flash floods. The information used from this dataset was the time taken for a river to reach its peak height after a major rain event.
q)meta peak
c | t f a
----------| -----
site_no | s
lat | f
lon | f
start_time| z s
end_time | z
peak_q | f
peak_time | z
delta_time| f
date | d NOAA¶
NOAA is a US governmental agency for monitoring and preserving the climate and environment. This dataset provided flood-level thresholds for locations across the US. These thresholds consisted of four warning stages and the river height for a given location that causes them to reach these stages. The four warning stages are
| warning | meaning |
|---|---|
| Action | Mitigation action needs to be taken in order to prepare for possible hydrological activity. |
| Flood | The river height poses a threat to lives, property and businesses. |
| Moderate | Some inundation of roads or buildings. A flood warning should be released. |
| Major | Extensive inundation of roads and buildings. Considerable evacuations of areas may occur. |
q)meta warning
c | t f a
----------| -----
GaugeLID | C
Status | C
Location | C
Latitude | f
Longitude | f
Waterbody | C
State | C
Observed | C
ObsTime | C
Units | C
Action | C
Flood | C
...Feature engineering¶
Given all the different data sources available, it was possible to split the information into three datasets. The datasets differ based on the features contained within them. These features were created by extracting aggregated information from the rainfall and stream height datasets. A description of the features defining each dataset are explained below:
- Ungauged basin
-
Features included the past rainfall information of stream sites. This dataset can be used at locations where there is no stream height gauge present, therefore no features were extracted from the stream gauge dataset. The land use data was also included in this dataset.
- Gauged basin
-
Features were extracted containing information about past stream height values before an event. This was also joined with the data from the
Ungauged basinabove. TheGauged basindataset can be used for locations containing historical data from stream gauges. - Perfect Forecasts
-
This dataset extracted features using the current rainfall values for a short period of time after after an event. Data from the
Ungauged basinandGauged basinwere also included. This dataset is used when weather predictions are available for locations along with historical stream height information.
The reason that these three datasets were chosen, was to reflect how this model could be used in a real-world scenario. For the Perfect Forecasts dataset, we assume that future forecasted rainfall is available for the location, however in some applications, this future rainfall prediction cannot always be given with certainty, which is when the Gauged basin or Ungauged basin datasets could be used. The Gauged basin dataset is suitable for stream sites that have historical stream height data recorded over a period of time. When predicting on new sites that do not have this historical data or future rainfall predictions available, the Gauged basin dataset is applicable.
To obtain these features, the addFeat function was used. This enabled features pertaining to previous information to be extracted. This previous information included the past rainfall and stream height values during a set period of time before an event. Windowed features were also added using this function. These window features provided a summary of how certain values changed, such as rainfall or stream height, over a fixed window of time. Windowed features were included, as knowing how fast the rainfall is accumulating in an area along with how the stream height is changing before an event can have a major impact on predicting if a flood will occur. addFeat takes the following arguments as inputs:
- table that is being updated
- how many values to calculate (integer list)
- column to apply the function to (symbol)
- new column name (symbol)
- dictionary of where, group-by and what type of functional statement is used
- function that is applied to the grouped columns
// Upstream, previous, windowed and lagged extraction function
addFeat:{[tab;n;col;newcol;dict;fnc]
dict[`w][
tab;
dict`wh;
dict`gr;
$[1<count col;raze;]applyFunc[n;newcol;;fnc] each col] }The following functions are also called within addFeat:
// Create new column name
colname:{enlist`$string[y],"_",string[x],"_",string[z]}
// Apply functions to appropriate columns
// and rename columns appropriately
applyFunc:{[n;newcol;col;fnc]
raze{[n;newcol;col;fnc]
colname[n;newcol;col]!enlist fnc[n;col]
}[col;newcol;;fnc] each raze n }Whether or not flooding will occur, also depends on what happens in the stream prior to reaching the stream site. This information can be extracted by looking at what happens at locations upstream (direction towards the source of the river), such as the upstream precipitation and stream height values. The ordering of the stream ID number allows the addFeat function to extract the upstream values from the precipitation and stream height datasets. The ID number of each stream site consisted of at least eight digits. The first two digits were the grouping number of the river-basin catchment. The remaining digits were in ascending order based on the location of the gauge along the stream.
An example of this grouping is given below
q)select distinct site_no by catch_id:2#'string each site_no from precip
catch_id| site_no ..
--------| ------------------------------------------------------------..
"01" | `01303500`01304000`01304500`01305000`01305500`01306460`01308..
"02" | `02077000`02079500`02079640`02110400`02110500`02110550`02110..
"03" | `03010674`03010820`03011020`03014500`03164000`03165000`03165..
"04" | `04213319`04213376`04213394`04213401`04213500`04214060`04214..
"05" | `05050000`05290000`05291000 ..
"06" | `06334500`06354881`06355500`06356500`06357800`06359500`06360..// Calculate value of lagged features
prv:{(xprev;y;x)}
// Grouping site numbers by catchment, using the first 2 digits
catch_site:((';#);2;($:;`site_no))
site_date :`site_no`date!(catch_site;`date)
dict:`w`wh`gr!(!;();site_date)
// Extract the 1st upstream precipitation for each site per day
upstr_ppt :addFeat[precip;1;`ppt;`upstr;dict;prv]
// Extract the 1st upstream stream height for each site per day
upstr_height:addFeat[maxht;1;`height;`upstr;dict;prv]When predicting flood events, it is important to also look at what happens in the days prior to the event, such as the amount of rainfall that fell or how the height of the stream changed. The addFeat function was applied to obtain these historical values of rainfall and stream gauge height, for both the current and upstream locations. After discussions with hydrologists, it was decided that the 10 days prior to an event would be included. Any longer than that was deemed to be irrelevant and had the potential to negatively affect the predictions.
dict[`gr]:site:(enlist `site_no)!enlist `site_no
prev_rain:addFeat[
upstr_ppt;
enlist 1_til 10;
`ppt`upstr_ppt_1;
`prev;
sited:dict;
prv]
all_height:addFeat[
upstr_height;
enlist 1_til 10;
`height`upstr_height_1;
`prev;
dict;
prv]q)reverse cols prev_rain //print the new columns created
`prev_upstr_height_1_9`prev_upstr_height_1_8`prev_upstr_height_1_7`p..
q)reverse cols all_height //print the new columns created
`prev_upstr_ppt_1_9`prev_upstr_ppt_1_8`prev_upstr_ppt_1_7`prev_upstr..The above features were applicable to both the monthly and time to peak models. However, additional features that were problem-specific were also added.
Monthly model
When forecasts were provided for each model, it was important to include information about the maximum moving average rainfall over different time windows. This windowed feature gives an insight into how fast the rain was falling over a set time period, which may indicate whether a flood will occur or not. This feature was added to the dataset using the functions displayed below.
// Calculate maximal moving average
max_mavg:{(max;(mavg;y;x))}
dict[`gr]:(`date`site_no)!(($;enlist`month;`date);`site_no)
all_rain:addFeat[
prev_rain;
enlist 1_til 15;
`ppt`upstr_ppt_1;
`window;
dict;
max_mavg]Time-to-peak model
The hours before a flood event can provide important information about how quickly the stream gauge height is moving. This is incredibly useful to a model predicting how long it will take for the stream to reach its peak height. The information extracted at a given stream location comprised of the maximum moving averages over different bucket sizes for the two days before the event. This was found using stream height data from USGS, which was updated at 15-minute intervals.
To make the times from the stream-height dataset consistent with the FLASH dataset, named below as peak_data, the times were converted to be time-zone agnostic.
These zones are:
EDT Eastern Daylight Time
CDT Central Daylight Time
EST Eastern Standard Time// Obtain timezone (unk) information for each site
// from the gauges hdb (str)
time_zone:raze{
si:x 0; dd:x 1;
select `$first site_no,`$first unk from str
where date=first dd,si=`$site_no
} each site_dateq)time_zone
site_no unk
------------
01312000 EST
01315000 EST
01315500 EST
01318500 EST
01321000 EST
q)// Join time-zone information to the FLASH dataset
q)5#peak_data:peak_data ij`site_no xkey time_zone
site_no lat lon start_time end_time ..
---------------------------------------------------------------------..
01396500 40.6778 -74.87917 2009.07.01T16:30:00.000 2009.07.01T20:15:0..
01397000 40.5722 -74.86806 2009.07.01T19:00:00.000 2009.07.02T02:00:0..
01377500 40.9928 -74.02111 2009.07.01T23:45:00.000 2009.07.02T00:15:0..
06478500 43.1858 -97.63528 2009.07.06T16:45:00.000 2009.07.22T15:45:0..
04215500 42.8297 -78.77528 2009.07.10T21:15:00.000 2009.07.11T01:45:0..// Modify the time-zone based on extracted information from gauges hdb
change_zone:{
tm:x 0; tz:x 1;
$[tz=`EDT;tm-04:00;tz=`CDT;tm-05:00;tm-06:00] }After change_zone was applied to the peak_data table, the start_time, end_time and peak_time values were updated in order to reflect the correct time-zone.
q)5#peak_data
site_no lat lon start_time end_time ..
---------------------------------------------------------------------..
01396500 40.6778 -74.87917 2009.07.01T12:30:00.000 2009.07.01T16:15:0..
01397000 40.5722 -74.86806 2009.07.01T15:00:00.000 2009.07.01T22:00:0..
01377500 40.9928 -74.02111 2009.07.01T19:45:00.000 2009.07.01T20:15:0..
06478500 43.1858 -97.63528 2009.07.06T11:45:00.000 2009.07.22T10:45:0..
04215500 42.8297 -78.77528 2009.07.10T15:15:00.000 2009.07.10T19:45:0..The features, along with information about the projected rainfall in the days following the event, were also extracted and joined onto the dataset.
// The date range of interest
range:{(within;x;(,;(+;(-:;2);y);y))}
// The where clause to be applied
wh:{(
range[`date;x 1];
range[`datetime;x 2];
(=;enlist first x; ($;enlist`;`site_no)) ) }
// Dictionary to be passed to the feat function
dict:{`w`wh`gr!(?;wh x;0b)}
// Extract the windowed height features for
// 2, 4, 12 and 48 hours before each event
raze window_ht_prev:{
addFeat[str; enlist 2 4 12 48; `height; `window_prev; dict x; max_mavg]
} each flip peak_data `site_no`date`start_timeq)10#raze window_ht_prev
window_prev_height_2 window_prev_height_4 window_prev_height_12 windo..
---------------------------------------------------------------------..
6.25 6.25 6.245 6.211..
2.89 2.89 2.89 2.89 ..
1.92 1.92 1.92 1.92 ..
12.875 12.8625 12.84833 12.81..
2.38 2.38 2.38 2.38 ..
3.22 3.22 3.22 3.22 ..
2.82 2.82 2.82 2.816..
1.52 1.52 1.52 1.52 ..
0.47 0.47 0.47 0.47 ..
1.67 1.67 1.668333 1.657..wh:{((within;`date;(,;y 1;(+;y 1;x)));(=;enlist first y;`site_no))}
dict:{`w`wh`gr!(?;wh[x;y];0b)}
// Extract the rainfall predictions for each site
// up to 3 days after each event
raze rain_pred:{addFeat[
all_rain;
enlist 1_til x;
`ppt`upstr_ppt_1;
`fut_window;
dict[x;y];
max_mavg] }[3] each flip peak_data `site_no`dateq)10#raze rain_pred
fut_window_ppt_1 fut_window_ppt_2 fut_window_upstr_ppt_1_1 fut_window..
---------------------------------------------------------------------..
3.06 1.665 2.29 1.265 ..
1.53 0.935 2.49 1.39 ..
0.71 0.605 0.71 0.605 ..
1.07 0.535 0.32 0.16 ..
0.44 0.22 0.62 0.31 ..
0.62 0.31 1.78 0.89 ..
1.8 0.97 0.66 0.57 ..
1.61 0.935 1.58 0.93 ..
2.12 1.095 0.43 0.245 ..
0.87 0.79 0.69 0.51 ..Target data¶
Monthly model
The target data used in this case was the flood-level warning, extracted from the NOAA dataset.
The latitude and longitude of these provided thresholds did not exactly match the stream-gauge locations. As such, the latitudes and longitudes of both the stream locations and NOAA threshold readings were joined using a k-dimensional tree (kd-tree) nearest-neighbors algorithm. This algorithm is explained in Appendix 1.
The code used to achieve this nearest-neighbors calculation is seen below with the algorithm implementation contained in full in the GitHub repository associated with this paper.
// Get latitudes and longitudes of the warning and stream gauge sites
latl:raze each
warning[`Latitude`Longitude],'gauges[`dec_lat_va`dec_long_va]
// Create a kd tree of the latitudes and longitudes
tabw:kd.buildtree[latl;2]
// Get indices of where the stream gauge lat and long are.
// Will be used for indexing in the kd tree
gauge_val:count[warning]+til count gauges
// Calculate the threshold nearest neighbor of each stream-gauge
// location using the kdtree
nnwarn:kd.nns[
;
tabw;
(count[warning]#0),count[gauges]#1;
flip wlatl;
`edist] each gauge_val
// Make a table indicating the index of the nearest neighbor
// to each gauge site along with the corresponding distance
joins:([site_no:gauges`site_no]nn:nnwarn[;0];ndw:nnwarn[;1])q)10#joins
site_no | nn ndw
--------| ---------------
01303500| 4652 0.1774627
01304000| 1545 0.1393672
01304500| 3475 0.04823593
01305000| 2800 0.1609363
01305500| 1508 0.07574579
01306460| 1508 0.1871804
01308000| 2458 0.05487667
01308500| 2458 0.04829199
01309500| 2458 0.100588
01309950| 1596 0.07899928
q)10#floodlvl:(maxht ij joins)lj`nn xkey warning
site_no date height nn ndw GaugeLID Status Loca..
---------------------------------------------------------------------..
01303500 2009.07.01 0.75 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.02 0.53 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.03 0.36 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.04 0.32 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.05 0.31 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.06 0.3 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.07 0.84 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.08 0.6 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.09 0.4 4652 0.1774627 "WESN6" "no_flooding" "Gle..
01303500 2009.07.10 0.35 4652 0.1774627 "WESN6" "no_flooding" "Gle..This dataset was then joined onto the stream-gauge data, adding columns counting the number of times a given stream gauge reached each warning level per month.
For the sake of this project, we only wanted to focus on the Flood stage. This level was chosen in an attempt to achieve a more balanced dataset while still predicting a meaningful target. Choosing either of the more severe levels would result in a very low number of targets making it more difficult to discern events of interest. Our target data was a binary label denoting whether the flood warning level was reached in a given month. Any site that claimed to flood more than 28 days per month were omitted from the dataset as we only wanted to focus on events that occurred infrequently and were more difficult to predict.
threshold:0!select
first Action, first Flood, first Moderate, first Major,
no_Action:count where height>Action,
no_Flood:count where height>Flood,
no_Mod:count where height>Moderate,
no_Major:count where height>Major
by site_no, "m"$date
from floodlvl
threshold:select from threshold where no_Flood<28
threshold[`target]:threshold[`no_Flood]>0
q)threshold
site_no date Action Moderate Major target..
---------------------------------------------..
01200000 2009.07 6 10 12 0 ..
01200000 2009.08 6 10 12 0 ..
01200000 2009.09 6 10 12 0 ..
01200000 2009.10 6 10 12 0 ..
01200000 2009.11 6 10 12 0 ..
01200000 2009.12 6 10 12 0 ..
01200000 2010.01 6 10 12 0 ..
01200000 2010.02 6 10 12 0 ..
01200000 2010.03 6 10 12 0 ..
01200000 2010.04 6 10 12 0 ..
01200000 2010.05 6 10 12 0 ..
01200000 2010.06 6 10 12 0 ..
...Time-to-peak model
The FLASH dataset was then used for the time-to-peak model, which highlights how long it will take a stream gauge location to reach its peak height after the rain event.
Only dates within the 10-year period and site numbers within the six states mentioned were included. The target data was calculated by subtracting the start-time (denoted by the start of a major rainfall event at the location) from the time that the peak height was found to occur.
This was then converted into a binary classification problem by setting a threshold for a ‘flash flood’ at 3.5 hours after the major rainfall event. Any time above this was set to 0b and less than this time was 1b. This threshold was chosen after discussions with hydrologists, who found this to be a reasonable split in the dataset.
q)10#peak_data[`delta_peak]:24 * (-). peak_data`peak_time`start_time
0.25 3.5 0.25 130.5 1.5 2.25 6.5 1.5 0.25 20.75
q)10#peak_data[`target]:peak_data[`delta_peak]<3.5
1110110110bSpatial and temporal joins¶
Monthly model
After joining the stream-height and precipitation tables from USGS and PRISM, the dataset was then broken up into monthly values. By taking the first day of each month at a site, it was possible to obtain the maximum moving averages of precipitation for different window sizes for a given month, along with the precipitation and height values for the last few days of the month prior. This data was then joined to the stream_char dataset, which consisted of the basin and land-cover characteristics, and the “threshold” dataset, based on month and site number.
Lagged features were then added to this dataset, which included information such as did a flood occur in the month prior, the year prior and also how often on average did the given location flood.
all_monthly_data:addFeat[
all_monthly_data;
enlist 1 12;
`target;
`lagged;
sited;
prv]
tgts:value exec no_Flood by site_no from all_monthly_data
all_monthly_data[`lagged_target_all]:raze{count[x]mavg raze x}each tgtsTime-to-peak model
The daily rain and height, FLASH, and the stream_char were then joined based on site number and date to create the time-to-peak dataset.
q)10#all_peak_data:peak_data ij`site_no`year xkey stream_char
site_no lat lon start_time end_time ..
---------------------------------------------------------------------..
01396500 40.6778 -74.87917 2009.07.02T04:30:00.000 2009.07.02T08:15:0..
01397000 40.5722 -74.86806 2009.07.02T07:00:00.000 2009.07.02T14:00:0..
01377500 40.9928 -74.02111 2009.07.02T11:45:00.000 2009.07.02T12:15:0..
06478500 43.1858 -97.63528 2009.07.07T07:45:00.000 2009.07.23T06:45:0..
04215500 42.8297 -78.77528 2009.07.11T15:15:00.000 2009.07.11T19:45:0..
04215000 42.89 -78.64528 2009.07.11T15:45:00.000 2009.07.11T20:15:0..
06834000 40.3517 -101.1236 2009.07.17T23:00:00.000 2009.07.18T21:15:0..
01391000 40.9978 -74.11194 2009.07.21T14:45:00.000 2009.07.21T18:15:0..
02162093 34.0274 -81.04194 2009.07.23T00:00:00.000 2009.07.23T00:45:0..
01391000 40.9978 -74.11194 2009.07.28T20:30:00.000 2009.07.29T18:00:0..
q)10#monthly_stream_data:monthly_data ij`site_no`year xkey stream_char
site_no date height upstr_height_1 prev_height_1 prev_height_2 pr..
---------------------------------------------------------------------..
01303500 2009.07 0.75 0.36 ..
01303500 2009.08 0.4 0.45 0.4 0.32 0...
01303500 2009.09 0.27 0.3 0.28 0.31 0...
01303500 2009.10 0.26 0.3 0.27 0.3 0...
01303500 2009.11 0.28 0.33 0.29 0.3 0...
01303500 2009.12 0.49 0.34 0.42 0.28 0...
01303500 2010.01 1.41 0.36 0.73 0.29 0...
01303500 2010.02 0.29 0.32 0.88 0.35 0...
01303500 2010.03 1.81 0.44 1.24 1.04 1...
01303500 2010.04 1.14 0.59 1.66 2.07 1...Train and test split¶
A dictionary was created for each of the three separate datasets:
- Ungauged
- Gauged
- Perfect Forecasts
The dictionary contained the different feature columns created above along with the basin characteristics required to make up the above datasets for each of the monthly (M) and time to peak (P) models.
fc:{x where x in y} / find column
ungauged_colsM: fc[ungauged_cols;cols cleaned_monthly]
gauged_colsM: fc[gauged_cols;cols cleaned_monthly]
perfect_forecast_colsM:fc[perfect_forecast_cols;cols cleaned_monthly]
ungauged_colsP: fc[ungauged_cols;cols cleaned_peak]
gauged_colsP: fc[gauged_cols;cols cleaned_peak]
perfect_forecast_colsP:fc[perfect_forecast_cols;cols cleaned_peak]
ungauge: `M`P!(ungauged_colsM;ungauged_colsP)
gauge: `M`P!(ungauge[`M],gauged_colsM;ungauge[`P],gauged_colsP)
forecast:`M`P!
(gauge[`M],perfect_forecast_colsM;gauge[`P],perfect_forecast_colsP)q)forecast
M| `month`cos_t`sin_t`elv`imp`CatAreaSqKm`WsAreaSqKm`CatAreaSqKmRp100..
P| `month`cos_t`sin_t`elv`imp`CatAreaSqKm`WsAreaSqKm`CatAreaSqKmRp100..split_dict function which takes a table as input, as well as M or P indicating which model was being used.
split_dict:{(!). flip(
(`ungauged;flip x ungauge y);
(`gauged;flip x gauge y);
(`forecast;flip x forecast y) ) }q)split_dict[all_monthly_data;`M]
ungauged| 7i -0.959493 -0.2817326 456f 1.454468 0.7407 526.9086..
gauged | 7i -0.959493 -0.2817326 456f 1.454468 0.7407 526.9086..
forecast| 7i -0.959493 -0.2817326 456f 1.454468 0.7407 526.9086..q)(split_dict[all_monthly_data;`M])`ungauged
7i -0.959493 -0.2817326 456f 1.454468 0.7407 526.9086 0.1926 87..
8i -0.6548607 -0.7557496 456f 1.454468 0.7407 526.9086 0.1926 87..
9i -0.1423148 -0.9898214 456f 1.454468 0.7407 526.9086 0.1926 87..
10i 0.415415 -0.909632 456f 1.454468 0.7407 526.9086 0.1926 87..
11i 0.8412535 -0.5406408 456f 1.454468 0.7407 526.9086 0.1926 87..
12i 1f -2.449294e-16 456f 1.454468 0.7407 526.9086 0.1926 87..
2i 0.8412535 0.5406408 456f 1.454468 0.7407 526.9086 0.1926 87..
3i 0.415415 0.909632 456f 1.454468 0.7407 526.9086 0.1926 87..
4i -0.1423148 0.9898214 456f 1.454468 0.7407 526.9086 0.1926 87..
5i -0.6548607 0.7557496 456f 1.454468 0.7407 526.9086 0.1926 87..
6i -0.959493 0.2817326 456f 1.454468 0.7407 526.9086 0.1926 87..
7i -0.959493 -0.2817326 456f 1.454468 0.7407 526.9086 0.1926 87..
..Prior to the application of a train-test split on the data, rows containing null values are removed from the dataset as these cannot be passed to machine learning algorithms.
cleaned_monthly:all_monthly_data[del_null all_monthly_data]
cleaned_peak: all_peak_data[del_null all_peak_data]Monthly model
When splitting the data for this model, it was deemed important that no time leakage occurred between the training and test sets (e.g. the training set contained information from 2009 to 2017, while the test set contained the remaining years). This ensured that the model was being tested in a way that was similar to a real-world deployment. A split was chosen so that 20 percent of the data for each site was in the test set.
// The cutoff dataset is produced and date defined
// at which the datasets are to be cutoff
cutoff:update cutoff_date:min[date]+floor 0.8*max[date]-min[date]
by site_no from cleaned_monthly
// Extract data and targets from the dataset
XtrainMi:select from cutoff where date<cutoff_date
XtestMi :select from cutoff where date>=cutoff_date
ytrainM :exec target from cutoff where date<cutoff_date
ytestM :exec target from cutoff where date>=cutoff_date
// From the master training and testing datasets extract
// appropriate information for the monthly data
XtrainM:split_dict[XtrainMi;`M]
XtestM:split_dict[XtestMi;`M]Time-to-peak model
The time-to-peak data was separated so that sites did not appear in both the train and test datasets. This was done to ensure that the models being produced could be generalized to new locations. The target data was binned into a histogram as below and the train-test split completed such that the distribution of targets in the training and testing sets were stratified.
sites:0!select sum target by site_no from cleaned_peak
plt[`:hist][sites`target]
plt[`:xlabel]["Number of events per site"]
plt[`:ylabel]["Number of associated sites"]
plt[`:show][]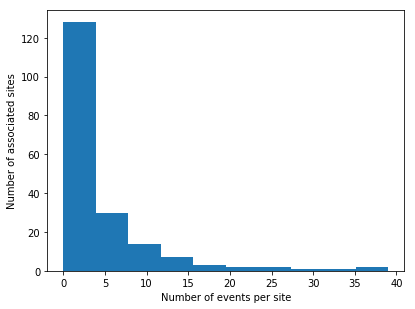
// Set the number of events associated with each bin of the dataset
bins:0 5 15 25.0
// Split the target data into the associated bin
y_binned:bins bin`float$sites`target
// Using embedPy, stratify site numbers and targets
// into an 80-20 train-test split of the data
tts:train_test_split[
sites `site_no;
sites `target;
`test_size pykw 0.2;
`random_state pykw 607;
`shuffle pykw 1b;
`stratify pykw y_binned ]`
// Update the cleaned_peak data
// to add a flag indicating training/testing
cleaned_peak[`split]:`TRAIN
peak_split:update split:`TEST from cleaned_peak where site_no in`$tts 1Building models¶
For both problems a variety of models were tested, but for the sake of this paper, models and results from an eXtreme Gradient Boost (XGBoost) and random-forest classifier (described in more detail in Appendix 2) are presented below. These models were chosen due to their ability to deal with complex, imbalanced datasets where overfitting is a common feature. Overfitting occurs when the model fits too well to the training set, capturing a lot of the noise from the data. This leads to the model performing successfully in training, while not succeeding as well on the testing or validation sets. Another problem that can occur, is that a naïve model can be produced, always predicting that a flood will not occur. This leads to high accuracy but not meaningful results. As seen below in the results section, XGBoosts and random forests were able to deal much better with these issues by tuning their respective hyper-parameters.
To visualize the results, a precision-recall curve was used, illustrating the trade-off between the positive predictive value and the true positive rate over a variety of probability thresholds. This is a good metric for the success of a model when the classes are unbalanced, compared with similar graphs such as the ROC curve. Precision and recall were also used because getting a balance between these metrics when predicting floods was vital to ensure that all floods were given warnings. Yet also to ensure that a low number of false positives were given, the penalty for which was that warnings would be ignored.
A function named pr_curve was created to output the desired results from the models. This function outputs the accuracy of prediction, the meanclass accuracy, a classification report highlighting the precision and recall per class, along with a precision-recall curve. This function also returned the prediction at each location in time for the models used, as can be seen later in this paper to create a map of flooding locations.
The arguments to the pr_curve function are:
- matrix of feature values
- list of targets
- dictionary of models being used
The dictionary of models consisted of XGBoost and a random-forest model, with varying hyper-parameters for each model.
build_model:{[Xtrain;ytrain;dict]
rf_hyp_nms:`n_estimators`random_state`class_weight;
rf_hyp_vals:(dict`rf_n;0;(0 1)!(1;dict`rf_wgt));
rf_clf:RandomForestClassifier[pykwargs rf_hyp_nms!rf_hyp_vals]
[`:fit][Xtrain; ytrain];
xgb_hyp_nms:`n_estimators`learning_rate`random_state,
`scale_pos_weight`max_depth;
xgb_hyp_vals:(dict`xgb_n;dict`xgb_lr;0;dict`xgb_wgt;dict`xgb_maxd);
xgb_clf: XGBClassifier[pykwargs xgb_hyp_nms!xgb_hyp_vals]
[`:fit]
[np[`:array]Xtrain; ytrain];
`random_forest`XGB!(rf_clf;xgb_clf) }Results¶
The results below were separated based on the three datasets.
Model testing¶
Ungauged models¶
Monthly
dict:`rf_n`rf_wgt`rf_maxd`xgb_n`xgb_lr`xgb_wgt`xgb_maxd!
(200;1;8;200;.2;15;7)
models:build_model[XtrainM`ungauged;ytrainM;dict]q)pltU1:pr_curve[XtestM`ungauged;ytestM;models]
Accuracy for random_forest: 0.9380757
Meanclass accuracy for random_forest: 0.8382345
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.9424622 0.9939699 0.967531 13101
1 | 0.7340067 0.2152024 0.3328244 1013
avg/total| 0.8382345 0.6045861 0.6501777 14114
Accuracy for XGB: 0.9197959
Meanclass accuracy for XGB: 0.69065
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.9512177 0.9629799 0.9570627 13101
1 | 0.4300823 0.3613031 0.3927039 1013
avg/total| 0.69065 0.6621415 0.6748833 14114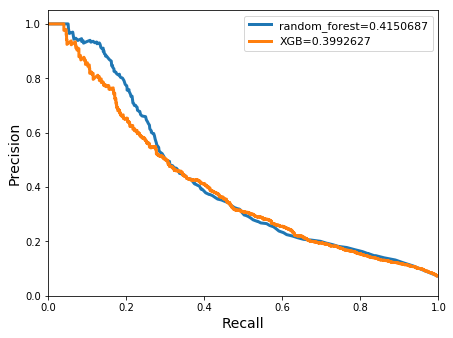
Time-to-peak
dict:`rf_n`rf_wgt`rf_maxd`xgb_n`xgb_lr`xgb_wgt`xgb_maxd!
(220;1;17;340;.01;1.5;3)
models:build_model[XtrainP`ungauged;ytrainP;dict]q)pltU2 :pr_curve[XtestP`ungauged;ytestP;models]
Accuracy for random_forest: 0.7330896
Meanclass accuracy for random_forest: 0.7312101
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.7336066 0.9572193 0.8306265 374
1 | 0.7288136 0.2485549 0.3706897 173
avg/total| 0.7312101 0.6028871 0.6006581 547
Accuracy for XGB: 0.7751371
Meanclass accuracy for XGB: 0.7474176
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.7995227 0.8957219 0.8448928 374
1 | 0.6953125 0.5144509 0.5913621 173
avg/total| 0.7474176 0.7050864 0.7181275 547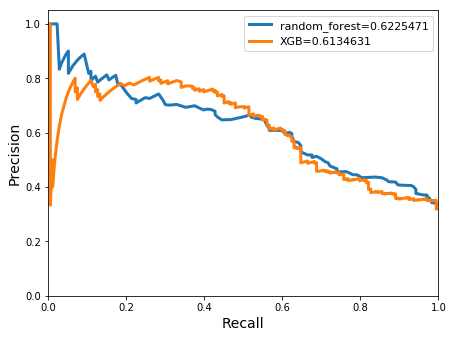
Gauged models¶
Monthly
dict:`rf_n`rf_wgt`rf_maxd`xgb_n`xgb_lr`xgb_wgt`xgb_maxd!
(100;16;8;100;0.2;16;9)
models:build_model[XtrainM`gauged;ytrainM;dict]q)pltG1:pr_curve[XtestM`gauged;ytestM;models]
Accuracy for random_forest: 0.9430843
Meanclass accuracy for random_forest: 0.9163495
Accuracy for random_forest: 0.9422559
Meanclass accuracy for random_forest: 0.9000509
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.9439867 0.9969468 0.9697442 13101
1 | 0.8561151 0.2349457 0.3687064 1013
avg/total| 0.9000509 0.6159463 0.6692253 14114
Accuracy for XGB: 0.9332578
Meanclass accuracy for XGB: 0.7507384
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.9559055 0.9729792 0.9643668 13101
1 | 0.5455712 0.4195459 0.4743304 1013
avg/total| 0.7507384 0.6962625 0.7193486 14114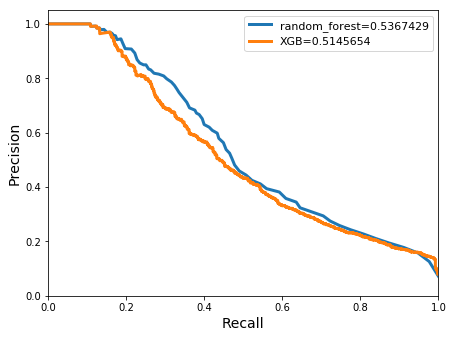
Time-to-peak
dict:`rf_n`rf_wgt`rf_maxd`xgb_n`xgb_lr`xgb_wgt`xgb_maxd!
(100;1;17;350;0.01;1.5;3)
models:build_model[XtrainP`gauged;ytrainP;dict]q)pltG2 :pr_curve[XtestP`gauged;ytestP;models]
Accuracy for random_forest: 0.7367459
Meanclass accuracy for random_forest: 0.763421
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.7309237 0.973262 0.8348624 374
1 | 0.7959184 0.2254335 0.3513514 173
avg/total| 0.763421 0.5993478 0.5931069 547
Accuracy for XGB: 0.7842779
Meanclass accuracy for XGB: 0.7650789
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.7990654 0.9144385 0.8528678 374
1 | 0.7310924 0.5028902 0.5958904 173
avg/total| 0.7650789 0.7086643 0.7243791 547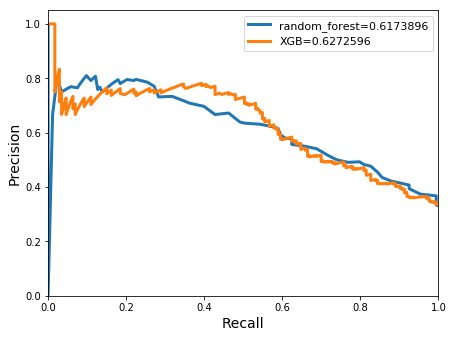
Perfect Forecasts models¶
Monthly
dict:`rf_n`rf_wgt`xgb_n`xgb_lr`xgb_wgt`xgb_maxd!
(100;15;100;0.2;15;7)
models:build_model[XtrainM`forecast;ytrainM;dict]q)pltP1:pr_curve[XtestM`forecast;ytestM;models]
Accuracy for random_forest: 0.9448066
Meanclass accuracy for random_forest: 0.9130627
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.9462553 0.9971758 0.9710484 13101
1 | 0.8798701 0.2675222 0.4102952 1013
avg/total| 0.9130627 0.632349 0.6906718 14114
Accuracy for XGB: 0.9471447
Meanclass accuracy for XGB: 0.8045102
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.9695219 0.9736661 0.9715896 13101
1 | 0.6394984 0.6041461 0.6213198 1013
avg/total| 0.8045102 0.7889061 0.7964547 14114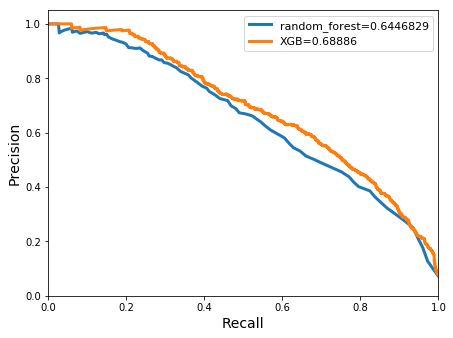
Time-to-peak
dict:`rf_n`rf_wgt`rf_maxd`xgb_n`xgb_lr`xgb_wgt`xgb_maxd!
(100;1;17;300;0.01;2.5;3)
models:build_model[XtrainP`forecast;ytrainP;dict]q)pltP2 :pr_curve[XtestP`forecast;ytestP;models]
Accuracy for random_forest: 0.7550274
Meanclass accuracy for random_forest: 0.7668274
class | precision recall f1_score support
---------| ------------------------------------
0 | 0.751046 0.959893 0.842723 374
1 | 0.7826087 0.3121387 0.446281 173
avg/total| 0.7668274 0.6360159 0.644502 547
Accuracy for XGB: 0.7440585
Meanclass accuracy for XGB: 0.7027966
class | precision recall f1_score support
---------| -------------------------------------
0 | 0.8031088 0.828877 0.8157895 374
1 | 0.6024845 0.5606936 0.5808383 173
avg/total| 0.7027966 0.6947853 0.6983139 547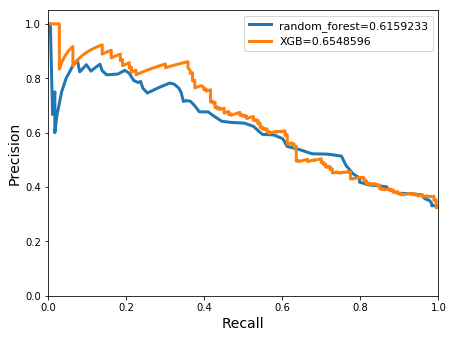
Scoring summary¶
Ungauged models¶
Monthly
The accuracies of both classifiers in the monthly model were relatively high in this case. Random forests achieved a slightly higher score of 0.938. The meanclass accuracy was lower for both classifiers, ranging from ~0.7-0.84 in the random forests and XGBoost respectively. However, considering that the class distribution was extremely imbalanced, the accuracy is an unreliable metric to evaluate the models fairly. Both classifiers returned low precision and recall scores when evaluating the positive class, indicating that the models were not adept at discerning flood events. Low scores of ~0.4 were also seen in the precision-recall curves for both classifiers.
Time-to-peak
XGBoosts achieved both a higher accuracy of 0.78 and a more stable precision recall ratio, 0.7 to 0.51, for the positive class when compared with random forests. This indicates that a relatively large amount of flood events occurring under the 3.5 hour threshold were being identified by the model. The meanclass accuracies for both classifiers were similar at ~0.75. The area under the precision-recall curve were also seen to be comparable for both classifiers.
Gauged models¶
Monthly
Improvements in both the accuracy and meanclass accuracy were evident in the gauged models when compared to the ungauged example. In this case, higher accuracies were achieved by the random-forest classifier. The meanclass accuracy also performed better at 0.9 when compared with the XGBoost classifier result of 0.75. Although still low, a slightly improved balance between the precision and recall scores, 0.54 to 0.42, for the positive class was reached by the XGBoost. The area under the precision-recall curve improved in both classifiers to 0.51 (XGBoost) and 0.54 (random forests) from the previous ungauged model.
Time-to-peak
The accuracy and meanclass accuracy achieved with the gauged datasets were very similar to the results obtained in the ungauged model. This in conjunction with similarities to the precision and recall scores indicates that the addition of previous stream/river heights does not impact the models. The areas under with the precision-recall curves however, were also similar when compared with the previous models curves.
Perfect Forecast models¶
Monthly
Similar accuracy results were seen between the random forests and XGBoost with results on the order of 0.945. The random-forest classifier achieved a greater meanclass accuracy score of 0.91 compared with that of XGBoosts 0.8. Precision and recall scores for the positive class were also high at ~0.62 for both metrics. However the random-forest classifier produced a high imbalance between the precision and recall scores which were 0.88 and 0.27 respectively. Both precision-recall curves improved from the previous gauged model, achieving areas of 0.69 and 0.64 for XGBoost and the random forest classifier respectively.
Time-to-peak
A slight decrease in accuracy occurred in both classifiers compared with previous models, although an improved balance between the precision and recall scores of 0.6 and 0.56 were seen for the XGBoost. The area under the precision-recall curves increased slightly when compared to the the previous models’ results, reaching scores of 0.65 for the XGBoost and and 0.62 for the random forests classifiers.
Feature significance¶
There was also a lot to be learned from determining which features contributed to predicting the target for each model. To do this, the function ml.fresh.significantfeatures was applied to the data, to return the statistically significant features based on a p-value. Combining this with ml.fresh.ksigfeat[x] enabled the top x most significant features to be extracted from each dataset.
title:{"The top 15 significant features for ",x," predictions are:"}
nums :{string[1+til x],'x#enlist". "}
q_kfeat:.ml.fresh.ksigfeat 15Monthly model
title["monthly"]
X_Month:flip forecast[`M]!cleaned_monthly forecast[`M]
y_Month:cleaned_monthly`target
3 cut`$nums[15],'
string .ml.fresh.significantfeatures[X_Month;y_Month;kfeat]"The top 15 significant features for monthly predictions are:"
1. lagged_target_all 2. window_ppt_1 3. window_ppt_2
4. window_ppt_3 5. window_ppt_4 6. window_ppt_5
7. window_ppt_6 8. window_upstr_ppt_1_1 9. window_upstr_ppt..
10. window_upstr_ppt_1_3 11. window_upstr_ppt_1_4 12. lagged_target_1
13. lagged_target_12 14. window_upstr_ppt_1_5 15. window_ppt_7From the above results, it is evident that the most important features for predicting flooding in the monthly models were the features that were created throughout the notebook. In particular the windowed precipitation features (both in the site and upstream locations, window_ppt_ and window_upstr_ppt_) along with the lagged target values (the average target value overall being the most important, lagged_target_all, and the target value from the previous month before the event holding the least amount of information compared, lagged_target_1). It is also evident that the basin characteristics from the NLCDPlus dataset do impact the model predictions as strongly as the created features.
Time-to-peak model
title["time-peak"]
X_t2p:flip forecast[`P]!cleaned_peak[forecast[`P]]
y_t2p:cleaned_peak`target
3 cut`$nums[15],'
string .ml.fresh.significantfeatures[X_t2p;y_t2p;kfeat]"The top 15 significant features for time-peak predictions are:"
1. WsAreaSqKmRp100 2. WsAreaSqKm 3. window_prev_height_48
4. prev_upstr_height_1_1 5. window_prev_height_12 6. prev_height_1
7. WetIndexCat 8. prev_height_5 9. prev_height_4
10. prev_height_6 11. prev_height_7 12. prev_height_2
13. window_prev_height_4 14. prev_height_8 15. prev_height_3
Compared with the monthly model, it is clear that the basin characterics such as the area of a watershed (WsAreaSqKmRp100, WsAreaSqKm) and the wetness index of a catchment (WetIndexCat) along with the previous height of the stream before the flood event (in both the current and upstream location) have the most impact on the models predictions. The maximum moving averages of the height up to 48 hours before the flood event (window_prev_height_) also played an important role. The previous and windowed precipitation values did not appear as a top feature for this model.
Graphics¶
Monthly model
Using these results, it was also possible to build a map that highlighted per month which areas were at risk of flooding. This could be used by governmental bodies to prioritize funding in the coming weeks.
// Extract the prediction values from the monthly perfect forecast model
preds:last pltP1`model
newtst:update preds:preds from XtestMi
// Find all the locations that the model predicted will flood in 2018.
newt:select from newtst where date within 2018.01 2018.12m,preds=1
// Convert the table to a pandas dataframe
dfnew:.ml.tab2df newt
// Show the monthly flood predictions using gmaps
graphs:.p.get`AcledExplorer
graphs[`df pykw dfnew][`:render][];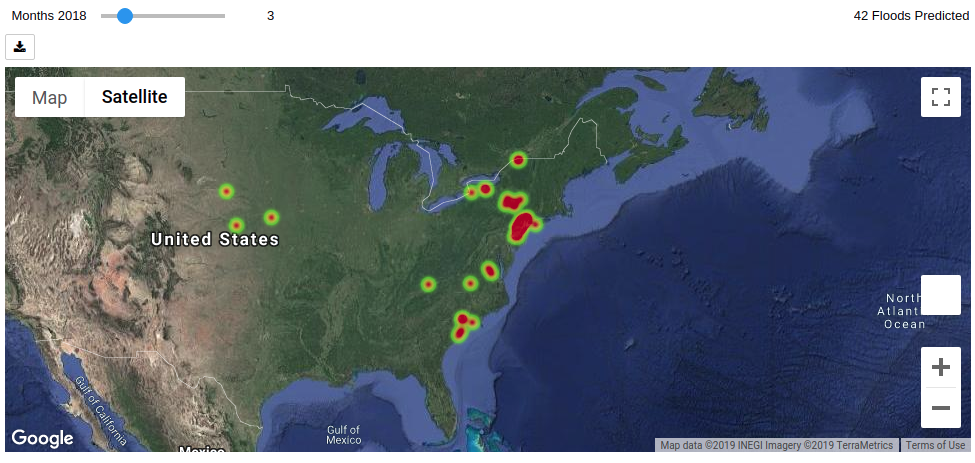
Time-to-peak model
Data relating to the peak height of a stream from an actual flooding event was also compared with the upper bound peak time from our model.
// The predictions for the ungauged model are extracted
pred:last pltU2`model
// For a specific site the start, peak and end times of an produced
pg:raze select site_no, start_time, end_time, peak_time
from XtrainPi
where unk=`EDT,i in
where pred=XtestPi`target,site_no=`02164110, target=1,delta_peak>2
// Define parameters to be taken into account in plotting
rainfall :`x_val`col`title!(pg[`start_time];`r;`rainfall)
actual_peak:`x_val`col`title!(pg[`peak_time];`g;`actual_peak)
pred_bound :`x_val`col`title!
(03:30+pg[`start_time];`black;`predicted_upper_bound)
// Extract relevant information for each site
// at the time of a major rainfall event
graph:select from str where
date within (`date$pg[`start_time];`date$pg[`end_time]),
datetime within (neg[00:15]+pg[`start_time];[00:10]+pg[`end_time]),
(pg`site_no)=`$site_no
// Plot stream height as a function of time
times :graph`datetime
heights:graph`height
plt_params:`label`linewidth!(`height;3)
plt[`:plot][times;heights;pykwargs plt_params]
// Plot lines indicating relevant events
pltline:{
dict:`color`label`linewidth!(x`col;x`title;3);
plt[`:axvline][x`x_val;pykwargs dict]; }
pltline each(rainfall;actual_peak;pred_bound)
plt[`:legend][`loc pykw `best]
plt[`:title]["Time to Peak"]
plt[`:ylabel]["Height"]
plt[`:xlabel]["Time"]
plt[`:xticks][()]
plt[`:show][]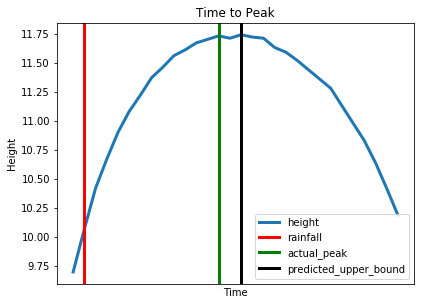
The above plot gives an indication to how close the time to peak models prediction was compared with the time that the actual flood peak occured. In a real life scenario, being able to create an upper bound time limit predicting when a flood will reach its peak, allows emergency services to take appropriate action, possibly reducing the damages caused by floods.
Conclusion¶
From the above results we could predict, with relatively high accuracy, whether an area was likely to flood or not in the next month. We could also produce a model to predict if a stream would reach its peak height within 3.5 hours.
For the monthly models, the future weather predictions played an important role in predicting whether an area would flood or not. Accuracy increased as the weather predictions and gauged information columns were added to the dataset. This corresponds with the results from the significant feature tests, where lagged_target information and the windowed rain volumes of the current month were deemed to be the most features for inclusion. For the majority of the models, the random-forests classifier obtained high-accuracy results, however this often coincided with imbalanced precision and recall scores. In some scenarios, high-precision scores were achieved along with corresponding low recall, indicating that flooding events could be missed. Although XGBoosts didn’t achieve as high accuracy, the precision and recall scores were much more balanced, which is a favorable trait to have in this type of model when predicting complex events such as flooding.
The opposite was true for the time-to-peak models, as previous rain- and stream-gauge information, along with the basin characteristics, were deemed to be the most significant features when predicting these values. Including additional information about the future predicted rainfall did not improve the accuracy of the results. The best results were obtained from the gauged model by the XGBoost classifier. Despite this, the Perfect Forecasts dataset achieved the best balance between the precision and recall of the positive class, compared with the ungauged model that favoured high precision alongside low recall scores.
Both of these results are to be physically expected. In the case of the monthly prediction, information regarding future rainfall information is vital to predicting if an area will flood in the next month. Whereas in the case of a time-to-peak value, it would extremely unlikely that information about rainfall in the days following the peak height being reached would add any predictive power to the model.
Knowing the features that contribute to flood susceptibility and the length of time it takes for a river to reach its peak height, are important pieces of information to extract from the model. From this, organizations such as USGS can better prepare for flood events and understand how changing climates and placement of impervious surface can affect the likelihood of flooding.
The best results from the models above were obtained by continuously adjusting the hyper-parameters of the model. The unbalanced target data in the monthly model, meant that weighting the classes was an important feature to experiment with. This was particularly important when trying to obtain high precision and recall results. Between the two models, balance in the recall and precision was better for the XGBoost model.
Author¶

Diane O’Donoghue joined First Derivatives in 2018 as a data scientist in the Capital Markets Training Program and is currently on the Machine Learning team based in London. Within the team, Diane has been involved with expanding the Machine Learning Toolkit and the automated machine-learning platform.
Other papers by Diane O’Donoghue
Code¶
The code presented in this paper is available from kxcontrib/fdl2019.
Acknowledgements¶
I gratefully acknowledge the Disaster Prevention team at FDL: Piotr Bilinski, Chelsea Sidrane, Dylan Fitzpatrick, and Andrew Annex for their contribution and support, along with my colleagues in the Machine Learning team.
Appendixes¶
1. Kd-tree¶
A kd-tree is used in k-dimensional space to create a tree structure. In the tree each node represents a hyperplane which divides the space into two seperate parts (the left and the right branch) based on a given direction. This direction is associated with a certain axis dimension, with the hyperplane perpendicular to the axis dimension. What is to the left or right of the hyperplane is determined by whether each data point being added to the tree is greater or less than the node value at the splitting dimension. For example, if the splitting dimension of the node is x, all data points with a smaller x value than the value at the splitting dimension node will be to the left of the hyperplane, while all points equal to or greater than will be in the right subplane.
The tree is used to efficiently find a datapoint’s nearest neighbor, by potentially eleminating a large portion of the dataset using the kd-tree’s properties. This is done by starting at the root and moving down the tree recursively, calculating the distance between each node and the datapoint in question, allowing branches of the dataset to be eliminated based on whether this node-point distance is less than or greater than the curent nearest neighbor distance. This enables rapid lookups for each point in a dataset.
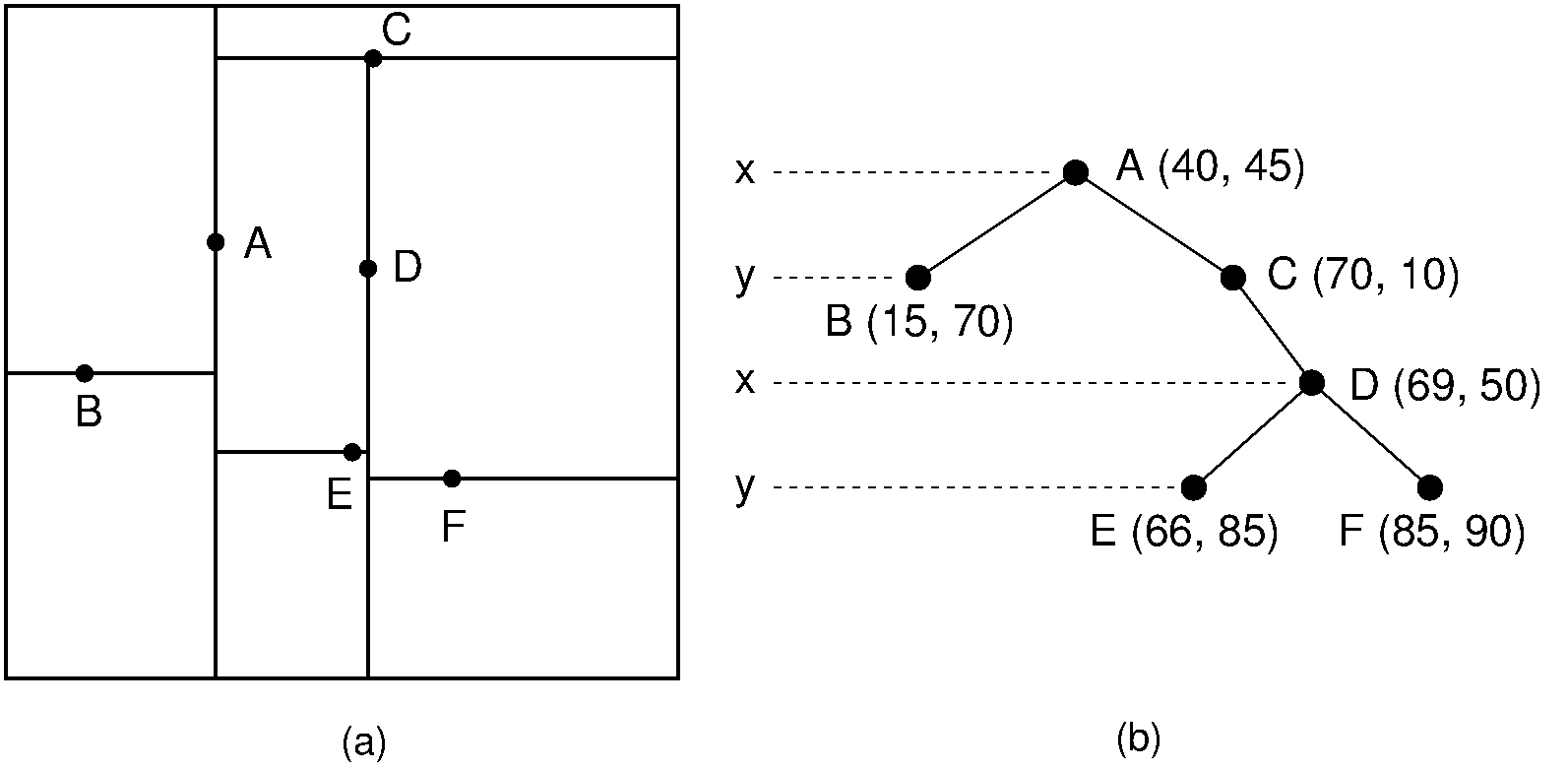
Visual representation of a kd-tree
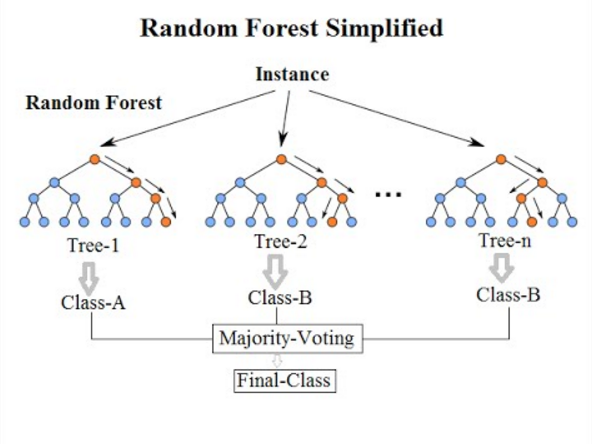
2. Ensemble methods¶
An ensemble learning algorithm combines multiple outputs from a wide variety of predictors to achieve improved results. A combination of ‘weak’ learners are typically used with the objective to achieve a ‘strong’ learner. A weak predictor is a classifier that is only slightly correlated to the true predictions, while a strong learner is highly correlated. One of the advantages of using ensemble methods is that overfitting is reduced by diversifying the set of predictors used and averaging the outcome, lowering the variance in the model.
- XGBoosts
-
XGBoosts, commended for its speed and performance, is an ensemble method built on a gradient-boosting framework of decision trees. This method uses boosting techniques by building the model sequentially, using the results from the previous step to improve the next. This method relies on subsequent classifiers to learn from the mistakes of the previous classifier.
- Random Forests
-
This is also an ensemble method, where classifiers are trained independently using a randomized subsample of the data. This randomness reduces overfitting, while making the model more robust than if just a single decision tree was used. To obtain the output of the model, the decisions of multiple trees are merged together, represented by the average.